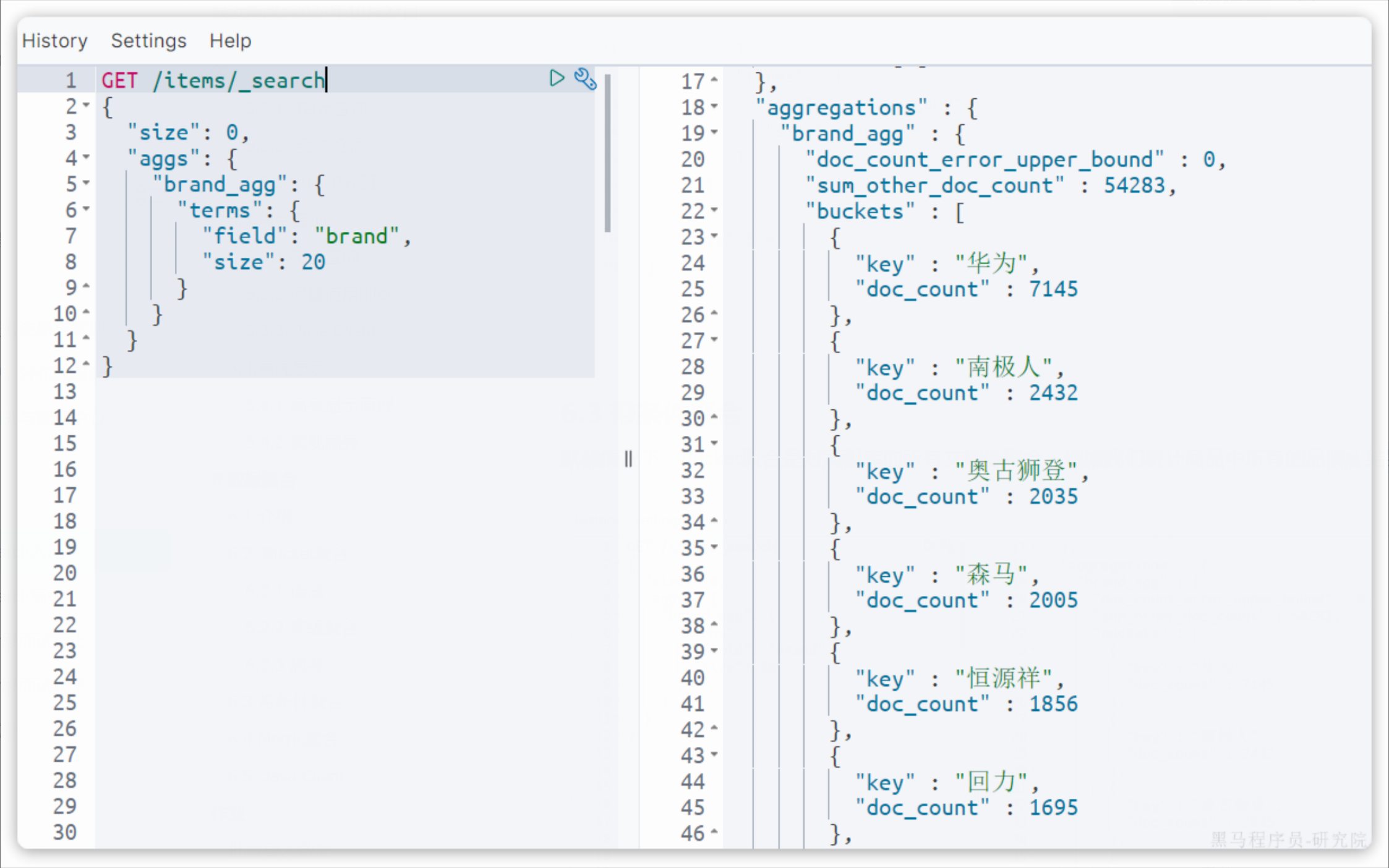
django 条件过滤 queryset.filter用法和 django_filters.FilterSet用法
1 queryset.filter用法
__exact 精确等于 like 'aaa'
__iexact 精确等于 忽略大小写 ilike 'aaa'
__contains 包含 like '%aaa%'
__icontains 包含 忽略大小写 ilike '%aaa%',但是对于sqlite来说,contains的作用效果等同于icontains。
__gt 大于
__gte 大于等于
__lt 小于
__lte 小于等于
__in 存在于一个list范围内
__startswith 以...开头
__istartswith 以...开头 忽略大小写
__endswith 以...结尾
__iendswith 以...结尾,忽略大小写
__range 在...范围内
__year 日期字段的年份
__month 日期字段的月份
__day 日期字段的日
__isnull=True/False
如果参数是字典,如
condtions: {'date__lt': '2018-05-22','status': '未支付','name__exact': 'yangxia'}
Entry.objects.filter(**condtions)相当于 Entry.objects.filter(date__lt= '2018-05-22',status='未支付',name__exact='yangxia')
翻译成sql语句是
select * from Entry.objects where date<='2018-05-22' and status='未支付' and name like 'yangxia'
filter例子:
>> q1 = Entry.objects.filter(headline__startswith="What")
>> q2= q1.filter(pub_date__gte=datetime.date.today())
>>> q3= q.filter(pub_date__lte=datetime.date.today())
2 django_filters.FilterSet用法
from django_filters import rest_framework as django_filters
class RobotFilter(django_filters.FilterSet):
robot_id = django_filters.CharFilter(field_name='id')
machine_id = django_filters.CharFilter(field_name='machine_id')
city = django_filters.CharFilter(field_name='city')
# lookup_expr(可选)为判断条件,field_name(必选)为模型类属性,created_time查询字符串
created_time = django_filters.CharFilter(field_name='created_at', lookup_expr='startswith')
created_start_time = django_filters.DateTimeFilter(field_name='created_at', lookup_expr='gt')
created_end_time = django_filters.DateTimeFilter(field_name='created_at', lookup_expr='lt')
problem_isnull = django_filters.BooleanFilter(field_name='problem', lookup_expr='isnull')
name = django_filters.CharFilter(lookup_expr='iexact') # iexact表示精确匹配, 并且忽略大小写
author = django_filters.CharFilter(lookup_expr='icontains') # icontains表示模糊查询(包含),并且忽略大小写
price = django_filters.NumberFilter(look_expr='exact') # exact表示精确匹配
age_g = filters.NumberFilter(field_name='age', lookup_expr='gte',help_text="年龄大等于")
age_l = filters.NumberFilter(field_name='age', lookup_expr='lte',help_text="年龄小等于")
# opensea是一个外键
town = filters.CharFilter(field_name='opensea__home_town',lookup_expr='icontains',help_text="户籍地")
exp = filters.CharFilter(method='get_exp_work_display',help_text="职位匹配")
def get_exp_work_display(self, queryset, *arg):
word = arg[1]
# MySeaMid.objects.filter(user=self.request.user, sea_type=0).order_by('-add_time')
queryset = queryset.filter(Q(opensea__worker__icontains=word) | Q(opensea__job_exp__icontains=word))
return queryset
task_res_state = django_filters.CharFilter(method="get_task_res_state") def get_task_res_state(self, queryset, *arg): #多选情况
if str(arg[1]) == "0": # arg[1]=('task_res_state', '0')
task_res = (1, 2, 3)
else:
task_res = (0, 4, 5, 6)
print(task_res)
queryset = queryset.filter(task_res__in=task_res)
return queryset class Meta:
model = Robot
fields = ['robot_id', 'machine_id', "city", "created_start_time", "created_end_time", 'created_time',
'firmware_version', 'state', "robot_type", "hardware_version", "exist_map", 'task_res_state']
转自:https://blog.csdn.net/weixin_38836909/article/details/112611214
======================================================
当使用复杂的ORM方式查询时,如果有困惑,使用 str(queryset.query) 查看对应生成的SQL语句。
聚合和其他 QuerySet 子句
filter() 和 exclude()
聚合结果也可以使用过滤。任何应用于普通模型字段的 filter() (或 exclude())对聚合的对象也有约束效果。
当与 annotate() 子句一起使用时,过滤器的效果是限制用来计算“注释”( annotate() 子句会给queryset中的对象增加一个属性和值,称之为“注释”)的对象。
例如,以下查询生成所有标题以 “Django” 开头的书籍的带注释列表:
>>> from django.db.models import Avg, Count
>>> Book.objects.filter(name__startswith="Django").annotate(num_authors=Count("authors"))
当与 aggregate() 子句一起使用时,过滤器的效果是限制用来计算聚合的对象。
例如,以下查询生成所有标题以 “Django” 开头的书籍的平均价格:
>>> Book.objects.filter(name__startswith="Django").aggregate(Avg("price"))
过滤注释
注解过的值也可以使用过滤器。注解的别名可以和任何其他模型字段一样使用 filter()和 exclude()子句。(因为使用 annotate()生成的也是一个QuerySet,根据链式查询的规则,是可以这样的。)
例如,要生成一个具有多位作者的书籍列表:
>>> Book.objects.annotate(num_authors=Count("authors")).filter(num_authors__gt=1)
annotate() 和 filter() 子句的顺序
当开发一个涉及 annotate() 和 filter() 子句的复杂查询时,要特别注意应用于 QuerySet 的子句的顺序。
当一个 annotate() 子句应用于查询,会根据查询状态来计算注释。这实际上意味着 filter() 和 annotate() 不是可交换的操作。
filter()用在前面,会先过滤对象,再生成注释。
annotate()用在前面,会先生成注释,然后过滤对象,在多对多的查询和一对多的反向查询时,会容易观察到差异。例如:
出版者A有两本评分4和5的书。
出版者B有两本评分1和4的书。
出版者C有一本评分1的书。
以下是一个使用 Count 聚合的示例:
>>> a, b = Publisher.objects.annotate(avg_rating=Avg("book__rating")).filter(
... book__rating__gt=3.0
... )
>>> a, a.avg_rating
(<Publisher: A>, 4.5) # (5+4)/2
>>> b, b.avg_rating
(<Publisher: B>, 2.5) # (1+4)/2
>>> a, b = Publisher.objects.filter(book__rating__gt=3.0).annotate(
... avg_rating=Avg("book__rating")
... )
>>> a, a.avg_rating
(<Publisher: A>, 4.5) # (5+4)/2
>>> b, b.avg_rating
(<Publisher: B>, 4.0) # 4/1 (book with rating 1 excluded)
第一个查询请求至少有一本评分3以上的书籍的出版者的书籍平均分。第二个查询只请求评分3以上的作者书籍的平均评分。
order_by()
annotate() 子句之后可以用order_by()排序,因为注释相当于查询对象结果的一个属性了。
例如,要按参与书籍创作的作者数量对书籍的 QuerySet 进行排序:
>>> Book.objects.annotate(num_authors=Count("authors")).order_by("num_authors")
values()
通常,注解值会添加到每个对象上,即一个被注解的 QuerySet 将会为初始 QuerySet 的每个对象返回一个结果集。然而,当使用 values() 子句来对结果集进行约束时,生成注解值的方法会稍有不同。不是在原始 QuerySet 中对每个对象添加注解并返回,而是根据定义在 values() 子句中的字段组合先对结果进行分组,再对每个单独的分组进行注解,这个注解值是根据分组中所有的对象计算得到的。
通过一个例子对比一下:
查询每个作者所著书的平均评分:
>>> Author.objects.annotate(average_rating=Avg("book__rating"))
使用了values("name")
Author.objects.values("name").annotate(average_rating=Avg("book__rating"))
在这个例子中,作者会按名字分组,所以你只能得到不重名的作者分组后计算出的注释值。如果数据中有两个作者同名,那么他们原本各自的查询结果将被合并到同一个结果中;两个作者的所有评分都将被计算为一个平均分。
annotate() 和 values() 的顺序
和使用 filter() 一样,作用于某个查询的 annotate() 和 values() 子句的顺序非常重要。如果 values() 子句在 annotate() 之前,就会根据 values() 子句产生的分组来计算注解。
然而如果 annotate() 子句在 values() 之前,就会根据整个查询集生成注解。然后 values() 子句只能限制输出的字段。例如:
>>> Author.objects.annotate(average_rating=Avg("book__rating")).values(
... "name", "average_rating"
... )
这段代码将为每个作者添加一个唯一注释,但只有作者姓名和 average_rating 注释会返回在输出结果中。
和 order_by() 一起用会发生化学反应
这里需要注意的一点是order_by()会影响分组。
聚合所生成的注释
你也可以在生成的注释结果上生成聚合。例如,如果您想计算每本书的平均作者数量,您首先要用作者数量对书籍集进行注释,然后对该作者数量进行聚合:
>>> from django.db.models import Avg, Count
>>> Book.objects.annotate(num_authors=Count("authors")).aggregate(Avg("num_authors"))
{'num_authors__avg': 1.66}
在空查询集或组上进行聚合操作时,需要格外小心,因为这可能会导致未定义的行为或错误。在执行聚合操作之前,通常应确保查询集或组中包含足够的数据以执行所需的聚合计算。如果查询集或组为空,可以使用条件语句来避免聚合错误或不必要的操作。
当对空的查询集或分组应用聚合操作时,结果通常默认为其 default 参数,通常是 None。这种行为发生是因为当执行的查询不返回任何行时,聚合函数会返回 NULL。
原文链接:https://blog.csdn.net/chengyikang20/article/details/136474554
======================================================
source: https://blog.csdn.net/qq_33867131/article/details/82754778
1、filter() 将满足条件的数据提取出来
取出id大于2 且 id不等于3 的图书
books = Book.objects.filter(id__gte=2).filter(~Q(id=3))
2、exclude() 将满足条件的数据剔除
books = Book.objects.filter(id__gte=2).exclude(id=3)
3、order_by() 将满足条件的数据进行排序
articles = Article.objects.filter(title='2').order_by('-create_time')
4、values(): 指定返回哪些字段,返回值是:字段和值形成的字典{"title":"xxx", "content":"xxx"}
(1)获取图书的id,name和作者表中的,作者名(Book和Author表外键连接)
books = Book.objects.values("id", "name", "author__name")
=======>>想要给 作者名,换个名字
books = Book.objects.values("id", "name", author_name=F("author__name"))
(2)获取每本书的销量(这里和annotate场景类似,感觉这样更好用一点)
books = Book.objects.values("id", "name", sales=Count("bookorder__id"))
5、values_list(): 用法和values()一样,但是返回值是元组('xxx', 'xxx')
books = Book.objects.values_list("name", flat=True) =====>> 返回结果:红楼梦
如果只指定一个字段,那么我们可以指定'flat=True',这样返回回来的结果就不再是一个元组,而是这个
字段的值,'flat=True'只能用在一个字段的情况下,否则会报错!!!
6、select_related():提取某个模型的数据的同时,也提前将相关联的数据提取出来(只能用在一对多或者一对一中)
获取图书的作者(Book和Author表外键连接)
(1)先得到图书表的所有数据,再 . 出作者(这个方法很耗性能,每 . 一下,就会执行一次查询语句)
books = Book.objects.all()
for book in books:
print(book.author.name)
(2)查出图书表的所有信息和关联表中作者的所有信息,存储在内存中,再取时就直接从内存中去取,而不用再
执行sql语句,大大优化了性能
books = Book.objects.select_related("author")
for book in books:
print(book.author.name)
7、prefetch_related():这个方法和select_related非常的类似,就是在访问多个表中的数据的时候,
减少查询的次数(只能用在多对一和多对多中)
(1)先查找出所有的图书信息 --> 再查出每本书的订单信息(每一次bookorder_set,都会执行一次查询语句)
# 先查找出所有的图书信息
books = Book.objects.all()
for book in books:
# 再查出每本书的订单信息
orders = book.bookorder_set.all()
for order in orders:
print(order.id)
(2)查找出所有的图书信息和查出每本书的订单信息存储在内存当中
books = Book.objects.prefetch_related("bookorder_set")
for book in books:
orders = book.bookorder_set.all()
for order in orders:
print(order.id)
8、
defer 过滤掉指定的字段,返回值不是字典,而是模型
only 只提取指定的字段,返回值不是字典,而是模型
articles = Article.objects.defer("title")
articles = Article.objects.only("title")
9、
first() 获取第一条数据
last() 获取最后一条数据
10、exists 如果要判断某个条件的元素是否存在,那么建议使用exists
if Book.objects.filter(name__contains='红楼梦').exists():
print(True)
比使用count更高效:
if Book.objects.filter(name__contains='红楼梦').count() > 0:
print(True)
也比直接判断QuerySet更高效:
if Book.objects.filter(name__contains='红楼梦'):
print(True)
11、distinct() :去除掉重复数据
提取所有销售的价格超过80元的图书,并且删掉那些重复的数据
books = Book.objects.filter(bookorder__price__gte=80).distinct()
12、QuerySet 切片操作
books = Book.objects.all()[1:3]
books = Book.objects.all()[1:3:2] (第三个参数为步长)
======================================================
======================================================
======================================================