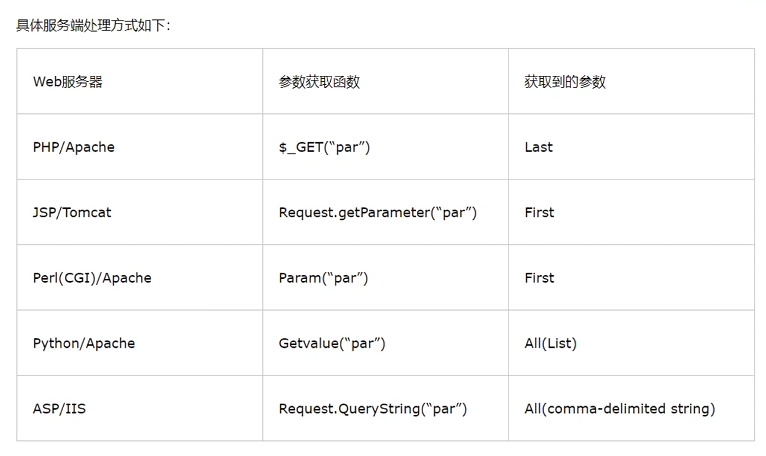
第2章 C#2
2.1 泛型
2.1.1 示例:泛型诞生前的集合
在泛型诞生之前(.NET1),开发者常用如下方式创建集合:
-
数组
-
普通对象集合
如
ArrayList、Hashtable -
专用类型集合
如
StringCollection
// 数组
static string[] GenerateNames()
{string[] names = new string[4];names[0] = "Gamma";names[1] = "Vlissides";names[2] = "Johnson";names[3] = "Helm";return names;
}
static void PrintNames(string[] names)
{foreach (string name in names){Console.WriteLine(name);}
}
// ArrayList
static ArrayList GenerateNames()
{ArrayList names = new ArrayList();names.Add("Gamma");names.Add("Vlissides");names.Add("Johnson");names.Add("Helm");return names;
}
static void PrintNames(ArrayList names)
{foreach (string name in names){Console.WriteLine(name);}
}
// StringCollection
static StringCollection GenerateNames()
{StringCollection names = new StringCollection();names.Add("Gamma");names.Add("Vlissides");names.Add("Johnson");names.Add("Helm");return names;
}
static void PrintNames(StringCollection names)
{foreach (string name in names){Console.WriteLine(name);}
}
在只需要处理 string 类型的情况下,StringCollection 是不二之选。如果需求其他类型集合,而 .NET Framework 又未实现,那只能自己写一个了。为此 .NET 提供了 System.Collections.CollectionBase 抽象类,减少重复工作。
2.1.2 泛型降临
泛型的出现解决了 C#1 中集合无法灵活定义的问题。上节的例子改用 List<T> 后如下:
static List<string> GenerateNames()
{List<string> names = new List<string>();names.Add("Gamma");names.Add("Vlissides");names.Add("Johnson");names.Add("Helm");return names;
}
static void PrintNames(List<string> names)
{foreach (string name in names){Console.WriteLine(name);}
}
2.1.2.1 类型形参与类型实参
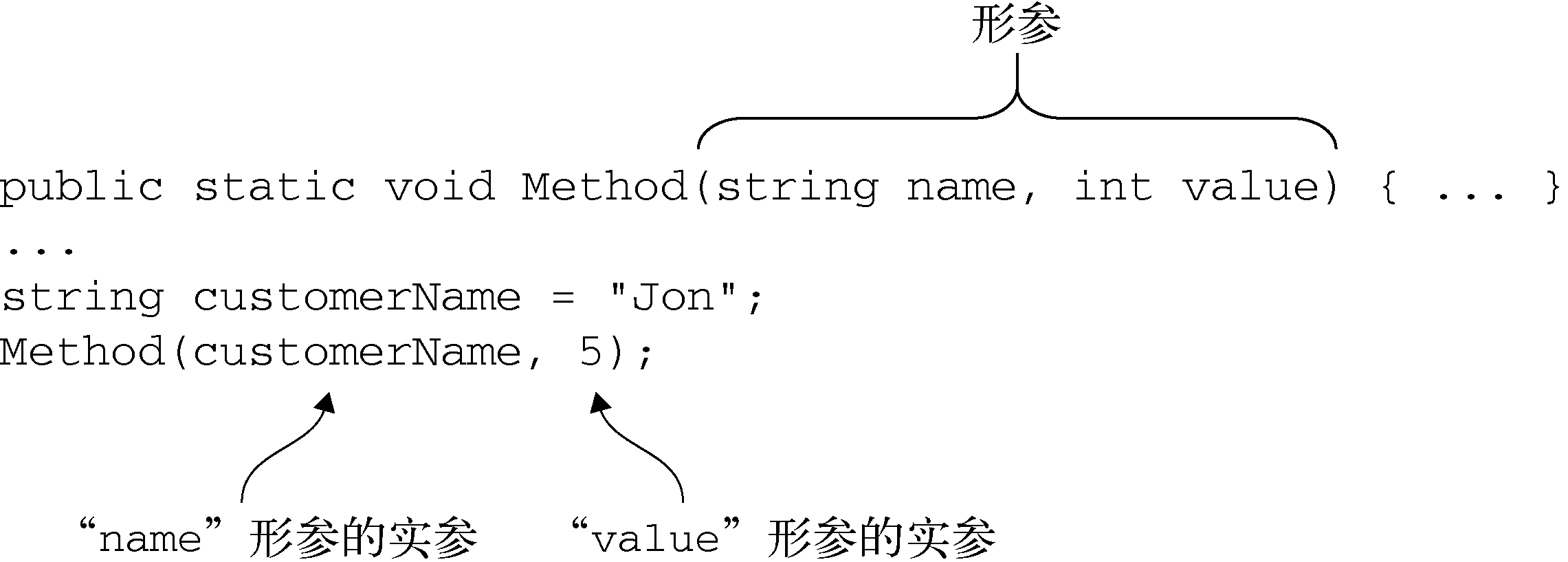
形参(parameter)和实参(argument)的概念很早便出现了:
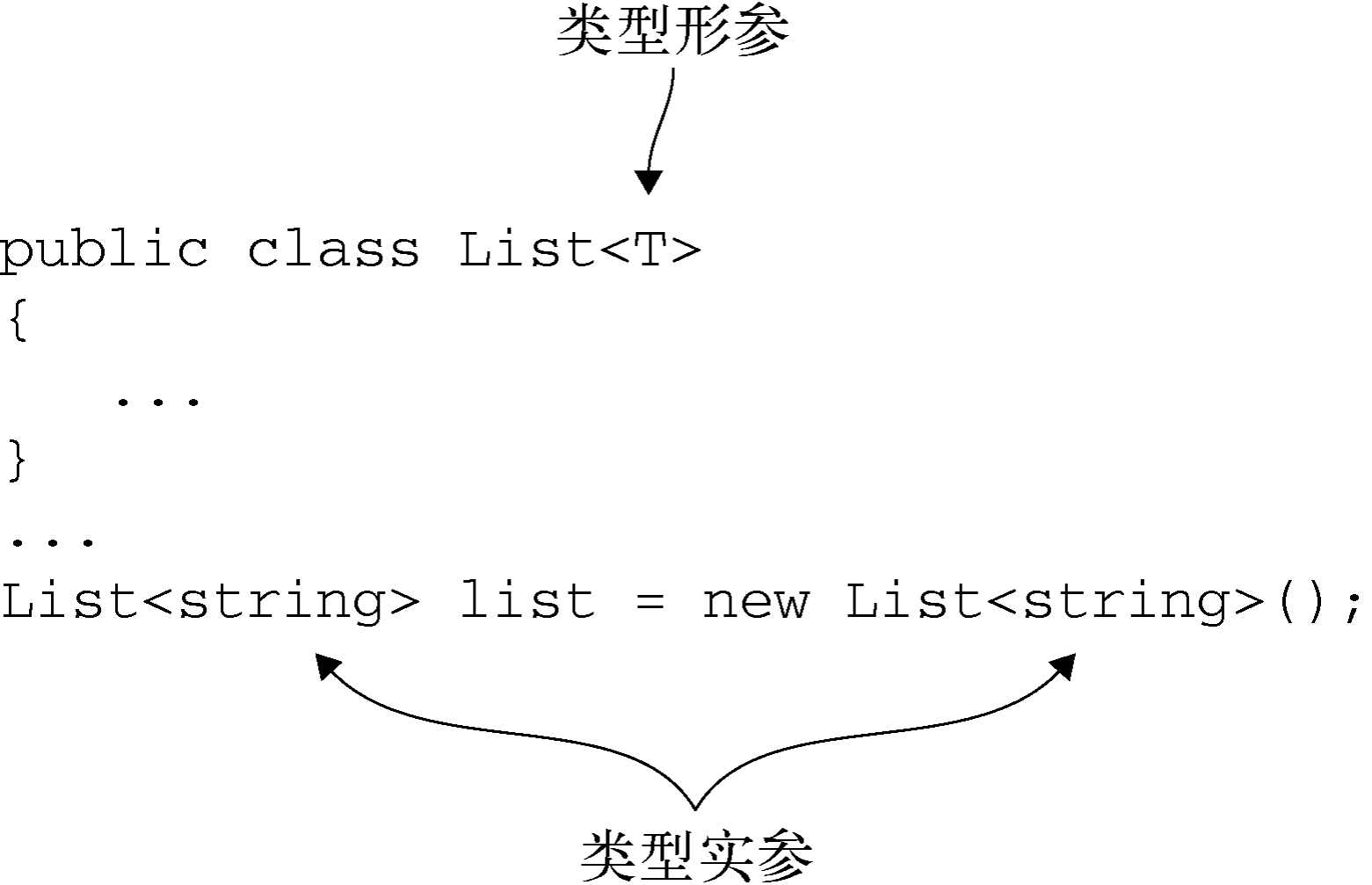
相对的,泛型也引入了两个参数概念:** 类型形参 (type parameter)和 类型实参 **(type argument):
2.1.2.2 泛型类型和泛型方法的度
泛型度(arity)是泛型声明中类型形参的 数量 。我们可将非泛型的声明视为泛型度为 0 。
泛型度是区分同名泛型声明的有效指标。以如下声明为例,这三个方法的泛型度各不相同:
深入解析C(第4版).pdf - p49 - 深入解析C(第4版)-P49-20250103160834-4zfnnwn

需要注意的是,多个类型形参 不能 采用相同的名字(类似于不同参数不能同名)。以下声明是 非法 的:
public void Method<T, T>() {}
2.1.3 泛型的使用范围
对于类型,泛型适用于:
| 类型 | 是否适用 |
|---|---|
| 枚举 | ❌ |
| 类 | ✅ |
| 结构体 | ✅ |
| 接口 | ✅ |
| 委托 | ✅ |
对于成员,泛型仅适用于 方法 。以下类型成员不能是泛型:
- 字段
- 属性
- 索引器
- 构造器
- 事件
- 终结器
有些类型成员适用了其他泛型类型,看似是泛型成员,实则 不是 。只需记住一条原则:判断一个声明是否是泛型声明的唯一标准,是看它是否 引入了新的类型形参 。
以如下代码为例,items 实际 不是 泛型成员:
public class ValidatingList<TItem>
{private readonly List<TItem> items = new List<TItem>();
}
2.1.4 方法类型实参的类型推断
对于泛型方法,编译器可以隐式推断出类型实参。以如下代码为例,二者都能正常编译:
public static List<T> CopyAtMost<T>(List<T> input, int maxElements) { ... }List<int> numbers = new List<int>();
...
List<int> firstTwo = CopyAtMost<int>(numbers, 2);
public static List<T> CopyAtMost<T>(List<T> input, int maxElements) { ... }List<int> numbers = new List<int>();
...
List<int> firstTwo = CopyAtMost(numbers, 2);
需要注意,编译器只能推断出传递给方法的类型实参,但推断不出 返回值 的类型实参。
类型推断在简化泛型类型实例的创建方面很有帮助。以 .NET4.0 的元组为例,其 Create() 工厂方法通过隐式推断获取实例更为简洁:
public static Tuple<T1> Create<T1>(T1 item1)
{return new Tuple<T1>(item1);
}
public static Tuple<T1, T2> Create<T1, T2>(T1 item1, T2 item2)
{return new Tuple<T1, T2>(item1, item2);
}
试比较如下两段代码,显然使用工厂方法更为简洁(泛型类型推断不适用于构造器):
new Tuple<int, string, int>(10, "x", 20)
Tuple.Create(10, "x", 20)
如果推断的类型不是我们想要的类型,我们可以通过 显式类型转换 进行限制,或显式指定类型实参:
// 目标类型为 Tuple<int, object, int>
Tuple.Create<int, object, int>(10, "x", 20);
// or
Tuple.Create(10, (object) "x", 20)
// 目标类型为 Tuple<string, int>
Tuple.Create((string) null, 50)
2.1.5 类型约束
泛型约束可以:
- 约束方法实参的值的 类型
- 约束方法内部如何 操作、使用
T 类型的值
以如下代码为例,它限制 T 必须实现 IFormattable 接口
static void PrintItems<T>(List<T> items) where T : IFormattable
{CultureInfo culture = CultureInfo.InvariantCulture;foreach (T item in items){Console.WriteLine(item.ToString(null, culture));}
}
类型约束适用的范围
类型约束适用于:
接口约束
语法为: where T : SomeInterface
引用类型约束
语法为: where T : class
class 关键字表示任何引用类型,包括接口、委托。
值类型约束
语法为: where T : struct
类型实参必须是非可空类型(结构体或枚举),可空类型不适用于本约束。
构造器约束
语法为: where T : new()
转换约束
语法为: where T : SomeType
此处 SomeType 可以是 类 、 接口 或其他 类型形参 :
-
where T : Control -
where T : IFormattable -
where T1 : T2
类型约束 可以 组合使用,组合规则比较复杂,此处不再赘诉。如果违法了相关规则,编译器会给出明确的错误信息。
多个类型形参的泛型约束
一个声明存在多个类型形参时,每个类型形参都可以有各自的类型约束:
TResult Method<TArg, TResult>(TArg input)where TArg : IComparable<TArg>where TResult : class, new()
2.1.6 default 运算符和 typeof 运算符
2.1.6.1 default 运算符
default 运算符是一元运算符,返回传入类型的默认值。引用类型默认值为 null ;非可空值类型,返回对应类型的“ 0 值”(0、0.0、0.0n、false、UTF-16 编码的单元 0 等);可空值类型,返回 该类型的 null 值 。
default 可 用于泛型类型。下面几种形式均合法:
-
default(T) -
default(int) -
default(string) -
default(List<T>) -
default(List<List<string>>)
2.1.6.2 typeof 运算符
typeof 运算符的使用相对复杂,可以分为 5 种情况(如下例子假设 T 实际传入的是 double 类型):
| 情形 | 例子 | 返回内容 |
|---|---|---|
| 不涉及泛型类型 | typeof(string) |
String |
| 涉及泛型类型,不涉及类型形参 | typeof(List<int>) |
List<Int32> |
| 仅涉及类型形参 | typeof(T) |
Double |
| 涉及泛型,且泛型作为类型形参 | typeof(List<TItem>) |
List<Double> |
| 涉及泛型,但操作数中不含类型实参 | typeof(List<>) |
List<T> |
上述例子中,List<> 的写法仅在 typeof 中是有效的。如果参数多于一个,每增加一个参数就 增加一个逗号 。如 Dictionary<TKey, TValue> 的泛型定义,要写成 typeof(Dictionary<,>)
2.1.7 泛型类型初始化与状态
对于泛型类型,每个封闭的、已构造类型都会被单独初始化,并且拥有各自的静态域。
以如下代码为例,string 和 int 最终对应的计数值为 2 、 1 ,且静态构造函数执行了 2 次:
class GenericCounter<T>
{private static int value;static GenericCounter(){Console.WriteLine("为 {0} 类型初始化计数器", typeof(T));}public static void Increment(){value++;}public static void Display(){Console.WriteLine("{0} 类型的计数为: {1}", typeof(T), value);}
}
class GenericCounterDemo
{static void Main(){GenericCounter<string>.Increment();GenericCounter<string>.Increment();GenericCounter<string>.Display();GenericCounter<int>.Display();GenericCounter<int>.Increment();GenericCounter<int>.Display();}
}
如果泛型类型进一步嵌套,问题将更加复杂。以如下代码为例,右侧所示的 4 种类型都是 独立 的,各自拥有 value 字段。:
class Outer<TOuter>
{class Inner<TInner>{static int value;}
}
-
Outer<string>.Inner<string> -
Outer<string>.Inner<int> -
Outer<int>.Inner<string> -
Outer<int>.Inner<int>
2.2 可空值类型
2.2.2 CLR 和 framework 的支持:Nullable<T> 结构体
可空值类型背后的核心要素是 Nullable<T> 结构体,该结构体的一个早期版本如下:
public struct Nullable<T> where T : struct
{private readonly T value;private readonly bool hasValue;public Nullable(T value){this.value = value;this.hasValue = true;}public bool HasValue { get { return hasValue; } }public T Value{get{if (!hasValue){throw new InvalidOperationException();}return value;}}
}
深入解析C(第4版).pdf - p60 - 深入解析C(第4版)-P60-20250106133511-nqgnlww
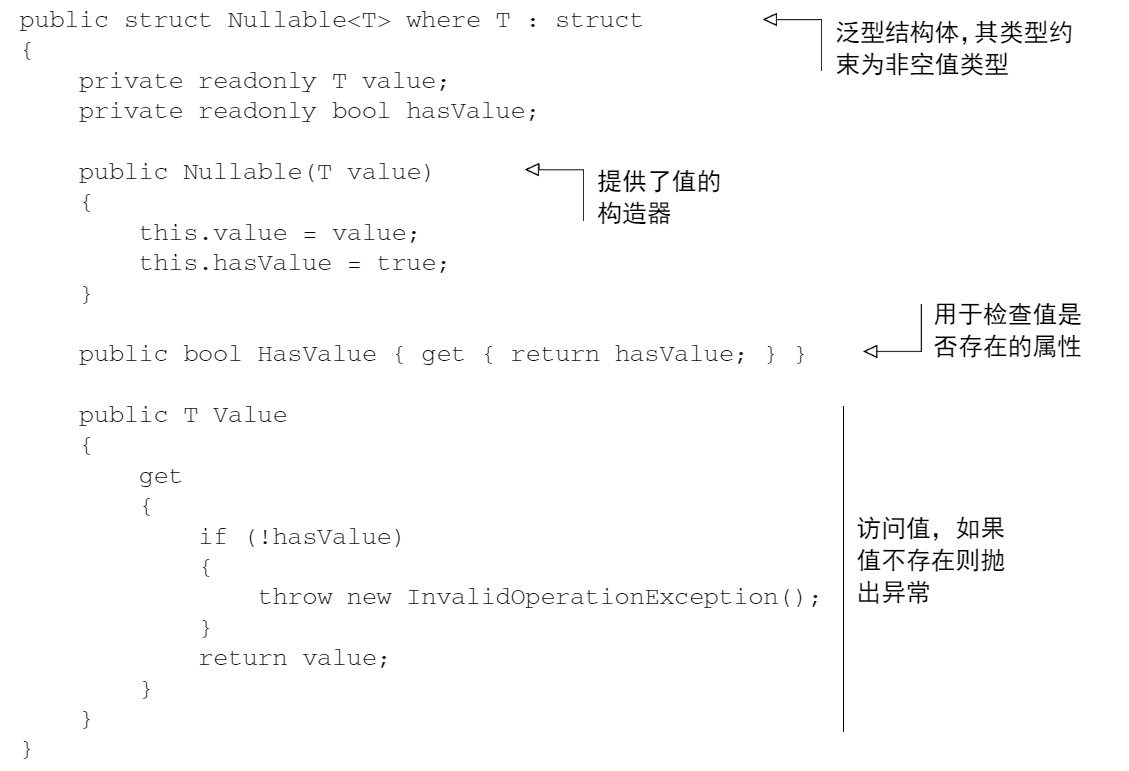
其中 where T : struct 约束 T 只能是除 Nullable<T> 外的任意值类型。此外,Nullable<T> 还提供了如下这些方法和运算符:
-
GetValueOrDefault()、GetValueOrDefault(T defaultValue) 方法 -
重写了
object 类的 Equals(object) 和 GetHashCode() 方法其行为更加明确:先比较
HasValue 属性;当两个对象的HasValue 均为 true ,再比较 Value 属性是否相等。 -
支持
T 到Nullable<T> 的隐式类型转换 -
支持
Nullable<T> 到 T 的显式类型转换当
HasValue 为 false 时则抛出 InvalidOperationException 异常。该转换等同于使用 Value 属性。
Eureka
我们与其说
where T : struct 是不允许Nullable<T>,倒不如说是不允许“可为 null 的类型”。如下代码编译器会报 编译器错误 CS0453 - C# | Microsoft Learn:Nullable<Nullable<int>> value = new();该限制仅对
Nullable<T> 有效(应该是编译器打了洞),我测试自定义的可空类型并不会有该错误:MyNullable<MyNullable<int>> value = new(); Nullable<MyNullable<int>> value2 = new();public struct MyNullable<T> where T : struct {private readonly T value;private readonly bool hasValue;public MyNullable(T value){this.value = value;this.hasValue = true;}public bool HasValue { get { return hasValue; } }public T Value{get{if (!hasValue){throw new InvalidOperationException();}return value;}} }
2.2.2.1 装箱行为
普通值类型(这里指非可空值类型)和可空值类型面对装箱行为稍有不同。
-
普通值类型:以
int 类型为例,装箱前后调用GetType() 方法返回的结果和typeof(int) 相同 :// x.GetType() 和 o.GetType() 得到的类型相同。 int x = 5; object o = x; -
可空值类型:没有对等的装箱类型。装箱结果视
HasValue 属性值决定:- false:装箱后为 null 引用
- true:装箱后为
T 对象的 引用
Nullable<int> noValue = new Nullable<int>(); object noValueBoxed = noValue; Console.WriteLine(noValueBoxed == null); Console.WriteLine(noValueBoxed.GetType()); // 抛出 NullReferenceExceptionNullable<int> someValue = new Nullable<int>(5); object someValueBoxed = someValue; Console.WriteLine(someValueBoxed.GetType());深入解析C(第4版).pdf - p62 - 深入解析C(第4版)-P62-20250106155158-8bf8rws

Tips
值类型调用
GetType() 方法有一个副作用:总会触发一次 装箱操作 。这是因为object.GetType() 方法是非虚方法(不能重写)。该行为多少会影响效率(但不至于造成困扰)。
2.2.3 语言层面支持
2.2.3.1 ? 后缀
C# 为 Nullable<T> 提供了一个简化版写法,即在类型名后添加 ? 后缀。下面 4 个声明完全等价:
-
Nullable<int> x; -
Nullable<Int32> x; -
int? x; Int32? x;
2.2.3.2 null 字面量
C#1 中 null 表达式永远代指一个 null 引用 。C#2 因引入了可空类型,null 的含义发生了扩展:
- 表示一个 null 引用
- 或者表示一个
HasValue 为 false 的 可空类型 的值。
null 引用和可空值类型不容易辨明。如下两行代码 是 等价的(第 二 种更常用):
int? x = new int?();
int? x = null;
我们判断可空类型是否有值可用如下两种方式(根据编码习惯选择,没有优劣):
if (x != null)
if (x.HasValue)
2.2.3.3 转换
前面我们提到 T 和 Nullable<T> 之间有隐式/显式转换。此外,C# 还允许链式转换:对于任意两个非空的值类型 S 和 T,如果存在从 S 到 T 的类型转换(如 int 转为 decimal),则以下类型转换都是合法的:
-
Nullable<S> 到Nullable<T> 的类型转换( 显式转换或隐 式转换,视 S 到 T 的转换类型而定); -
S 到Nullable<T> 的类型转换(同上); -
Nullable<S> 到T 的 显 式类型转换。
上述转换的原理是:将 S 到 T 按照要求进行转换,并为其填充空值。这种操作被称为** 提升 (lifting**)
Notice
无论是可控值还是非可空值,都可以进行显式类型转换。LINQ to XML 很好的利用了该特性。见10.6.2.1 XML 对象与空运算符
2.2.3.4 提升运算符
C# 允许对如下运算符进行重载:
一元运算符 + - ! ~ ++ --四则运算 + - * / %位运算 & | ^ << >>比较 == != > < >= <=
深入解析C(第4版).pdf - p64 - 深入解析C(第4版)-P64-20250106175336-fep62gz
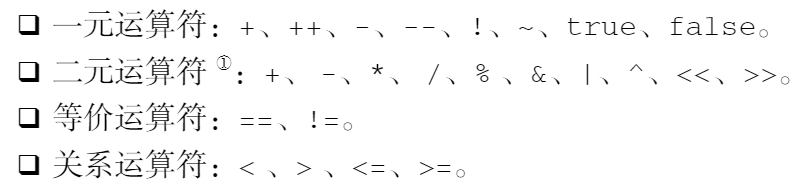
Nullable<T> 重载了 T 所重载的上述运算符。不过在可空类型中,这些运算符的操作数类型、返回值类型与非可空类型有所区别,因此被称为“** 提升 运算符**”。提升运算符要遵循如下规则:
-
true 和 false 运算符 不能 被提升;
但二者很少用,因此影响不大。
Info
关于 true、false 运算符,见4.14.4 重载 true 和 false
-
只有操作数是 非可空值 类型的运算符才能被提升;
-
对于一元运算符和二元运算符(即四则运算和位运算),原运算符的返回类型必须是 非可空的值 类型;
-
对于等价运算符和关系运算符(即比较运算),原运算符的返回类型必须是
bool 类型; -
作用于
Nullable<bool> 的& 和| 运算符具有单独定义的行为,稍后介绍。
上述运算符的运算遵循如下规则:
- 任意一个 操作数为 null,则返回值也为 null;
- 等价运算符和关系运算符(即比较运算)返回值是 非可 空的布尔型;
- 等价运算,两个 null 被视为 相 等,一个 null 和一个非 null 则 不 等;
- 关系运算符,任意一个操作数为 null 时,总是返回 false 。
22.3.4.1 向可空整数应用提升运算符的例子
下面用 int 来举例说明。我们假定有 3 个变量:four、five 和 nullInt,它们都是 Nullable<int> 类型,值分别是 4、5、null:
| 表达式 | 提升运算符 | 结果 |
|---|---|---|
-nullInt |
int? -(int? x) |
null |
-five |
int? -(int? x) |
-5 |
five + nullInt |
int? +(int? x, int? y) |
null |
five + five |
int? +(int? x, int? y) |
10 |
four & nullInt |
int? &(int? x, int? y) |
null |
four & five |
int? &(int? x, int? y) |
4 |
nullInt == nullInt |
bool ==(int? x, int? y) |
true |
five == five |
bool ==(int? x, int? y) |
true |
five == nullInt |
bool ==(int? x, int? y) |
false |
five == four |
bool ==(int? x, int? y) |
false |
four < five |
bool <(int? x, int? y) |
true |
nullInt < five |
bool <(int? x, int? y) |
false |
five < nullIn |
bool <(int? x, int? y) |
false |
nullInt < nullInt |
bool <(int? x, int? y) |
false |
nullInt <= nullInt |
bool <=(int? x, int? y) |
false |
2.2.3.5 可空逻辑
下表是 Nullable<bool> 的 4 个逻辑运算符的真值表。其中与(&)或(|)具有特殊行为,列表中额外规则都已加粗:
| x | y | x & y | x | y | x ^ y | !x |
|---|---|---|---|---|---|
| true | true | true | true | false | false |
| true | false | false | true | true | false |
| true | null | null | ** true ** | null | false |
| false | true | false | true | true | true |
| false | false | false | false | false | true |
| false | null |
** false ** | null | null | true |
| null | true | null | ** true ** | null | null |
| null | false | ** false ** | null | null | null |
| null | null | null | null | null | null |
深入解析C(第4版).pdf - p66 - 深入解析C(第4版)-P66-20250107103456-ansmroj

Warn
提升运算符的执行结果是 C#特有的
本节所讨论的提升运算符、类型转换以及
Nullable<bool> 逻辑等特性都是由 C#编译器提供的,而不是由 CLR 或 framework 本身提供的。如果使用 ildasm 工具检查上述可空值运算符的代码,就会发现是编译器创建了所有 IL 代码来进行空值检查,并做出相应处理。
因此,不同语言处理 null 值的方式会有所不同。如果需要在基于.NET 平台的不同语言之间移植代码,就需要格外小心了。例如 Visual Basic 中提升运算符的行为就更接近 SQL:当x 或y 为 null 时,x < y 的结果也为 null 。
2.2.3.6 as 运算符与可空值类型
自 C#2 开始,as 运算符可用于可空值类型(在此之前只能用于 引用 类型)。该运算符的返回值为一个可空类型的值:当原始引用的类型为 null 或与目标类型不匹配时,返回 null 值,或者返回一个有意义的值,示例如下:
static void PrintValueAsInt32(object o)
{int? nullable = o as int?;Console.WriteLine(nullable.HasValue ? nullable.Value.ToString() : "null");
}PrintValueAsInt32(5); // 打印 5
PrintValueAsInt32("some string"); // 打印 null
2.2.3.7 空合并运算符 ??
空合并运算符(??)用于解决这样一个问题:当一个表达式运算结果为 null 时,为变量提供一个 默认 值。
?? 是一个二元运算符,first ?? second 表达式的计算步骤如下:
- 计算
first 表达式; - 若结果不为 null ,则整个表达式的结果等于 first 的计算结果;
- 若结果为 空 ,则继续计算 second 表达式,整个表达式的结果为 second 的计算结果。
空合并运算符还能组合使用:
int? value = x ?? y ?? z;
Notice
如果第一个操作数的类型是可空值类型,第二个操作数是非可空值类型,整个表达式的类型将是 非可空值 类型!例如以下代码是合法的:
int? a = 5; int b = 10; int c = a ?? b;
2.3 简化委托的创建
2.3.1 方法组转换
方法组:即一个或多个同名方法。我们每次对方法的调用就是对方法组的一次使用。以如下代码为例,Console.WriteLine 就是一个方法组,编译器会根据方法的 调用实参 从方法组中选择合适的重载方法进行调用:
Console.WriteLine("hello");
方法组除了被调用,还可以用于委托创建表达式。在 C#1 中,其使用方式为:
private void HandleButtonClick(object sender, EventArgs e) { ... }
// 假设 EventHandler 签名为:public delegate void EventHandler(object sender, EventArgs e)
EventHandler handler = new EventHandler(HandleButtonClick);
C#2 通过方法组转换简化了这一操作:只要委托的签名与方法组中任何一个重载方法 兼容 ,该方法组就可以隐式地转换为该委托类型。上面的例子可以简化为:
EventHandler handler = HandleButtonClick;
这两种方式最终会生成同样的 IL 代码。
2.3.2 匿名方法
匿名方法:无须在创建委托实例前预先编写另一个实体方法(该方法最终还是会出现在 IL 代码中) ,只需在委托中创建内联代码即可。
匿名方法的大体使用步骤是:使用 delegate 关键字,添加 实参列表 (可选),在大括号内编写需要的代码。下面是一个简单的用例:
// 省略了实参列表
EventHandler handler = delegate
{Console.WriteLine("Event raised");
};
EventHandler handler = delegate(object sender, EventArgs args)
{Console.WriteLine("Event raised. sender={0}; args={1}",sender.GetType(), args.GetType());
};
匿名方法真正的威力在闭包中才能得到体现,这部分在介绍 lambda 表达式时会进行讲解,见3.5.2 捕获变量。
2.3.3 委托的兼容性
C#1 创建委托实例时,方法 签名 、 返回值 需要和委托的 签名 、 返回值 完全一致。假设有如下委托声明和方法:
Printer printer = new Printer(PrintAnything);void PrintAnything(object obj)
{Console.WriteLine(obj);
}public delegate void Printer(string message);
因 Printer 委托的参数和 PrintAnything 的参数不一致,上述代码在 C#1 中是不合法的。C#2 开始支持了这种转换。
此外,只要委托的签名兼容,委托可以通过 委托 创建:
public delegate void GeneralPrinter(object obj);GeneralPrinter generalPrinter = ...; // 创建任意委托
Printer printer = new Printer(generalPrinter); // 构建一个 Printer 来封装 GeneralPrinter
同样的,只要返回值类型兼容,委托可以通过 委托 创建:
public delegate object ObjectProvider(); // 无参委托
public delegate string StringProvider(); // 有返回值StringProvider stringProvider = ...; // 创建任意 StringProvider 委托
ObjectProvider objectProvider = new ObjectProvider(stringProvider);
Eureka
其实这部分内容涉及逆变和协变
需要注意的是,参数/返回值之间的兼容性必须满足“一致性转换”规则。以如下代码为例,它无法通过编译:
public delegate void Int32Printer(int x);
public delegate void Int64Printer(long x);Int64Printer int64Printer = ...;
Int32Printer int32Printer = new Int32Printer(int64Printer);
2.4 迭代器
2.4.1 迭代器简介
迭代器:包含迭代器块的方法或属性。
迭代器块:(本质上是)包含 yield return 或 yield break 语句的代码,只能用于以下返回类型的方法或属性:
-
IEnumerable -
IEnumerable<T> (T 可以是类型形参,也可以是普通类型) -
IEnumerator -
IEnumerator<T> (T 可以是类型形参,也可以是普通类型)
迭代器用到的语句有:
-
yield return 语句:用于生成返回序列的各个值 -
yield break 语句:用于终止返回序列
下面是一个简单的迭代器例子:
static IEnumerable<int> CreateSimpleIterator()
{yield return 10;for (int i = 0; i < 3; i++){yield return i;}yield return 20;
}
2.4.2 延迟执行
迭代器的特点之一是它是延迟执行的。我们以前一节的迭代器为例,下面是一段针对它的消费代码:
IEnumerable<int> enumerable = CreateSimpleIterator();
using (IEnumerator<int> enumerator = enumerable.GetEnumerator())
{while (enumerator.MoveNext()){int value = enumerator.Current;Console.WriteLine(value);}
}
static IEnumerable<int> CreateSimpleIterator() {yield return 10;for (int i = 0; i < 3; i++){yield return i;}yield return 20; }
断点调试时我们会发现:CreateSimpleIterator()、GetEnumerator() 方法被调用后根本不会触发断点,只有 MoveNext() 被调用时才会真正开始执行。
Info
延迟执行(也称延迟计算)属于 lambda 演算的一部分,于 20 世纪 30 年代被提出。其基本思想十分简单:只在需要获取计算结果时执行代码。
2.4.3 执行 yield 语句
当如下几种情形之一发生时,代码会终止执行:
-
抛出异常;
异常会正常流转。需要注意的是,抛出异常的是
MoveNext() 方法! -
方法执行完毕;
MoveNext() 方法返回 false -
遇到
yield break 语句;
MoveNext() 方法返回 false -
执行到
yield return 语句,迭代器准备返回值。
Current 属性被赋以当前迭代值,MoveNext() 方法返回 true 。
2.4.4 延迟执行的重要性
以打印斐波那契数列为例,迭代器的延迟执行的优势可以得到很大发挥:
static IEnumerable<int> Fibonacci()
{int current = 0;int next = 1;while (true) // 只有无限次请求时才会变成无限循环{yield return current; // 生成当前的斐波那契值int oldCurrent = current;current = next;next = next + oldCurrent;}
}static void Main()
{foreach (var value in Fibonacci()){Console.WriteLine(value);if (value > 1000){break;}}
}
从上面的例子可以看到:迭代器可以按需执行,使用者可以根据需要灵活调用 Fibonacci() 方法。
2.4.5 处理 finally 块
我们以如下迭代器为例,思考:“在 finally 块中”这句输出会在第一次 yield 后打印吗?
static IEnumerable<string> Iterator()
{try{Console.WriteLine("第一次 yield 前");yield return "first";Console.WriteLine("两次 yields 间");yield return "second";Console.WriteLine("第二次 yield 后");}finally{Console.WriteLine("在 finally 块中");}
}
答案是:不会。迭代器对 finally 的处理逻辑如下:
- 每次执行至
yield return 语句时,执行就会 暂停 ,(逻辑上讲)执行此时还停留在 try 块中。
foreach 遍历迭代器时会起到 using 语句的作用(参见4.6.1 可枚举类型)。如下两段消费代码等价,都会输出“在 finally 块中”:
foreach (string value in Iterator())
{Console.WriteLine("Received value: {0}", value);if (value != null){break;}
}
IEnumerable<string> enumerable = Iterator();
using (IEnumerator<string> enumerator = enumerable.GetEnumerator())
{while (enumerator.MoveNext()){string value = enumerator.Current;Console.WriteLine("Received value: {0}", value);if (value != null){break;}}
}在调用 Dispose() 方法时,即时迭代器还暂停在 try 块中也无妨,Dispose() 方法会最终调用 finally 块,非常智能。
2.4.6 处理 finally 的重要性
finally 块的处理对迭代器意义重大,它意味着:
-
迭代器可以用于那些需要 释放资源 的方法;
如文件处理器
-
相同目的的迭代器可以 链接 起来使用
如 LINQ to Objects
下面是一个使用迭代器读取文件的例子:
static IEnumerable<string> ReadLines(string path)
{using (TextReader reader = File.OpenText(path)){string line;while ((line = reader.ReadLine()) != null){yield return line;}}
}
通过迭代器我们只需打开文件 一 次。不过它也有缺点:因文件不存在/不可读导致抛出异常会延迟至 MoveNext() 方法调用时,导致不及时。
Tips
.NET4.0 引入了
File.ReadLines() 方法,功能与之类似。
Notice
需要注意的是,非泛型的
IEnumerator 接口并未扩展自IDisable 接口(IEnumerator<T> 接口扩展自IDisable、IEnumerator 接口),foreach 循环会自行检查迭代器是否实现了IDisposable,并根据需要调用Dispose() 方法。开发者如果手动调用
MoveNext() 方法进行迭代,对于非泛型版IEnumerator,需要手动判断是否实现IDisposable 接口,并调用Dispose() 方法;对于泛型版IEnumerator<T>,直接使用 using 语句即可。
2.4.7 迭代器实现机制概览
Info
更多细节请参考Iterator 块实现细节:自动生成的状态机
迭代器明面上是调用了 yield return、yield break 的方法,实际上编译器会为它生成一个全新的类型以实现相关接口。我们编写的方法体会被移动至生成类型的 MoveNext() 方法中。
以如下迭代器代码为例:
public static IEnumerable<int> GenerateIntegers(int count)
{try{for (int i = 0; i < count; i++){Console.WriteLine("Yielding {0}", i);yield return i;int doubled = i * 2;Console.WriteLine("Yielding {0}", doubled);yield return doubled;}}finally{Console.WriteLine("In finally block");}
}
编译器生成的代码(反编译后、已简化)有:
public static IEnumerable<int> GenerateIntegers( // 原方法声明签名的int count) // 桩方法
{GeneratedClass ret = new GeneratedClass(-2);ret.count = count;return ret;
}
private class GeneratedClass // 表示状态机的: IEnumerable<int>, IEnumerator<int> // 生成类
{public int count; //private int state; // 状态机中所有不同private int current; // 功能的字段private int initialThreadId; //private int i; //public GeneratedClass(int state) // 桩方法和 GetEnumerator() 方法都会调用的构造器{this.state = state;initialThreadId = Environment.CurrentManagedThreadId;}public bool MoveNext() { ... } // 状态机的主体代码public IEnumerator<int> GetEnumerator() { ... } // 用于创建新的状态机public void Reset() // 生成的迭代器不支持 Reset 操作{throw new NotSupportedException();}public void Dispose() { ... } // 根据需要执行 finally 块public int Current { get { return current; } } // 用于返回最后生成值的属性private void Finally1() { ... } // MoveNext() 和 Dispose() 方法中使用的 finally 块主体IEnumerator Enumerable().GetEnumerator() //{ //return GetEnumerator(); // 显式实现的} // 非泛型接口成员//object IEnumerator.Current { get { return current; } } //
}
从上述代码可以看到,编译器根据迭代器生成了一个** 状态机 **(一个私有嵌套类),状态机包含了:
-
方法当前执行位置 指示器 。
该指示器与 CPU 的指令计数器类似,用于区分若干种状态;
-
所有 参数 的一份复本;
-
方法体中定义的局部变量;
-
最近一次生成的值。
调用迭代器时会执行以下操作:
- 调用
GetEnumerator() 来获得IEnumerator<int> - 反复调用
MoveNext() 并访问IEnumerator<int> 中的Current 属性,直到MoveNext() 返回 false - 在需要清理内存时调用
Dispose() 方法,无论是否有异常抛出。
Info
生成的迭代器不支持 Reset 操作,关于 Reset 的作用,见7.1.1 IEnumerable 和 IEnumerator
MoveNext() 方法实现概览
MoveNext() 的大致结构如下:
public bool MoveNext()
{try{switch (state){// 跳转表负责跳转到方法中的正确位置}// 方法代码在每个 yield return 都会返回}fault // 只有发生异常时 fault 块的代码才会执行,它是 IL 中专有的结构{Dispose(); // 发生异常后清理资源}
}
状态机包含了一个变量(state)用于记录当前执行位置。变量的具体值随不同的实现有所差别。以 Roslyn 编译器为例,状态值如下所示。
- −3:
MoveNext() 当前正在执行。 - −2:
GetEnumerator() 尚未被调用。 - −1:执行完成(无论成功与否)。
- 0:
GetEnumerator() 已被调用,但是MoveNext() 还未被调用(方法的开始)。 - 1:在第 1 条
yield return 语句。 - 2:在第 2 条
yield return 语句。
MoveNext() 的作业逻辑有:
-
利用
state 变量在各个状态间跳转; -
发生异常时:在 fault 块中执行 finally 工作
此处会触发
Dispose() 方法,进而调用finally1() 方法( finally 块中的代码)。 -
正常执行结束:在 try 块的结尾正常调用
Dispose() 方法。
Info
fault 块是一个 IL 结构,在 C# 中没有对等形式,类似于 finally 块。
2.5 一些小的特性
2.5.1 局部类型(partial class)
局部类型(也成为“分布类”)允许单个类、结构体或者接口分成多个部分声明,而且一般分布于多个源文件。局部类型常与代码生成器配合使用,多个代码生成器分别负责不同的声明部分,之后还可以通过手动编码予以强化。
一个简单的示例如下:
partial class PartialDemo
{public static void MethodInPart1(){MethodInPart2(); // 调用第 2 部分声明的方法}
}partial class PartialDemo
{private static void MethodInPart2() // 被第一部分调用的方法{Console.WriteLine("In MethodInPart2");}
}
泛型类有一些额外限制:
- 各部分声明的类型名和类型形参 必须 相同,类型约束(如有) 必须 相同;
类型实现接口时则相对自由:
- 声明的类型若实现了多个接口,这些局部类型 可以 负责各自的接口实现,且实现和声明 可以 不在同一局部类中
2.5.1.1 局部方法(C#3)
局部方法:可以在一个类型的局部声明中声明一个不包含 方法体 的方法,而在另一个局部声明中定义该方法的实现(可选)。
局部方法有如下特点:
-
默认是 私 有方法,返回值必须是 void 且不能使用 out 参数(可以使用 ref 参数);
-
编译时只会保留实现了的局部方法。
如果局部方法只是声明而没有实现,那么会 移除该方法的所有调用代码 。
源生成 器常借助局部方法的特性生成可选的“钩子方法”,开发者可以手动为“钩子方法”添加额外的行为。
下面是局部方法的简单用例:
partial class PartialMethodsDemo
{public PartialMethodsDemo(){OnConstruction(); // 调用尚未实现的局部方法}public override string ToString(){string ret = "Original return value";CustomizeToString(ref ret); // 调用已经实现的局部方法return ret;}partial void OnConstruction(); // 编译时会被移除partial void CustomizeToString(ref string text);
}
partial class PartialMethodsDemo
{// 局部方法的实现partial void CustomizeToString(ref string text){text += " - customized!";}
}
2.5.2 静态类
静态类:使用 static 修饰符修饰的类。
静态类内部不能声明实例方法、属性、事件或构造器;可以声明普通的 嵌套 类。下面是一个简单的示例:
StaticClassDemo.StaticMethod(); // 合法StaticClassDemo localVariable = null; // 非法
List<StaticClassDemo> list = // 非法new List<StaticClassDemo>();static class StaticClassDemo
{public static void StaticMethod() { } // 合法public void InstanceMethod() { } // 非法,静态类不可声明实例方法public class RegularNestedClass // 合法,静态类可以声明普通嵌套类型{public void InstanceMethod() { } // 合法,普通嵌套类型可以声明实例成员}
}
此外,扩展方法(C#3)对于静态类也有特殊要求:只能在非嵌套、非泛型的静态类中声明。
2.5.3 属性的 getter/setter 访问分离
该机制于 C#2 引入:可以通过添加修饰符来让一个访问器比另一个更私有。通常都是让 setter 访问器比 getter 访问器更私有(见5.2 属性的设计)。
下面是一个简单的例子:
private string text;public string Text
{get { return text; }private set { text = value; }
}
2.5.4 命名空间别名
自 C#1 开始,C# 便支持了命名空间和命名空间别名这两个特性,下面是一个简单的用例,用于区分 Windows Forms 和 ASP.NET Web Forms 的两个 Button 类:
using System;
using WinForms = System.Windows.Forms;
using WebForms = System.Web.UI.WebControls;class Test
{static void Main(){Console.WriteLine(typeof(WinForms.Button));Console.WriteLine(typeof(WebForms.Button));}
}
C#2 从 3 个方面扩展了命名空间别名的支持:
- 命名空间别名限定符语法
- 全局命名空间别名
- 外部别名
这部分内容参见《C#7.0 核心技术指南》:
2.12.5.2 命名空间别名限定符
在 2.12.3.3 名称隐藏中提到,内层 namespace 中的名称会隐藏外层 namespace 中的名称,我们可以通过类型的完全限定解决。不过有些情况类型的完全限定也无法解决冲突:
namespace N {class A {public class B{ }static void Main(){new A.B(); // 此处将调用内部类B}} }namespace A {class B{ } }Main 方法将会实例化嵌套类 B 或命名空间 A 中的类 B。编译器总是给当前命名空间中的标识符以更高的优先级;在这种情况下,将会实例化嵌套类 B。
要解决这样的冲突,可以使用“
::”限定命名空间别名,用法如下:1. 全局命名空间(别名 global)
即所有 namespace 的根命名空间(由上下文关键字 global 指定)
namespace N {class A {public class B{ }static void Main(){(new A.B()).GetType().Dump();(new global::A.B()).GetType().Dump();;}} }namespace A {class B{ } }2.一系列的外部别名
此处代码与2.12.5.1 外部别名稍显不同:
extern alias W1; extern alias W2;W1::Widgets.Widget w1 = new W1::Widgets.Widget(); W2::Widgets.Widget w2 = new W2::Widgets.Widget();
2.5.5 编译指令
编译指令:用于为编译器提供额外的信息,实际并不能改变程序行为。
C# 编译器支持:
-
警告指令:主要用于禁用、启用特定警告信息
#pragma warning disable CS0219 int variable = CallSomeMethod(); #pragma warning restore CS0219 -
校验和指令:一般出现在自动生成的代码中
在 C#6 之前,只能使用数字来作为警告的标识。Roslyn 编译器提升了编译流的扩展性,其他包也可以提供警告信息。为此 C# 修改了警告标识规则:
- 允许(且应该)在警告前添加前缀(如使用 CS0219 而非 0219)
Info
关于指令,另见4.16 预处理指令
2.5.6 固定大小的缓冲区
固定大小的缓冲区只能用于 非安全的 代码,并且只能用于 结构体 内部。我们通过 fixed 修饰符完成这一工作。下面是一个简单的例子,它分配了 16byte 的数据:
unsafe struct VersionedData
{public int Major;public int Minor;public fixed byte Data[16];
}
unsafe static void Main()
{VersionedData versioned = new VersionedData();versioned.Major = 2;versioned.Minor = 1;versioned.Data[10] = 20;
}
Info
关于固定大小的缓冲区,另见25.6 将结构体映射到非托管内存中
C#7.3 关于访问大小固定缓冲区字段的改进
上一节的代码展示了如何通过局部变量访问固定大小的缓冲区。假设 versioned 变量不是局部变量,而是一个类的字段,在 C#7.3 之前,需要通过 fixed 语句来创建一个 指针 才能访问 versioned.Data;到了 C#7.3 以后,就可以通过字段直接访问该缓冲区了,不过仍限于 非安全 的上下文中。
unsafe struct VersionedData {public int Major;public int Minor;public fixed byte Data[16]; } unsafe static void Main() {VersionedData versioned = new VersionedData();versioned.Major = 2;versioned.Minor = 1;versioned.Data[10] = 20; }
2.5.7 InternalsVisibleTo(友元程序集)
InternalsVisibleToAttribute 是作用于程序集的特性,它包含一个参数,用于指定另一个程序集。被指定的程序集可以访问当前程序集中的 internal 成员。
下面是用法的简单示例:
[assembly:InternalsVisibleTo("NodaTime.Test,PublicKey=0024...4669"]
该特性常用于:
-
测试程序集测试当前程序集的内部成员;
-
私有工具类访问内部成员,避免代码复制;
-
其他库访问当前库的内部成员
不推荐该场景使用,这致使内部成员修改时代码版本号也需随之更改
Info
关于友元程序集,另见友元程序集