接着我们上次向Spring AI提交的混元模型模块,我已经完成了所有关于混元的聊天对接,并提交了相应的PR描述。提交后,荣获了一张“好人卡”,如图所示:

今天,我们决定将之前提交给Spring AI官方的PR重新拿出来,并准备将其独立维护在一个开源仓库中。做出这一决策的原因是Spring AI官方表示将不再继续维护这么多大模型。这一决定其实也有其合理性,因为Spring AI的核心目标是通过简化Java开发智能体的过程来提升开发效率,而不是承担维护多个大型模型的责任。这种偏离了最初目标的做法,可能会导致资源和精力的过度分散,本末倒置了。
好了,废话不多说,今天我们主要的目标是将相关的代码单独提取出来,并推送到maven中央仓库中,确保它可以被广泛使用和管理。
混元
最初我们打算将这个项目命名为spring-ai-tencent,但经过一番思考后,我们发现这个名字可能会带来一些误解。为了避免这种误解,同时确保名称更加简洁明了,我们决定继续使用spring-ai-hunyuan这个名称。这个名称不仅更容易记住,而且不会引发额外的混淆,
提取代码
第一步就是将写入到Spring AI中的混元对接代码都提取出来,最后结果如图所示:
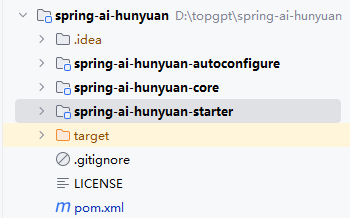
核心模块(core)主要负责与混元的API对接,提供基础的接口和功能。Autoconfigure模块则实现了自动依赖注入功能,使得项目中的相关依赖能够自动装配并正确运行。Starter模块则是专为其他项目提供的依赖包,通过引入Starter模块,其他项目能够快速集成并使用混元模型。
简单测试一下,看下测试用例是否都正常通过了。如图所示:
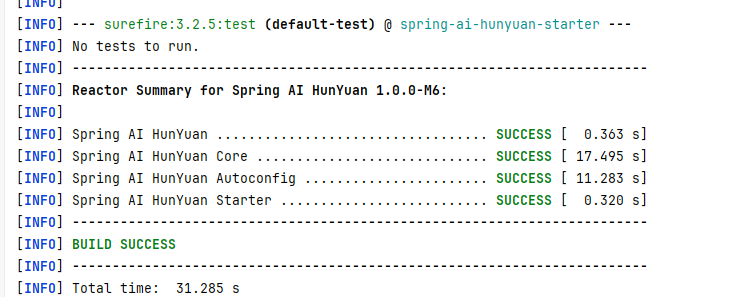
这个过程相对繁琐且没有太多技术含量,因此直接跳过。值得一提的是,我将项目中的所有包名都统一更改为 io.github.studiousxiaoyu,主要是出于发布到 Maven 中央仓库的考虑。由于在向 Maven 仓库提交时,包名必须遵循一定的规范,因此不可以随意命名,后续会详细解释这一点。
注册mvn账户
接下来,我们需要进行 Maven 账户的注册。可以通过以下官方链接进行注册:https://central.sonatype.com/
在注册过程中,只需根据官方页面提供的详细指引进行操作即可。由于注册步骤非常直观且有明确的指导,因此在这里就不再详细说明了。
Namespace
接着,我们就需要弄一个命名空间专门存储我们的开源代码,如图所示:
这里你可以有自己的域名也可以,为了方便我这里直接使用的github仓库地址,gitee也是可以的。如图所示:
添加后,他会给你一长串的id,就是我打马赛克的地方。
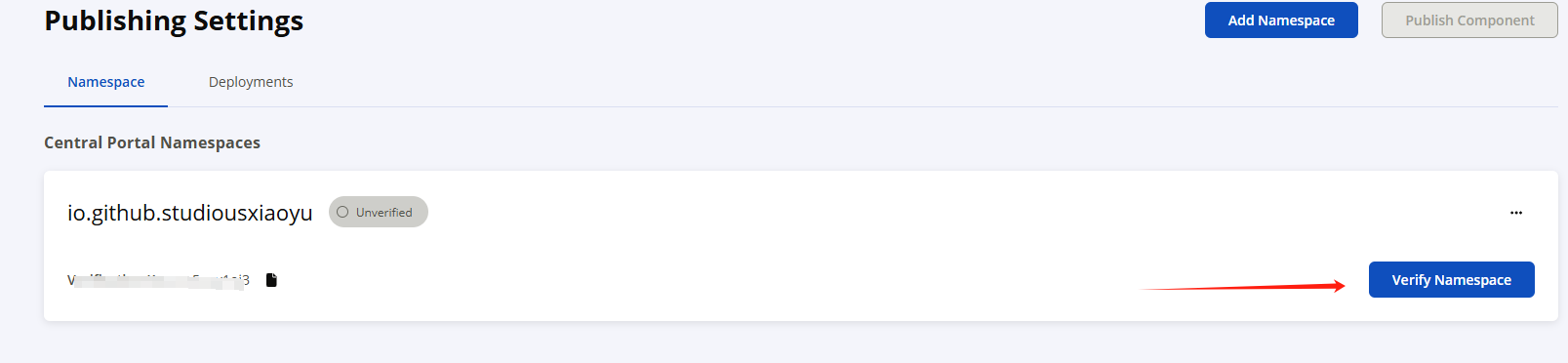
开源仓库
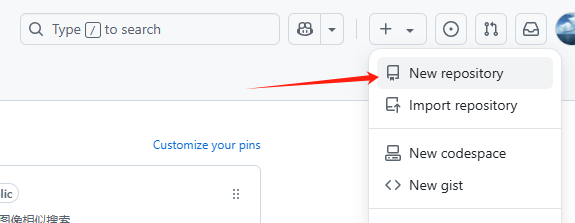
然后,你将这一长串id复制出来,去自己的github仓库创建一个公共开源的仓库即可。如图所示:
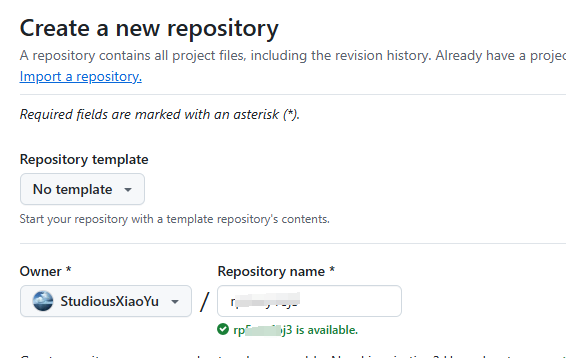
这里不用添加任何文件,空仓库也是没问题的。主要就是他们在验证的时候,看有没有这个仓库地址而已。如图所示:
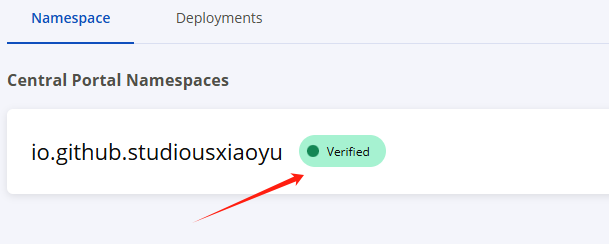
最后,我们稍等一会儿,他就会验证成功了,如图所示:
秘钥信息
前提准备工作已经顺利完成,接下来只需确保你的本地 Maven 环境中配置好一些必要的秘钥信息,主要包括两个关键部分:GPG 密钥和 Maven 账户密码。这是官方要求的必要步骤,只有配置齐全后,才能顺利进行后续的发布或部署操作。
Gpg
先来申请复杂的gpg,本地必须安装下这个软件:https://gnupg.org/download/index.html#sec-1-2
下载的时候,如果有钱就捐,没钱就如图所示:
安装好 GPG 后,由于安装路径没有添加到环境变量中,因此我们需要手动找到 GPG 的安装位置。比如:E:\Program Files (x86)\GnuPG\bin。你可以根据实际安装位置进行调整。
打开cmd命令面板,我们需要生成自己的私钥和公钥:
gpg --gen-key
按照指示创建完成后,再使用命令分发生成的id即可:
gpg --keyserver keyserver.ubuntu.com --send-keys 生成的id
接着在setting.xml中写好自己写的秘钥,注意不是生成的id。
<server><id>gpg.passphrase</id><passphrase>秘钥</passphrase>
</server>
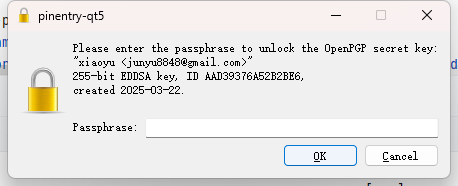
gpg.passphrase是固定的,写好后,进行deploy时会校验这个值。你不用修改成其他的id
如果你没配置这个字段值的话,每次deploy时都会提示如下弹窗让你输入。如图所示:
mvn账户秘钥
在进行申请之前,首先需要在我们项目的 pom.xml 依赖文件中配置好该插件的信息。在配置时,特别需要注意 publishingServerId 属性中的值是可以根据需要进行修改的。具体修改成什么值,需要确保与 Maven 中的 settings.xml 配置文件中的相关值一致。
<build><plugins><plugin><groupId>org.sonatype.central</groupId><artifactId>central-publishing-maven-plugin</artifactId><version>0.7.0</version><extensions>true</extensions><configuration><publishingServerId>central</publishingServerId></configuration></plugin></plugins>
</build>
那么mvn中的setting配置文件写的秘钥,我们也需要申请,官方地址如下:https://central.sonatype.com/account
点击如图所示,生成相关的秘钥信息。如账户和密码。

紧接着我们就需要在mvn中的setting配置文件添加如下信息:
<settings><servers><server><id>central</id><username><!-- your token username --></username><password><!-- your token password --></password></server></servers>
</settings>
没错的,这里的id对应的就是pom文件中的publishingServerId值。
发布
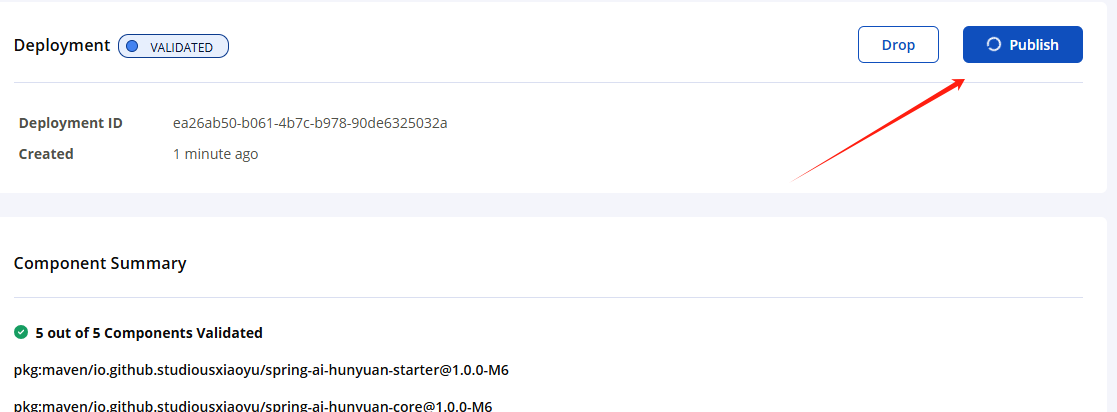
在完成所有相关信息的配置后,我们就可以执行 mvn deploy 指令来开始部署操作。此时,系统将进行一些处理,稍等片刻,当控制台显示部署成功的消息后,我们就可以前往以下网址:https://central.sonatype.com/publishing/deployments
在这个页面上查看我们刚刚推送的 Maven 依赖包是否成功上传并且已被正确发布。效果如图所示:
小结
在本篇文章中,我们详细介绍了将混元模型模块从Spring AI迁移并独立维护的全过程。
首先,介绍了项目命名的思考与调整,选择了更符合开源规范的spring-ai-hunyuan作为最终名称。接着,我们展示了如何提取并整理代码,包括核心模块、自动配置模块和Starter模块的构建。重点还包括了如何在Maven中央仓库上注册账户、配置GPG密钥、申请Maven账户秘钥等细节步骤,确保代码能够顺利发布和管理。
最终,我们通过执行 mvn deploy 命令完成了依赖包的上传,成功将项目推送至Maven中央仓库,为广大开发者提供了一个稳定且可扩展的开源解决方案。