服务器配置为:2个11264MiB NvidiaGPU + 16核 3.8GHz CPU + 72G 内存;部署Ollama平台,使用Qwen-coder2.5:32B模型。
1. 下载、安装并运行ollama;
ollama的安装网上介绍的比较多,此处不再多讲,可以参考 Ollama全面指南:安装、使用与高级定制
若在服务器上部署ollama,确保ollama的对外接口在编辑器所在的主机上可以访问;

2. 下载并安装qwen-coder32b;
在ollama官网上查找模型qwen2.5-coder
在服务器上运行:
ollama run qwen2.5-coder
3. 下载Pychaim插件Proxy-AI
在pychaim的plugin的MarketPlace中搜索Proxy-AI并安装。
4. 配置Proxy-AI
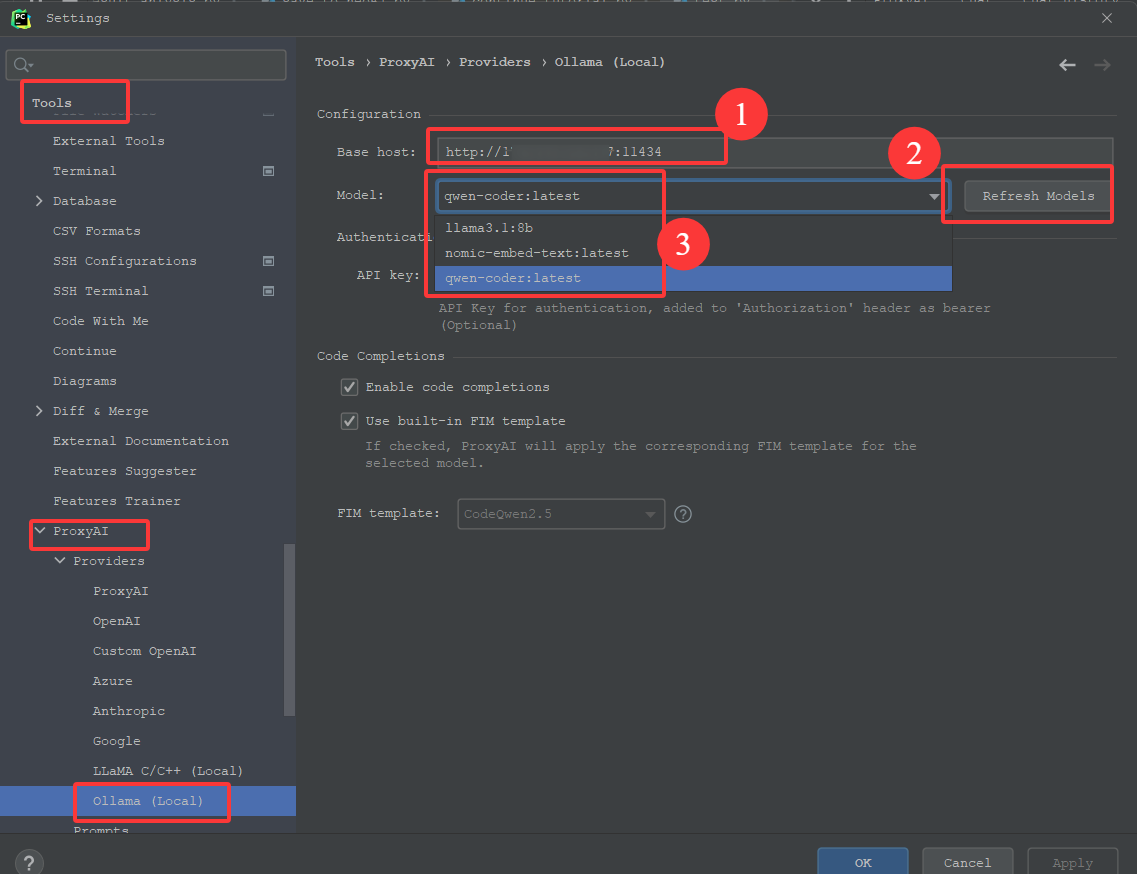
配置好1 Base Host后,点击2 Refresh Model, 3处可以自动显示环境上部署的所有模型,选择自己需要的那个。
注意事项:
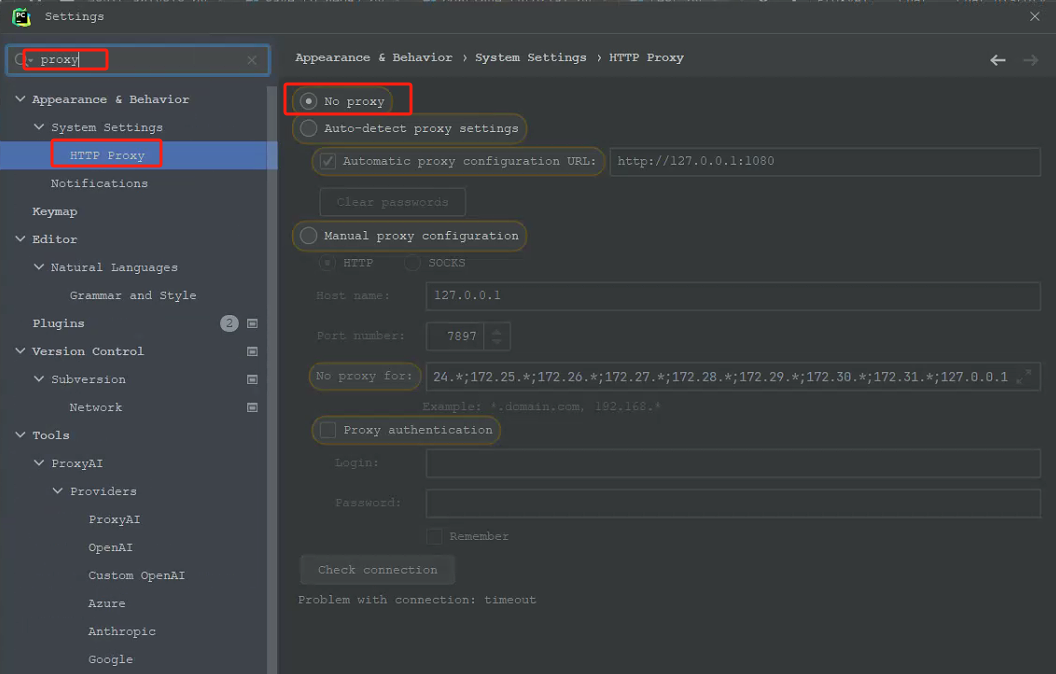
一定要注意Pychaim中的Proxy是否选中了代理,需要选择No Proxy;之前我为了下载插件选择了代理,导致配置好ollama的url中,刷新model一直显示不粗来,为止浪费了2天的时间。
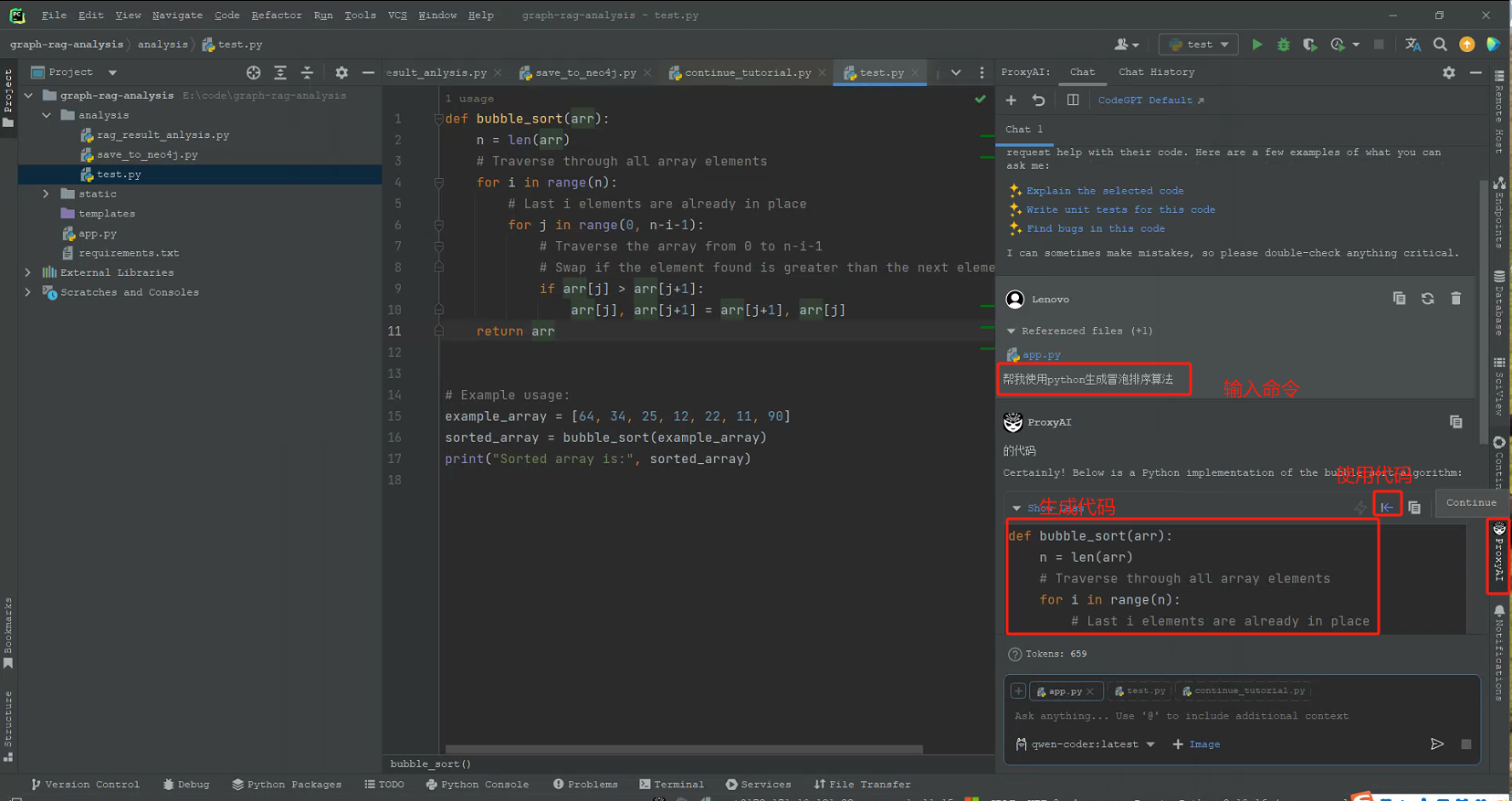
5. 使用Proxy-AI
6.参考
DeepSeek基于Ollama本地部署及集成IDEA
![[Vue] Vue 模板编译原理解析 part3](https://xiejie-typora.oss-cn-chengdu.aliyuncs.com/2023-11-20-063716.png)


![[Windows] TechSweeper 应用程序卸载神器V1.2.1](https://i.postimg.cc/5NmhzMtj/7.gif)