AMD Instinct™MI300系列微架构
AMD Instinct MI300系列加速器基于AMD CDNA 3架构,旨在为HPC、人工智能(AI)和机器学习(ML)工作负载提供领先性能。AMD Instinct MI300系列加速器非常适合极端的可扩展性和计算性能,可以在单个服务器到世界上最大的EB级超级计算机的所有设备上运行。
在MI300系列中,AMD推出了加速器复杂芯片(XCD),其中包含处理器的GPU计算元素以及较低级别的缓存层次结构。
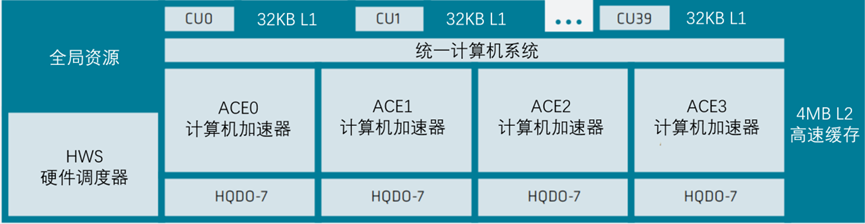
描述了AMD Instinct MI300加速器系列中单个XCD的结构,如图5-7所示。
图5-7 torch.compile可以将Llama 模型的吞吐量提高多达 2.6 倍
XCD级系统架构显示了40个计算单元,每个计算单元具有32KB的L1缓存,一个具有4个ACE计算加速器的统一计算系统,共享4MB的L2缓存和一个HWS硬件调度器。
在XCD上,四个异步计算引擎(ACE)将计算着色器工作组发送到计算单元(CU)。XCD有40个CU:38个处于聚合级别的活动CU和2个用于产量管理的禁用CU。CU都共享一个4 MB的L2缓存,用于合并芯片的所有内存流量。AMD CDNA™3 XCD芯片的CU不到AMD Instinct MI200系列计算芯片的一半,是一个较小的构建块。然而,它使用了更先进的封装,处理器可以包括6或8个XCD,最多可容纳304个CU,大约比MI250X多40%。
MI300系列使用AMD Infinity Fabric™技术作为互连,集成了多达8个垂直堆叠的XCD、8个高带宽存储器3(HBM3)堆叠和4个I/O管芯(包含系统基础设施)。
CDNA 3 CU内的Matrix Core有了重大改进,强调了人工智能和机器学习,提高了现有数据类型的吞吐量,同时增加了对新数据类型的支持。CDNA 2矩阵核支持FP16和BF16,同时提供INT8用于推理。与MI250X加速器相比,CDNA 3矩阵核的性能是FP16和BF16的三倍,同时为INT8提供了6.8倍的性能增益。与FP32相比,FP8的性能增益为16倍,而TF32的性能增益是FP32的4倍。
MI300X针对不同数据类型的峰值性能,见表5-1。
表5-1 MI300X针对不同数据类型的峰值性能
|
计算与数据类型
|
FLOPS/CLOCK/CU
|
峰值TFLOPS
|
|
矩阵FP64
|
256
|
163.4
|
|
向量FP64
|
128
|
81.7
|
|
矩阵FP32
|
256
|
163.4
|
|
向量FP32
|
256
|
163.4
|
|
向量TF32
|
1024
|
653.7
|
|
矩阵FP16
|
2048
|
1307.4
|
|
矩阵BF16
|
2048
|
1307.4
|
|
矩阵FP8
|
4096
|
2614.9
|
|
矩阵INT8
|
4096
|
2614.9
|
表5-1总结了AMD Instinct MI300X开放计算平台(OCP)和开放加速器模块(OAM),针对不同数据类型和命令处理器的聚合峰值性能。如果在每个时钟周期中提交SIMD(或矩阵)指令,中间列列出了单个计算单元的峰值性能(在单个指令中处理的数据元素的数量)。第三列列出了OAM的理论峰值性能。GPU的理论聚合峰值内存带宽为每秒5.3 TB。
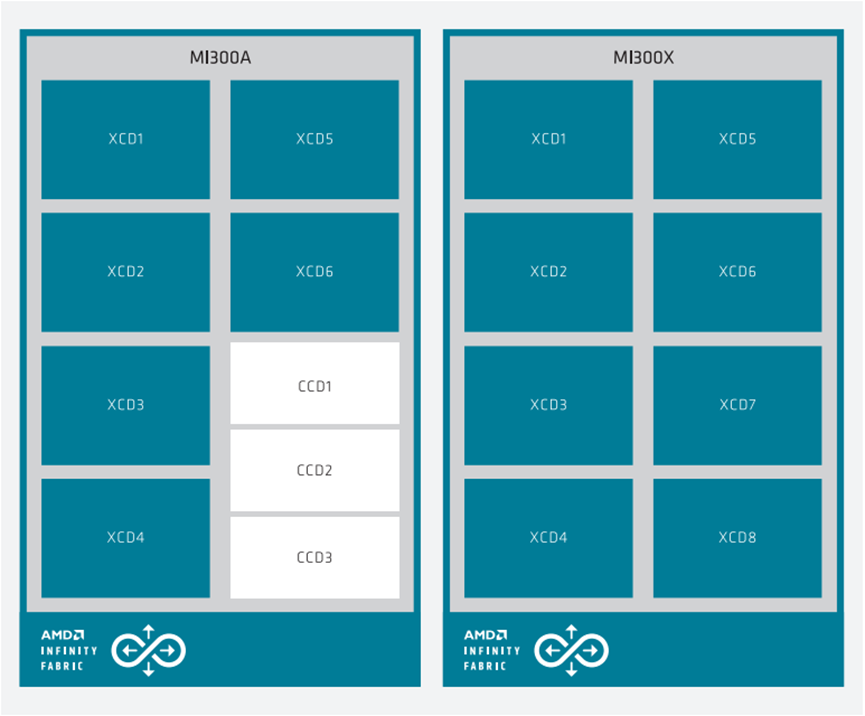
显示了APU(左)和OAM包(右)的框图,两者都通过AMD Infinity Fabric™网络在片上连接,如图5-8所示。
图5-8 APU(左)和OAM包(右)框图,通过AMD Infinity Fabric™网络在片上连接
MI300系列系统架构显示,MI300A(左)具有6个XCD和3个CCD,而MI300X(右)具有8个XCD。
5.2.1节点级架构
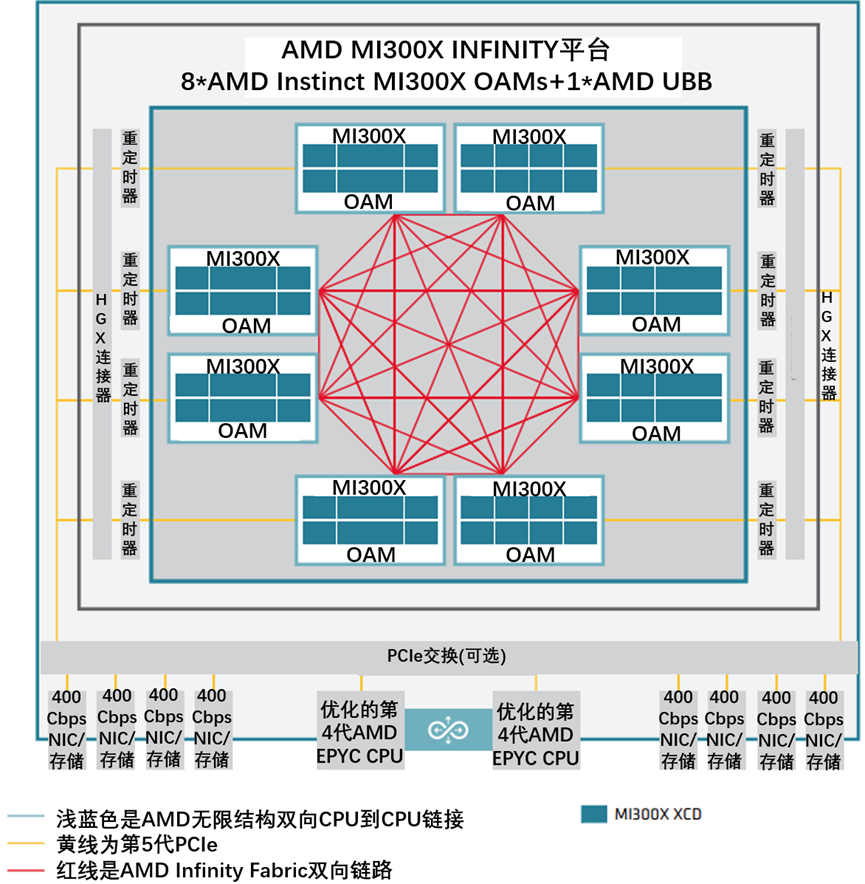
MI300系列节点级架构,显示了8个完全互连的MI300X OAM模块,通过重定时器和HGX连接器连接到(可选)PCIEe交换机。
如图5-9所示,显示了具有双插槽配置的AMD EPYC处理器和八个AMD Instinct MI300X加速器的系统的节点级架构。MI300X OAM通过PCIe Gen 5 x16链路(黄线)连接到主机系统。GPU使用七个高带宽、低延迟的AMD Infinity Fabric™链路(红线)形成一个完全连接的8-GPU系统。
图5-9双插槽AMD EPYC处理器和8个AMD Instinct MI300X加速器的节点级架构
5.2.2 MI300和MI200系列性能计数器和指标
列出并描述了可用于AMD Instinct™MI300和MI200 GPU的硬件性能计数器和衍生指标。还可以使用ROCProfiler工具访问此信息。
MI300和MI200系列性能计数器包括以下类别:
1)命令处理器计数器
2)图形寄存器总线管理器计数器
3)着色器处理器输入计数器
4)计算单位计数器
5)L1指令缓存(L1i)和标量L1数据缓存(L1d)计数器
6)向量L1缓存子系统计数器
7)L2缓存访问计数器
以下部分提供了每个类别的其他详细信息。
所有MI300和MI200系列性能计数器的初步验证正在进行中。带星号(*)的需要进一步评估。
1. 命令处理器计数器
命令处理器计数器进一步分为命令处理器提取器和命令处理器计算。
2. 命令处理器提取器计数器
命令处理器提取器计数器定义,见表5-2。
表5-2 命令处理器提取器计数器定义
|
硬件计数器
|
单位
|
定义
|
|
CPF_CMP_UTCL1_STALL_ON_TRANSLATION
|
周期
|
一个计算统一翻译缓存(L1)在等待翻译时停滞的周期数
|
|
CPF_CPF_STAT_BUSY
|
周期
|
命令处理器提取器正忙的周期数
|
|
CPF_CPF_STAT_IDLE
|
周期
|
命令处理器提取器空闲的周期数
|
|
CPF_CPF_STAT_STALL
|
周期
|
命令处理器提取器停止的周期数
|
|
CPF_CPF_TCIU_BUSY
|
周期
|
命令处理器提取器纹理缓存接口单元接口繁忙的周期数
|
|
CPF_CPF_TCIU_IDLE
|
周期
|
命令处理器提取器纹理缓存接口单元接口空闲的周期数
|
|
CPF_CPF_TCIU_STALL
|
周期
|
命令处理器提取器纹理缓存接口单元接口在等待空闲标签时停滞的周期数
|
纹理缓存接口单元是命令处理器和存储系统之间的接口。
3. 命令处理器计算计数器
命令处理器提取器计数器定义,见表5-3。
表5-3 命令处理器提取器计数器定义
|
命令处理器计算计数器
|
单位
|
定义
|
|
CPC_ME1_BUSY_FOR_PACKET_DECODE
|
周期
|
命令处理器计算微引擎正忙于解码数据包的周期数
|
|
CPC_UTCL1_STALL_ON_TRANSLATION
|
周期
|
一个统一翻译缓存(L1)暂停等待翻译的周期数
|
|
CPC_CPC_STAT_BUSY
|
周期
|
命令处理器计算繁忙的周期数
|
|
CPC_CPC_STAT_IDLE
|
周期
|
命令处理器计算处于空闲状态的周期数
|
|
CPC_CPC_STAT_STALL
|
周期
|
命令处理器计算停滞的周期数
|
|
CPC_CPC_TCIU_BUSY
|
周期
|
命令处理器计算纹理缓存接口单元接口繁忙的周期数
|
|
CPC_CPC_TCIU_IDLE
|
周期
|
命令处理器计算纹理缓存接口单元接口空闲的周期数
|
|
CPC_CPC_UTCL2IU_BUSY
|
周期
|
命令处理器计算统一翻译缓存(L2)接口繁忙的周期数
|
|
CPC_CPC_UTCL2IU_IDLE
|
周期
|
命令处理器计算统一翻译缓存(L2)接口空闲的周期数
|
|
CPC_CPC_UTCL2IU_STALL
|
周期
|
命令处理器计算统一翻译缓存(L2)接口停滞的周期数
|
|
CPC_ME1_DC0_SPI_BUSY
|
周期
|
命令处理器计算微引擎处理器正忙的周期数
|