1. 什么是Attention
注意力机制(Attention Mechanism)是机器学习和人工智能领域中的一个重要概念,用于模拟人类视觉或听觉等感知过程中的关注机制。注意力机制的目标是让模型能够在处理信息时,更加关注与任务相关的部分,忽略与任务无关的信息。这种机制最初是受到人类大脑对信息处理的启发而提出的。
注意力机制的基本原理如下:
-
输入信息:首先,注意力机制接收输入信息,这可以是序列数据、图像、语音等。
-
查询、键和值:对于每个输入,注意力机制引入了三个部分:查询(query)、键(key)、值(value)。这些部分通常是通过神经网络学习得到的。查询用于表示要关注的内容,键用于表示输入信息中的特征,值则是与每个键相关的信息。
-
权重分配:注意力机制根据查询和键之间的关系来计算权重,这些权重决定了每个值在最终输出中的贡献程度。通常使用某种形式的相似度度量(如点积、缩放点积等)来计算权重。
-
加权求和:将计算得到的权重与对应的值相乘,然后将它们加权求和,得到最终的输出。这个输出通常包含了模型在处理输入信息时关注的部分。
-
重复:上述过程通常会被重复多次,以便模型可以在不同的上下文中动态地调整注意力。
注意力机制的核心思想是让模型能够自动地确定在处理输入信息时要关注哪些部分,从而提高了模型在各种任务中的性能。它在自然语言处理、计算机视觉和语音处理等领域都有广泛的应用,如在机器翻译中的Transformer模型、图像分割中的U-Net模型以及语音识别中的Listen, Attend and Spell(LAS)模型等。
总的来说,注意力机制可以帮助模型更好地理解和利用输入信息,提高了模型的表现和泛化能力。
2. Why Attention
由于LSTM和GRU只在一定程度上改进了循环神经网络的长句子依赖问题,并且信息的记忆能力也不是很强和计算能力有限。如果模型要记住很多信息,不得不设计的更复杂,为了解决这些问题,注意力机制出现了,它即能从大量信息中选择重要的信息来缓解神经网络模型的复杂度,而且能高效的并行运算。注意力机制的计算是一个匹配的过程,即通过一个查询(Query)向量到键(Key)和值(Value)对数据对来映射输出值.
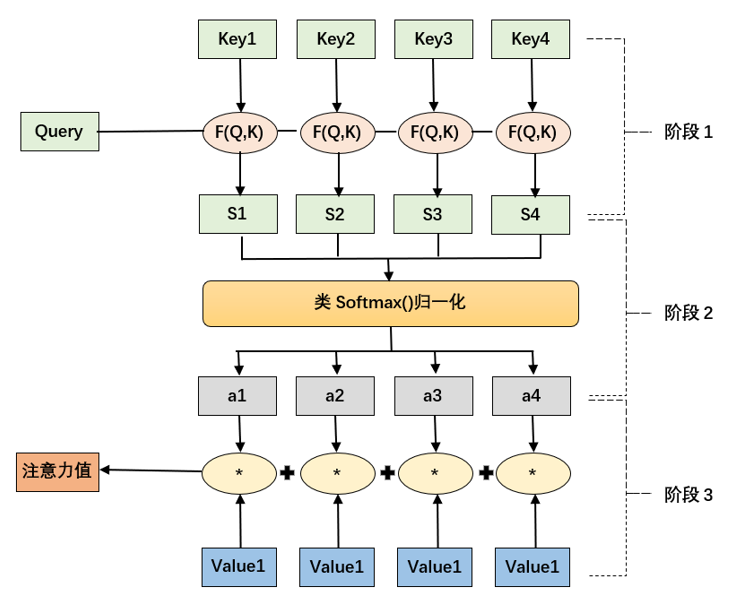
注意力的计算一般有三个阶段。第一阶段是计算查询向量Q和每个输入的K的相关性或相似度,得到注意力权重系数 :
第二阶段是使用SoftMax函数对第一阶段得出的权重系数进行尺度缩放,即把它归一化为概率分布 ai![]() ,分子是把神经元的当前输出映射到(0,+∞),分母是所有输出结果值的总和,公式如下:
,分子是把神经元的当前输出映射到(0,+∞),分母是所有输出结果值的总和,公式如下:
第三阶段:将第二阶段得出的权重与value值加权求和,得到最终需要的Attention数值:
3. TF attention api 介绍
Attention class
tf.keras.layers.Attention(use_scale=False, score_mode="dot", **kwargs)
Dot-product attention layer, a.k.a. Luong-style attention.
Inputs are query tensor of shape [batch_size, Tq, dim], value tensor of shape [batch_size, Tv, dim] and key tensor of shape [batch_size, Tv, dim]. The calculation follows the steps:
- Calculate scores with shape
[batch_size, Tq, Tv]as aquery-keydot product:scores = tf.matmul(query, key, transpose_b=True). - Use scores to calculate a distribution with shape
[batch_size, Tq, Tv]:distribution = tf.nn.softmax(scores). - Use
distributionto create a linear combination ofvaluewith shape[batch_size, Tq, dim]:return tf.matmul(distribution, value).
4. 实验代码
4.1. 验证并理解TF attention方法,只输入query和value矩阵。
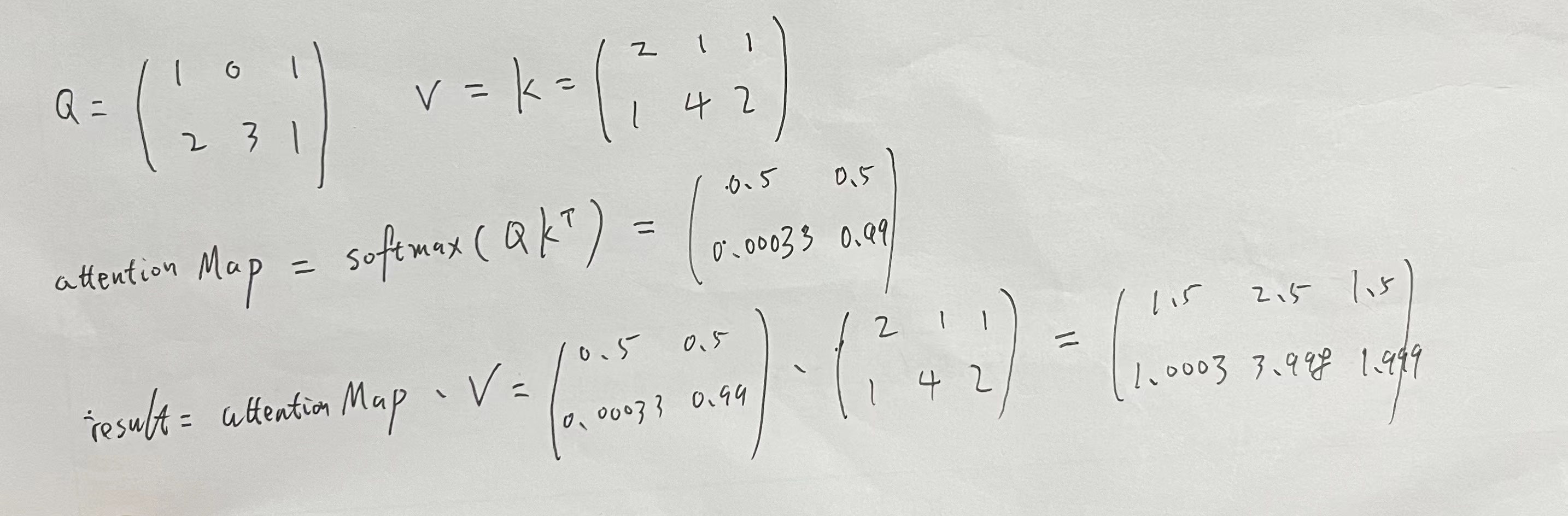
def softmax(t):s_value = np.exp(t) / np.sum(np.exp(t), axis=-1, keepdims=True)# print('softmax value: ', s_value)return s_valuedef numpy_attention(inputs,mask=None,training=None,return_attention_scores=False,use_causal_mask=False):query = inputs[0]value = inputs[1]key = inputs[2] if len(inputs) > 2 else valuescore = np.matmul(query, key.transpose())attention_score_np = softmax(score)result = np.matmul(attention_score_np, value)print('attention score in numpy =', attention_score_np)print('result in numpy = ', result)def verify_logic_in_attention_with_query_value():query_data = np.array([[1, 0.0, 1],[2, 3, 1]])value_data = np.array([[2, 1.0, 1],[1, 4, 2 ]])print(query_data.shape)numpy_attention([query_data, value_data], return_attention_scores=True)print("=============following is keras attention output================")attention_layer= tf.keras.layers.Attention()result, attention_scores = attention_layer([query_data, value_data], return_attention_scores=True)print('attention_scores = ', attention_scores)print('result=', result);
if __name__ == '__main__':verify_logic_in_attention_with_query_value()运行结果
(2, 3)
attention score in numpy = [[5.0000000e-01 5.0000000e-01][3.3535013e-04 9.9966465e-01]]
result in numpy = [[1.5 2.5 1.5 ][1.00033535 3.99899395 1.99966465]]
=============following is keras attention output================
attention_scores = tf.Tensor(
[[5.0000000e-01 5.0000000e-01][3.3535014e-04 9.9966466e-01]], shape=(2, 2), dtype=float32)
result= tf.Tensor(
[[1.5 2.5 1.5 ][1.0003353 3.998994 1.9996647]], shape=(2, 3), dtype=float32)4.2. 验证并理解TF attention方法,输入query, key, value矩阵。
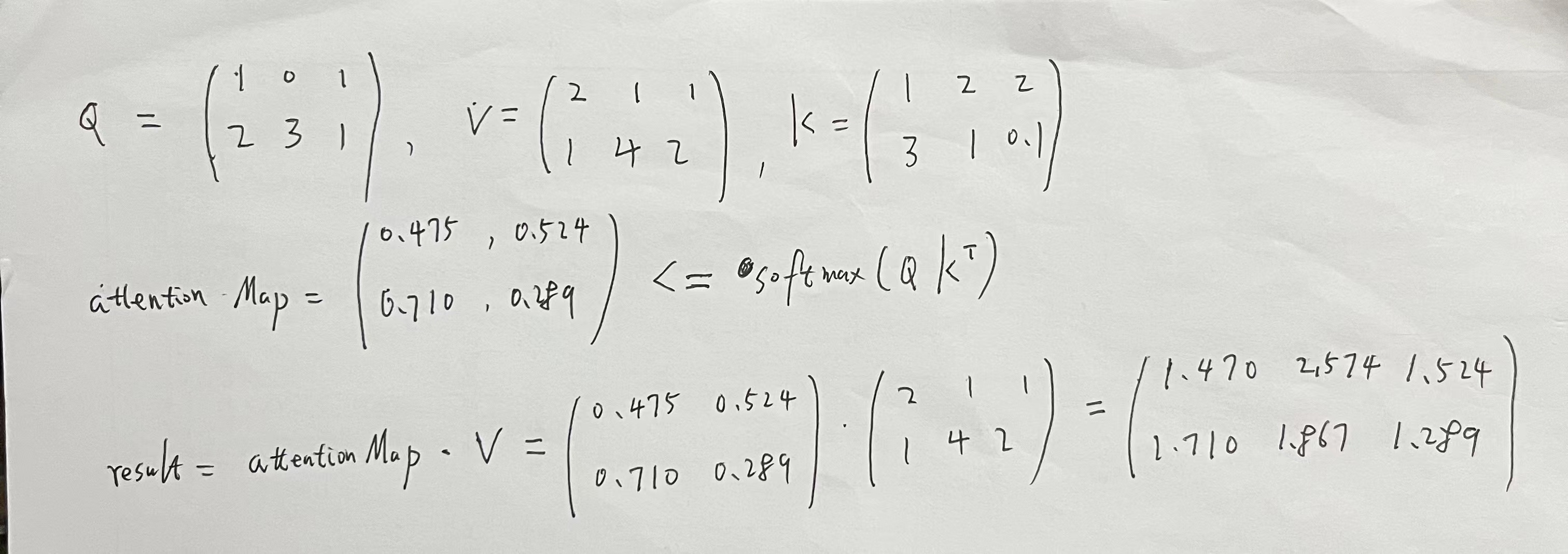
def verify_logic_in_attention_with_query_key_value():query_data = np.array([[1, 0.0, 1],[2, 3, 1]])value_data = np.array([[2, 1.0, 1],[1, 4, 2 ]])key_data = np.array([[1, 2.0, 2], [3, 1, 0.1]])print(query_data.shape)numpy_attention([query_data, value_data, key_data], return_attention_scores=True)print("=============following is keras attention output================")attention_layer= tf.keras.layers.Attention()result, attention_scores = attention_layer([query_data, value_data, key_data], return_attention_scores=True)print(attention_layer.get_weights())print('attention_scores = ', attention_scores)print('result=', result);
if __name__ == '__main__':verify_logic_in_attention_with_query_key_value()结果
(2, 3)
attention score in numpy = [[0.47502081 0.52497919][0.7109495 0.2890505 ]]
result in numpy = [[1.47502081 2.57493756 1.52497919][1.7109495 1.86715149 1.2890505 ]]
=============following is keras attention output================
[]
attention_scores = tf.Tensor(
[[0.47502086 0.52497923][0.7109495 0.28905058]], shape=(2, 2), dtype=float32)
result= tf.Tensor(
[[1.4750209 2.5749378 1.5249794][1.7109495 1.8671517 1.2890506]], shape=(2, 3), dtype=float32)