大模型微调经验分享
大模型微调目的
-
模型:大模型仍是欠拟合状态。在某些特定任务上无法达到实际业务需求 or 性能差无法直接使用 ==> 改善特定任务下欠拟合程度
-
数据:预训练数据分布和特定任务数据分布不一致 ==>将特定任务、场景的语料的内在关系融入大模型参数中,同时和预训练的通用语料建立联通关系。缩小预训练数据和业务数据的差异,增强对业务数据的理解能力。
-
提高在特定场景、任务的准确率 && 减少幻觉现象
大模型的幻觉问题调研
大模型微调方法

plug-in
chatgpt插件
plug-in: 第三方api,调用插件可以增强LLM系统的功能,比如:搜索api、科学计算等等
plug-in优化:补充系统能力比如文档解析插件;提升单个插件完成任务的准确度比如提高召回率
原始模型参数微调
全量微调(Full Fine-Tuning,FT)
- 微调模型与原始预训练模型大小相同
- 所有参数都可以通过梯度回传到更新,理论上限最高,资源消耗最大
- 一般会走完预训练的3阶段,也叫Continual pretraining
==> 所需资源、训练时间最大,且当语料不够大时容易过拟
部分层微调(Freeze Tuning)
- 只微调与训练模型的某些层来适配新的任务
- 一般微调模型最后1~3层,微调参数可以指定微调MLP或QKV
==> 局部更新参数,不高效
逐层微调
从底层开始逐层微调,直至所有层都完成微调
==> 表现不好
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
只微调少量或者额外的参数,降低计算、存储成本
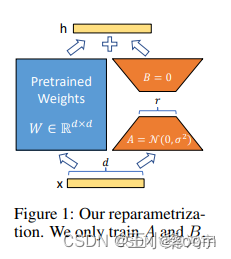
LoRA/QLoRA
LoRA模型微调原理视频
https://blog.csdn.net/weixin_44826203/article/details/129733930
- 通过小参数的低秩矩阵来近似模型权重矩阵W的参数更新
- 假设:大模型微调过程中权重变化具有较低的内在秩
- 推理过程先合并基座模型和LoRA的参数
- QLoRA:通过量化技术、分页优化器降低显存
==> 没有额外的推理延时,大致收敛于基座模型
P-Tuning
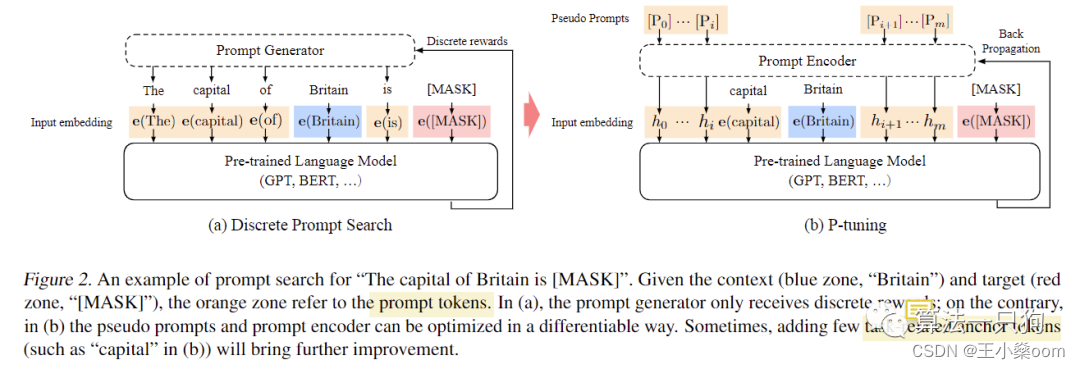
- 在输入或隐层添加额外可训练的前缀tokens,只训练这些前缀参数
- 连续prompt
==>前缀保留部分序列长度会减少下游任务的序列输入长度
Adapter-Tuning
https://zhuanlan.zhihu.com/p/574191259
将较小的神经网络或模块插入与训练模型的每一层,微调时之训练adapter参数
==> 添加适配器引入额外计算导致推理延迟
Prefix Tuning
https://blog.csdn.net/qq_36426650/article/details/120255851
==>难以优化,性能随可训练参数的规模非单调变化
低资源微调
- LoRA/QLoRA(减少训练参数)
- 混合精度训练(减少显存占用一半,加速训练一倍)
- LOMO(大幅减少显存占用,某些场景比lora差)
- Activation checkpointing(减少显存占用,额外计算量)
- 异构设备训练(减少显存占用)
混合精度训练
LOMO github
Activation checkpointing
模型Prompt工程
https://zhuanlan.zhihu.com/p/618871247
RLHF(人类反馈强化学习)
https://zhuanlan.zhihu.com/p/591474085