如何创建命名管道
使用mkfifo函数就可以在程序里面创建管道文件,该函数的声明如下:
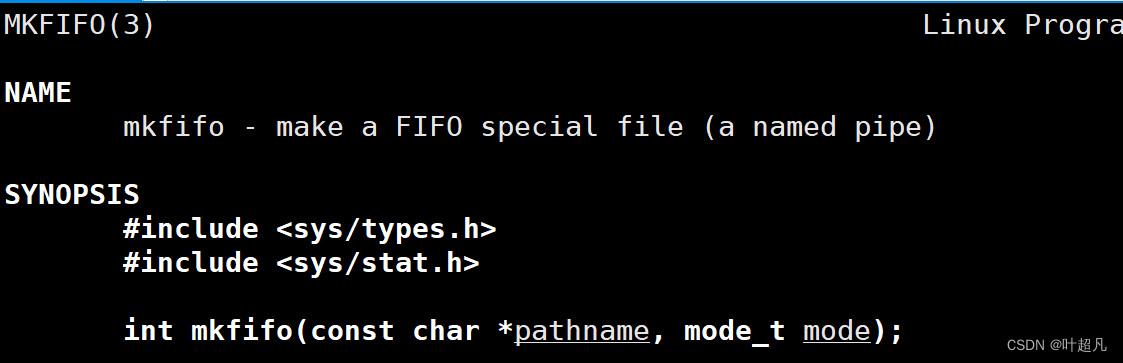
该函数需要两个参数,第一个参数表示要在哪个路径下创建管道文件并且这个路径得待上管道文件的名字,因为每个文件都有对应的权限,所以函数的第二个参数就表示管道文件的权限,如果管道文件创建成功了该函数就返回0,如果创建失败该函数就直接返回对应的错误码:
那么接下来我们就创建一个管道文件出来瞧瞧,当前所在的路径如下:

那么我们就可以在程序里面通过函数mkfifo来创建管道文件:
#include<iostream>
#include<cerrno>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
using namespace std;
int main()
{umask(0);int n=mkfifo("/home/xbb/folder13/name_pipe",0600);if (n == 0){cout<<"creat success"<<endl;}else{cout << "errno: " << errno << " err string: " << strerror(errno) << endl;}return 0;
}
那么运行的结果就如下:
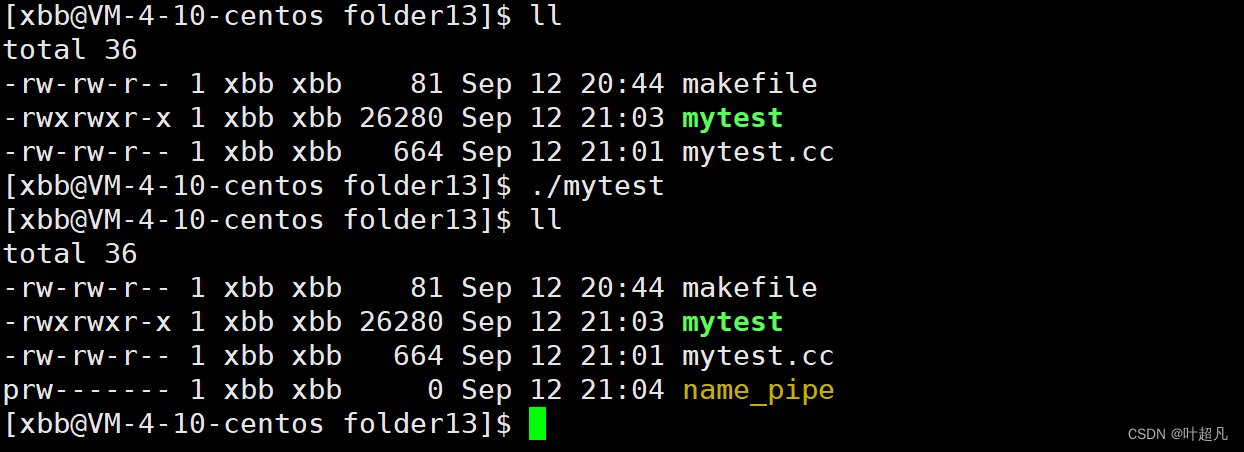
可以看到程序运行成功之后多出来了一个名为name_pipe的文件,并且这个文件是以p为开头,那么这个p就表示pipe的意思表示当前文件是管道文件,并且使用指令ls -il查看文件inode的时候也可以发现该文件有inode,那么这就说明管道文件是一个独立的文件,并且当前管道文件的大小为0表示当前文件里面没有任何的数据,然后使用下面的指令我们可以往屏幕上面不停地输出数据:cnt=0; while :; do echo "hello world-> $cnt"; let cnt++; sleep 1;done:
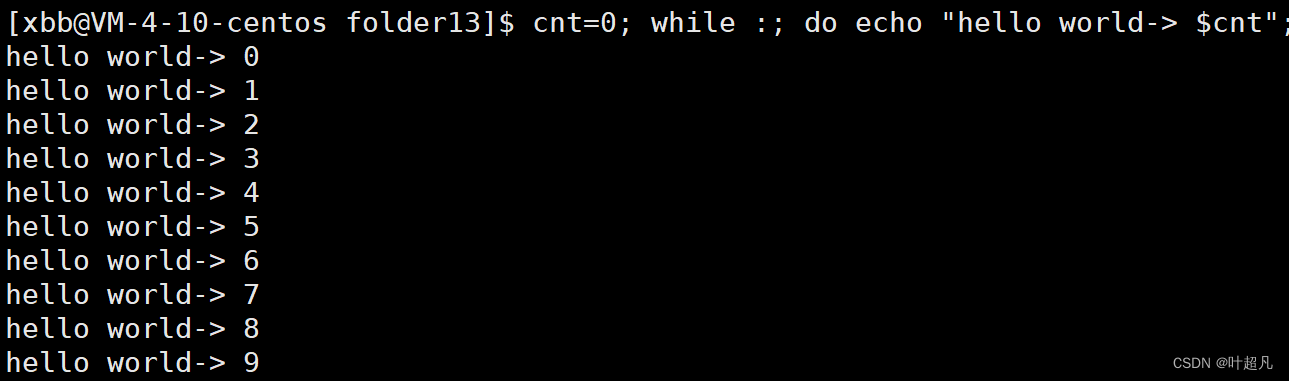
那么这里我们就可以使用重定向,将原本输出到屏幕的数据输出到管道文件里面:

运行当前的指令就会不停地往管道里面输入数据,但是我们再创建一个进程不停地查看的管道文件的大小时,便会发现管道文件的大小没有发生任何变化:
可是虽然文件的大小没有发生任何的变化,但是当我们使用cat指令输出文件的内容时便又会发现,屏幕中打印了我们输入到文件里面的内容:
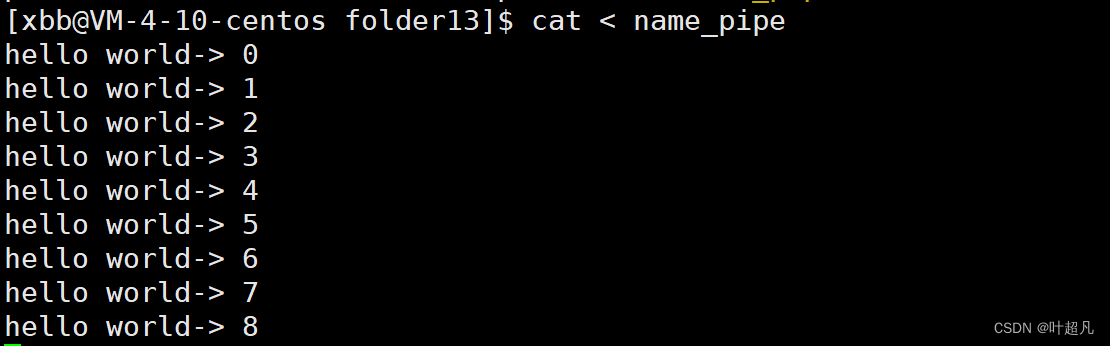
那么这就是管道文件的特性,那么接下来我们来看看命名管道的原理。
命名管道的原理
当我们在操作系统中打开一个文件,操作系统会创建一个struct file对象,该对象里面含有缓冲区和文件有广的操作方法,然后进程中的PCB中就会有一个指针指向一个名为file_struct的结构体,结构体中存在一个指针数组,数组的每个元素就指向不同文件的struct file对象:
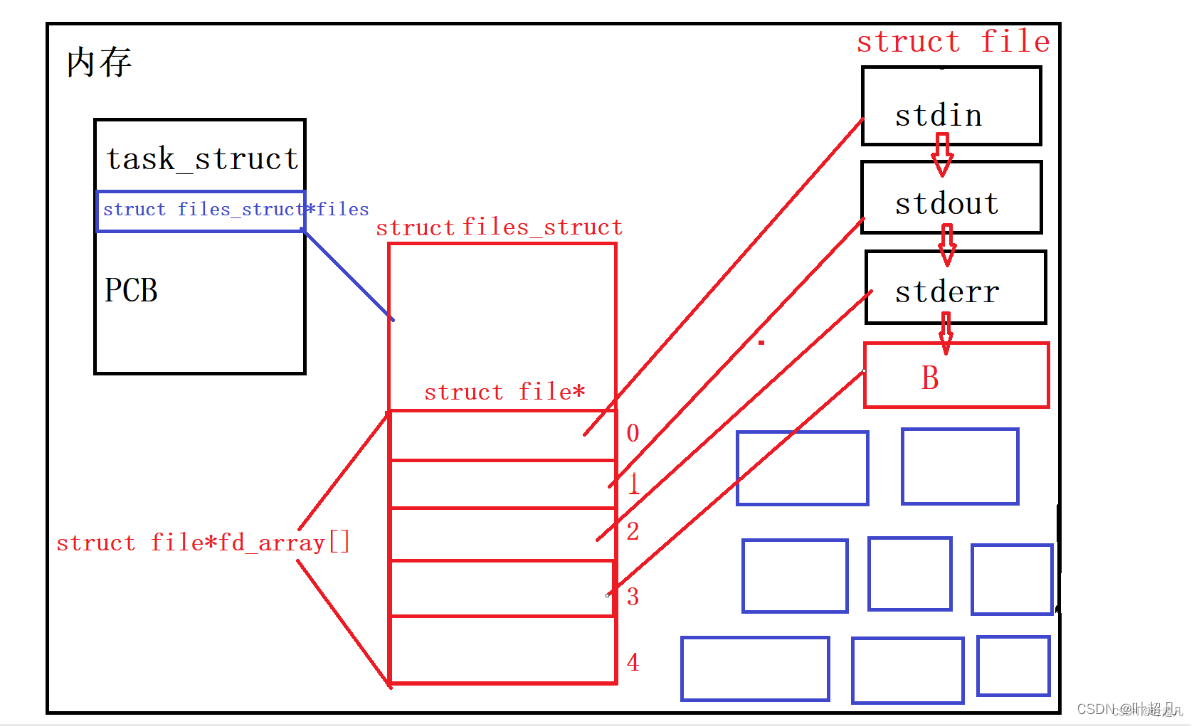
但是这里存在一个问题,如果多个进程打开同一个文件,那操作系统会为这个文件创建多个struct file对象吗?答案是不会的,即使多个进程都打开了同一个文件,操作系统也只会创建一个struct file对象,所以这就会导致多个进程共用一个struct file,如果多个进程共用一个struct file的话,那这不就是让多个进程看到同一份资源嘛,所以这个strcut file就相当于是一个管道,只不过该管道文件的strcut file不会将内部缓冲区的数据刷新到磁盘中的文件里面,struct file对象中的数据都是内存级被写入和读取,那命名管道是如何做到让不同的进程看到同一份资源的呢?答案是让不同的进程打开指定名称(路径+文件名)的同一个文件,路径+文件名=唯一确定的文件,之所以叫命名管道是因为该管道是通过文件名的方式来看到同一份资源,而匿名管道是父子进程通过继承的方式来确定唯一性,并不通过文件名,所以将其称之为匿名管道。
命名管道的通信
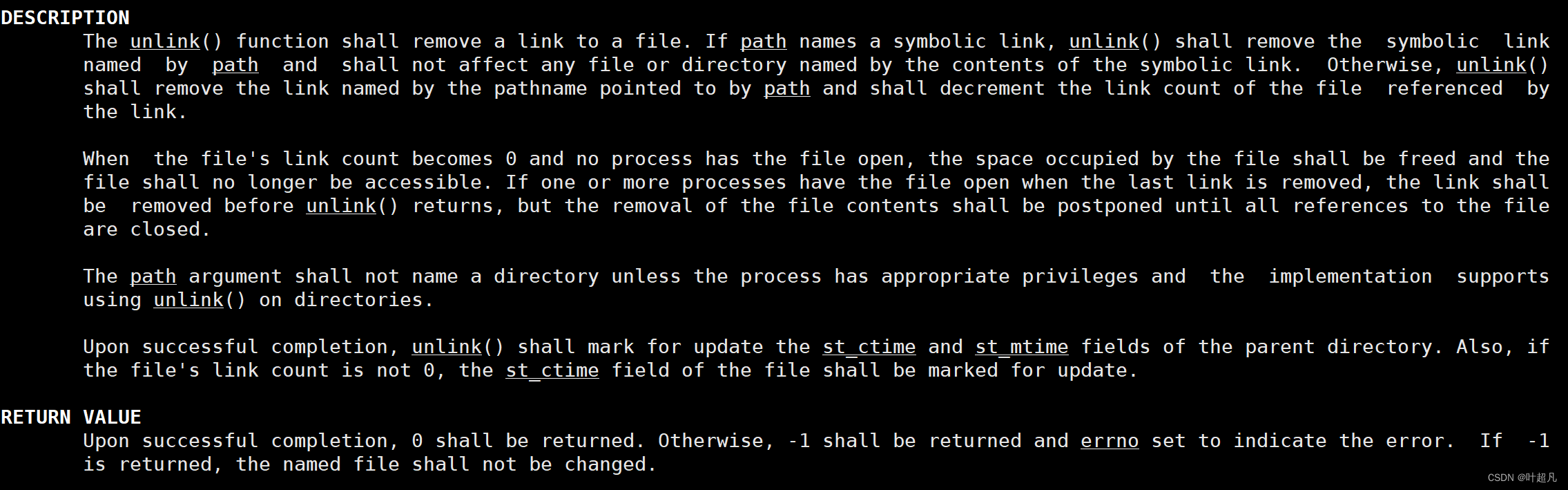
函数mkfifo可以在程序里面创建命名管道,既然有创建那么同样的道理就有对应的函数来删除管道文件,unlink函数就可以用来删除创建的管道文件,该函数的声明如下:

函数内的参数表示要删除的管道文件,如果删除成功就返回0,删除失败就返回对应的错误码:
那么这里我们就可以使用这两个函数来实现进程之间的通信,首先创建一个文件,这个文件里面就包含两个函数,一个函数用来创建管道文件,一个函数用来删除管道文件:
#include<iostream>
#include<cerrno>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
using namespace std;
#define PIPE_PATH "/home/xbb/folder13/name_pipe"
bool createFifo(const string &path)
{}void removeFifo(string &path)
{}
根绝前面的经验我们可以很容易得实现createFifo函数,当mkfifo函数返回的值等于0的话就返回true,函数的返回值为非0的话就返回false:
bool createFifo(const string &path)
{umask(0);int n=mkfifo(path.c_str(),0600);if(n==0){return true;}else{cout << "errno: " << errno << " err string: " << strerror(errno) << endl;return false;}
}
同样的道理removeFifo函数里面就是调用unlink函数来进行删除,那么这里我们就用assert函数来进行判断文件是否删除成功,那这里的代码如下:
void removeFifo(const string &path)
{int n=unlink(path.c_str()); assert(n==0);(void)n;
}
那么这就是comm.hpp文件的内容,接下来我们还要创建server.cc文件和client.cc文件,server.cc文件负责从管道里面读取数据,client.cc文件就负责从管道里面写入数据,因为server.cc文件是读端,所以我们就让他来决定管道的创建和删除,那么在这个server.cc文件里面首先使用comm.hpp中的creatFifo函数创建管道,然后使用assert判断一下创建是否成功,创建成功之后就使用open函数以读的方式打开该管道文件,然后就得到这个函数的读端的下标
#include"comm.hpp"
int main()
{int r = createFifo(PIPE_PATH);assert(r);(void)r;int rfd=open(PIPE_PATH, O_RDONLY);cout<<"开始读取"<<endl;if(rfd<0){exit(1);}return 0;
}
走到这里我们的管道文件就在当前进程顺利的创建并且打开了,那么这时我们就可以创建一个while循环不停地往管道里面读取信息,因为读取的信息要放到一个地方进行存储,所以在循环之前我们还得穿件一个数组用来充当缓冲区,那么在循环里面就可以使用read函数从下标为rfd的文件里面读取数据,将读取的数据放到缓冲区里面,因为读取数据的时候可能会出现结束或者出错的情况,所以这里还得创建一个变量用来记录read函数的返回值,那么这里的代码如下:
#include"comm.hpp"
int main()
{int r = createFifo(PIPE_PATH);assert(r);(void)r;int rfd=open(PIPE_PATH, O_RDONLY);cout<<"开始读取"<<endl;if(rfd<0){exit(1);}char buffer[1024]={0};while(true){ssize_t s = read(rfd, buffer, sizeof(buffer)-1);}return 0;
}
然后就使用if else语句对size的值进行判断,如果size的值大于0就表示当前的读取是正确的,我们直接输出buffer里面的值,如果size的值等于0就表示当前的读取结束了直接使用break结束while循环,如果sizede值小于0就表示当前的读取出现了错误,那么我们就打印一下错误码看看哪里出现了问题并使用break结束循环,循环结束之后我们就关闭当前打开的管道文件,并且使用removeFifo函数删除管道文件,那么这里的代码如下:
#include"comm.hpp"
int main()
{int r = createFifo(PATH);assert(r);(void)r;int rfd=open(PATH, O_RDONLY);cout<<"开始读取"<<endl;if(rfd<0){exif(1);}char buffer[1024]={0};while(true){ssize_t s = read(rfd, buffer, sizeof(buffer)-1);if(s > 0){buffer[s] = 0;std::cout << "client->server# " << buffer << std::endl;}else if(s == 0){std::cout << "client quit, me too!" << std::endl;break;}else{std::cout << "err string: " << strerror(errno) << std::endl;break;}}close(rfd);// sleep(10);removeFifo(NAMED_PIPE);return 0;
}
那么这是server.cc文件的内容,那么对于client.cc文件也是同样的道理,首先以写的方式打开管道文件然后进行判断,再创建一个缓冲区将想要写入管道的信息先写入到缓冲区里,再使用write函数将缓冲区的内容放到写入到管道里面,然后根据write函数的返回值来判断当前的写入是否成功,因为要多次写入所以这里也得添加while循环来进行循环写入:
#include"comm.hpp"
int main()
{int Wfd=open(PIPE_PATH, O_WRONLY);if(Wfd < 0) exit(1);char buffer[1024];cout<<"client say"<<endl;while(true){fgets(buffer, sizeof(buffer), stdin);if(strlen(buffer) > 0) {//将末尾的/n去掉buffer[strlen(buffer)-1] = 0;}ssize_t n = write(Wfd, buffer, strlen(buffer));assert(n == strlen(buffer));(void)n;}close(Wfd);return 0;
}
此文件写完之后我们就可以来完成makefile文件,首先该功能的运行需要让两个文件都生成可执行程序,所以这里就将指令较为all,该指令需要client和server生成可执行程序:
.PHONY:
all: client server
但是当前路径下并没有可执行程序,所以我们还得添加两个可执行程序对应的实现方法和依赖文件:
.PHONY:
all: client serverclient:client.ccg++ -o $@ $^ -std=c++11 -g
server:server.ccg++ -o $@ $^ -std=c++11 -g
然后就是删除指令,该指令将生成的两个可执行程序删除就行,那么makefile的全部内容如下:
.PHONY:
all: client serverclient:client.ccg++ -o $@ $^ -std=c++11 -g
server:server.ccg++ -o $@ $^ -std=c++11 -g.PHONY:
clean:rm -f client server
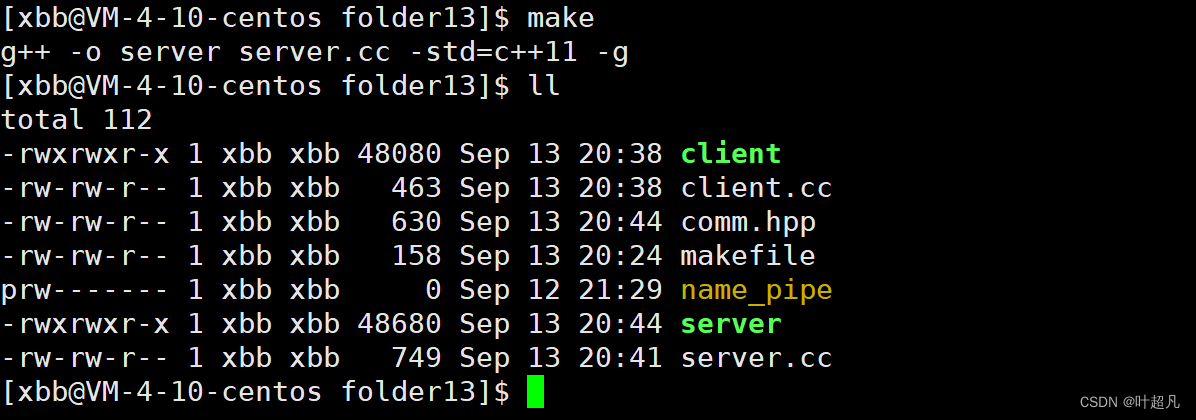
那么接下来我们就可以进行测试,首先使用make指令生成两个可执行程序:
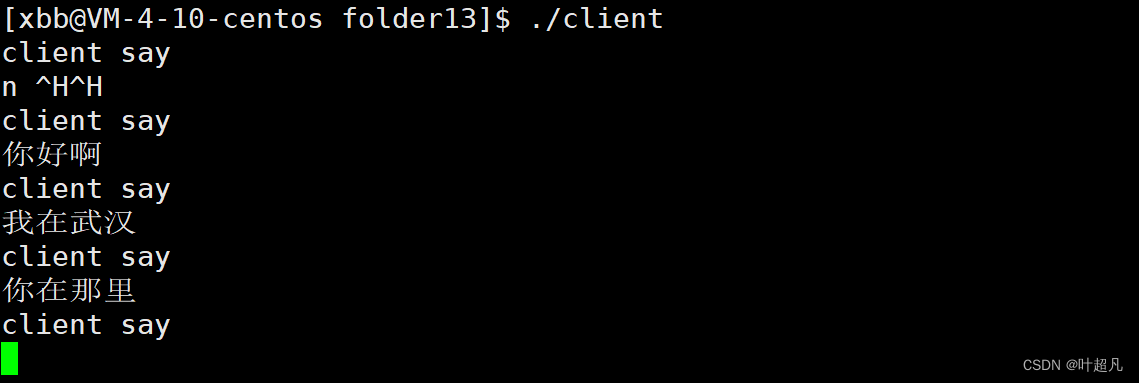
然后先打开server再打开client程序,然后就可以看到这样的现象:

因为写端没有打开,所以server一直阻塞在open函数那里,当我们运行client程序之后就可以看到server进程打印出来了内容:


然后我们往client进程里面输入内容,然后便可以看到,输入导client里面的内容输出到server这里:
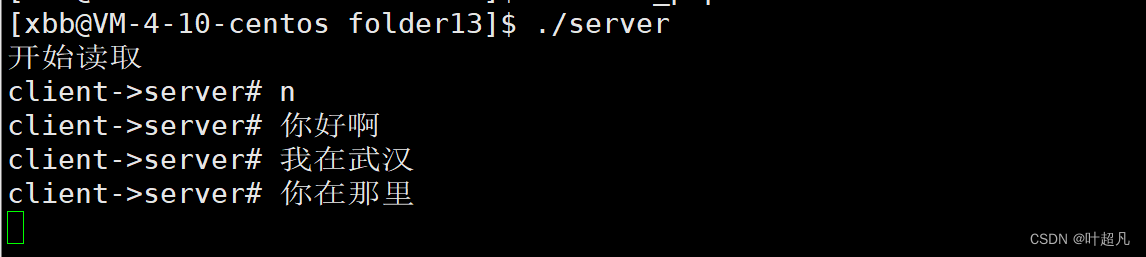
那么这就是命名管道的通信。