最近在做一次系统整体优化,发现系统存在GC时长过长及JVM内存溢出的问题,记录一下优化的过程
面试的时候我们都被问过如何处理生产问题,尤其是线上oom或者GC调优的问题更是必问,所以到底应该如何发现解决这些问题呢,用真实的场景实操,更具有说服性。
一:如何发现
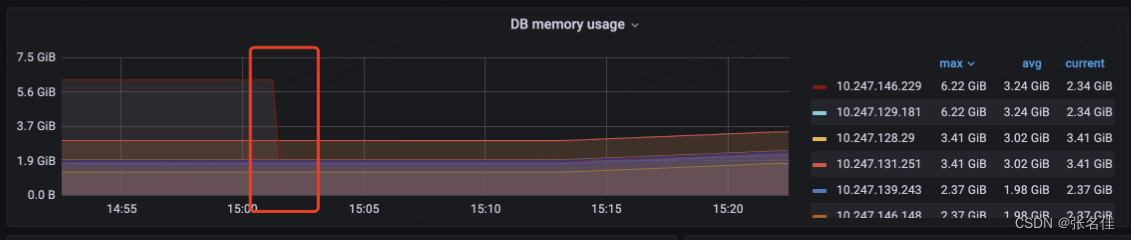
1.发现经过如下,首先pass服务的pod不停自动触发重启,因为pass配置系统health接口访问超时,通过系统的grafana监控发现二点异常,1.GC时间大量超时40s+,2.堆内存达到24G(也是我们配置最大的内存,触发OOM)
监控如下:
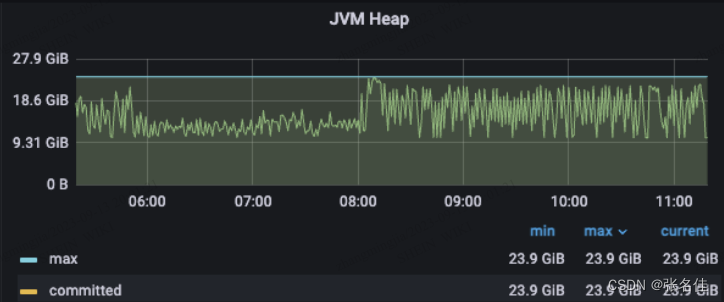
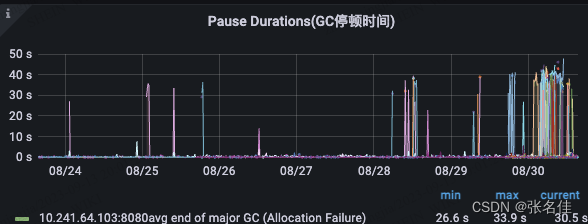
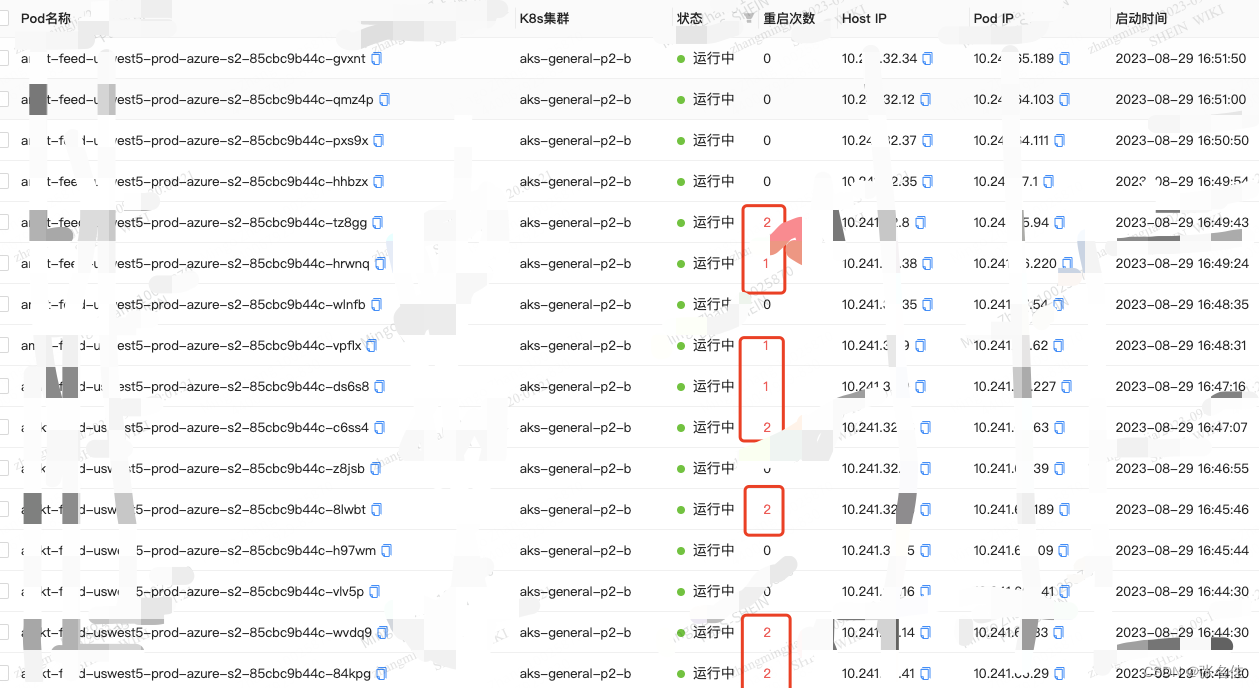
所以我们可以梳理出以下链路
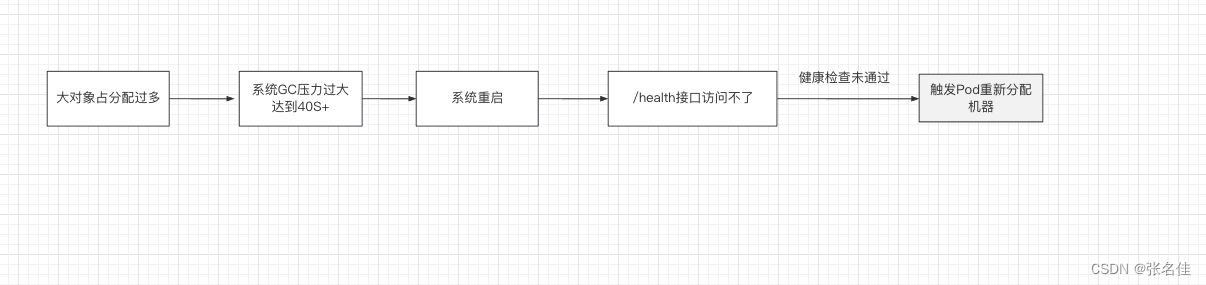
二:如何优化
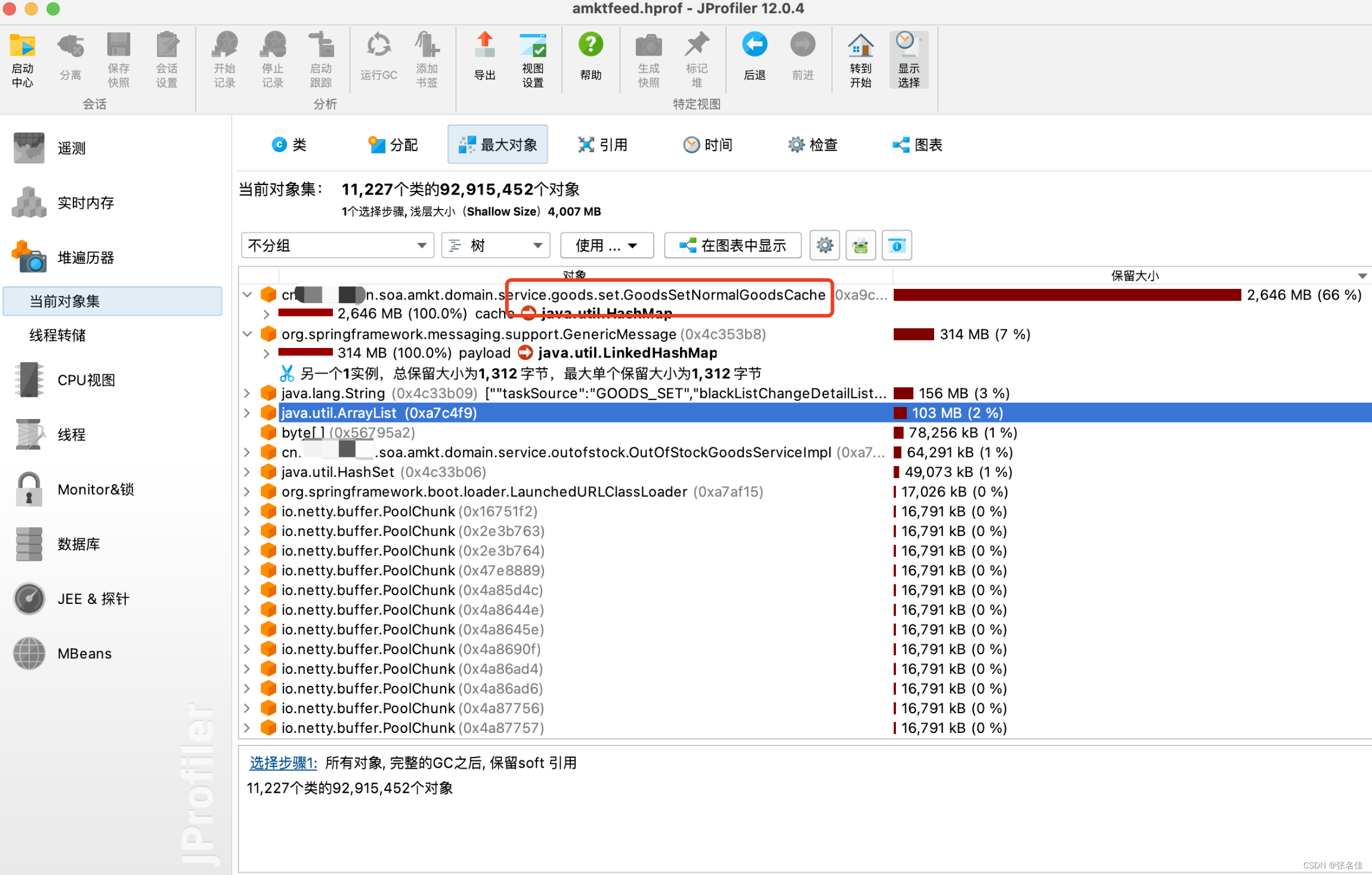
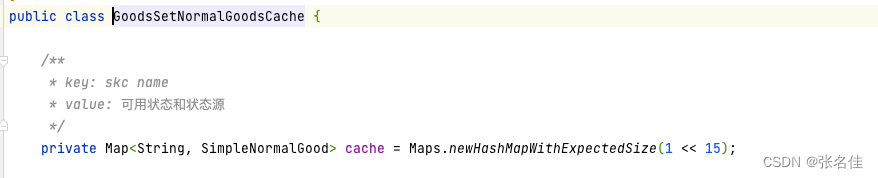
1,我们dump系统的在业务低谷期的内存情况,看看业务的低谷期时系统中是否存在不合理的大对象,如果有肯定是要优化掉的,因为业务高峰期会肯定分配一些局部变量大对象,需要给他们腾空间,可以理解先优化最简单的,再优化运行中产生的,结果还真的发现在这个GoodsSetNormalGoodsCache类的中cache对象,存了一个近1200W(并且随业务持续增长)的内存大对象,用于全局skc分站点上下架的缓存信息
dump如下:
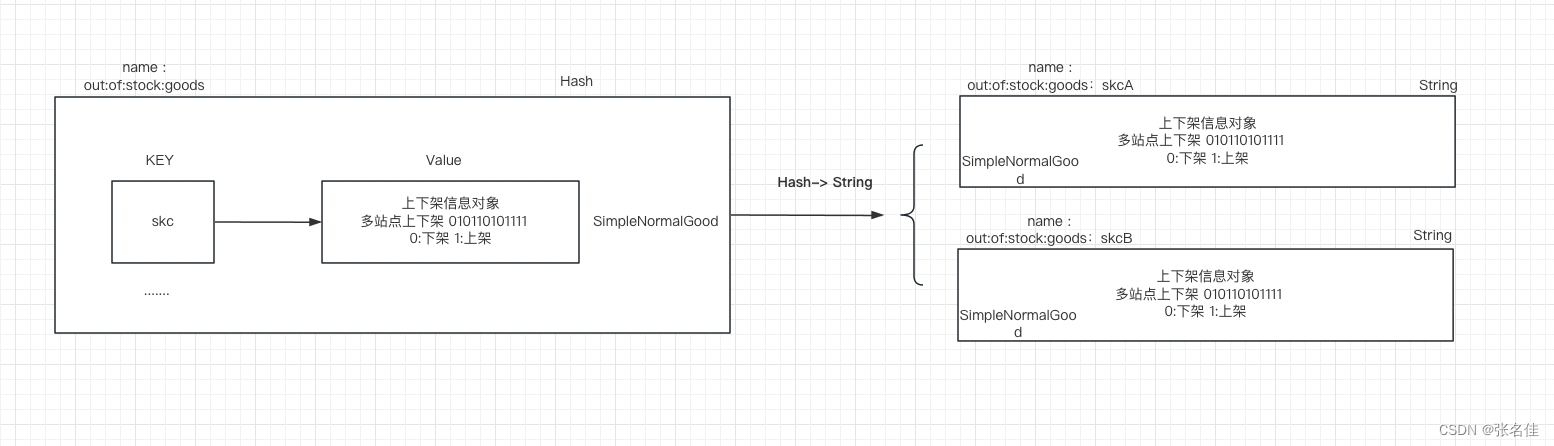
1.巧用redis优化大对象
优化策略:大家很容易想到将map由JVM内存移入redis的hash结构中存储(面试过很多人都说把oom的对象直接剔除,其实很多时候我们处理的场景是不允许删除,如果直接移除可以解决问题,我相信大部分开发就不会加载部分大对象进入内存,加载进去必然是为了快速查询全量数据),存储结构如下图: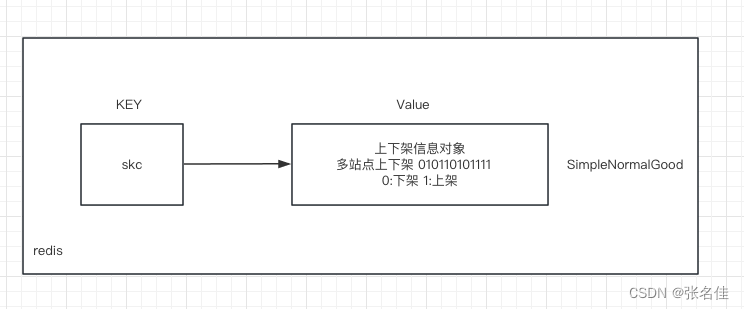
但是实际上线后,生产环境中又遇到新的问题,这个keyQPS很高达到几万qps,因为业务逻辑增量任务需要不停且大量的查询skc在不同站点的上下架信息,必然也导致这个key是一个热key
如图:(注意这里的元素个数是900w,因为在做初始化)

当然,系统中出现热key不是问题,问题在于redis也是个大key,导致数据产生倾斜,最高的节点和最低的节点相差一个G的数据,并且我们联系运维同学重平衡也无法生效,于是我们思考应该如何从开发角度解决这个问题,究其根本原因是key太大,存储的数据太多,那么我们的场景并没有统计功能,也就是说这个key我们可以拆开,降低单个key的大小,QPS自然也就降低下去了。
如图:
优化后重新写入数据,我们可以清晰看出倾斜的数据节点恢复正常了
2.巧用布隆过滤器优化大对象
上面我们dump了系统空闲水位的大对象也进行优化了,那么代码运行时产生的局部大对象,我们的优化思路时什么呢,正好我们的代码中,有一个很大的set存储商品集(可以理解为一些条件的skc集合)全量的skc,用于商品更新的时候和上一次数据进行对比产生增量,你可以理解为一个集合数据要更新,那么更新后产生了哪些新增的数据我们怎么知道呢,肯定是存了一份之前的历史数据,那这个数据就装在set,现在的问题是需要更新的商品集很多,所以set也很多,导致set的大对象的频繁创建和回收,触发GC压力很大
我们的优化思路是,1.首先这个set不是用于常驻查询,换句话说就不是热key,用于临时操作,那么放在redis就得不偿失了,当然了也是可以做到,2.这个set的作用主要用于存储全量进行判断是否存在,但是问题在于内存开销大,有没有一种结构可以内存占用小又可以判断元素是否存在,这个容器就是即布隆过滤器
我们利用guava的布隆过滤器写个简单的程序说明优化流程,以及内存占用对比
public class BloomFilterUtils {/*** builderBloomFilter** @param size 长度* @param fpp 误判率* @return*/public static BloomFilter<String> builderBloomFilter(int size, double fpp) {BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), size, fpp);return bf;}public static void main(String[] args) {HashSet<String> set = new HashSet<>();ArrayList<String> list = new ArrayList<>();//存储1000w元素,误判率百万分一,即10个误判BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), 1000 * 10000, 0.0000001d);for (int i = 0; i <= 1000 * 10000; i++) {String skc = UUID.randomUUID().toString();set.add(skc);list.add(skc);bf.put(skc);}System.out.println("布隆内存占用 = " + RamUsageEstimator.humanSizeOf(bf));System.out.println("set 内存占用:" + RamUsageEstimator.humanSizeOf(set));System.out.println("list 内存占用:" + RamUsageEstimator.humanSizeOf(list));}
}
运行结果:

可以看出1000w-skc(字符串模拟skc)的存储,set占用最高,因为要记录额外的信息(hashcode)用于判重,list结构其次,而布隆仅仅为35分之一(受误判率影响),当然业务场景要允许存在个别误判
三:总结
昨晚上述优化后,我们成功将gc时间降低到5s内

- 对于jvm大对象的优化,我们要在于要明确大对象为什么会产生,结合业务和相关技术,采取最优的方式,既优化了大对象,也不损失性能甚至还能提速,而不是八股文中的直接移除一刀切
2)oom或者gc时间增长的问题,并不是出现问题才排查修复,我们更应该关注和监控系统空闲时水位线,不要让内存慢慢的泄漏,从而导致出现压死骆驼的最后一个稻草时,我们才能发现,那样就太慢了