一、前言
此示例演示如何训练 PointNet 网络以进行点云分类。
点云数据由各种传感器获取,例如激光雷达、雷达和深度摄像头。这些传感器捕获场景中物体的3D位置信息,这对于自动驾驶和增强现实中的许多应用非常有用。例如,区分车辆和行人对于规划自动驾驶汽车的路径至关重要。然而,由于每个对象的数据稀疏性、对象遮挡和传感器噪声,使用点云数据训练稳健分类器具有挑战性。深度学习技术已被证明可以通过直接从点云数据中学习强大的特征表示来解决其中的许多挑战。点云分类的开创性深度学习技术之一是PointNet。
此示例在悉尼大学创建的悉尼城市对象数据集上训练 PointNet 分类器。该数据集提供使用激光雷达传感器从城市环境中获取的点云数据的集合。该数据集包含来自 100 个不同类别(如汽车、行人和公共汽车)的 14 个标记对象。
二、加载数据集
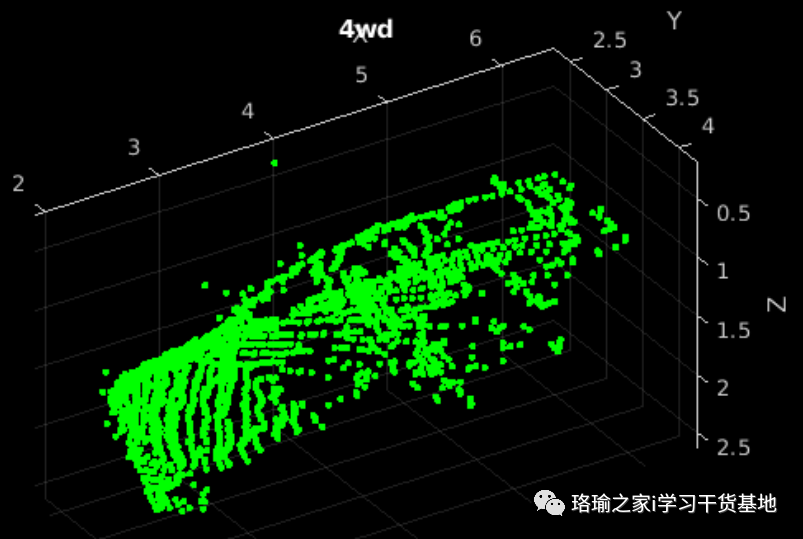
下载悉尼城市对象数据集并将其提取到临时目录。使用此示例末尾列出的帮助程序函数加载下载的训练和验证数据集。使用前三个数据折叠进行训练,使用第四个数据折叠进行验证。读取其中一个训练样本并使用 进行可视化。
阅读标签并计算分配给每个标签的点数,以更好地了解数据集中标签的分布。接下来,使用直方图可视化类分布。
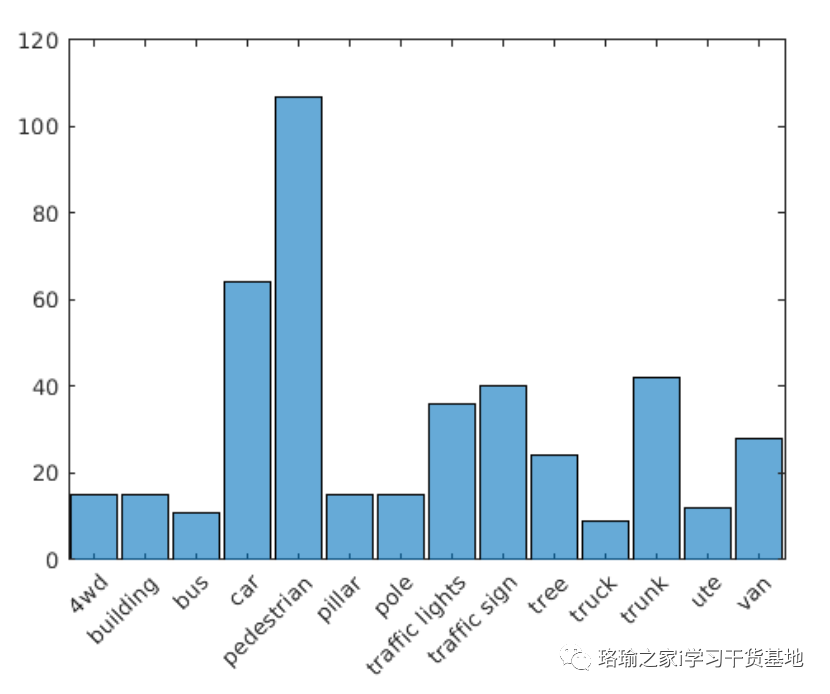
标签直方图显示数据集不平衡且偏向于汽车和行人,这可能会阻止对稳健分类器的训练。您可以通过对不常见的类进行过采样来解决类不平衡问题。对于悉尼城市对象数据集,复制与不常用类对应的文件是解决类不平衡的简单方法。
按标签对文件进行分组,计算每个类的观测值数,并使用此示例末尾列出的帮助程序函数将文件随机过采样为每个类所需的观测值数。
三、数据增强
复制文件以解决类不平衡会增加网络过度拟合的可能性,因为许多训练数据是相同的。为了抵消这种影响,请使用 and helper 函数对训练数据应用数据增强,该函数随机旋转点云、随机删除点,并使用高斯噪声随机抖动点。
预览其中一个增强训练样本。
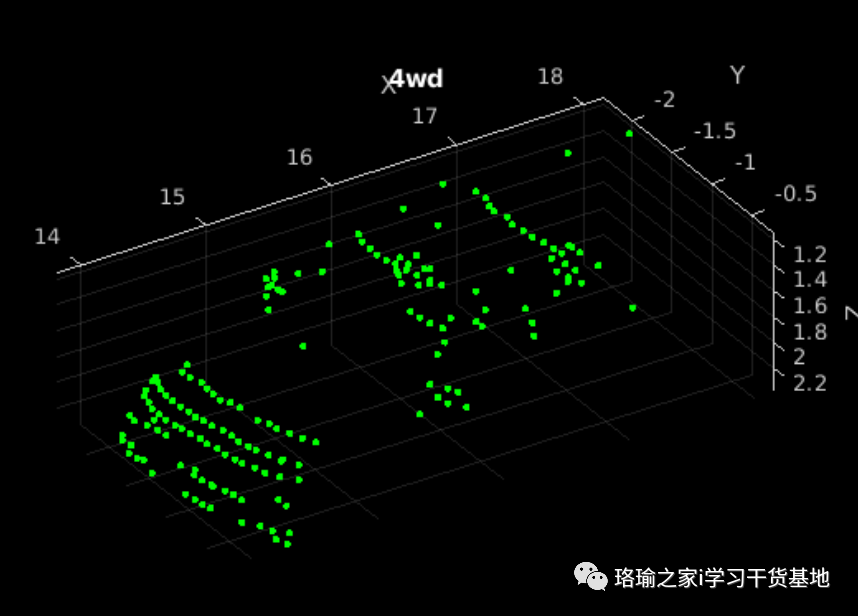
请注意,由于用于测量训练网络性能的数据必须代表原始数据集,因此数据增强不会应用于验证或测试数据。
四、数据预处理
准备用于训练和预测的点云数据需要两个预处理步骤。
首先,要在训练期间启用批处理,请从每个点云中选择固定数量的点。最佳点数取决于数据集和准确捕获对象形状所需的点数。为了帮助选择适当的点数,请计算每个类的最小、最大和平均点数。
由于每个班级的点数存在大量的类内和类间差异,因此很难选择适合所有类的值。一种启发式方法是选择足够的点来充分捕获对象的形状,同时不会通过处理太多点来增加计算成本。值 1024 可在这两个方面之间进行良好的权衡。您还可以根据实证分析选择最佳点数。但是,这超出了此示例的范围。使用该函数在训练和验证集中选择 1024 个点。
最后一个预处理步骤是规范化 0 到 1 之间的点云数据,以解决数据值范围的巨大差异。例如,与距离较远的对象相比,靠近激光雷达传感器的对象具有较小的值。这些差异可能会阻碍训练期间网络的收敛。用于规范化训练集和验证集中的点云数据。
预览增强和预处理的训练数据。
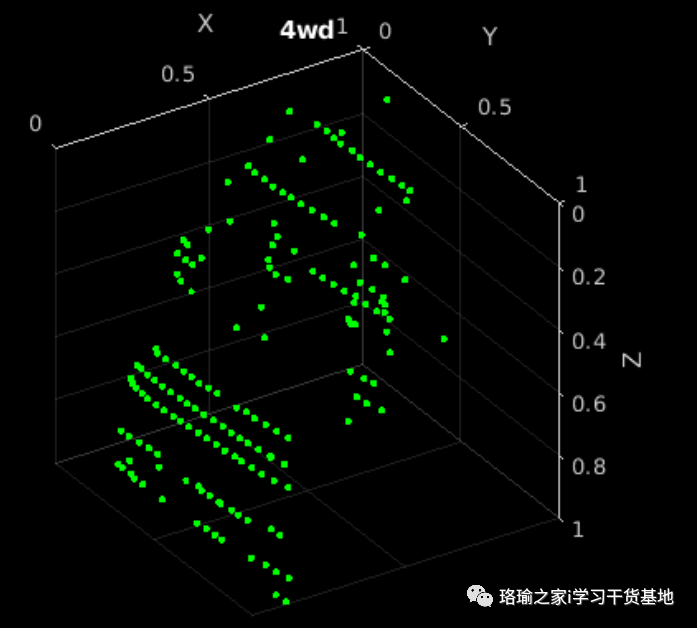
五、定义点网模型
PointNet 分类模型由两个组件组成。第一个组件是一个点云编码器,它学习将稀疏的点云数据编码为密集的特征向量。第二个组件是一个分类器,用于预测每个编码点云的分类类。
PointNet 编码器模型进一步由四个模型组成,然后是最大操作。
-
输入转换模型
-
共享 MLP 模型
-
特征转换模型
-
共享 MLP 模型
共享 MLP 模型是使用一系列卷积、批量归一化和 ReLU 操作实现的。卷积操作的配置使得权重在输入点云中共享。变换模型由共享 MLP 和应用于每个点云的可学习变换矩阵组成。共享 MLP 和 max 操作使 PointNet 编码器对点的处理顺序不变,而转换模型则为方向变化提供不变性。
5.1 定义点网编码器模型参数
共享 MLP 和变换模型由输入通道数和隐藏通道大小进行参数化。此示例中选择的值是通过在悉尼城市对象数据集上调整这些超参数来选择的。请注意,如果要将 PointNet 应用于其他数据集,则必须执行其他超参数优化。
将输入转换模型输入通道大小设置为 64,将隐藏通道大小设置为 128、256 ,并使用此示例末尾列出的帮助程序函数初始化模型参数。
将第一个共享 MLP 模型输入通道大小设置为 64,将隐藏通道大小设置为 ,并使用此示例末尾列出的帮助程序函数初始化模型参数。
将特征转换模型输入通道大小设置为 64,将隐藏通道大小设置为 64、128 和 256,并使用此示例末尾列出的帮助程序函数初始化模型参数。
将第二个共享 MLP 模型输入通道大小设置为 64,将隐藏通道大小设置为 64,并使用此示例末尾列出的函数初始化模型参数。
5.2 定义点网分类器模型参数
PointNet 分类器模型由共享 MLP、完全连接操作和 softmax 激活组成。将分类器模型输入大小设置为 64,将隐藏通道大小设置为 512 和 256,并使用此示例末尾列出的帮助程序函数初始化模型参数。
六、定义点网功能
创建示例末尾的“模型函数”部分中列出的函数,以计算 PointNet 模型的输出。函数模型将点云数据、可学习模型参数、模型状态以及指定模型是否返回训练或预测输出的标志作为输入。网络返回用于对输入点云进行分类的预测。
七、定义模型梯度函数
创建示例的“模型梯度函数”部分中列出的函数,该函数将模型参数、模型状态和小批量输入数据作为输入,并返回相对于模型中可学习参数的损失梯度和相应的损失。
八、指定训练选项
训练 10 个 epoch,并以 128 个周期为批次加载数据。将初始学习率设置为 0.002,将 L2 正则化因子设置为 0.01。初始化 Adam 优化的选项。
九、训练点网
使用自定义训练循环训练模型。
在训练开始时随机播放数据。
对于每次迭代:
-
读取一批数据。
-
评估模型梯度。
-
应用 L2 权重正则化。
-
用于更新模型参数。
-
更新训练进度图。
在每个纪元结束时,根据验证数据集评估模型,并收集混淆指标,以随着训练的进行来衡量分类准确性。
完成 epoch 后,将学习率降低 .
初始化参数梯度的移动平均值和 Adam 优化器使用的梯度的元素平方。
如果为 true,则训练模型。否则,请加载预训练网络。
请注意,训练是在具有 12 GB GPU 内存的 NVIDIA Titan X 上验证的。如果您的 GPU 内存较少,则可能会在训练期间耗尽内存。如果发生这种情况,请降低 .训练此网络大约需要 5 分钟。根据您的 GPU 硬件,可能需要更长的时间。显示验证混淆矩阵。
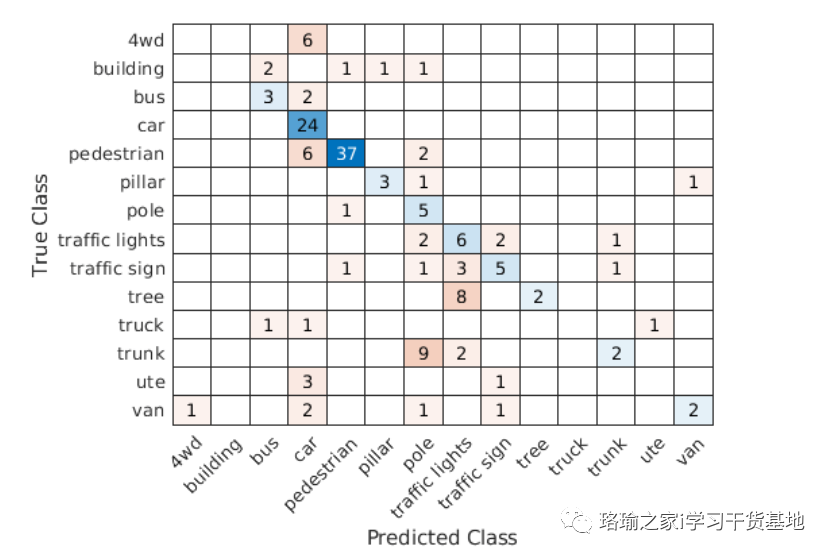
计算平均训练和验证准确性。由于悉尼城市对象数据集中的训练样本数量有限,因此将验证准确率提高到 60% 以上具有挑战性。在没有帮助程序函数中定义的增强的情况下,该模型很容易过度拟合训练数据。为了提高 PointNet 分类器的健壮性,需要进行额外的培训。
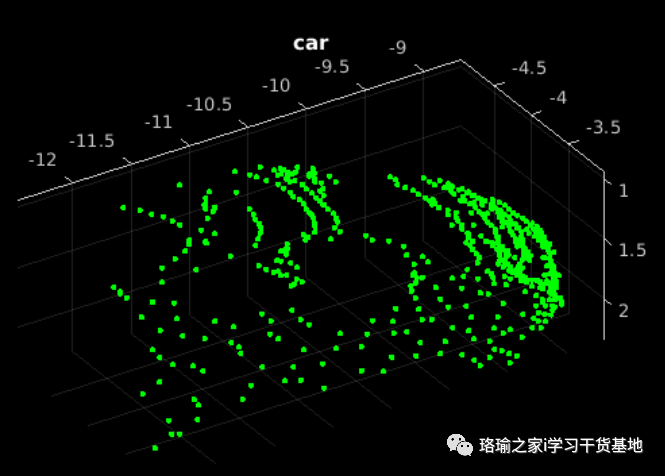
十、使用点网对点云数据进行分类
加载点云数据,使用训练期间使用的相同函数预处理点云,使用模型函数预测点云标签。显示得分最高的点云和预测标签。
十一、模型梯度函数
函数将一小批数据、相应的目标和可学习的参数作为输入,并返回相对于可学习参数和相应损失的损失梯度。损失包括一个正则化项,旨在确保 PointNet 编码器预测的特征转换矩阵近似正交。要计算梯度,请使用训练循环中的函数评估函数。
十二、点网分类器函数
该函数将点云数据 dlX、可学习模型参数、模型状态和标志 isTraining作为输入,该标志指定模型是返回用于训练还是预测的输出。然后,该函数调用 PointNet 编码器和多层感知器来提取分类特征。在训练期间,每次感知器操作后都会应用dropout。在最后一个感知器之后,操作将分类特征映射到类的数量,并使用softmax激活将输出规范化为标签的概率分布。PointNet 编码器预测的概率分布、更新的模型状态和特征转换矩阵作为输出返回。
十三、程序
使用Matlab R2022b版本,点击打开。(版本过低,运行该程序可能会报错)
程序有偿获取:评论区下留言,博主看到会私信你。