目录
一,什么是map和set
二,set的使用
插入
键值对
删除(erase)与查找
lowerbound与upperbound
equal_range
multiset
三,map的使用
insert
查找
删除
重载[ ]
编辑
一,什么是map和set
C++中的Map和Set都是关联式容器,用于存储数据的集合。
所谓关联式容器,不同于序列式容器,序列是容器是一种线性结构用来存放数据,而关联式容器,虽然也是存放数据的,但是他们的数据与存放的key值,是一一对应的,利用键值查找数据或修改数据。
它们之间的区别在于:
Map是一组键值对的结构,类似于JSON对象。每个元素都是由一个关键字和一个值组成。关键字起到索引的作用,值则表示与索引相关联的数据。Set对象类似于数组,且成员的值都是唯一的.
Map可以通过get方法获取值,而set不能因为它只有值.
Set的迭代器是const的,不允许修改元素的值;map允许修改value,但不允许修改key.
在C++中,Map和Set都是STL(标准模板库)的一部分。它们都有自己的特定语法和用法。例如,要使用Map,您需要包含头文件<map>,而要使用Set,您需要包含头文件<set>。这些容器都提供了许多有用的方法,例如插入、删除、查找等等。希望这些信息能够帮助你更好地理解它们之间的区别。
对于map和set,我们首先要知道他们的底层就是一颗搜索二叉树,因此对于他们的功能和性质我们要知道会有限制以及搜索树特殊的性质,
二,set的使用

可以看到库里给出的实现,首先只有一个数据的类型模板T,之后就是仿函数compare用来比较,一个空间配置器为我们开辟对应的空间。
因为set只有一个参数,故此它的key也就是它的数据,也就是一个key模型。
我们再来看看它的内容:

成员函数构造与析构,这里需要提到的一点是,对于节点的拷贝与释放,代价是比较大的,因此析构与拷贝构造需要我们去好好使用。
之后的迭代器,容量等我们在学习STL其他容器大致也能明白如何使用。
对于任何一个数据模型,最为重要的功能无非是增,删,查,改,这四个功能,但底层是搜索树,这是不存在修改的,因为set只是一个单纯的key模型。
插入
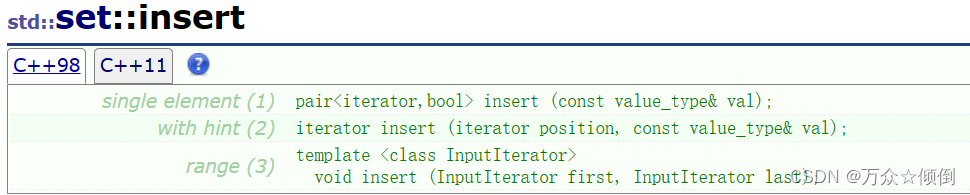
库里给出了三种插入的方式,直接插入,利用迭代器确定位置插入(谨慎使用,可能会破坏树结构),利用迭代器插入一连串的数据。一般我们就是用第一个插入数据。
我们简单的使用一下:
void test1()
{set<int> s;s.insert(2);s.insert(1);s.insert(5);s.insert(4);s.insert(9);s.insert(4);//迭代器遍历set<int>::iterator it = s.begin();while (it != s.end()){cout << *it<<" ";it++;}cout << endl;
}首先插入元素后,利用迭代器遍历插入的数据我们发现书记已经排好序了,其次相同的数据只会插入一个,这与我们之前学习到的搜索二叉树一样,而这里的遍历,实际上就是走了一个中序遍历,且在相同值插入的时候会判断直接返回。
键值对
其次对于函数的返回值,也是一个我们没见过的pair,这个其实就是一个键值对,在这里,封装了两个数据,我们来看看它定义:

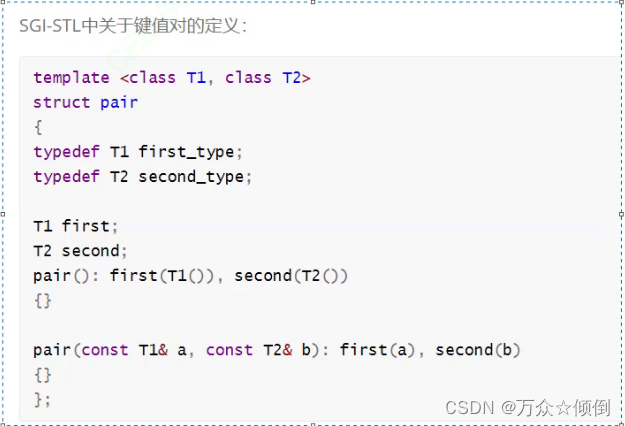
一共封装了两个数据以及它们对应的模板参数,一个first,一个second分别代表了两个数据,
利用这种方式函数可以返回两个数据。而这里对于我们的set,first就是一个迭代器表示这个节点,second是一个bool值,表示是否插入成功。
pair<set<int>::iterator, bool> p = s.insert(5);//利用pair p接收返回值删除(erase)与查找
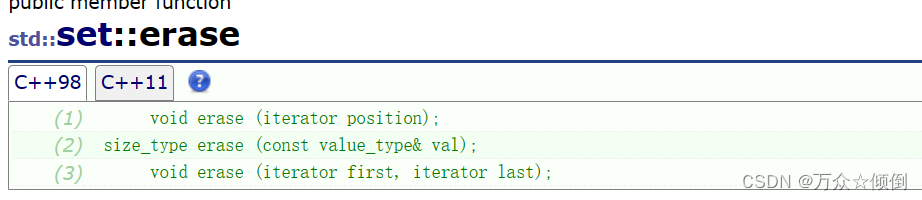

删除的方式与插入的方式类型,我们可以直接给值,给迭代器位置,给迭代器区间都可以。
而这里就可以与find配合起来,find的返回值就是迭代器类型。
其次就是比较特殊的两个接口函数:
lowerbound与upperbound
我们可以直接看看库里给的测试:
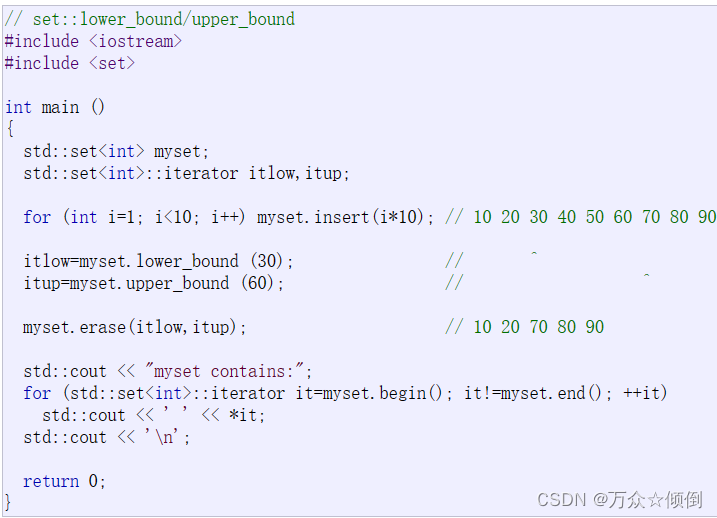
可以看到,通过lowerbound和upperbound的返回值,我们删除了某一段迭代器,这里itlower返回30,upperbound返回70,迭代器区间就是[30~70],实际上,upperbound返回的是一个比参数大的迭代器,lowerbound返回的是比参数小于或等于的迭代器。通过这种方式我们可以找迭代器区间,返回这个区间是,删除函数接收到删除的是[30~70)区间的迭代器。
类似的区间还有
equal_range


可以看到equal_range的返回值是一个pair,里面放封装了两个迭代器,根据测试,可以看到第一个是一个比参数大于等于的迭代器,第二个是比参数大于的迭代器。
multiset
了解完set之后,库里其实还有一个与set基本一致的结构-multiset,所谓的multiset本质上与set的区别就是multiset可以存放相等的数据:
void test1()
{multiset<int> s;s.insert(2);s.insert(1);s.insert(1);s.insert(1);s.insert(5);s.insert(4);s.insert(9);//迭代器遍历multiset<int>::iterator it = s.begin();while (it != s.end()){cout << *it<<" ";it++;}cout << endl;
}对于寻找,若有多个一样的,返回第一个找到的val的节点。
且此时的mulyiset对上述的接口equal_range与count等函数接口配合使用可以对相同的元素更加灵活的操作。
三,map的使用
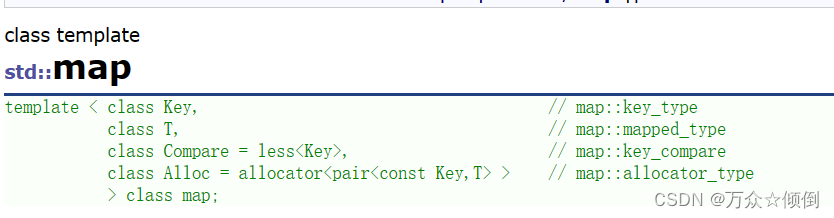
首先来看看map的定义,模板参数中,给了key值的类型模板,数据T的类型模板,利用仿函数实现的一个比较,一个空间配置器用来开辟空间。
与set的区别是多了一个数据类型,对于set来说是key模型,那么对于map来说就是一个key_value模型,通过键值key来获取对应的数据value。
之后便是与set如出一辙的构造析构,迭代器等基本的实现,我们还是主要来看看增删查改。
insert

map的insert与set基本近似,但是我们这里不是两个数据模板参数吗?为什么这里传入参数只有一个,且类型为value_type,此时我们需要在求助于库看一看:

这里的valuetypr实际上是key_type与mapped_type两个类型参数封装起来的pair,即这个value —_type本质上是一个pair类。
其次对于这里的pair是很灵活的,pair是支持带参数的拷贝构造的,这奥我们的类型能初始化参数,那么类型即使看起来不一样但同时初始化字符串。

除了一个个显式实例化pair,我们自己还可以直接用make_pair传入参数自动生成对应的pair对象,并且在传入参数时,不需要再一个个的显示类型实例化,直接传入pair匿名对象。
其次插入的返回值也是一个pair对象,这里第一个表示该迭代器,第二个表示是否插入,其次迭代器中存放的也是pair,第一个表示key,第二个表示value。
之后通过map我们轻松的就可以创建一个字典模型:
void test2()
{map<string, string> dictionary;dictionary.insert(pair<string, string>("a", "abanden"));dictionary.insert(pair<string, string>("b", "bacteria"));dictionary.insert(pair<string, string>("c", "cabbage"));dictionary.insert(pair<const char*, const char*>("d", "data"));dictionary.insert(make_pair("e", "erase"));map<string, string>::iterator it = dictionary.begin();while (it != dictionary.end()){cout <<(*it).first <<" ";cout << (*it).second << endl;it++;}cout << endl;
}查找

可以清晰地看到find的返回值是迭代器,参数是key,即通过键值找对应的value.
删除

删除是通过迭代器或者key值删除的,也是可与find配合使用。
重载[ ]
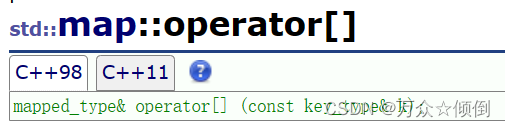

对于这里的重载[ ],这里我们自己刚开始看可能搞不懂,我们可以仔细观察对于重载operator,它的本质就是insert(key)的返回值pair中的迭代器(insert().first)的second,即就是我们的value值,它是通过这种方式来访问key值处的value。
通过重载[ ],我们直接访问到key处的value,查找更加简单方便。



![[架构之路-254/创业之路-85]:目标系统 - 横向管理 - 源头:信息系统战略规划的常用方法论,为软件工程的实施指明方向!!!](https://img-blog.csdnimg.cn/74a4f8b6f7f4410bb73a8a165d306f78.png)