目录
1、为什么引入集群
1.1、先来了解集群是什么
1.2、哨兵模式的缺陷 + 引入集群解决了什么问题
1.3、使用集群,如何存储数据
2、三种主流的分片方式【经典面试题】
2.1、哈希求余算法
2.1.1、哈希求余算法的介绍
2.1.2、哈希求余算法如何扩容
2.2、一致性哈希算法
2.2.1、一致性哈希的流程
2.2.1、一致性哈希算法中如何扩容
2.3、哈希槽分区算法
2.3.1、哈希槽分区算法介绍
2.3.2、哈希槽分区算法相关问题说明
3、Redis采用哪种分片方式
4、搭建集群环境(基于docker)
4.1、创建目录
4.2、使用.sh脚本批量生成配置文件
4.3、编写docker-compose.yml文件
4.4、启动容器
4.5、构建集群
5、使用集群
6、故障处理-主节点挂了
6.1、故障判定
6.2、故障迁移
6.3、集群宕机
7、集群扩容
第一步:把新的主节点加入到集群
第二步:重新分配slots
第三步:给新的主节点添加从节点
8、删除主节点
1、为什么引入集群
1.1、先来了解集群是什么
- 广义上来说,只要是多个机器构成了一个分布式系统,都可以称为是一个“集群”
- 狭义上来说,Redis提供的集群模式,这个集群模式之下,这要是解决存储空间不足而需要拓展存储空间的问题
举例来说,我们前面提到过的主从复制和哨兵模式就属于是“广义上的集群”;Redis中的集群模式叫做狭义上的集群,也就是我们本篇文章要介绍的集群~
1.2、哨兵模式的缺陷 + 引入集群解决了什么问题
哨兵 + 主从复制只能提高可用性,而不能提高数据的存储容量,当我们需要存的数据接近或超过机器的物理内存时,就需要引入更多的机器来存储数据。
这种情况下,对数据的管理,只是使用哨兵和主从复制就难以胜任,引入集群后,不论是数据管理也好,还是后续存储空间需要扩容,都会更加友好的处理~
总结一句话,引入集群就是解决了扩容问题~
1.3、使用集群,如何存储数据
假设有1TB的数据需要存储,我们此时使用集群的方式存储,例如分为三台机器来存储,如图:
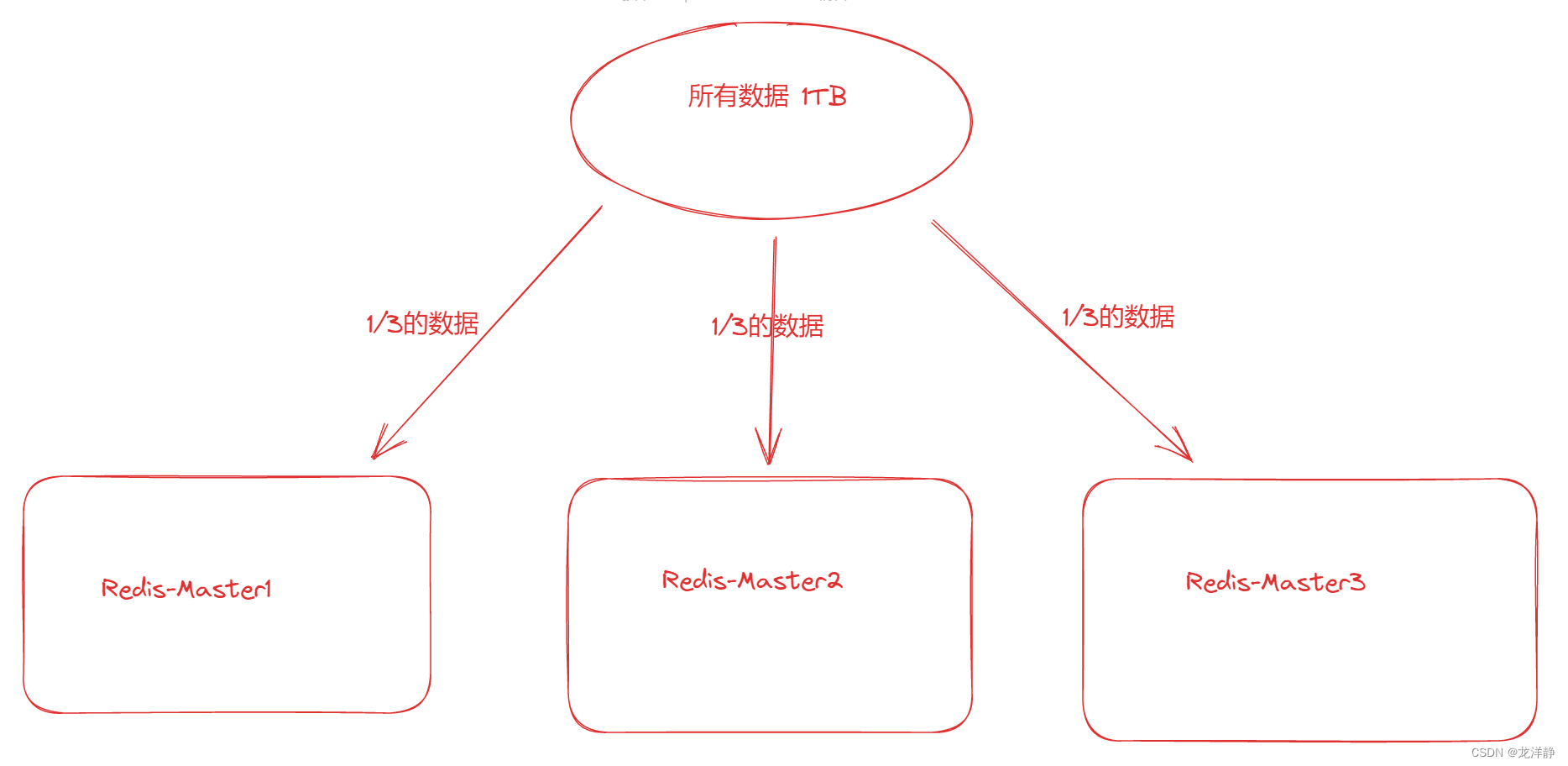
但实际上是不止这么几台机器的,还有从节点呢~

上述中每个篮框部分,就是一个分片(Sharding),当需要更多的存储空间时,增加更多的分片即可~
那么在这里又会引入一个新的问题,把数据分成多份,怎么分?
下面介绍了三种主流的分片方式~
2、三种主流的分片方式【经典面试题】
2.1、哈希求余算法
2.1.1、哈希求余算法的介绍
小伙伴们肯定多少对哈希表的基本思想会有一点了解的,我就不具体解释了~
在这里的分片方式中,简单来说就是借助一个哈希函数把key映射到整数,再针对数组的长度求余,就可以得到一个数组下标啦~
说明一:把key映射到整数
因为求余中,当然是要求该数为整数,而key值不一定为整数,所以我们借助映射来得到每个不同的key所对应的整数。例如使用md5,就可以将一个字符串经过一系列的数学变换将其转换为一个整数【十六进制,并且计算出的所有字符串的长度都是固定的;结算出的结果比较分散,两个高度相似的字符串计算出的结果差异会很大;计算结果是不可逆的】
说明二:针对数组长度求余,分片方式中,数组长度怎么确定
我们使用上述得到的整数模上一个分片数量。这里其实就是把分片的数量作为是数组长度~
例如我们这里有三个分片,编号为 0、1、2:

结合上图,也就是假设有几个key被转换为整数后为0 1 2 3 4 5 6 7 8 9 10 11,给这些整数模3,在就可以把对应key的数据存储进去 ~
在进行查询时,也是一样的步骤,先把key转换为整数,然后求余,再去对应的机器中查找~
2.1.2、哈希求余算法如何扩容
具体如何扩容,我们结合上面的例子来说,上面说假设有3个分片来存储,那我们再假设这个三个分片存储数据不够了,要进行扩容,需要我们再增加一个分片~
此时增加分片后,我们需要对数据整理,也就是说原本的数组长度为3,此时变成了4,原本储存的那一大批数据就需要拿出来,重新存进去,如图:
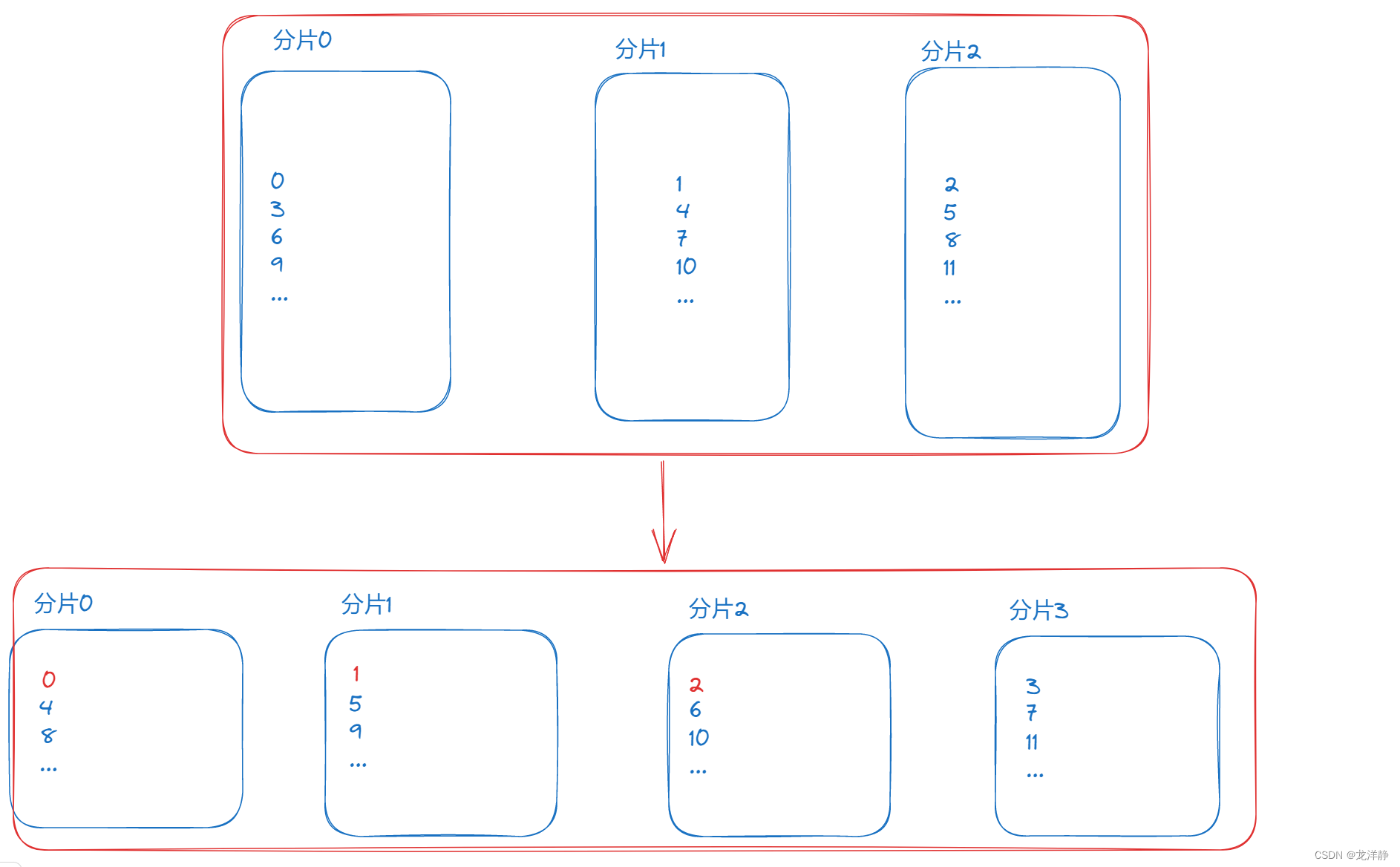
我们能看到,原本的12个数据,再次整理后,只有三个【图中标红了】还在原本的分片中,按照不精确的数学统计来说,需要重新搬运的数据高达百分之七十五以上~
而且根据上图,我们能看到这里扩容时,是通过“替换”的方式来实现,搬运数据时需要单独先拿四台机器搬运,搬运完后,原本的三台机器才可以拿走到其他地方使用,相当于要同时使用七台机器,这还只是说主节点的机器呢!
总结:哈希求余算法虽然实现相对简单,但是在扩容时依赖的机器较多,成本高,操作步骤也非常复杂~
2.2、一致性哈希算法
一致性哈希最初提出来,就是为了解决上述哈希求余的缺点的,降低了扩容时搬运数据的开销,更加高效的进行扩容~
在哈希求余算法中,各个数据是交替出现,也就是说整数 0 1 2这样的连续数据的存储位置是分别在三台不同的分片(机器)上的,而一致性哈希则会将其放置在同一个分片上~
2.2.1、一致性哈希的流程
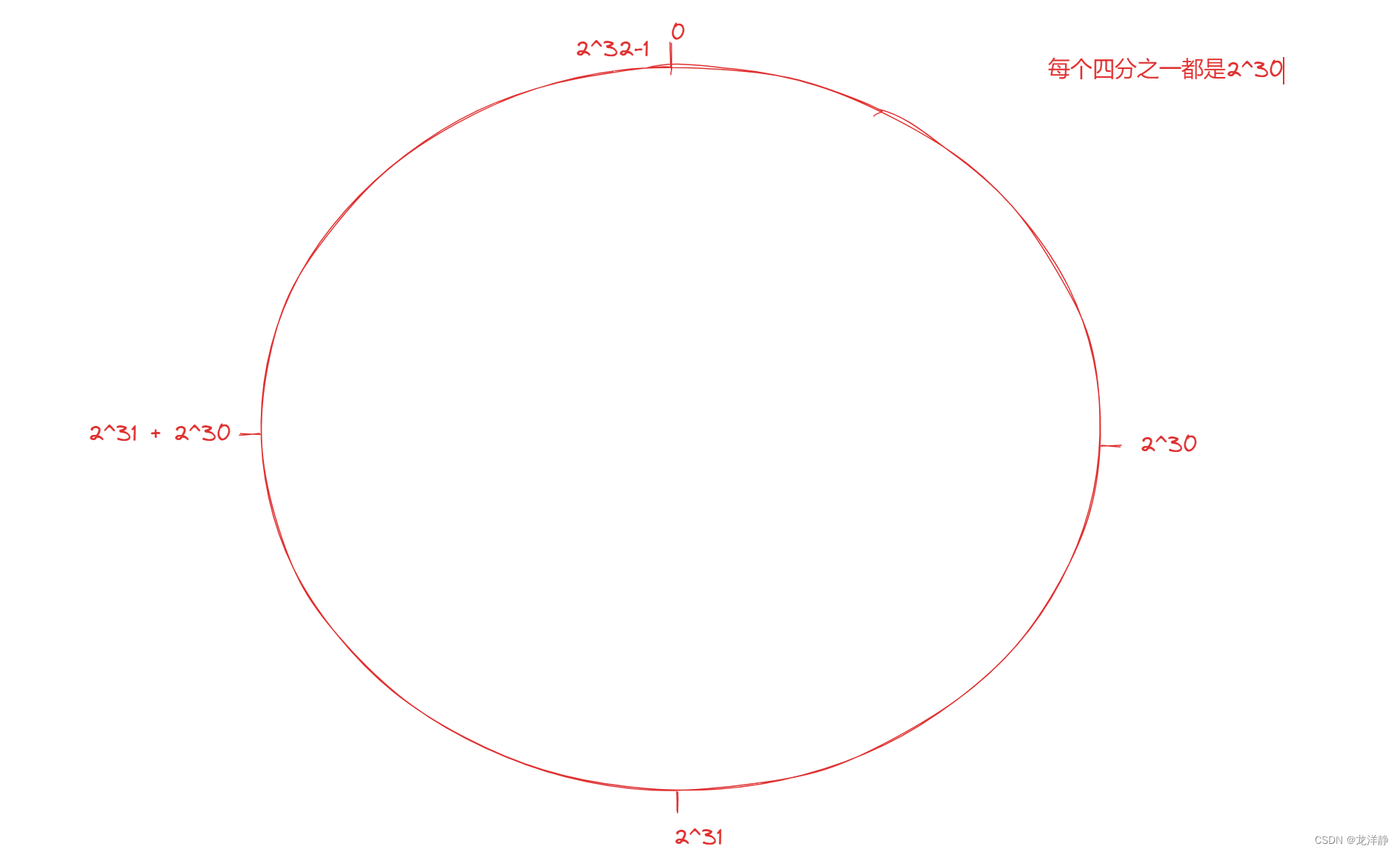
步骤一:将0~2^32-1这个数据空间,映射到一个圆环上。数据按照顺时针方向增长~
图示:
步骤二:把分片放到圆环的某个位置上
图示:

步骤三: 此时有一个key,计算得到hash值整数为H,此时就顺着这个H所在的位置顺时针往下找,找到的第一个分片就是这个key所从属的分片~
图示:
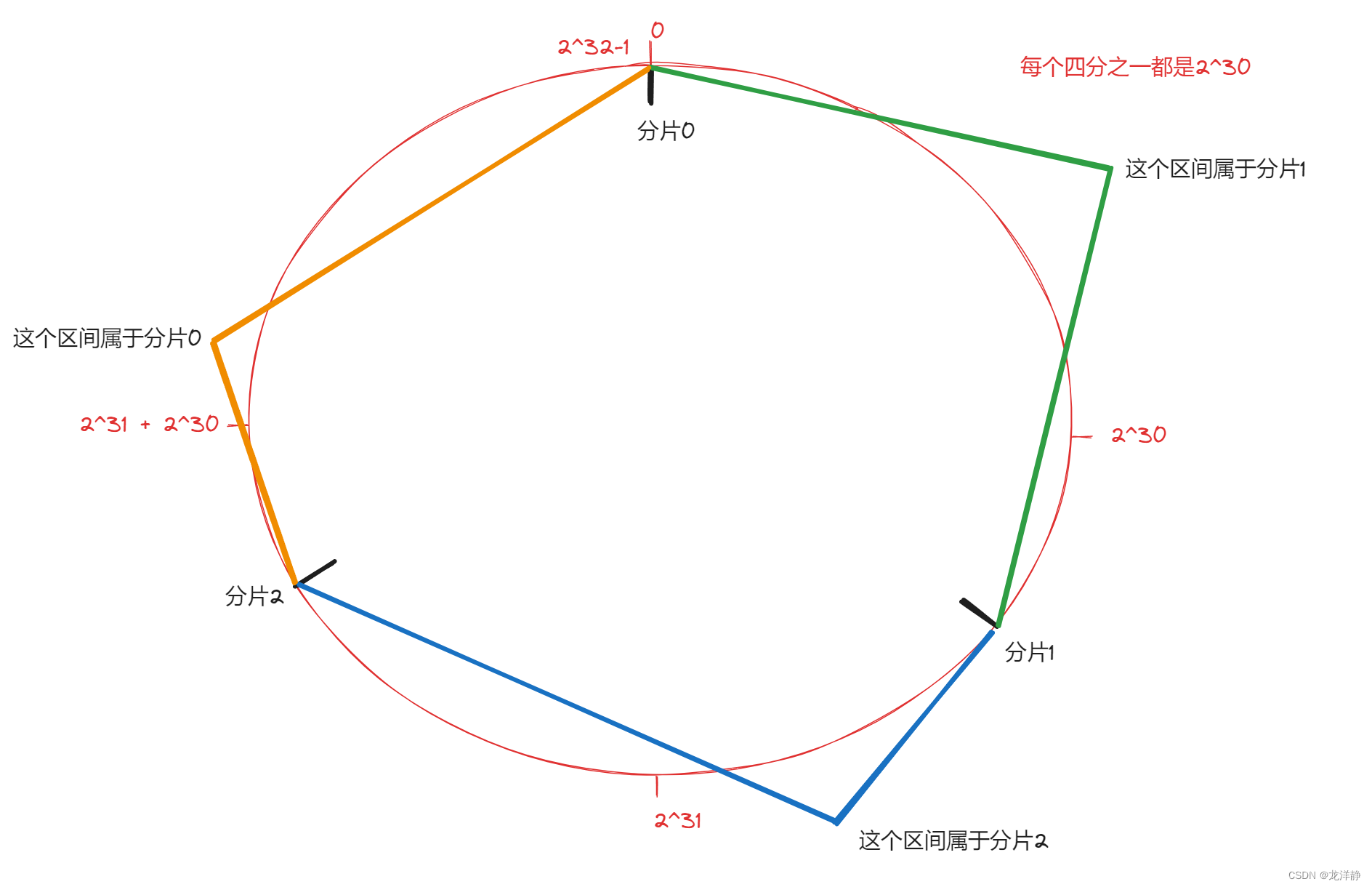
相当于是,N个分片的位置把整个圆环分成了N个管辖区间,key的hash值落在哪个区间就归对应区间管理~
2.2.1、一致性哈希算法中如何扩容
扩容结合下图来看:
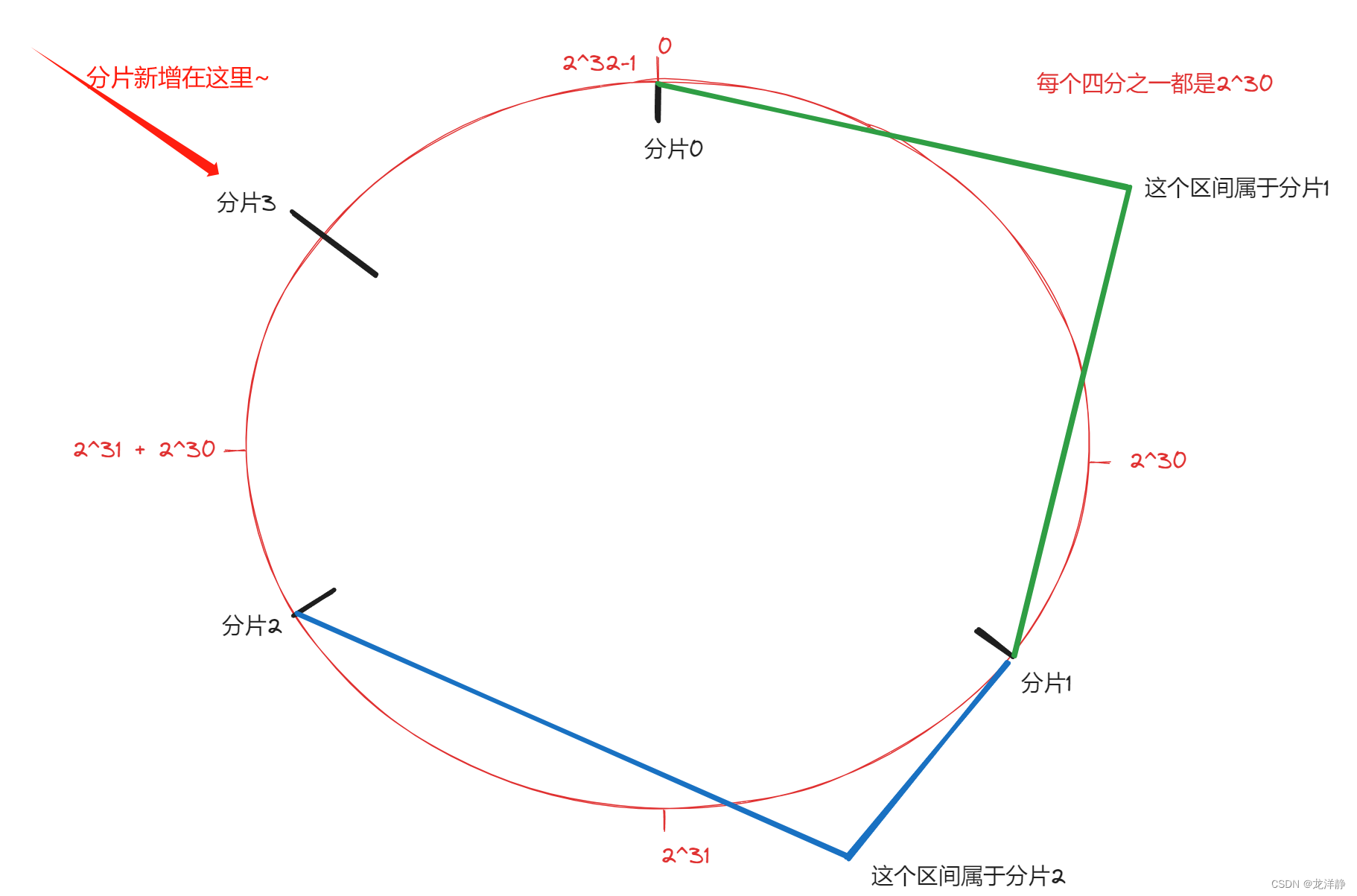
我们可以看到新增的分片放置在0号和2号分片中间,再进行数据搬运时,只需要将0号分片上一半的数据搬运到新增的3号分片上。
这种搬运方式,带来的好处:
- 搬运的成本变低
- 需要搬运的数量相对来说较少了
这种搬运方式的缺点:数据分布不均匀
这个缺点有一种解决方案就是:每次扩容多搞几个分片。这个方案虽然可行,但是又会带来新的缺点,可能会导致很多分片上数据并不多,不仅需要的机器多,而且这些机器的内存空间利用率不一定高,就会造成浪费!
2.3、哈希槽分区算法
为了解决搬运成本高和数据分布不均匀的问题,提出了哈希槽算法~
2.3.1、哈希槽分区算法介绍
首先准备16384个槽位,然后根据下列算法公式,放置key值。公式:hash_slot = crc16(key) % 16384
公式说明:
- crc16也是一种hash算法,和md5类似,计算后的值为整数~
- 16384个槽位也就是[0,16383]
- 并不是说每个槽位占据一个分片,而是把这些槽位均匀的分配给现有的分片,每个分片都需要记录自己当前有哪些槽位号~
2.3.2、哈希槽分区算法相关问题说明
问题一:分片如何分配的槽位?
这个分配是很灵活的,不一定要求每个分片持有的的槽位必须连续~
例如分配1:
- 0号分片:[0,5461],共5462个槽位
- 1号分片:[5462,10923],共5462个槽位
- 2号分片:[10924,16383],共5460个槽位
例如分配2:
- 0号分片:[0,4461] + [13385,14385]
- 1号分片:[4462,8+1923] + [14386,15386]
- 2号分片:[1923,13384] + [15387,16383]
这里采用的相对平均比较的,而不是严格的均匀~
不管在实际情况中是如何分配的,只要每个分片知道自己是持有哪些槽位即可~
问题二:分片如何记录自己当前有哪些槽位号?
每个分片都是使用“位图”的数据结构来表示出当前有多少槽位号~
也就是说,16384个bit位,用每一位0/1来区分自己这个分片当前是否持有该槽位号~
问题三:新增分片时如何处理的 ?
新增时,可根据实际情况,灵活调整(Redis中当前某个分片包含哪些槽位是可以手动配置的),下面只是一个举例:
原本:
- 0号分片:[0,5461],共5462个槽位
- 1号分片:[5462,10923],共5462个槽位
- 2号分片:[10924,16383],共5460个槽位
新增后:
- 0号分片:[0,4095],共4096个槽位
- 1号分片:[5462,9557],共4096个槽位
- 2号分片:[10924,15019],共4096个槽位
- 3号分片:[4096,5461] + [9558,10923] + [15019,16383],共4096个槽位
问题四:Redis集群是最多有16384个分片吗?
并非是Redis集群是最多有16384个分片。如果是这样的话,有16384个分片,一个分片持有一个槽位,那这对于集群的数据均匀是很难保证的,可能有的分片上有多个数据,有的分片上一个数据也没有;并且这么大规模的集群,本身的复杂度就会很高,不可避免的会导致出故障的概率就会越大~
问题五:为什么是16384个槽位?
- 原因一:节点之间通过心跳包通信,心跳包中包含了该节点持有哪些slots(槽位),这个是使用位图来表示的,表示16384(16k)个slots,需要的位图大小为2kb。如果说给定的槽位数更多了,此时就需要消耗更多的空间,例如可能需要8kb位图来表示。虽然8kb也没多大但是在频繁的网络心跳包中还是一个不小的开销~
- Redis集群一般建议不超过1000个分片(Redis官方的建议)~ 所以16k对于最大1000个分片来说是足够用的,同时也会使对应的槽位配置位图体积不至于很大~
3、Redis采用哪种分片方式
Redis采用的是分片方式3 —— 哈希槽分区算法~
4、搭建集群环境(基于docker)
我们基于docker来搭建一个集群,每个节点都是一个容器,具体搭建出来的拓扑结构如下:

接下来,我们先准备9个节点来掩饰集群的搭建【下面我们会顺便多准备2个节点,后续集群的扩容会用到~】
4.1、创建目录
看过上一篇的小伙伴,会知道我们有一个Redis目录,没有的小伙伴随便创建一个就好啦~
我们进到这个Redis目录中先创建一个redis-cluster目录,然后再创建两个文件:
红框以外的目录是上一篇用到的,没有的小伙伴,不管了~
4.2、使用.sh脚本批量生成配置文件
在Linux上以.sh后缀结尾的文件,称为“脚本”【不理解脚本是什么意思的小伙伴,可以理解他为一个“剧本”,他里面就是把一些命令放到一个文件里,让他们批量化执行。我个人感觉就是更加压榨计算机,放松双手~】
将下面的内容复制到generate.sh文件中:
for port in $(seq 1 9); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done#上下ip那里有些许差异for port in $(seq 10 11); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.1${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
说明:下图可能标注有点乱,根据我每句话前面标的序号顺序来看,会好一些~

复制进去成功后,保存退出,执行命令:sh generate.sh -->或bash generate.sh
我们可以来查看目录:
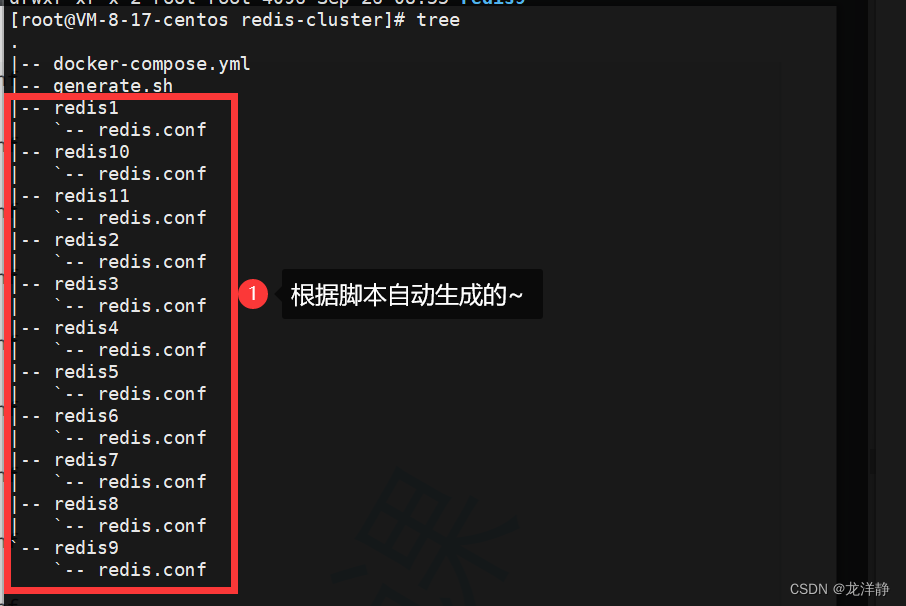
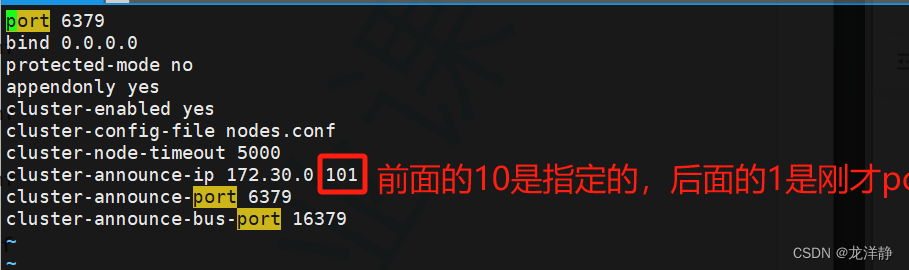
其中每个redis1/2/3/...节点中的配置文件redis.conf中的内容出ip外都是相同的,例redis1:
4.3、编写docker-compose.yml文件
将以下内容复制进刚才创建的文件docker-compose.yml中:
version: '3.3'
networks:mynet:ipam:config:- subnet: 172.30.0.0/24
services:redis1:image: 'redis:5.0.9'container_name: redis1restart: alwaysvolumes:- ./redis1/:/etc/redis/ports:- 6371:6379- 16371:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.101redis2:image: 'redis:5.0.9'container_name: redis2restart: alwaysvolumes:- ./redis2/:/etc/redis/ports:- 6372:6379- 16372:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.102redis3:image: 'redis:5.0.9'container_name: redis3restart: alwaysvolumes:- ./redis3/:/etc/redis/ports:- 6373:6379- 16373:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.103redis4:image: 'redis:5.0.9'container_name: redis4restart: alwaysvolumes:- ./redis4/:/etc/redis/ports:- 6374:6379- 16374:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.104redis5:image: 'redis:5.0.9'container_name: redis5restart: alwaysvolumes:- ./redis5/:/etc/redis/ports:- 6375:6379- 16375:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.105redis6:image: 'redis:5.0.9'container_name: redis6restart: alwaysvolumes:- ./redis6/:/etc/redis/ports:- 6376:6379- 16376:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.106redis7:image: 'redis:5.0.9'container_name: redis7restart: alwaysvolumes:- ./redis7/:/etc/redis/ports:- 6377:6379- 16377:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.107redis8:image: 'redis:5.0.9'container_name: redis8restart: alwaysvolumes:- ./redis8/:/etc/redis/ports:- 6378:6379- 16378:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.108redis9:image: 'redis:5.0.9'container_name: redis9restart: alwaysvolumes:- ./redis9/:/etc/redis/ports:- 6379:6379- 16379:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.109redis10:image: 'redis:5.0.9'container_name: redis10restart: alwaysvolumes:- ./redis10/:/etc/redis/ports:- 6380:6379- 16380:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.110redis11:image: 'redis:5.0.9'container_name: redis11restart: alwaysvolumes:- ./redis11/:/etc/redis/ports:- 6381:6379- 16381:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.1114.4、启动容器
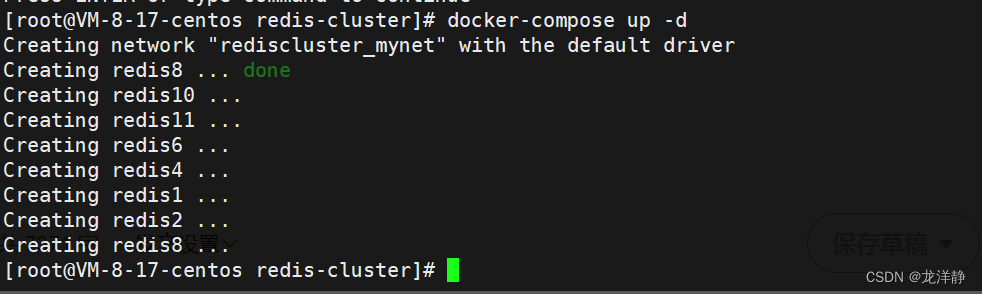
命令:docker-compose up -d
【如果自己的服务器太小的话,执行这一步,服务器可能会崩掉,大家谨慎哈~】
由于我的服务器太拉的原因,我就部署不了这么多节点了,我把从节点去掉了三个,相当于以前是每一个主节点有两个从节点,现在只有一个从节点了~
启动完毕:
4.5、构建集群
按照我们预想的是前9个主机构建成集群,3主6从。而我现在实际是3主3从~
构建命令如下:
redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379 172.30.0.103:6379 172.30.0.104:6379 172.30.0.106:6379 172.30.0.108:6379 --cluster-replicas 1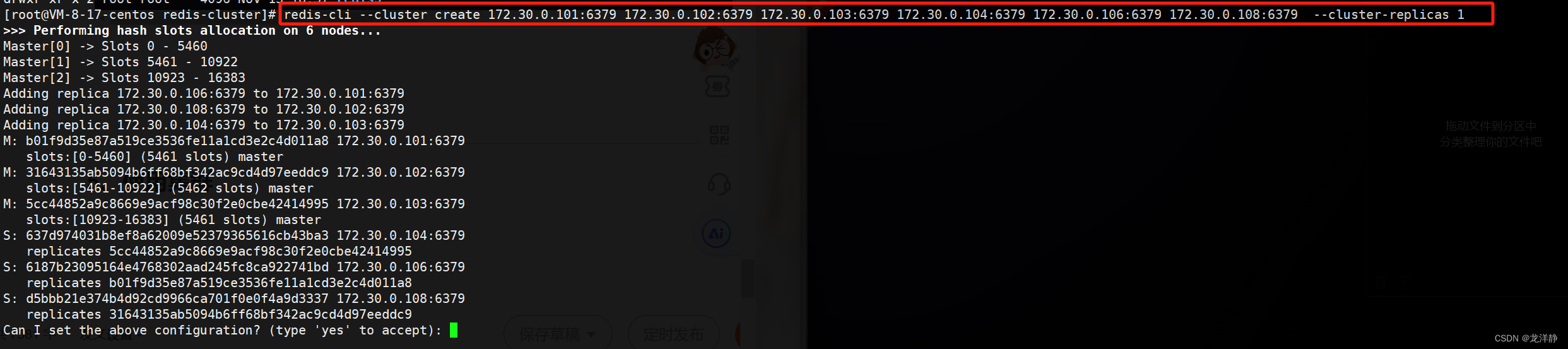
- --cluster create:表⽰建⽴集群. 后⾯填写每个节点的 ip 和地址(确保这个命令的 IP 和实际环境一致).
- --cluster-replicas 1: 表⽰每个主节点需要两个从节点备份. 这个配置设置了以后,redis 就知道 2个节点是一伙的(一个分片上的),一共 6 个节点,一共是 3 个分片.
构建集群:

构建成功:

5、使用集群
任意连接一个节点:下面是使用不同方式,连接上同一个节点:172.30.0.103:6379

说明:
- 可以通过-h 连接,也可以通过-p连接
- 使用-p直接到对外端口
查看信息:

注意点:
当我们在启动时使用 -c 选项,此时redis客户端会根据当前key计算出的槽位号,自动匹配分片的主机,进一步完成操作~
如下:

6、故障处理-主节点挂了
6.1、故障判定
判定步骤:
- 节点A给节点B发送ping包,B就会给A返回一个pong包。心跳包的ping和pong除了message type 属性之外,其他部分都是一样的,例如会包含集群的配置信息(给节点的id,该节点从属于哪个分片,是主节点还从节点,从属于于谁,持有哪些slots的位图...)。
- 每个节点,每秒钟,都会给一些随机的节点发起ping包,而不是全发一遍,这样的设定是为了避免在节点很多的时候,心跳包也很多(例如9个节点,如果全发就是72组心跳包,随机发起一个,就只用发9组心跳包)
- 当节点A给节点B发送器ping包,B不能如期回应时,A就会尝试重置和B的tcp连接,看是否可以连接成功。如果仍然连接失败,A就会把B设为PFAIL状态(主观下线)
- A判定B为Pfail后,会通过Redis内置的Gossip协议,和其他节点进行沟通,向其他节点确认B的状态(每个节点都会维护一个自己的“下线列表”,由于视角不同,每个节点的下线列表也不一定相同)
- 此时A发现其他很多节点也认为B为Pfail,并且数目超过集群总个数的一半,那么A就会把B标记成fail(客观下线)。并且会把这个消息同步给其他节点(其他节点收到之后,也会把B标记为fail)
- 至此,B就彻底被判定为故障节点了~
例如,我们现在手动将redis1停了:

连接上redis2,观察结果:

并且,后续redis1如果恢复了(重启了),他依然是从节点,因为主节点已经有了,他挂的时候,他的从节点就已经顶上了~
6.2、故障迁移
迁移流程:
- 从节点判定自己是否具有参选资格。如果从节点和主节点已经太久没通信,会认为从节点的数据和主节点的差异太大,时间超过阈值,就是失去竞选资格
- 具有竞选资格的节点,比如C和D,就会先休眠一定时间.【休眠时间 = 500ms基础时间 + [0,500ms]随机时间 + 排名*1000ms】offset的值越大,则排名越靠前
- 比如C的休眠时间到了,C就会给其他所有集群中的节点,进行拉票操作。但是只有主节点才有投票资格
- 主节点就会把自己的票投给C,当C收到的票数超过主节点数目的一半时,C就会晋升为主节点(C执行slaveof no one,并且让D执行slaveof C)
- 同时,C还会把自己成为主节点的消息,同步给其他集群的节点。其他节点也会随之更新自己保存的集群结构
上述这种算法叫做Raft算法,是一种在分布式系统中广泛使用的算计.【在随机休眠时间的加持下,基本上就是谁先唤醒,谁就能成功竞选】
6.3、集群宕机
以下三种情况,会出现集群宕机
- 某个分片,所有的节点全部挂了
- 某个分片,主节点挂了,但是没有从节点
- 超过半数的主节点都挂了
7、集群扩容
扩容原因:存储空间不够了呗。下面的扩容,最终结果就是:增加了一个主节点redis10,并且redis11作为redis10的从节点~
由于我的服务器带不起来那么多节点,所以我就直接把redis6、redis8停了,再演示扩容操作:

步骤流程:
第一步:把新的主节点加入到集群
命令:
redis-cli --cluster add-node 172.30.0.110:6379 172.30.0.101:6379说明:
- add-node:第一个ip和端口号表示新增的节点是什么,第二个ip和端口号表示集群上的任意一个节点(随便是谁都行,主要是说明要加入的是哪个集群)
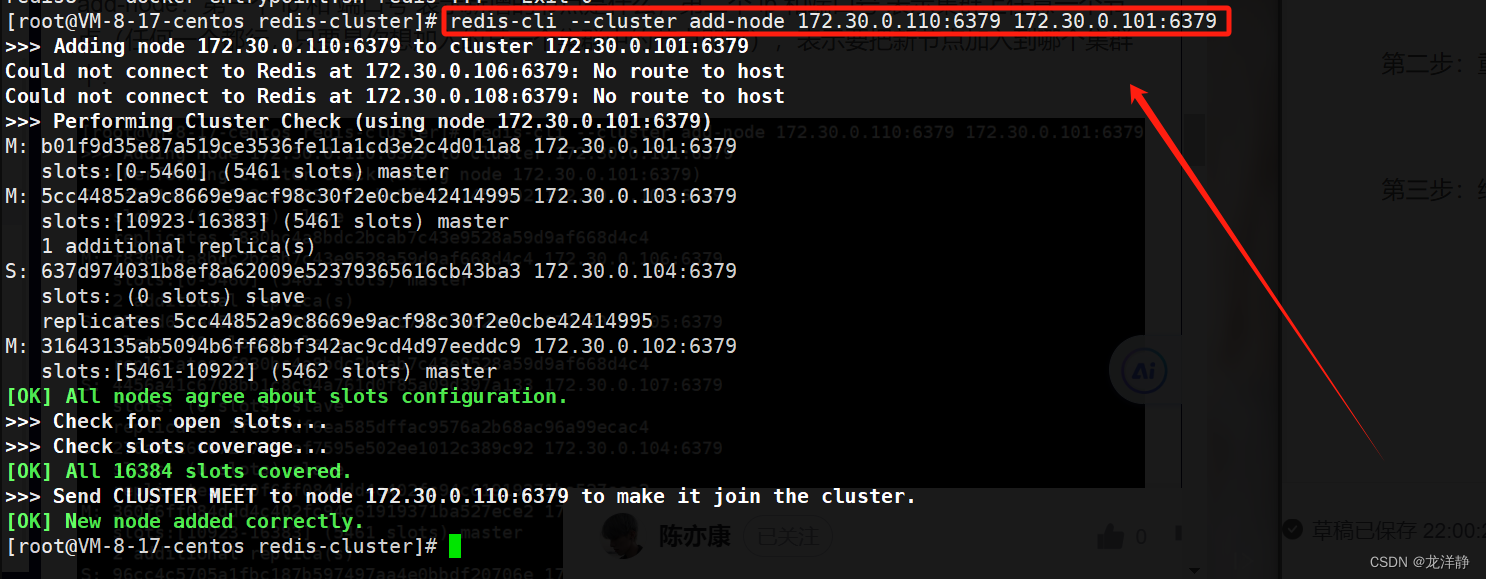
可以看到,新增的节点还没有分配slots:

第二步:重新分配slots
命令:
redis-cli --cluster reshard 172.30.0.101:6379输入命令后,会先打印出当前每个集群机器的情况,然后要求用户输入要切分多少个slots:

如果前面三个主节点,每一个都给这个新节点匀一部分slots,那么我们用16384/4即可,在这里填入4096:

输入后,又问,让哪个节点接收(填写id),我们直接粘贴redis10主机的id就可以了:
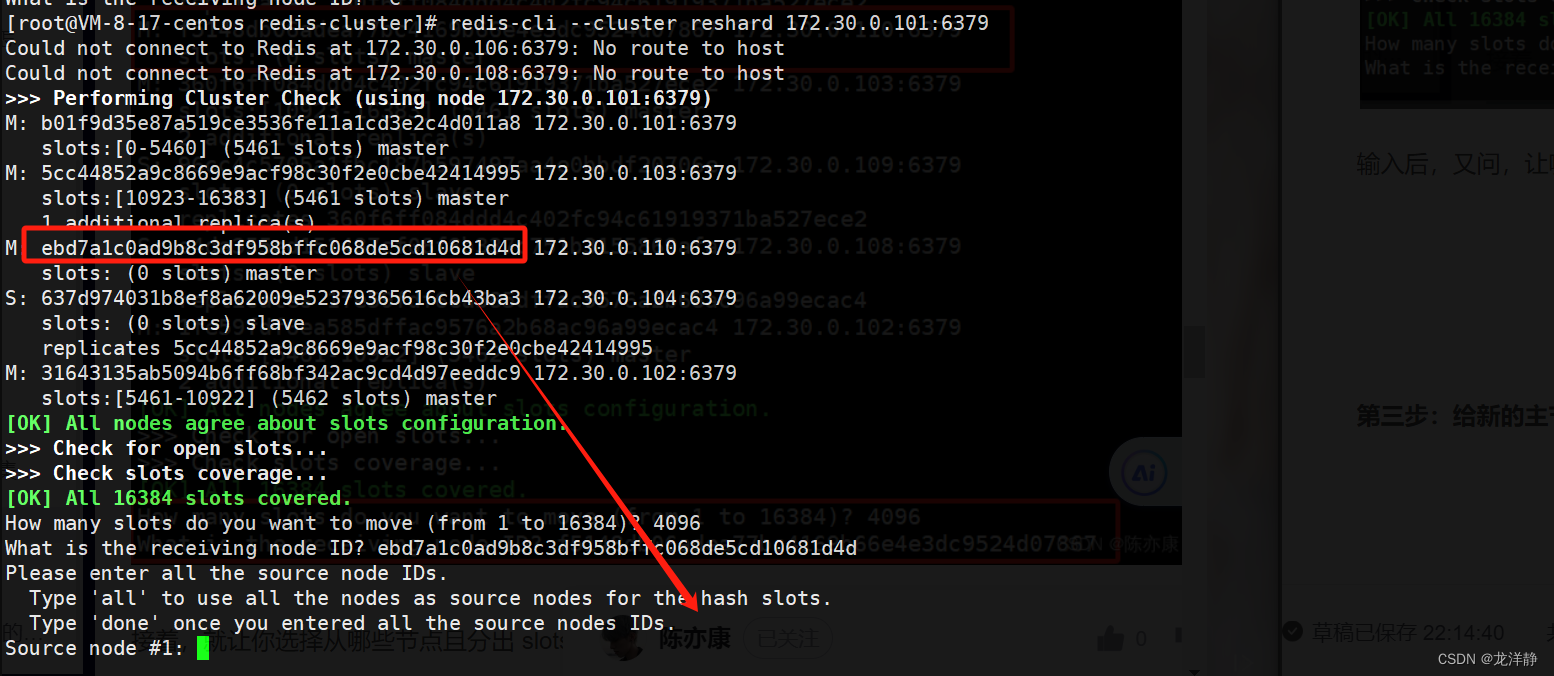
接着,又会让你选择从哪些节点且分出多少:
- all 表示所有的主节点
- 或者手动指定某个(以done结尾)
这里我们输入all:
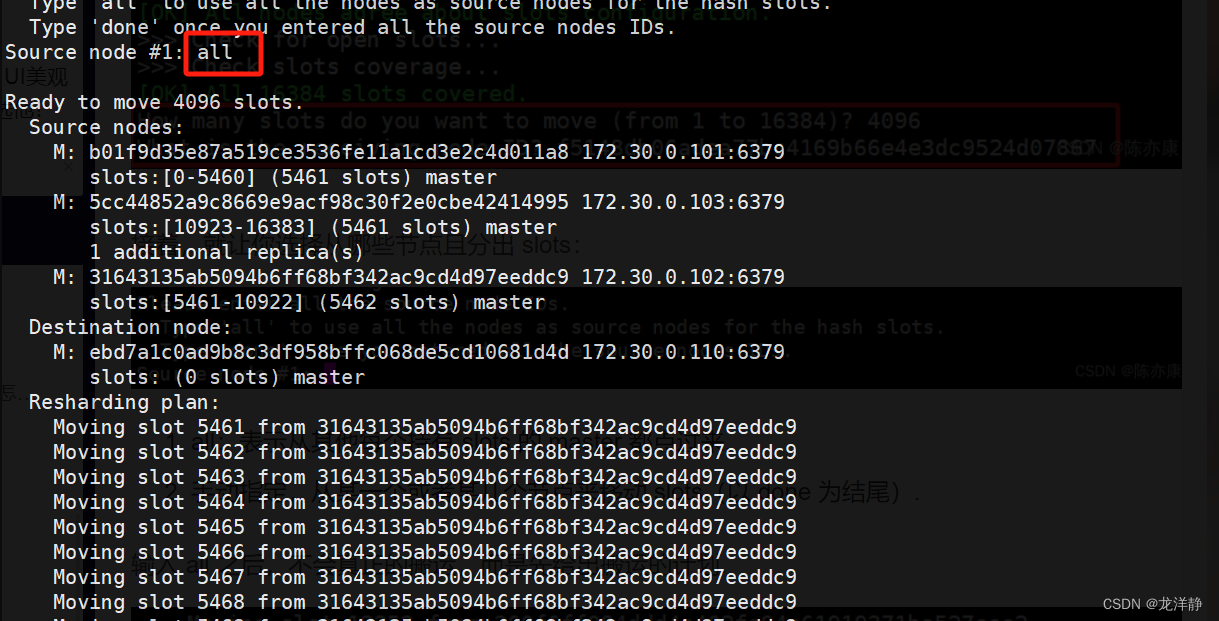
输入all后,并不会真正的搬运,而是给出搬运的计划,下面会等待你输入yes后,才开始真正搬运,搬运时,不仅仅是slots重新划分,也会把slots上对应的数据,也进行搬运到新的节点(主机)上~【重量级操作】
第三步:给新的主节点添加从节点
命令:
redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave说明,第一个ip和端口号表示新增的节点是什么,第二个ip和端口号表示集群上的某一个主节点,后面跟上--cluster-slaveof,表示加入后作为这个主节点的从节点存储~
8、删除主节点
命令:
redis-cli --cluster del-node 172.30.0.101:6379 节点id第一个ip和端口号表示所在集群是哪个~
好啦,本期就到这里咯,下期见~~~