一、什么是mmdetection
商汤科技(2018 COCO 目标检测挑战赛冠军)和香港中文大学最近开源了一个基于Pytorch实现的深度学习目标检测工具箱mmdetection,支持Faster-RCNN,Mask-RCNN,Fast-RCNN等主流的目标检测框架,后续会加入Cascade-RCNN以及其他一系列目标检测框架。
二、mmdetection安装
本人安装环境:
系统环境:Ubuntu 20.04.2 LTS
cuda版本:11.7
torch版本:1.8.1
torchvision版本:0.9.1
(一)、安装pytorch
在配置环境之前,建议先安装ANCONDA,具体的安装方法自行百度一下吧,安装完ANCONDA之后,首先创建虚拟环境,指令如下:
conda create -n mmdetection python=3.6 # 创建环境
创建完成之后激活该虚拟环境:
source activate mmdetection
在安装pytorch之前要先看什么版本的配置满足要求,配置pytorch要求python以及torchvision版本要对应,我们可以从离线网站上看配置要求:http://download.pytorch.org/whl/torch_stable.html
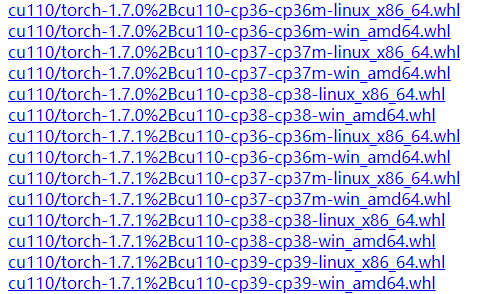
以上图为例:
cu110代表cuda11.0版本,cp37代表python3.7大版本。linux_x86_64代表在linux系统上的配置
一般cuda的版本都是向下兼容的,所以我们只需要将python 版本以及pytorch,cuda版本对应上即可。
找到好对应的版本之后从pytorch官网官网找到指令:https://pytorch.org/get-started/previous-versions/
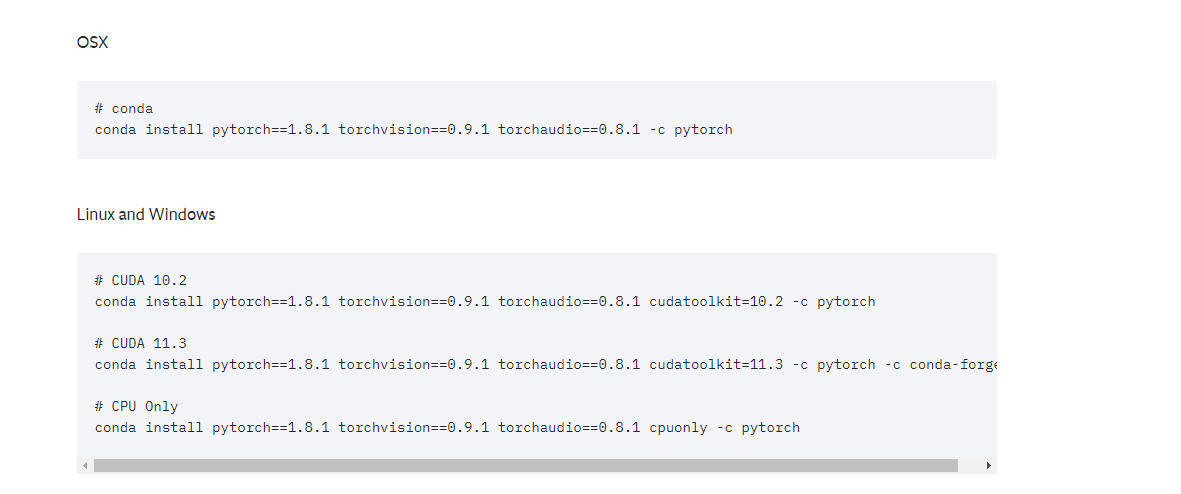
依照我自身的版本,选择conda install pytorch==1.8.1 torchvision==0.9.1 torchaudio==0.8.1 cudatoolkit=10.2 -c pytorch指令即可自行安装。如果网速过慢或者下载失败则给conda换源即可,具体换源方法自行百度。
安装完pytorch之后我们就可以安装mmdetection
(二)、安装mmdetection
第一步使用pip安装openmim,直接运行如下指令:
pip install -U openmim
安装完openmim之后通过mim自动安装对应版本的mmcv-full:
mim install mmcv-full
安装完mmcv-full之后则可以在git仓库拉取源码了:
git clone https://github.com/open-mmlab/mmdetection.git
拉取之后切换到mmdetection根目录下:
cd mmdetection
安装附加库:
pip install -v -e .
# 或者
python setup.py develop
安装完成之后可以运行demo进行验证框架的可使用性。
下载配置文件以及权重文件
mim download mmdet --config yolov3_mobilenetv2_320_300e_coco --dest .
下载完成后直接运行demo:
python demo/image_demo.py demo/demo.jpg yolov3_mobilenetv2_320_300e_coco.py yolov3_mobilenetv2_320_300e_coco_20210719_215349-d18dff72.pth --device cpu --out-file result.jpg
运行成功后则会在根目录下生成result.jpg,则环境搭建完成。
三、搭建完mmdetection之后,就可以对自建数据集进行训练了
(一)、voc
1、首先根据规范的VOC数据集导入到项目目录下,如下图所示:
mmdetection
----mmdet
----tools
----configs
----data
--------VOCdevkit
------------VOC2007
--------------- Annotations
---------------- JPEGImages
---------------- ImageSets
------------------------ Main
---------------------------- test.txt
---------------------------- trainval.txt
---------------------------- val.txt
---------------------------- test.txt
先在mmdetection目录下依次创建data、VOCdevkit、VOC2007文件夹,嵌套关系如上,再在VOC2007文件夹下按VOC格式存放自己的数据集(Annotation存放检测框信息、JPEGImages存放要检测的图片,这两个文件夹的名字一定不能修改),ImageSets是放txt文件,可以修改名字,但是初次使用建议规范格式。
2、修改配置文件
mmdet/datasets/voc.py修改类别:

3、 配置图片格式
mmdet/datasets/xml_style.py修改图片格式:如果图片是jpg则改成jpg,是png格式就改成png

4、mmdetection/mmdet/core/evaluation/class_names.py修改验证时的类别名称

只有一个类别的话需要改mmdetection/mmdet/datasets/xml_style.py:

5、detect/mmdetection/configs/yolox/yolox_s_8x8_300e_coco.py
修改训练参数:类别个数,数据集格式以及路径




验证方式修改为voc下的map
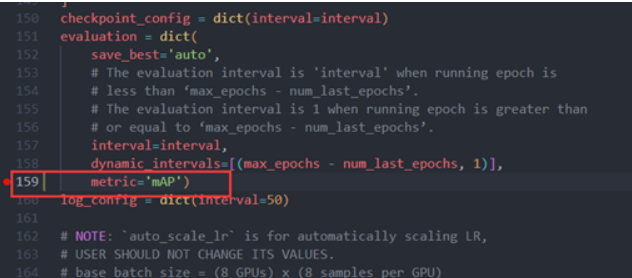
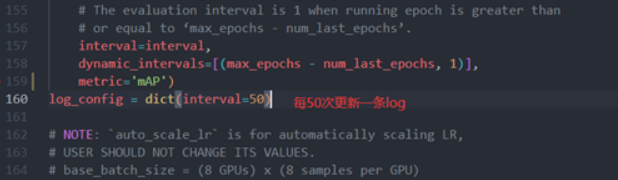
输出日志的间隔
detect/mmdetection/mmdet/datasets/pipelines/loading.py
如果我们的图像后缀有jpg,JPG,png,bmp……所以在一开始创建数据txt时候就直接存了文件名,在这一步的时候把后面填充的.jpg去掉。

6、增加训练指标(可选择不修改):
mmdetection/mmdet/core/evaluation/mean_ap.py


也可以通过下列指令将VOC转换为COCO格式数据集进行训练:
#数据集转换 在目录下创建data文件夹,在目录C:\AI_Dataset\VOCtest_06-Nov-2007\VOCdevkit下必须存在VOC2007或者VOC2012文件夹
python .\tools\dataset_converters\pascal_voc.py \VOCdevkit --out-dir .\data --out-format coco
(二)、训练
(1)、单机单卡
python ./tools/train.py ./configs/yolox/yolox_s_8x8_300e_coco.py (二)、单机多卡
./tools/dist_train.sh ./configs/yolox/yolox_s_8x8_300e_coco.py 8
# 也可以指定端口号
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4训练后会在mmdetection/work_dirs/yolox_s_8x8_300e_coco/ 下生成训练结果,其中,yolox_s_8x8_300e_coco.py为训练模型的配置文件;20220705_155440.log 终端log文件;20220705_155440.log.json json版本,主要是之后可视化训练过程参数使用。
(三)、恢复训练
若中途中断训练,可接上次训练结果继续训练,或从之前某个epoch的模型直接开始训练:
python ./tools/train.py ./work_dirs/yolox_s_8x8_300e_coco/yolox_s_8x8_300e_coco.py --auto-resume
python ./tools/train.py ./work_dirs/yolox_s_8x8_300e_coco/yolox_s_8x8_300e_coco.py --resume-from ./work_dirs/yolox_s_8x8_300e_coco/epoch_100.pth(三)、测试
修改:detect/mmdetection/mmdet/models/detectors/base.py
这是在txt文件下定义图片后缀的情况下需要修改
运行测试脚本,将test.txt中的图像拿来测试效果:image_test.py:
from argparse import ArgumentParser
import os
from mmdet.apis import inference_detector, init_detector
import cv2def show_result_pyplot(model, img, result, score_thr=0.3, fig_size=(15, 10)):"""Visualize the detection results on the image.Args:model (nn.Module): The loaded detector.img (str or np.ndarray): Image filename or loaded image.result (tuple[list] or list): The detection result, can be either(bbox, segm) or just bbox.score_thr (float): The threshold to visualize the bboxes and masks.fig_size (tuple): Figure size of the pyplot figure."""if hasattr(model, 'module'):model = model.moduleimg = model.show_result(img, result, score_thr=score_thr, show=False)return imgdef main():# config文件config_file = '[path]/mmdetection/work_dirs/yolox_s_8x8_300e_coco/yolox_s_8x8_300e_coco.py'# 训练好的模型checkpoint_file = '[path]/mmdetection/work_dirs/yolox_s_8x8_300e_coco/epoch_100.pth'# model = init_detector(config_file, checkpoint_file)model = init_detector(config_file, checkpoint_file, device='cuda:0',)# 图片路径img_dir = '[path]/data/JPEGImages/'# 检测后存放图片路径out_dir = '[path]/mmdetection/work_dirs/yolox_s_8x8_300e_coco/images_test_result/'if not os.path.exists(out_dir):os.mkdir(out_dir)# 测试集的图片名称txttest_path = '[path]/data/ImageSets/Main/test.txt'fp = open(test_path, 'r')test_list = fp.readlines()count = 0for test in test_list:test = test.replace('\n', '')test2=test[:-4]name = img_dir + test + '.jpg'count += 1print('model is processing the {}/{} images.'.format(count, len(test_list)))result = inference_detector(model, name)img = show_result_pyplot(model, name, result)cv2.imwrite("{}/{}.jpg".format(out_dir, test2), img)if __name__ == '__main__':main()(四)、可视化
(1)、可视化训练过程参数:
(1)、训练过程的map
python ./tools/analysis_tools/analyze_logs.py plot_curve ./work_dirs/yolox_s_8x8_300e_coco/20220705_155440.log.json --keys mAP --out out2.jpg --eval-interval 10
(2)、训练过程的loss
python ./tools/analysis_tools/analyze_logs.py plot_curve ./work_dirs/yolox_s_8x8_300e_coco/20220705_155440.log.json --keys loss loss_cls loss_obj --out out1.jpg
(2)、可视化数据增强处理流程的结果:
python ./tools/misc/browse_dataset.py --output-dir ./work_dirs/yolox_s_8x8_300e_coco/vis_pipeline/ ./work_dirs/yolox_s_8x8_300e_coco/yolox_s_8x8_300e_coco.py (3)、开启tensorboard实时查看训练参数变化:
mmdetection/configs/base/default_runtime.py
打开下面注释:

(五)、异常处理
针对标注文件 .xml的没有 标签的情况
AttributeError: ‘NoneType‘ object has no attribute ‘text‘
报错原因:标注文件 .xml的没有的标签。difficlut表明这个待检测目标很难识别,有可能是虽然视觉上很清楚,但是没有上下文的话还是很难确认它属于哪个分类;标为difficult的目标在测试成绩的评估中一般会被忽略,下面举一个例子:

种解决方法:
1、可以查找.xml标注文件,把没有difficlut标签的补上。
2、若标签数据非常多,所有都添加上difficult的话非常耗时。如果数据没有特别难分的类别,可以忽略这个标签,在代码里把difficlut置为1,具体操作如下:打开mmdet/datasets/xml_style.py,将difficult=int(obj.find(‘difficult’).text)改为如下代码: