我相信你们大多数人都听说过 ChatGPT 并尝试过它来回答你的问题! 有没有想过幕后发生了什么? 它由 Open AI 开发的大型语言模型 GPT-3 提供支持。 这些大型语言模型(通常称为LLM)开启了自然语言处理的许多可能性。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、什么是大型语言模型或LLM?
大型语言模型(LLM)经过大量文本数据的训练,使它们能够理解人类语言的含义和上下文。 以前,大多数模型都是使用监督方法进行训练的,我们提供输入特征和相应的标签。 与此不同的是,LLM是通过无监督学习进行训练的,他们接受大量没有任何标签和指令的文本数据。 因此,LLM可以有效地学习语言单词之间的含义和关系。 它们可用于各种任务,例如文本生成、问答、从一种语言翻译为另一种语言等等。
最重要的是,这些大型语言模型可以在您的自定义数据集上针对特定领域的任务进行微调。 在本文中,我将讨论微调的必要性、可用的不同LLM,并展示一个示例。
2、为什么要微调大模型?
假设你经营一个糖尿病支持社区,并希望设立在线帮助热线来回答问题。 预训练的LLM接受的训练更为普遍,无法为特定领域的问题提供最佳答案,也无法理解医学术语和首字母缩略词。 这个可以通过微调来解决。
我们所说的微调是什么意思? 简单来说,迁移学习! 大型语言模型使用大量资源在庞大的数据集上进行训练,并具有数百万个参数。 LLM 在预训练期间学到的表示和语言模式将转移到你当前手头的任务中。 用技术术语来说,我们使用预先训练的权重初始化模型,然后根据特定于任务的数据对其进行训练,以达到更多针对任务优化的参数权重。 你还可以更改模型的架构,并根据需要修改层。
微调LLM大模型有以下意义:
- 节省时间和资源:与从头开始训练相比,微调可以帮助你减少所需的训练时间和资源。
- 减少数据需求:如果你想从头开始训练模型,则需要大量标记数据,而个人和小型企业通常无法获得这些数据。 即使数据量较少,微调也可以帮助你实现良好的性能。
- 根据你的需求进行定制:经过预训练的LLM可能无法掌握你特定领域的术语和缩写。 例如,一个普通的LLM不会认识到“1 型”和“2 型”表示糖尿病的类型,而经过微调的LLM却可以。
- 实现持续学习:假设我们根据糖尿病信息数据微调了我们的模型并进行了部署。 如果你想要包含新的饮食计划或治疗方法怎么办? 你可以使用之前微调模型的权重并对其进行调整以包含新数据。 这可以帮助组织以有效的方式使模型保持最新。
3、如何选择开源 LLM 模型
下一步是为你的任务选择一个大型语言模型。 有什么选择?
目前可用的最先进的大型语言模型包括 GPT-3、Bloom、BERT、T5 和 XLNet。 其中,GPT-3(生成式预训练transformer)表现出了最好的性能,因为它经过了 1750 亿个参数的训练,可以处理各种 NLU 任务。 但是,GPT-3 微调只能通过付费订阅才能获得,并且比其他选项相对更昂贵。
另一方面,BERT是一个开源的大语言模型,可以免费进行微调。 BERT 代表双向编码器解码器transformer。 BERT 在理解上下文单词表示方面做得非常出色。
那么应该如何选择?
如果你的任务更面向文本生成,GPT-3(付费)或 GPT-2(开源)模型将是更好的选择。 如果你的任务属于文本分类、问答或实体识别,可以使用 BERT。 对于我的糖尿病问答案例,我将继续使用 BERT 模型。
4、准备和预处理微调LLM的数据集
这是微调中最关键的步骤,因为数据格式根据模型和任务而变化。 对于本例,我创建了一个示例文本文档,其中包含从国家卫生研究院网站获取的糖尿病信息。 您可以使用自己的数据。
要微调 BERT 的问答任务,建议将数据转换为 SQuAD 格式。 SQuAD 是斯坦福问答数据集,这种格式被广泛用于训练问答任务的 NLP 模型。 数据需要采用 JSON 格式,其中每个字段包含:
- 上下文:模型将根据其搜索问题答案的带有文本的句子或段落
问题:我们希望 BERT 回答的查询。 你需要根据最终用户如何与 QA 模型交互来构建这些问题。 - 答案:你需要在此字段下提供所需的答案。 其下有两个子组件,text 和answer_start。 文本将包含答案字符串。 而answer_start表示索引,从上下文段落中答案开始的位置开始。
正如你可以想象的那样,如果手动创建此数据,则需要花费大量时间来为文档创建这些数据。 别担心,我将向你展示如何使用 Haystack 标注工具轻松完成此操作。
5、用 Haystack 创建 SQuAD 格式的数据
使用 Haystack 标注工具,你可以快速创建用于问答任务的标注数据集。 可以通过在其网站上创建帐户来访问该工具。 创建一个新项目并上传你的文档。 可以在“文档”选项卡下查看它,转到“操作”,可以看到创建问题的选项。 你可以在文档中写下你的问题并突出显示答案,Haystack 会自动找到它的起始索引。 我在下图中展示了我是如何在我的文档中做到这一点的。
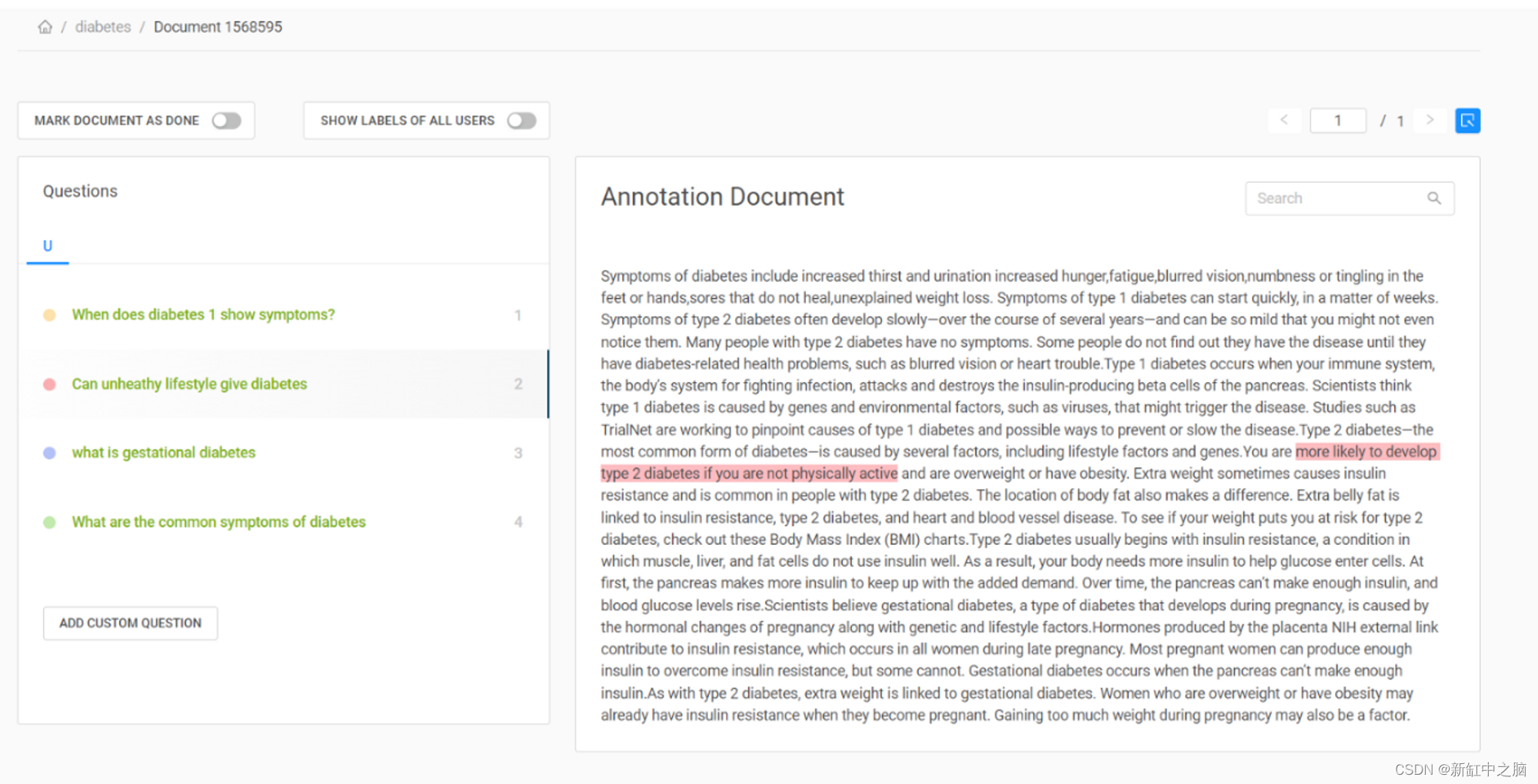
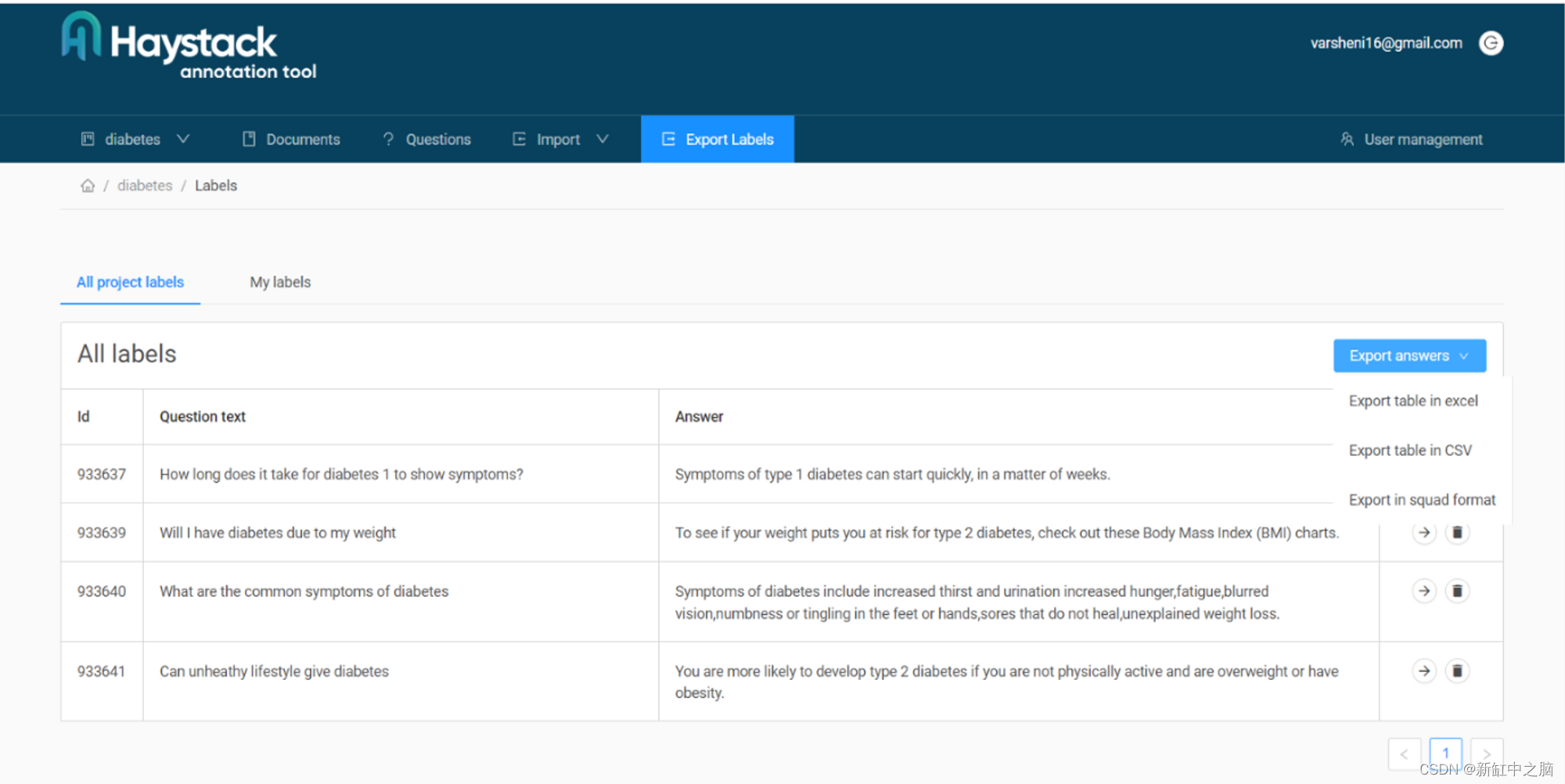
创建足够的问答对进行微调后,你应该能够看到它们的摘要,如下所示。 在“导出标签”选项卡下,你可以找到要导出的格式的多个选项。我们为我们的案例选择小队格式。 如果你在使用该工具时需要更多帮助,可以查看他们的文档。 现在我们有了包含用于微调的 QA 对的 JSON 文件。
6、如何微调LLM大模型?
Python 提供了许多可用于微调的开源包。 我在我的案例中使用了 Pytorch 和 Transformers 包。 首先使用包管理器 pip 导入包模块。 Transformers 库提供了一个 BERTTokenizer,专门用于对 BERT 模型的输入进行标记。
# Install and import the modules
!pip install torch
!pip install transformersimport json
import torch
from transformers import BertTokenizer, BertForQuestionAnswering
from torch.utils.data import DataLoader, Dataset
7、加载LLM微调自定义数据集
下一步是加载和预处理数据。 可以使用 pytorch 的 utils.data 模块中的 Dataset 类为数据集定义自定义类。 我创建了一个自定义数据集类糖尿病,如下面的代码片段所示。 init 负责初始化变量。 file_path 是一个参数,它将输入 JSON 训练文件的路径并用于初始化数据。 我们也在此处初始化 BertTokenizer。
接下来,我们定义一个 load_data() 函数。 此函数会将 JSON 文件读入 JSON 数据对象,并从中提取上下文、问题、答案及其索引。 它将提取的字段附加到列表中并返回它。
getitem 使用 BERT 分词器将问题和上下文编码为输入张量,即 input_ids 和 Attention_mask。 encode_plus将对文本进行标记,并添加特殊标记(例如[CLS]和[SEP])。 请注意,在输入到 BERT 之前,我们使用 squeeze() 方法来删除任何单一维度。 最后,它返回处理后的输入张量。
class diabetes(Dataset):def __init__(self, file_path):self.data = self.load_data(file_path)self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')def load_data(self, file_path):with open(file_path, 'r') as f:data = json.load(f)paragraphs = data['data'][0]['paragraphs']extracted_data = []for paragraph in paragraphs:context = paragraph['context']for qa in paragraph['qas']:question = qa['question']answer = qa['answers'][0]['text']start_pos = qa['answers'][0]['answer_start']extracted_data.append({'context': context,'question': question,'answer': answer,'start_pos': start_pos,})return extracted_datadef __len__(self):return len(self.data)def __getitem__(self, index):example = self.data[index]question = example['question']context = example['context']answer = example['answer']inputs = self.tokenizer.encode_plus(question, context, add_special_tokens=True, padding='max_length', max_length=512, truncation=True, return_tensors='pt')input_ids = inputs['input_ids'].squeeze()attention_mask = inputs['attention_mask'].squeeze()start_pos = torch.tensor(example['start_pos'])return input_ids, attention_mask, start_pos, end_pos
定义它后,可以通过向该类传递 file_path 参数来创建该类的实例。
# Create an instance of the custom dataset
file_path = 'diabetes.json'
dataset = diabetes(file_path)
8、微调训练大模型
我将使用 BertForQuestionAnswering 模型,因为它最适合 QA 任务。 你可以通过调用模型上的 from_pretrained 函数来初始化 bert-base-uncased 模型的预训练权重。 你还应该选择用于训练的评估损失函数和优化器。
我正在使用 Adam 优化器和交叉熵损失函数。 你可以使用 Pytorch 类 DataLoader 分批加载数据,并对其进行打乱以避免任何偏差。
# Set device (CPU or GPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# Initialize the BERT model for question answering
model = BertForQuestionAnswering.from_pretrained('bert-base-uncased')
model.to(device)optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
loss_fn = torch.nn.CrossEntropyLoss()
batch_size = 8
num_epochs = 50# Create data loader
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
一旦定义了数据加载器,你就可以继续编写最终的训练循环。 在每次迭代期间,从 data_loader 获取的每个批次都包含 batch_size 个示例,在这些示例上执行前向和后向传播。 该代码尝试找到参数的最佳权重集,使损失最小。
for epoch in range(num_epochs):model.train()total_loss = 0for batch in data_loader:# Move batch tensors to the deviceinput_ids = batch[0].to(device)attention_mask = batch[1].to(device)start_positions = batch[2].to(device)# Zero the gradientsoptimizer.zero_grad()# Forward passoutputs = model(input_ids, attention_mask=attention_mask, start_positions=start_positions)loss = outputs.loss# Backward pass and optimizationloss.backward()optimizer.step()total_loss += loss.item()avg_loss = total_loss / len(data_loader)print(f"Epoch {epoch+1}/{num_epochs} - Average Loss: {avg_loss:.4f}")
这样就完成了你的微调! 可以通过将模型设置为 model.eval() 来测试模型。 还可以使用微调学习率和历元数参数来获得数据的最佳结果。
9、LLM微调的最佳技巧和实践
在自定义数据上微调任何大型语言模型时需要注意以下几点:
- 你的数据集需要代表你希望语言模型擅长的目标领域或任务。 干净且结构良好的数据至关重要。
- 确保数据中有足够的训练示例,供模型学习模式。 否则,模型可能会记住示例并过度拟合,而无法推广到未见过的示例。
- 选择一个已在与你手头的任务相关的语料库上进行过训练的预训练模型。 对于问答,我们选择在斯坦福问答数据集上训练的预训练模型。 与此类似,有不同的模型可用于情感分析、文本生成、摘要、文本分类等任务。
- 如果你的 GPU 内存有限,请尝试梯度累积。 在此方法中,不是在每个批次之后更新模型的权重,而是在执行更新之前在多个小批次上累积梯度。
- 如果在微调时遇到过度拟合的问题,请使用正则化技术。 一些常用的方法包括向模型架构添加 dropout 层、实现权重衰减和层归一化。
10、结束语
大型语言模型可以帮助你快速高效地自动执行许多任务。 微调LLM可帮助你利用迁移学习的力量并根据你的特定领域对其进行定制。 如果你的数据集属于医疗、技术利基、金融数据集等领域,则微调可能至关重要。
在本文中,我们使用 BERT,因为它是开源的并且非常适合个人使用。 如果你正在进行大型项目,可以选择更强大的 LLM,例如 GPT3 或其他开源替代方案。 请记住,微调大型语言模型可能会耗费大量计算资源且耗时。 确保你有足够的计算资源,包括根据规模的 GPU 或 TPU。
原文链接:开源大模型微调指南 — BimAnt