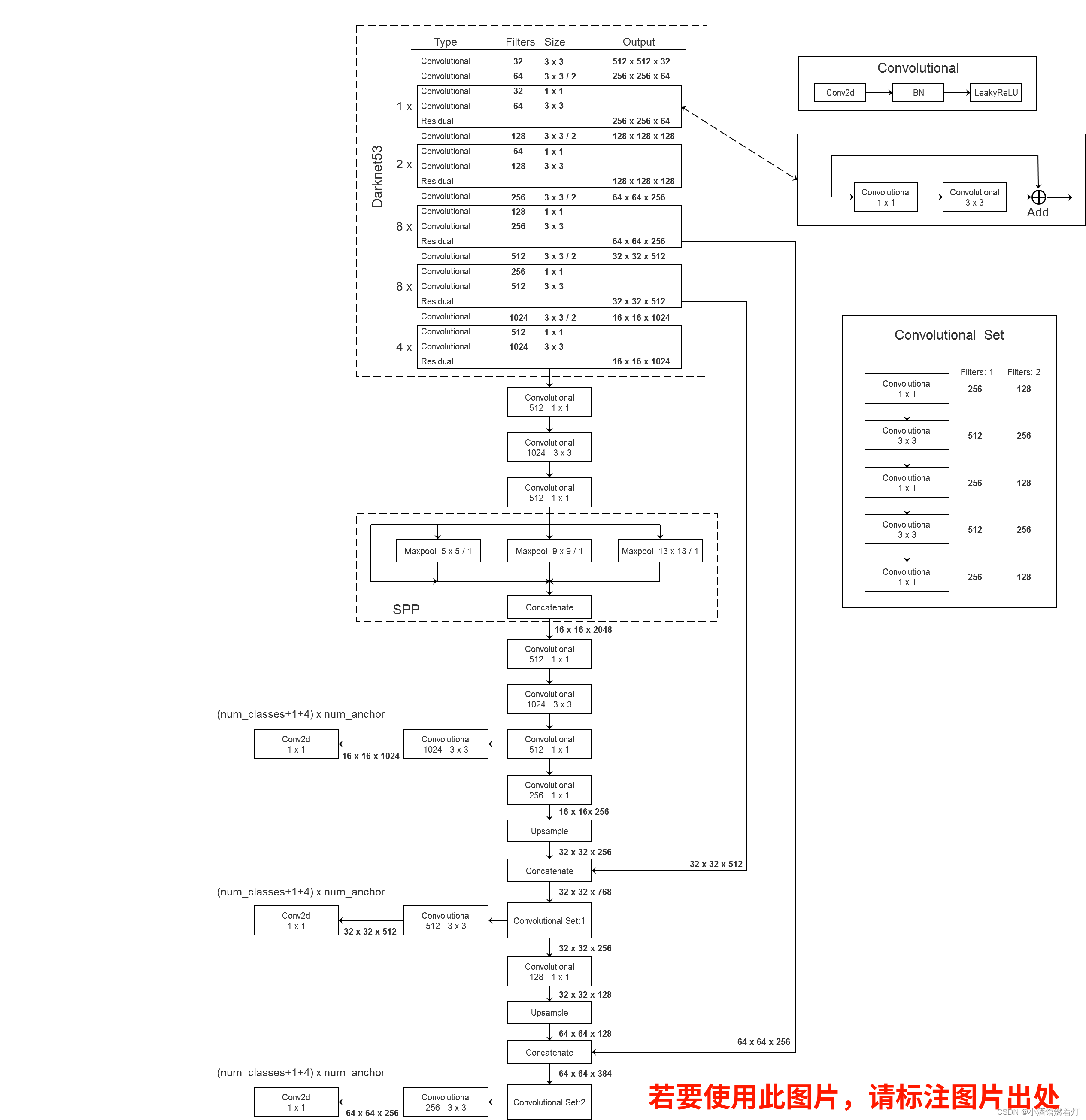
网络结构
以YOLOv3_SPP为例
cfg文件
部分,只是用来展示,全部的代码在文章最后
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16
width=608
height=608
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1 learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
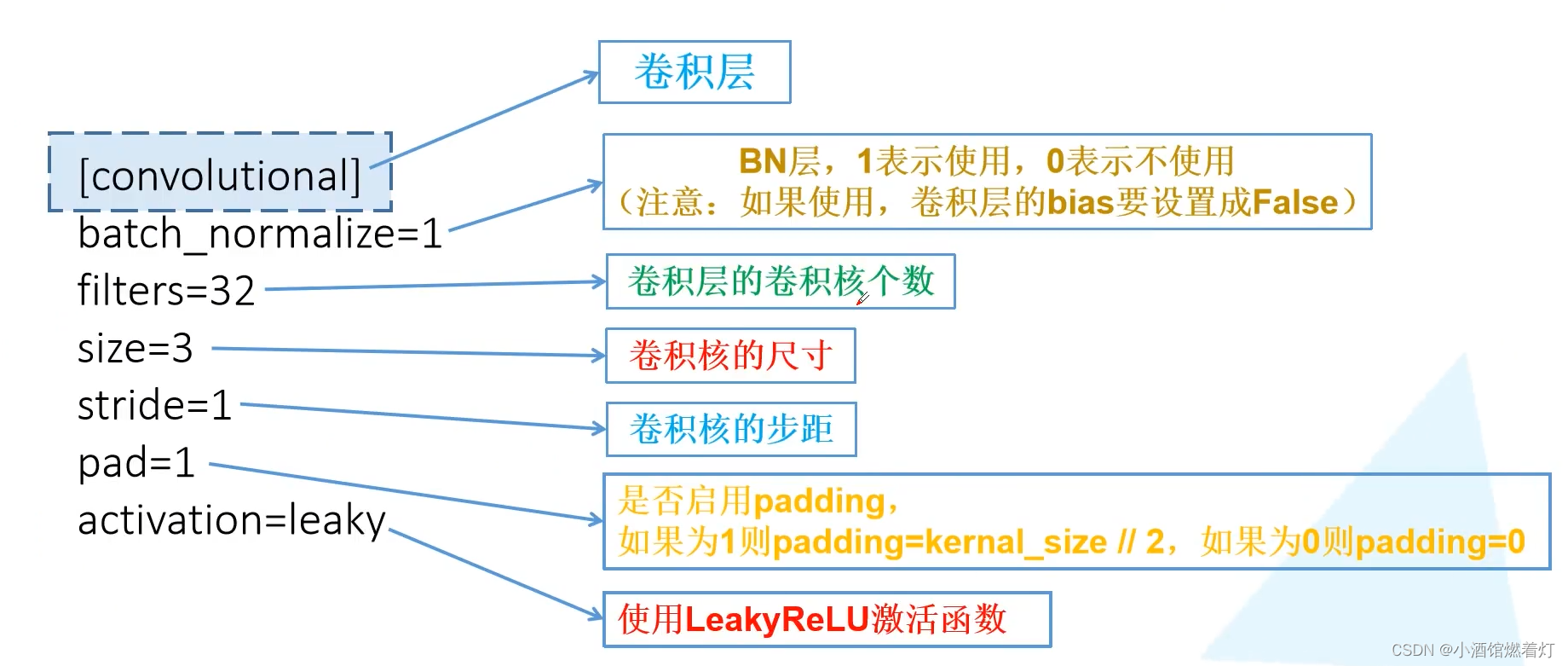
scales=.1,.1 [convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky # Downsample[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
分析结构
图形化分析




更加详尽的分析
1. Net层
[net]
#Testing
#batch=1
#subdivisions=1
#在测试的时候,设置batch=1,subdivisions=1
#Training
batch=16
subdivisions=4
#这里的batch与普遍意义上的batch不是一致的。
#训练的过程中将一次性加载16张图片进内存,然后分4次完成前向传播,每次4张。
#经过16张图片的前向传播以后,进行一次反向传播。
width=416
height=416
channels=3
#设置图片进入网络的宽、高和通道个数。
#由于YOLOv3的下采样一般是32倍,所以宽高必须能被32整除。
#多尺度训练选择为32的倍数最小320*320,最大608*608。
#长和宽越大,对小目标越好,但是占用显存也会高,需要权衡。
momentum=0.9
#动量参数影响着梯度下降到最优值得速度。
decay=0.0005
#权重衰减正则项,防止过拟合。
angle=0
#数据增强,设置旋转角度。
saturation = 1.5
#饱和度
exposure = 1.5
#曝光量
hue=.1
#色调learning_rate=0.001
#学习率:刚开始训练时可以将学习率设置的高一点,而一定轮数之后,将其减小。
#在训练过程中,一般根据训练轮数设置动态变化的学习率。
burn_in=1000
max_batches = 500200
#最大batch
policy=steps
#学习率调整的策略,有以下policy:
#constant, steps, exp, poly, step, sig, RANDOM,constant等方式
#调整学习率的policy,
#有如下policy:constant, steps, exp, poly, step, sig, RANDOM。
#steps#比较好理解,按照steps来改变学习率。steps=400000,450000
scales=.1,.1
#在达到40000、45000的时候将学习率乘以对应的scale
2. 卷积层
[convolutional]
batch_normalize=1
#是否做BN操作
filters=32
#输出特征图的数量
size=3
#卷积核的尺寸
stride=1
#做卷积运算的步长
pad=1
#如果pad为0,padding由padding参数指定。
#如果pad为1,padding大小为size/2,padding应该是对输入图像左边缘拓展的像素数量
activation=leaky
#激活函数的类型:logistic,loggy,relu,
#elu,relie,plse,hardtan,lhtan,
#linear,ramp,leaky,tanh,stair
# alexeyAB版添加了mish, swish, nrom_chan等新的激活函数
feature map计算公式:
OutFeature=\frac{InFeature+2\times padding-size}{stride}+1 \
3. 下采样
可以通过调整卷积层参数进行下采样:
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=leaky
可以通过带入以上公式,可以得到OutFeature是InFeature的一半。
也可以使用maxpooling进行下采样:
[maxpool]
size=2
stride=2
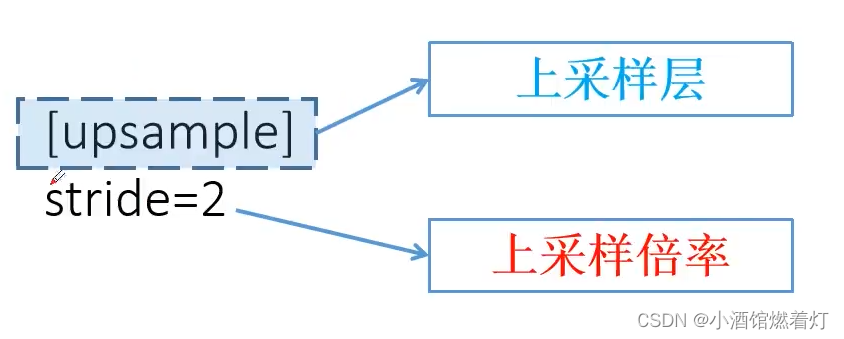
4. 上采样
[upsample]
stride=2
上采样是通过线性插值实现的。
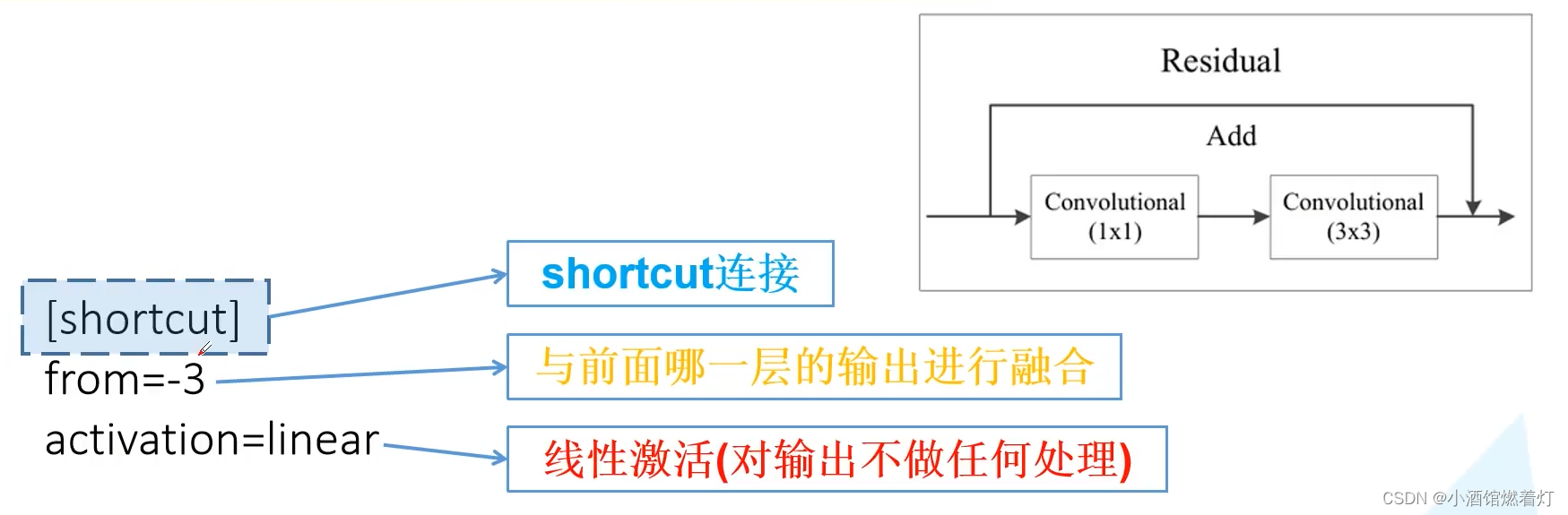
5. Shortcut和Route层
[shortcut]
from=-3
activation=linear
#shortcut操作是类似ResNet的跨层连接,参数from是−3,
#意思是shortcut的输出是当前层与先前的倒数第三层相加而得到。
# 通俗来讲就是add操作[route]
layers = -1, 36
# 当属性有两个值,就是将上一层和第36层进行concate
#即沿深度的维度连接,这也要求feature map大小是一致的。
[route]
layers = -4
#当属性只有一个值时,它会输出由该值索引的网络层的特征图。
#本例子中就是提取从当前倒数第四个层输出
6. YOLO层
[convolutional]
size=1
stride=1
pad=1
filters=18
#每一个[region/yolo]层前的最后一个卷积层中的
#filters=num(yolo层个数)*(classes+5) ,5的意义是5个坐标,
#代表论文中的tx,ty,tw,th,po
#这里类别个数为1,(1+5)*3=18
activation=linear[yolo]
mask = 6,7,8
#训练框mask的值是0,1,2,
#这意味着使用第一,第二和第三个anchor
anchors = 10,13, 16,30, 33,23, 30,61, 62,45,\59,119, 116,90, 156,198, 373,326
# 总共有三个检测层,共计9个anchor
# 这里的anchor是由kmeans聚类算法得到的。
classes=1
#类别个数
num=9
#每个grid预测的BoundingBox num/yolo层个数
jitter=.3
#利用数据抖动产生更多数据,
#属于TTA(Test Time Augmentation)
ignore_thresh = .5
# ignore_thresh 指得是参与计算的IOU阈值大小。
#当预测的检测框与ground true的IOU大于ignore_thresh的时候,
#不会参与loss的计算,否则,检测框将会参与损失计算。
#目的是控制参与loss计算的检测框的规模,当ignore_thresh过于大,
#接近于1的时候,那么参与检测框回归loss的个数就会比较少,同时也容易造成过拟合;
#而如果ignore_thresh设置的过于小,那么参与计算的会数量规模就会很大。
#同时也容易在进行检测框回归的时候造成欠拟合。
#ignore_thresh 一般选取0.5-0.7之间的一个值
# 小尺度(13*13)用的是0.7,
# 大尺度(26*26)用的是0.5。
读取代码的实现
有详细注释
from build_utils.layers import *
from build_utils.parse_config import *ONNX_EXPORT = Falsedef create_modules(modules_defs: list, img_size):"""Constructs module list of layer blocks from module configuration in module_defs:param modules_defs: 通过.cfg文件解析得到的每个层结构的列表:param img_size: 输入图像的大小:return: 构建的模块列表"""img_size = [img_size] * 2 if isinstance(img_size, int) else img_size# 如果img_size是整数类型,将其转化为长度为2的列表,否则保持原样modules_defs.pop(0) # cfg training hyperparams (unused)# 删除模块定义列表的第一个元素,这个元素对应于"[net]"的配置,我们不需要它output_filters = [3] # input channels# 初始化输出滤波器列表,值为3,对应输入通道数module_list = nn.ModuleList()# 初始化一个nn.ModuleList对象,用于保存构建的模块列表routs = [] # list of layers which rout to deeper layers# 初始化一个列表,用于保存那些输出会流向更深层的层的索引yolo_index = -1# 初始化yolo层的索引为-1,表示还没有找到yolo层# 遍历模块定义列表中的每个元素for i, mdef in enumerate(modules_defs):modules = nn.Sequential()# 创建一个nn.Sequential对象,用于保存一个层中的多个模块if mdef["type"] == "convolutional":bn = mdef["batch_normalize"] # 1 or 0 / use or notfilters = mdef["filters"]k = mdef["size"] # kernel sizestride = mdef["stride"] if "stride" in mdef else (mdef['stride_y'], mdef["stride_x"])# 如果层的类型是"convolutional":if isinstance(k, int):modules.add_module("Conv2d", nn.Conv2d(in_channels=output_filters[-1],out_channels=filters,kernel_size=k,stride=stride,padding=k // 2 if mdef["pad"] else 0,bias=not bn))else:raise TypeError("conv2d filter size must be int type.")# 添加一个nn.Conv2d层,参数包括输入通道数、输出通道数、卷积核大小、步长、填充等# 如果卷积核大小不是整数类型,会抛出TypeError异常if bn:modules.add_module("BatchNorm2d", nn.BatchNorm2d(filters))else:# 如果该卷积操作没有bn层,意味着该层为yolo的predictorrouts.append(i) # detection output (goes into yolo layer)# 如果存在bn层,添加一个nn.BatchNorm2d层;否则将该层的索引添加到routs列表中,该层为yolo层的predictor层if mdef["activation"] == "leaky":modules.add_module("activation", nn.LeakyReLU(0.1, inplace=True))else:pass # 如果存在激活函数为"leaky",添加一个nn.LeakyReLU层;否则不添加任何东西if mdef["type"] == "BatchNorm2d":# BatchNorm2d层的创建方法,代码中未给出具体实现,这里用pass表示pass# 如果"type"是"maxpool",表示这是一个最大池化层elif mdef["type"] == "maxpool":# 获取最大池化层的核大小(k)和步长(stride)k = mdef["size"] # kernel sizestride = mdef["stride"]# 根据核大小和步长创建最大池化层modules = nn.MaxPool2d(kernel_size=k, stride=stride, padding=(k - 1) // 2)# 如果"type"是"upsample",表示这是一个上采样层elif mdef["type"] == "upsample":# 如果在ONNX导出模式下,明确地设置上采样层的大小,避免使用scale_factorif ONNX_EXPORT: # 如果在ONNX导出模式下,判断是否需要明确设置上采样层的大小# 计算增益(gain)g,通过yolo_index和img_size计算g = (yolo_index + 1) * 2 / 32 # gain# 根据增益g设置上采样层的大小modules = nn.Upsample(size=tuple(int(x * g) for x in img_size))else:# 在非ONNX导出模式下,使用scale_factor设置上采样层的大小modules = nn.Upsample(scale_factor=mdef["stride"])# 如果"type"是"route",表示这是一个路由层(用于网络中的特征融合)elif mdef["type"] == "route": # [-2], [-1,-3,-5,-6], [-1, 61]# 获取路由层的层次信息(layers)layers = mdef["layers"]# 计算路由层的特征图总输出通道数(filters)filters = sum([output_filters[l + 1 if l > 0 else l] for l in layers])# 将路由层的层次信息添加到routs列表中routs.extend([i + l if l < 0 else l for l in layers])# 根据路由层的层次信息创建特征融合层(FeatureConcat)modules = FeatureConcat(layers=layers)# 如果"type"是"shortcut",表示这是一个快捷连接层(用于网络中的残差连接)elif mdef["type"] == "shortcut":# 获取快捷连接层的输入层次信息(layers)和输出通道数(filters)layers = mdef["from"]filters = output_filters[-1]# 将快捷连接层的输入层次信息添加到routs列表中# routs.extend([i + l if l < 0 else l for l in layers]) 这一行代码在原代码中被注释掉,可能是误操作,这里将其取消注释routs.append(i + layers[0]) # 这里假设输入的快捷连接层只有一个输入层次,所以直接用i + layers[0]表示其位置关系# 根据快捷连接层的输入层次信息创建加权特征融合层(WeightedFeatureFusion)modules = WeightedFeatureFusion(layers=layers, weight="weights_type" in mdef) # 这里假设weight的判断条件是固定的,如果需要根据不同情况设置不同的weight,需要修改此处代码。elif mdef["type"] == "yolo": # 如果模块类型是"yolo",执行以下代码yolo_index += 1 # 记录这是第几个yolo层,从0开始计数 [0, 1, 2]stride = [32, 16, 8] # 预测特征层对应原图的缩放比例# 根据mdef中的信息创建一个YOLOLayer对象modules = YOLOLayer(anchors=mdef["anchors"][mdef["mask"]], # anchor listnc=mdef["classes"], # number of classesimg_size=img_size,stride=stride[yolo_index])# 对于初始化前的Conv2d()偏置进行初始化 (https://arxiv.org/pdf/1708.02002.pdf section 3.3)try:j = -1 # j初始化为-1,代表使用最后一个模块进行初始化# bias: shape(255,) 索引0对应Sequential中的Conv2d# view: shape(3, 85)b = module_list[j][0].bias.view(modules.na, -1) # 获取最后一个模块的偏置,并重新塑造为(modules.na, -1)的形状b.data[:, 4] += -4.5 # obj 调整第4列的偏置值,可能是对某些特定对象检测的偏置进行调整b.data[:, 5:] += math.log(0.6 / (modules.nc - 0.99)) # cls (sigmoid(p) = 1/nc) 对第5列及之后的列进行偏置调整,可能是对类别检测的偏置进行调整module_list[j][0].bias = torch.nn.Parameter(b.view(-1), requires_grad=True) # 将调整后的偏置作为参数返回,并设置为需要梯度更新except Exception as e: # 如果出现异常print('WARNING: smart bias initialization failure.', e) # 打印警告信息,说明智能偏置初始化失败,并打印异常信息else: # 如果模块类型不是"yolo"print("Warning: Unrecognized Layer Type: " + mdef["type"]) # 打印警告信息,说明模块类型未被识别或不支持# 将创建的模块列表和输出过滤器列表添加到总的列表中module_list.append(modules)output_filters.append(filters)# 为每个模块定义创建一个二进制路由标记,初始值都为Falserouts_binary = [False] * len(modules_defs)for i in routs: # 对每个路由进行遍历routs_binary[i] = True # 将对应的路由标记设置为True,表示存在该路由return module_list, routs_binary # 返回模块列表和路由标记列表# 定义一个YOLOLayer类,继承自torch.nn.Module
class YOLOLayer(nn.Module):"""对YOLO的输出进行处理"""# 初始化函数def __init__(self, anchors, nc, img_size, stride):# 调用父类的初始化函数super(YOLOLayer, self).__init__()# 定义anchors张量,这是先验框的尺寸self.anchors = torch.Tensor(anchors)# 定义特征图上一步对应原图上的步距self.stride = stride # layer stride 特征图上一步对应原图上的步距 [32, 16, 8]# 定义先验框的数量self.na = len(anchors) # number of anchors (3)# 定义类别数量self.nc = nc # number of classes (80)# 定义输出的数量(包括obj,cls1等)self.no = nc + 5 # number of outputs (85: x, y, w, h, obj, cls1, ...)# 初始化网格数量为0self.nx, self.ny, self.ng = 0, 0, (0, 0) # initialize number of x, y gridpoints# 将anchors大小缩放到grid尺度self.anchor_vec = self.anchors / self.stride # batch_size, na, grid_h, grid_w, wh, 值为1的维度对应的值不是固定值,后续操作可根据broadcast广播机制自动扩充self.anchor_wh = self.anchor_vec.view(1, self.na, 1, 1, 2) # batch_size, na, grid_h, grid_w, whself.grid = None # grid变量初始化为None# 如果是在导出ONNX模型,设置训练状态为False,同时根据给定的img_size创建grid变量if ONNX_EXPORT: # 如果ONNX_EXPORT为True,进入该条件块self.training = False # 设置训练状态为Falseself.create_grids((img_size[1] // stride, img_size[0] // stride)) # number x, y grid points 根据给定的img_size和stride来创建grid变量# 定义一个名为create_grids的方法,该方法属于某个类,该类具有self(即实例本身)作为第一个参数def create_grids(self, ng=(13, 13), device="cpu"):"""更新grids信息并生成新的grids参数:param ng: 特征图大小,默认为(13, 13):param device: 设备类型,默认为"cpu":return: 无返回值,但会更新类实例的属性值"""# 将传入的ng参数赋值给self.nx和self.ny,表示特征图的横纵尺寸self.nx, self.ny = ng# 将ng参数转换为torch.tensor类型,并赋值给self.ng,用于记录特征图的尺寸self.ng = torch.tensor(ng, dtype=torch.float)# 构建xy offsets,即每个网格单元处的anchor的xy偏移量(相对于特征图原点)# build xy offsets 构建每个cell处的anchor的xy偏移量(在feature map上的)if not self.training: # 如果当前不是训练模式...# 使用torch.meshgrid函数生成网格坐标,yv为纵坐标,xv为横坐标yv, xv = torch.meshgrid([torch.arange(self.ny, device=device),torch.arange(self.nx, device=device)])# 将生成的横纵坐标进行堆叠,并通过view方法变换形状,成为(1, 1, self.ny, self.nx, 2)的张量# batch_size, na, grid_h, grid_w, whself.grid = torch.stack((xv, yv), 2).view((1, 1, self.ny, self.nx, 2)).float()# 如果anchor_vec的设备类型和当前的device不一致,就将anchor_vec和anchor_wh移动到当前的device上if self.anchor_vec.device != device:self.anchor_vec = self.anchor_vec.to(device)self.anchor_wh = self.anchor_wh.to(device)# 定义一个名为forward的函数,它是模型的前向传播过程def forward(self, p):# 判断是否是在导出ONNX模型,如果是则设置batch size为1,否则从输入参数中获取batch sizeif ONNX_EXPORT:bs = 1 # batch sizeelse:# 获取输入参数p的形状,并将三个维度分别赋值给bs(batch size)、ny(网络高度)、nx(网络宽度)bs, _, ny, nx = p.shape # batch_size, predict_param(255), grid(13), grid(13)# 检查网络尺寸是否与之前保存的尺寸相同,如果不同则重新创建网格,并赋值给self.gridif (self.nx, self.ny) != (nx, ny) or self.grid is None: # fix no grid bugself.create_grids((nx, ny), p.device)# 将输入参数的形状从(batch_size, 255, 13, 13)变换为(batch_size, 3, 85, 13, 13),85是由255*3得到的# permute操作将维度顺序变换,具体为:先保证第一维度不动,然后依次将后面的维度进行置换# 这里的意思是将(batch_size, 255, 13, 13)变换为(batch_size, 3, 85, 13, 13),然后再将其变换为(batch_size, 3, 13, 13, 85)# [bs, anchor, grid, grid, xywh + obj + classes]p = p.view(bs, self.na, self.no, self.ny, self.nx).permute(0, 1, 3, 4, 2).contiguous() # prediction# 如果模型处于训练状态,则直接返回预测结果pif self.training:return p# 如果是在导出ONNX模型,进行以下操作elif ONNX_EXPORT:# 为了避免ANN操作中的广播机制,计算锚点数量m,它是self.na、self.nx、self.ny三个值的乘积# 将self.ng的值重复m次,得到新的ng,然后计算其倒数ngm = self.na * self.nx * self.ny # 3*ng = 1. / self.ng.repeat(m, 1)# 将self.grid的值重复(1, self.na, 1, 1, 1)次,得到新的grid,然后将其形状变换为(m, 2)grid = self.grid.repeat(1, self.na, 1, 1, 1).view(m, 2)# 将self.anchor_wh的值重复(1, 1, self.nx, self.ny, 1)次,得到新的anchor_wh,然后将其形状变换为(m, 2),并乘以nganchor_wh = self.anchor_wh.repeat(1, 1, self.nx, self.ny, 1).view(m, 2) * ng# p = p.view(m, self.no) # 调整张量的形状,以适应后续操作。m可能是一个预设的形状或者是某个特定形状的函数。self.no表示类别数量。p = p.view(m, self.no)# xy = torch.sigmoid(p[:, 0:2]) + grid # x, y 通过sigmoid函数处理p的前两列并加上grid,grid可能表示网格坐标# wh = torch.exp(p[:, 2:4]) * anchor_wh # width, height 对p的第3列到第5列应用指数函数处理并乘以anchor_wh(锚框的宽高)# p_cls = torch.sigmoid(p[:, 4:5]) if self.nc == 1 else \ # conf 使用sigmoid函数处理p的第5列,如果类别数量为1,否则处理前两个类别并乘以p的第5列p[:, :2] = (torch.sigmoid(p[:, 0:2]) + grid) * ng # x, y 对p的前两列应用sigmoid函数并加上grid,然后乘以ng(某种缩放系数)p[:, 2:4] = torch.exp(p[:, 2:4]) * anchor_wh # width, height 对p的第3列到第5列应用指数函数处理并乘以anchor_wh(锚框的宽高)p[:, 4:] = torch.sigmoid(p[:, 4:]) # 对p的第5列后的所有列应用sigmoid函数p[:, 5:] = p[:, 5:self.no] * p[:, 4:5] # 对p的第5列后的所有列与第4列后的某一列相乘return p # 返回处理后的pelse: # 判断是否处于推理模式# 推理模式下的操作# [bs, anchor, grid, grid, xywh + obj + classes]克隆p,创建一个新的张量io,其中包含和p相同的数据,但某些元素可能被修改io = p.clone() # inference outputio[..., :2] = torch.sigmoid(io[..., :2]) + self.grid # xy 计算在feature map上的xy坐标 通过sigmoid函数处理io的前两列并加上self.grid(可能表示在feature map上的网格坐标)io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh # wh yolo method 计算在feature map上的wh 对io的第3列到第5列应用指数函数处理并乘以self.anchor_wh(锚框的宽高)io[..., :4] *= self.stride # 换算映射回原图尺度 io的前四列元素乘以self.stride(某种缩放系数)torch.sigmoid_(io[..., 4:]) # 对io的第5列后的所有列应用sigmoid函数return io.view(bs, -1, self.no), p # view [1, 3, 13, 13, 85] as [1, 507, 85] 最后返回一个形如[bs, -1, self.no]的张量和一个原始的p张量class Darknet(nn.Module):"""YOLOv3 spp object detection model"""def __init__(self, cfg, img_size=(416, 416), verbose=False): super(Darknet, self).__init__()# 这里传入的img_size只在导出ONNX模型时起作用self.input_size = [img_size] * 2 if isinstance(img_size, int) else img_size# 解析网络对应的.cfg文件self.module_defs = parse_model_cfg(cfg)# 根据解析的网络结构一层一层去搭建self.module_list, self.routs = create_modules(self.module_defs, img_size)# 获取所有YOLOLayer层的索引self.yolo_layers = get_yolo_layers(self)# 打印下模型的信息,如果verbose为True则打印详细信息self.info(verbose) if not ONNX_EXPORT else None # print model descriptiondef forward(self, x, verbose=False):return self.forward_once(x, verbose=verbose)def forward_once(self, x, verbose=False):# yolo_out收集每个yolo_layer层的输出# out收集每个模块的输出yolo_out, out = [], [] # 初始化两个空列表,用于存储YOLO层的输出和所有模块的输出if verbose:print('0', x.shape) # 如果verbose为True,打印输入x的形状str = "" # 初始化一个空字符串str,用于后续打印信息for i, module in enumerate(self.module_list): # 遍历module_list中的每个模块,并用enumerate函数获取模块的索引iname = module.__class__.__name__ # 获取当前模块的类名if name in ["WeightedFeatureFusion", "FeatureConcat"]: # 如果类名为"WeightedFeatureFusion"或"FeatureConcat"if verbose:l = [i - 1] + module.layers # 获取模块的层次列表,列表首项为当前模块索引,后面为上层模块索引sh = [list(x.shape)] + [list(out[i].shape) for i in module.layers] # 获取输入x的形状和上层模块输出的形状列表str = ' >> ' + ' + '.join(['layer %g %s' % x for x in zip(l, sh)]) # 拼接字符串,用于打印信息x = module(x, out) # 调用WeightedFeatureFusion或FeatureConcat方法,输入为x和上层模块的输出elif name == "YOLOLayer": # 如果类名为"YOLOLayer"yolo_out.append(module(x)) # 将YOLO层的输出添加到yolo_out列表中else: # 如果类名不属于["WeightedFeatureFusion", "FeatureConcat", "YOLOLayer"]中的任何一个x = module(x) # 直接运行该模块,例如卷积、上采样、最大池化、批量归一化等操作out.append(x if self.routs[i] else []) # 如果self.routs[i]为True,将当前模块的输出添加到out列表中,否则添加空列表if verbose:print('%g/%g %s -' % (i, len(self.module_list), name), list(x.shape), str) # 打印模块索引、类名、输入形状和之前拼接的字符串strstr = '' # 重置字符串str为空,用于下一次拼接if self.training: # trainreturn yolo_outelif ONNX_EXPORT: # export# x = [torch.cat(x, 0) for x in zip(*yolo_out)]# return x[0], torch.cat(x[1:3], 1) # scores, boxes: 3780x80, 3780x4p = torch.cat(yolo_out, dim=0)# # 根据objectness虑除低概率目标# mask = torch.nonzero(torch.gt(p[:, 4], 0.1), as_tuple=False).squeeze(1)# # onnx不支持超过一维的索引(pytorch太灵活了)# # p = p[mask]# p = torch.index_select(p, dim=0, index=mask)## # 虑除小面积目标,w > 2 and h > 2 pixel# # ONNX暂不支持bitwise_and和all操作# mask_s = torch.gt(p[:, 2], 2./self.input_size[0]) & torch.gt(p[:, 3], 2./self.input_size[1])# mask_s = torch.nonzero(mask_s, as_tuple=False).squeeze(1)# p = torch.index_select(p, dim=0, index=mask_s) # width-height 虑除小目标## if mask_s.numel() == 0:# return torch.empty([0, 85])return pelse: # inference or testx, p = zip(*yolo_out) # inference output, training outputx = torch.cat(x, 1) # cat yolo outputsreturn x, pdef info(self, verbose=False):"""打印模型的信息:param verbose::return:"""torch_utils.model_info(self, verbose)def get_yolo_layers(self):"""获取网络中三个"YOLOLayer"模块对应的索引:param self::return:"""return [i for i, m in enumerate(self.module_list) if m.__class__.__name__ == 'YOLOLayer'] # [89, 101, 113]
import os
import numpy as npdef parse_model_cfg(path: str):# 检查文件是否存在if not path.endswith(".cfg") or not os.path.exists(path):raise FileNotFoundError("the cfg file not exist...")# 读取文件信息with open(path, "r") as f:lines = f.read().split("\n")# 去除空行和注释行lines = [x for x in lines if x and not x.startswith("#")]# 去除每行开头和结尾的空格符lines = [x.strip() for x in lines]mdefs = [] # module definitionsfor line in lines:if line.startswith("["): # this marks the start of a new blockmdefs.append({})mdefs[-1]["type"] = line[1:-1].strip() # 记录module类型# 如果是卷积模块,设置默认不使用BN(普通卷积层后面会重写成1,最后的预测层conv保持为0)if mdefs[-1]["type"] == "convolutional":mdefs[-1]["batch_normalize"] = 0else:key, val = line.split("=")key = key.strip()val = val.strip()if key == "anchors":# anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326val = val.replace(" ", "") # 将空格去除mdefs[-1][key] = np.array([float(x) for x in val.split(",")]).reshape((-1, 2)) # np anchorselif (key in ["from", "layers", "mask"]) or (key == "size" and "," in val):mdefs[-1][key] = [int(x) for x in val.split(",")]else:# TODO: .isnumeric() actually fails to get the float caseif val.isnumeric(): # return int or float 如果是数值的情况mdefs[-1][key] = int(val) if (int(val) - float(val)) == 0 else float(val)else:mdefs[-1][key] = val # return string 是字符的情况# check all fields are supportedsupported = ['type', 'batch_normalize', 'filters', 'size', 'stride', 'pad', 'activation', 'layers', 'groups','from', 'mask', 'anchors', 'classes', 'num', 'jitter', 'ignore_thresh', 'truth_thresh', 'random','stride_x', 'stride_y', 'weights_type', 'weights_normalization', 'scale_x_y', 'beta_nms', 'nms_kind','iou_loss', 'iou_normalizer', 'cls_normalizer', 'iou_thresh', 'probability']# 遍历检查每个模型的配置for x in mdefs[1:]: # 0对应net配置# 遍历每个配置字典中的key值for k in x:if k not in supported:raise ValueError("Unsupported fields:{} in cfg".format(k))return mdefs
import torch.nn.functional as F
from .utils import *# 定义一个名为FeatureConcat的类,继承自nn.Module类,nn.Module是所有神经网络模块的基类
class FeatureConcat(nn.Module):"""# 类的文档字符串,用于解释类的功能将多个特征矩阵在channel维度进行concatenate拼接"""# 初始化函数,在创建类的实例时被调用def __init__(self, layers):# 调用父类的初始化函数,这是Python的继承机制的一部分super(FeatureConcat, self).__init__()# 将传入的参数layers赋值给self.layers,layer indices表示层的索引self.layers = layers # layer indices# 判断是否有多层,如果layers的长度大于1则说明有多个层,将结果赋值给self.multipleself.multiple = len(layers) > 1 # multiple layers flag# 前向传播函数,在计算输出时被调用def forward(self, x, outputs):# 如果有多层(即self.multiple为True),则使用torch.cat函数将outputs中对应self.layers的元素在channel维度拼接起来并返回,否则直接返回outputs中对应self.layers的元素return torch.cat([outputs[i] for i in self.layers], 1) if self.multiple else outputs[self.layers[0]]# 定义一个名为WeightedFeatureFusion的类,继承自nn.Module,用于实现特征矩阵的加权融合
class WeightedFeatureFusion(nn.Module): # weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070"""将多个特征矩阵的值进行融合(add操作)"""def __init__(self, layers, weight=False):# 调用父类的构造函数,进行初始化操作super(WeightedFeatureFusion, self).__init__()# 定义成员变量layers,存储要进行融合的特征矩阵的索引self.layers = layers # layer indices# 定义成员变量weight,表示是否应用权重,默认不应用权重self.weight = weight # apply weights boolean# 定义成员变量n,表示融合的特征矩阵个数加1self.n = len(layers) + 1 # number of layers 融合的特征矩阵个数# 如果应用权重,则定义成员变量w为nn.Parameter类型,初始值为torch.zeros(self.n),要求计算梯度if weight:self.w = nn.Parameter(torch.zeros(self.n), requires_grad=True) # layer weightsdef forward(self, x, outputs):# 前向传播函数,输入x为输入特征矩阵,outputs为所有层的输出特征矩阵# Weightsif self.weight:# 如果应用权重,则对权重进行sigmoid激活函数处理,使得权重在0-1之间w = torch.sigmoid(self.w) * (2 / self.n) # sigmoid weights (0-1)# 对输入特征矩阵x乘以权重w的第一个元素x = x * w[0]# Fusionnx = x.shape[1] # 输入特征矩阵x的通道数for i in range(self.n - 1):a = outputs[self.layers[i]] * w[i + 1] if self.weight else outputs[self.layers[i]] # feature to addna = a.shape[1] # 特征矩阵a的通道数# Adjust channels# 根据相加的两个特征矩阵的channel选择相加方式if nx == na: # same shape 如果channel相同,直接相加x = x + aelif nx > na: # slice input 如果channel不同,将channel多的特征矩阵砍掉部分channel保证相加的channel一致x[:, :na] = x[:, :na] + a # or a = nn.ZeroPad2d((0, 0, 0, 0, 0, dc))(a); x = x + aelse: # slice featurex = x + a[:, :nx]return x # 返回融合后的特征矩阵x
全部cfg
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16
width=608
height=608
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1 learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1 [convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky # Downsample[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear # Downsample[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear# Downsample[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear# Downsample[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear# Downsample[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky[shortcut]
from=-3
activation=linear######################[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky### SPP ###
[maxpool]
stride=1
size=5[route]
layers=-2[maxpool]
stride=1
size=9[route]
layers=-4[maxpool]
stride=1
size=13[route]
layers=-1,-3,-5,-6### End SPP ###[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=75
activation=linear[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=20
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1[route]
layers = -4[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[upsample]
stride=2[route]
layers = -1, 61[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=75
activation=linear[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=20
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1[route]
layers = -4[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[upsample]
stride=2[route]
layers = -1, 36[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=75
activation=linear[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=20
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1



![[Spring ~必知必会] Bean 基础常识汇总](https://img-blog.csdnimg.cn/img_convert/549241c9d7c3f383312e88ca73a16f9d.png)