主页:https://trex-counting.github.io/
github: GitHub - IDEA-Research/T-Rex: Detect and count any objects by visual prompting
论文:https://arxiv.org/abs/2311.13596
1、动机
对象计数领域,常用的方法有:
- 基于密度图的回归:回归一个2D密度图,作为计数结果;这种方法缺乏直观的视觉效果,很难让用户评估结果的准确性;
- 闭集目标检测:这是最常规的检测任务,需要闭集、类别已知,如YOLO系列等;这种方式如果要处理新类别,需要重新标注数据并训练模型,这是耗时且劳动密集的;
- 开集目标检测:如Grouping DINO,通过文本提示检测任意对象,这种方式的缺点是很多对象没有简洁的文本描述,这样在使用时,要定位想要的对象就变得比较困难,也即,很难找到准确的提示词;
- 多模态大语言模型问答:也即MLLM QA,用户通过问答来进行计数;这种方式的缺点是LLM的幻觉问题导致结果不可信,通常直接给出结果,却没有让用户可信的证据;
基于对上述方法缺点的观察,作者认为一个实用的计数系统应当具备以下四个特点:
- 直观的视觉反馈:应能提供像bbox、point、Mask之类的直观视觉反馈,从而佐证计数结果;
- 开集:应能计数任何对象,而非预定义的固定类别;
- 视觉提示:应允许用户通过指定一些示例作为提示,来计数特定类别的对象,而不需要像文本描述那样用文本来提示;
- 交互性:应能允许用户参与到整个计数过程,进行纠错等操作;

于是,作者设计出了T-Rex,同时具备以上四个特点,允许用户交互式地在开集上进行检测一切、计数一切。
2、方法
2.1 整体架构
T-Rex主要包括三个组件:图像编码器(ImageEncoder)、提示编码器(PromptEncoder)、框解码器(BoxDecoder)。一个典型的跨图操作如下所示:

简单描述一下:
- 先试用ImageEncoder对目标图和参考图分别进行图像编码;
- 然后将提示和参考图编码结果送入PromptEncoder,得到编码后的提示;
- 再然后将编码后的提示和目标图像的编码结果一起送入BoxDecoder,从而得到在目标图像上的检测结果;
- 如果检测结果没问题了(可能会经过多轮提示交互),就可以通过阈值过滤器,得到过滤后的目标计数;
*** 需注意 ***:
- 有时候一次提示不一定得到好的结果,可能会需要多轮交互提示;这个时候,图像编码是只做一次的,只需要对修改后的提示进行编码并重新进行框解码即可,也即ImageEncoder只在第一轮做一次,后续只做PromptEncoder和BoxDecoder;
- 如果不需要跨图,则上述过程中的目标图和参考图就是同一张图像了,也就只需要对图像做一次编码即可。
系统流程如图3所示:

2.2 工作模式
- Positive-only Prompt Mode:仅正例提示模式,只需用户提供正例prompt即可;
- Positive with Negative Prompt Mode:正例+负例提示模式,需要用户提示正例和负例;一般是先提供正例看看结果如何,若有误检,再提供负例,以消除误检;
- Cross-Image Prompt Mode:跨图提示模式,用户在参考图上进行提示,得到目标图上的检测结果;这种方式为自动化标注提供了可能,试想一下,我们对一批图像提前标注好,用这些标注作为prompt,在大量的新图像上进行处理,就可以得到预标注结果;
这几种模式的工作流程如图4所示:

2.3 讨论
T-Rex本质上是一个基于视觉prompt的开集检测器,相比基于文本prompt的开集检测器,区别在于视觉prompt更为直观且不存在问题描述定义不清的问题(比如:一个你从未见过或者无法用语言准备描述的物体)。
在目标计数任务中,一个重要考量是需要高度可信的预测,哪怕多一个少一个都是计数错误。T-Rex通过多轮交互、正负例提示来获取准确的检测检测结果,从而保证了精确的计数。
此外,多轮交互过程中,图像编码只进行一次,后续只对提示进行编码然后再进行框解码,这保证了整个过程的轻量化。
3. 一个新的计数数据集——Count Anything Benchmark
为了对 T-Rex 模型进行全面性能评估,作者提供了一个新的目标计数基准集——CA-44,其包含了44个数据集,涵盖了8个不同领域,如图5所示:

3. 实验结果


4. 缺点
目前的T-Rex还有很多缺点:
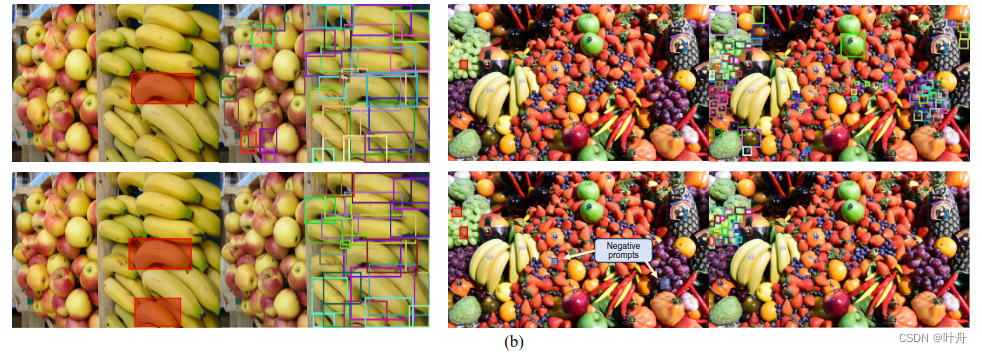
- 在单目标场景中,对目标做了提示后,可能会出现很多背景的误检,模型错误地将背景识别为密集目标;
- 密集多目标场景中,不同类别的密集目标可能会误检,需要提供更多负例;
- 跨图工作时,尤其是同时也是单目场景时,过拟合的风险很大,模型往往会忽略参考图上的提示,从而在目标图错误地检测出其他类别的目标;
T-Rex中的失败案例:(a)在单目标场景中,如果背景只引入单个提示,T-Rex仍然会检测到图中的密集对象。(b) 在密集的多目标场景中,T-Rex 可以产生错误检测,需要多个提示或否定提示进行校正。(c) 在跨图像工作流程中,T-Rex 在单目标密集场景中的风险过度拟合,导致错误的检测,例如为番茄打丝虫卵。


5. 试玩
在文章开头的主页地址中,我们可以试玩一下作者提供的Demo。
先使用其示例图像:

再用自己上传的图像(结果有三种选择:point、bbox、mask):

失败案例(用经典人群计数数据集中的图片,来看看对人头的检测效果如何):

可见,这种密集场景下,人头可判别特征很少,其效果是很不理想的;而对于上面的西瓜、人这种特征明显的目标,则具有不错的效果。
依我之见,此方法和SAM一样,对于常规目标、特征明显的目标是可用且效果显著的,而对于一些特征不显著的非常规目标,如裂缝、密集场景中的人头等,效果不甚理想。