最近亲戚想做点小超市生意,但是又不懂互联网,信息获取有点闭塞。知道我身在互联网大潮中,想让我帮忙看看网上有没有商铺转让的。心想,这不是小菜一碟,大显身手的时候来了,大概去58瞅了瞅,这玩意要我每天帮他刷新信息,获取有用的信息告诉他。以我的性格,我能这么干?
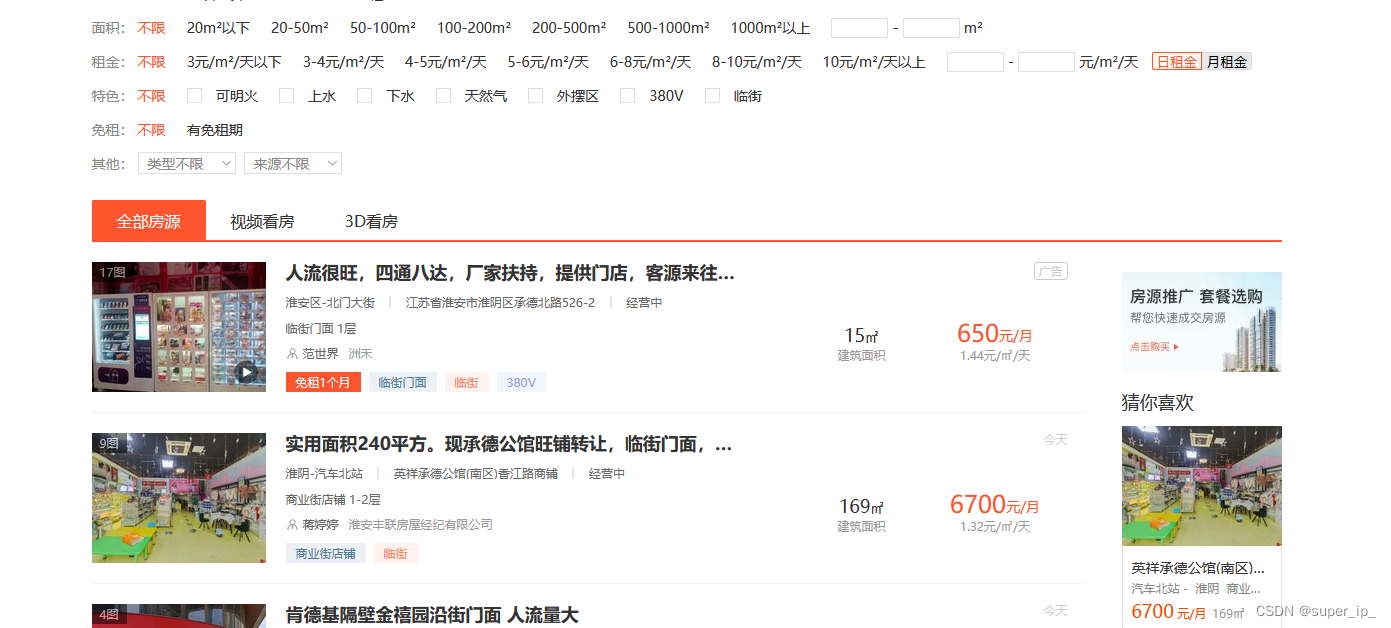
只能闲来有事,为了亲戚亲自出马写个抓取程序,你别说,还能用,那还说啥。动起来呗!
<?php
// 华科云商http代理服务器地址
$proxy = 'www.jshk.com.cn:30000';// 目标URL
$url = 'https://ha.58.com/shangpucz/?PGTID=0d100000-003c-8e2b-e5fa-f390550bfcd3&ClickID=7';// 初始化 cURL
$ch = curl_init();// 设置代理服务器
curl_setopt($ch, CURLOPT_PROXY, $proxy);// 设置URL和其他适当的选项
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);// 设置cURL选项以模拟真实浏览器
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3');// 设置SSL选项
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);// 抓取URL并把它传递给浏览器
$data = curl_exec($ch);// 检查是否有错误发生
if(curl_errno($ch))
{echo 'Curl error: ' . curl_error($ch);
}// 关闭cURL资源,并且释放系统资源
curl_close($ch);// 使用DOM解析器来解析HTML
$dom = new DOMDocument();
@$dom->loadHTML($data);// 使用XPath来查询我们需要的元素
$xpath = new DOMXPath($dom);
$elements = $xpath->query("//div[@class='some-class']"); // 请修改这里的XPath查询以匹配你需要的元素// 输出抓取的数据
foreach($elements as $element)
{echo $element->nodeValue, "\n";
}
?>
这样每天我下班的时候看看数据有啥新变动没,然后去和亲戚唠唠嗑啥的,完美的一天就这么过去了。这个仅供参考,不要来杠啊!
有啥问题或需求的,直接私信或留言。