本文来自正在规划的Go语言&云原生自我提升系列,欢迎关注后续文章。
2000年以来,自动化测试的广泛应用可能比任何其他软件工程技术都更能提高代码质量。Go是一种专注于提高软件质量的语言和生态系统,很自然的在其标准库中包含了测试支持。Go中测试代码非常容易,没有理由不添加测试。本章中,读者将了解如何测试Go代码,将测试分组为单元测试和集成测试,检查测试代码覆盖率,编写基准测试,并学习如何使用Go竞态检查器检测代码的并发问题。同时,还会讨论如何编写可测试的代码,以及为什么它会提高我们的代码质量。
测试的基础知识
Go的测试支持由两部分组成:库和工具。标准库中的testing包提供了编写测试所需的类型和函数,而Go包中的go test工具可运行测试并生成报告。与许多其他语言不同,Go的测试放在与生产代码相同的目录和相同的包中。由于测试位于同一包中,它们能够访问和测试未导出的函数和变量。读者很快就会学到如何编写仅测试公开API的测试。
注:本章的完整代码示例请见第15章的GitHub代码库。
下面编写一个简单的函数,然后编写测试来确保该函数正常运行。在sample_code/adder目录中的文件adder.go中添加如下代码:
func addNumbers(x, y int) int {return x + x
}相应的测试为adder_test.go:
func Test_addNumbers(t *testing.T) {result := addNumbers(2,3)if result != 5 {t.Error("incorrect result: expected 5, got", result)}
}测试文件都以_test.go结尾。如要为foo.go编写测试,可将测试放在名为foo_test.go的文件中。
测试函数以Test开头,并接收一个类型为*testing.T的参数。按照惯例,该参数被命名为t。测试函数不返回任何值。测试的名称(不含开头的“Test”)用于记录正在进行测试的内容,因此请选择能说明您正在测试内容的名称。在为单独的函数编写单元测试时,惯例是将单元测试命名为Test后接函数的名称。在测试未导出函数时,有些人会在Test和函数名称之间使用下划线。
此外,请注意使用标准的Go代码来调用正在进行测试的代码,并验证响应是否与预期一致。当结果不正确时,可以使用t.Error方法报告错误,使用方式类似于fmt.Print函数。读者很快会学到其他报告错误的方法。
刚刚了解了Go测试支持库的部分。下面来看看工具部分。就像go build用于构建二进制文件、go run用于运行文件一样,命令go test用于运行当前目录中的测试函数:
$ go test
--- FAIL: Test_addNumbers (0.00s)adder_test.go:8: incorrect result: expected 5, got 4
FAIL
exit status 1
FAIL test_examples/adder 0.006s貌似我们发现了代码中的bug。仔细观察addNumbers,发现我们使用x加x,而不是x加y。下面修改代码重新运行测试看bug是否已修复:
$ go test
PASS
ok test_examples/adder 0.006sgo test命令允许我们指定要测试的包。使用./...作为包名称表示要运行当前目录以及其所有子目录中的测试。添加-v标记获取详细的测试输出。
报告测试失败
*testing.T有几个报告测试失败的方法。我们已经用过Error,它将一组逗号分隔的值构建成一个失败描述字符串。
如果读者更乐意使用类似Printf的格式化字符串来生成消息,请改用Errorf方法:
t.Errorf("incorrect result: expected %d, got %d", 5, result)虽然Error和Errorf标记测试为失败,但测试函数会继续运行。如果觉得测试函数应该在发现失败后立即停止处理,使用Fatal和Fatalf方法。Fatal方法类似于Error,而Fatalf方法类似Errorf。不同之处在于,在生成测试失败消息后,测试函数会立即退出。注意,它不会退出所有测试;在当前测试函数退出后,剩余的测试函数都将继续执行。
何时该使用Fatal/Fatalf,何时该使用Error/Errorf呢?如果测试中的某个检查失败表示同一测试函数中的后续检查也将失败或导致测试panic,那么请使用Fatal或Fatalf。如果测试多个独立的项目(例如验证结构体中的字段),那么请使用Error或Errorf,这样可同时报告多个问题。也就可以更轻松地修复多个问题,而无需一次又一次地反复运行测试。
设置和清理
有时可能希望在运行测试之前设置一些通用状态,并在测试完成时将其删除。使用TestMain函数来管理该状态并运行测试:
var testTime time.Timefunc TestMain(m *testing.M) {fmt.Println("Set up stuff for tests here")testTime = time.Now()exitVal := m.Run()fmt.Println("Clean up stuff after tests here")os.Exit(exitVal)
}func TestFirst(t *testing.T) {fmt.Println("TestFirst uses stuff set up in TestMain", testTime)
}func TestSecond(t *testing.T) {fmt.Println("TestSecond also uses stuff set up in TestMain", testTime)
}TestFirst和TestSecond都引用了包级变量testTime。正确运行测试需要对其进行初始化。我们声明了一个名为TestMain的函数,其参数类型为*testing.M。如果包中有名为TestMain的函数,go test会去调用它,而不是其它测试函数。TestMain函数的责任是设置包中的测试正常运行所需的所有状态。一旦配置了状态,TestMain函数会在*testing.M上调用Run方法。这会运行包中的测试函数。Run方法返回退出码;0表示所有测试全部通过。最后,TestMain函数必须使用Run返回的退出码调用os.Exit。
运行go test输出如下:
$ go test
Set up stuff for tests here
TestFirst uses stuff set up in TestMain 2020-09-01 21:42:36.231508 -0400 EDTm=+0.000244286
TestSecond also uses stuff set up in TestMain 2020-09-01 21:42:36.231508 -0400EDT m=+0.000244286
PASS
Clean up stuff after tests here
ok test_examples/testmain 0.006s注:请注意,
TestMain只会调用一次,不会在每个单独的测试之前和之后都调用。此外,请注意每个包只能有一个TestMain。
一般在两种常见情况下使用TestMain:
- 需要在外部存储(如数据库)中设置数据时。
- 测试的代码依赖于需初始化的包级变量时。
前面已提到(还会再次提到!),应避免在程序中使用包级变量。那会让我们难以理解数据如何在程序中流动。如果出于这个原因使用TestMain,请考虑重构代码。
*testing.T上的Cleanup方法用于清理为单个测试创建的临时资源。该方法有一个参数,即没有输入参数或返回值的函数。该函数在测试完成时运行。对于简单的测试,可使用defer语句来实现相同的结果,但是当测试依赖于帮助函数来设置示例数据时,如例12-1,Cleanup非常有用。可以多次调用Cleanup,和defer一样,函数按照最后添加最先调用的顺序调用。
例12-1 使用t.Cleanup
// createFile is a helper function called from multiple tests
func createFile(t *testing.T) (_ string, err error) {f, err := os.Create("tempFile")if err != nil {return "", err}defer func() {err = errors.Join(err, f.Close())}()// write some data to ft.Cleanup(func() {os.Remove(f.Name())})return f.Name(), nil
}func TestFileProcessing(t *testing.T) {fName, err := createFile(t)if err != nil {t.Fatal(err)}// do testing, don't worry about cleanup
}如果测试中使用了临时文件,您可以利用*testing.T上的TempDir方法,无需编写清理代码。每次调用此方法时,都会新建一个临时目录,并返回目录的完整路径。它还会在测试完成时使用Cleanup注册一个处理程序,删除目录及其内容。可以使用它重写上面的示例:
// createFile is a helper function called from multiple tests
func createFile(tempDir string) (_ string, err error) {f, err := os.CreateTemp(tempDir, "tempFile")if err != nil {return "", err}defer func() {err = errors.Join(err, f.Close())}()// write some data to freturn f.Name(), nil
}func TestFileProcessing(t *testing.T) {tempDir := t.TempDir()fName, err := createFile(tempDir)if err != nil {t.Fatal(err)}// do testing, don't worry about cleanup
}使用环境变量进行测试
使用环境变量来配置应用程序是一种常见(也是非常好的)做法。为有助测试环境变量解析代码,Go在testing.T上提供了一个帮助方法。调用t.Setenv()可为测试注册环境变量的值。在背后,它会在测试退出时调用Cleanup,将环境变量恢复到其先前的状态。
// assume ProcessEnvVars is a function that processes envrionment variables
// and returns a struct with an OutputFormat field
func TestEnvVarProcess(t *testing.T) {t.Setenv("OUTPUT_FORMAT", "JSON")cfg := ProcessEnvVars()if cfg.OutputFormat != "JSON" {t.Error("OutputFormat not set correctly")}// value of OUTPUT_FORMAT is reset when the test function exits
}注:虽然使用环境变量来配置应用程序是好做法,但也应确保大部分代码完全不知道它们的存在。在程序开始运行之前,确保将环境变量的值复制到配置结构体中,可以在
main函数或其后的位置实现。这样做可以更易于重用和测试代码,因为代码的配置方式已经从代码的实际功能抽象出来了。相比自己编写这些代码,强烈建议考虑使用第三方配置库,比如Viper或envconfig。此外,可以考虑使用GoDotEnv将环境变量存储在
.env文件中,以供开发或持续集成机器使用。
存储样本测试数据
在go test遍历源代码树时,它将当前包目录用作工作目录。如果想要使用样本数据来测试包中的函数,请创建一个名为 testdata 的子目录来存储文件。Go 保留此目录名称作为保存测试文件的位置。在从 testdata 读取时,保持使用相对文件引用。由于go test会将当前工作目录更改为当前包,每个包会通过相对文件路径访问自己的 testdata。
小贴士:text包演示了如何使用 testdata。
缓存测试结果
就像在模块、包和导入中学到的那样,如果编译的包没有更改,Go 会将其缓存起来,在跨包运行测试时,如果测试已经通过且其代码没有更改,Go 也会缓存测试结果。如果修改了包中的任何文件或 testdata 目录中的文件,测试将被重新编译并重新运行。如果传递标记 -count=1给 go test,还可以强制测试始终运行。
测试公开API
我们编写的测试与生产代码位于同一个包中。这样能够测试导出和未导出的函数。
如果只想测试包的公开API,Go 有一种约定来进行指定。依然将测试源代码保存在与生产源代码相同的目录中,但使用 packagename_test 作为包名。重新执行我们最初的测试案例,这次使用一个已导出的函数。代码位于第15章的GitHub代码库中的 sample_code/pubadder 目录中。如果在 pubadder 包中有以下函数:
func AddNumbers(x, y int) int {return x + y
}那么可以使用pubadder包中 adder_public_test.go文件的如下代码测试公开API:
package pubadder_testimport ("github.com/learning-go-book-2e/ch15/sample_code/pubadder""testing"
)func TestAddNumbers(t *testing.T) {result := pubadder.AddNumbers(2, 3)if result != 5 {t.Error("incorrect result: expected 5, got", result)}
}请注意,我们测试文件的包名为 pubadder_test。尽管这些文件位于同一个目录中,我们仍需要导入 github.com/learning-go-book-2e/ch15/sample_code/pubadder。为遵循测试命名的约定,测试函数的名称与 AddNumbers 函数的名称相匹配。另外注意,我们使用了 pubadder.AddNumbers,因为是在不同的包中调用了一个已导出的函数。
小贴士:如果手动输入此代码,需要创建一个带有模块声明文件
go.mod的模块:module github.com/learning-go-book-2e/ch15
并将源代码放在模块的 sample_code/pubadder 目录中。
正如可以从包内部调用已导出的函数一样,也可以从源代码同一个包中的测试中测试公开API。在包名中使用_test后缀的优势是,可以将所测试的包视为“黑盒”。只能通过其导出的函数、方法、类型、常量和变量与其进行交互。还要注意,可以在同一源代码目录中交叉使用两个包名的测试源文件。
使用go-cmp比较测试结果
编写两个复合类型实例之间的完整比较可能会很冗长。虽然我们可以使用reflect.DeepEqual来比较结构体、字典和切片,但还有一种更好的方法。Google 发布了一个名为 go-cmp的第三方模块,它可以做这种比较,并返回不匹配内容的详细描述。我们通过定义一个简单的结构体和一个为其赋值的工厂函数来看看是如何使用的。代码位于第15章的GitHub代码库的 sample_code/cmp 目录中:
type Person struct {Name stringAge intDateAdded time.Time
}func CreatePerson(name string, age int) Person {return Person{Name: name,Age: age,DateAdded: time.Now(),}
}在测试文件中,需要导入github.com/google/go-cmp/cmp,测试函数如下:
func TestCreatePerson(t *testing.T) {expected := Person{Name: "Dennis",Age: 37,}result := CreatePerson("Dennis", 37)if diff := cmp.Diff(expected, result); diff != "" {t.Error(diff)}
}cmp.Diff函数接收期望输出和待测试函数返回的输出作为参数。它返回一个字符串,描述这两个输入之间的不匹配之处。如果输入匹配,它将返回一个空字符串。将cmp.Diff函数的输出赋给一个名为 diff 的变量,然后检测 diff 是否为空字符串。如果不为空,就表示发生了错误。
在构建并运行测试时,会看到go-cmp在两个结构体实例不匹配时生成的输出:
$ go test
--- FAIL: TestCreatePerson (0.00s)ch13_cmp_test.go:16: ch13_cmp.Person{Name: "Dennis",Age: 37,- DateAdded: s"0001-01-01 00:00:00 +0000 UTC",+ DateAdded: s"2020-03-01 22:53:58.087229 -0500 EST m=+0.001242842",}FAIL
FAIL ch13_cmp 0.006s以-和 +开头的行表示值不同的字段。这里测试失败是因为时间不匹配。这是一个问题,因为您无法控制 CreatePerson函数所赋的时间。需要忽略 DateAdded 字段。通过指定一个比较函数来实现。在测试中将该函数声明为一个局部变量:
comparer := cmp.Comparer(func(x, y Person) bool {return x.Name == y.Name && x.Age == y.Age
})将一个函数传递给cmp.Comparer函数,以创建一个自定义比较器。传入的函数两个参数必须为相同类型,并返回一个布尔值。它还必须是对称的(参数的顺序无关紧要)、确定性的(对于相同的输入,始终返回相同的值)和纯粹的(不能修改其参数)。在我们的实现中,比较 Name 和 Age 字段,忽略 DateAdded 字段。
然后修改调用cmp.Diff的代码,包含comparer:
if diff := cmp.Diff(expected, result, comparer); diff != "" {t.Error(diff)
}这只是对go-cmp最有用特性的快速概览。参见其官方文档学如何控制比较内容和输出格式。
表格测试
大多数情况下,验证函数是否正确运行通常需要多个测试用例。可以编写多个测试函数来验证该函数,或者在同一个函数内编写多个测试,但你会发现大部分测试逻辑是重复的。需要设置支持数据和函数,指定输入,检查输出,并进行比较以查看它们是否符合预期。与其一遍又一遍地编写这些内容,不如利用一种称为表格测试的模式。我们来看一个示例。代码们于第15章的GitHub代码库的 sample_code/table 目录中。假设我们在 table 包中有以下函数:
func DoMath(num1, num2 int, op string) (int, error) {switch op {case "+":return num1 + num2, nilcase "-":return num1 - num2, nilcase "*":return num1 + num2, nilcase "/":if num2 == 0 {return 0, errors.New("division by zero")}return num1 / num2, nildefault:return 0, fmt.Errorf("unknown operator %s", op)}
}要测试该函数,需要检查不同的分支,尝试返回有效结果的输入,以及触发错误的输入。可以编写如下代码,但这非常繁复:
func TestDoMath(t *testing.T) {result, err := DoMath(2, 2, "+")if result != 4 {t.Error("Should have been 4, got", result)}if err != nil {t.Error("Should have been nil error, got", err)}result2, err2 := DoMath(2, 2, "-")if result2 != 0 {t.Error("Should have been 0, got", result2)}if err2 != nil {t.Error("Should have been nil error, got", err2)}// and so on...
}我们改用表格测试。首先,声明一个匿名结构体切片。结构体包含测试的名称、入参和返回值的字段。切片中的每条代表一个测试:
data := []struct {name stringnum1 intnum2 intop stringexpected interrMsg string
}{{"addition", 2, 2, "+", 4, ""},{"subtraction", 2, 2, "-", 0, ""},{"multiplication", 2, 2, "*", 4, ""},{"division", 2, 2, "/", 1, ""},{"bad_division", 2, 0, "/", 0, `division by zero`},
}接着,循环遍历data中的每个测试用例,每次调用 Run 方法。这是有魔法的一行代码。我们向 Run 传递两个参数,一个子测试的名称,和一个带有类型为*testing.T的单个参数的函数。在函数内部,我们使用data中当前条目的字段调用 DoMath,一遍又一遍地使用相同的逻辑。在运行这些测试时,不仅会看到它们通过了,而且当您使用-v标记时,每个子测试都有一个名称:
for _, d := range data {t.Run(d.name, func(t *testing.T) {result, err := DoMath(d.num1, d.num2, d.op)if result != d.expected {t.Errorf("Expected %d, got %d", d.expected, result)}var errMsg stringif err != nil {errMsg = err.Error()}if errMsg != d.errMsg {t.Errorf("Expected error message `%s`, got `%s`",d.errMsg, errMsg)}})
}小贴士:比较错误消息很不可靠,因为可能没有对消息文本的兼容性保证。我们正在测试的函数使用
errors.New和 fmt.Errorf 创建错误,因此唯一的选择是比较消息。如果错误为自定义类型,请使用errors.Is或errors.As来检查是否返回了正确的错误。
有了运行大量测试的方法,下面了解一下测试代码的覆盖率。
并发运行测试
默认情况下,单元测试是顺序运行的。由于每个单元测试应与其他单元测试相互独立,进行并发测试非常理想。要使单元测试与其他测试并发运行,可在测试中的第一行调用*testing.T上的 Parallel 方法:
func TestMyCode(t *testing.T) {t.Parallel()// rest of test goes here
}并行测试与其他标记为并行的测试并发运行。
并行测试的优势在于它可以加速运行时间较长的测试套件。但也有一些缺点。如果有多个依赖于相同共享可变状态的测试,请不要将它们标记为并行,因为会得到不一致的结果。(但在所有这些警告之后,你的应用程序中没有任何共享可变状态吧?)此外,还要注意,如果将测试标记为并行并在测试函数中使用 Setenv 方法,测试会 panic。
在并行运行表格测试时要小心。当表格测试并行运行时,就像我们在 for 循环中启动了多个 goroutine 一样。在这个示例中,变量d的引用被所有并行测试共享,因此它们都看到相同的值:
func TestParallelTable(t *testing.T) {data := []struct {name stringinput intoutput int}{{"a", 10, 20},{"b", 30, 40},{"c", 50, 60},}for _, d := range data {t.Run(d.name, func(t *testing.T) {t.Parallel()fmt.Println(d.input, d.output)out := toTest(d.input)if out != d.output {t.Error("didn't match", out, d.output)}})}
}可在The Go Playground中运行这段代码或是通过第15章的GitHub代码库的 sample_code/parallel 目录获取代码。查看输出会看到对表格测试中最后的值进行了三次测试:
=== CONT TestParallelTable/a
50 60
=== CONT TestParallelTable/c
50 60
=== CONT TestParallelTable/b
50 60要避免这一问题,在for循环中调用t.Run前遮蔽d:
for _, d := range data {d := d // THIS IS THE LINE THAT SHADOWS d!t.Run(d.name, func(t *testing.T) {t.Parallel()fmt.Println(d.input, d.output)out := toTest(d.input)if out != d.output {t.Error("didn't match", out, d.output)}})}检测代码覆盖率
代码覆盖率是一个非常有用的工具,可以知道是否漏掉了某些明显的状况。但达到100%的测试覆盖率并不能保证在某些输入下代码中没有错误。首先,我们会学习如何使用go test展示代码覆盖率,然后我们会了解仅依赖代码覆盖率的局限性。
在go test命令中添加-cover标记可以计算覆盖率信息,并在测试输出中添加摘要。如果再加上一个-coverprofile 的参数,可将覆盖率信息保存到一个文件中。我们再回到第15章的GitHub代码库的sample_code/table目录中,收集代码覆盖率信息:
$ go test -v -cover -coverprofile=c.out如果检测表格测试的代码覆盖率,测试输出会显示一行信息,代码覆盖率为87.5%。虽然这是有用的信息,但我们更希望看到漏掉了哪些测试。Go 附带的cover工具会生成包含了这些信息的 HTML 表示:
$ go tool cover -html=c.out运行该命令,应该会打开浏览器并能看到如图12-1的页面:
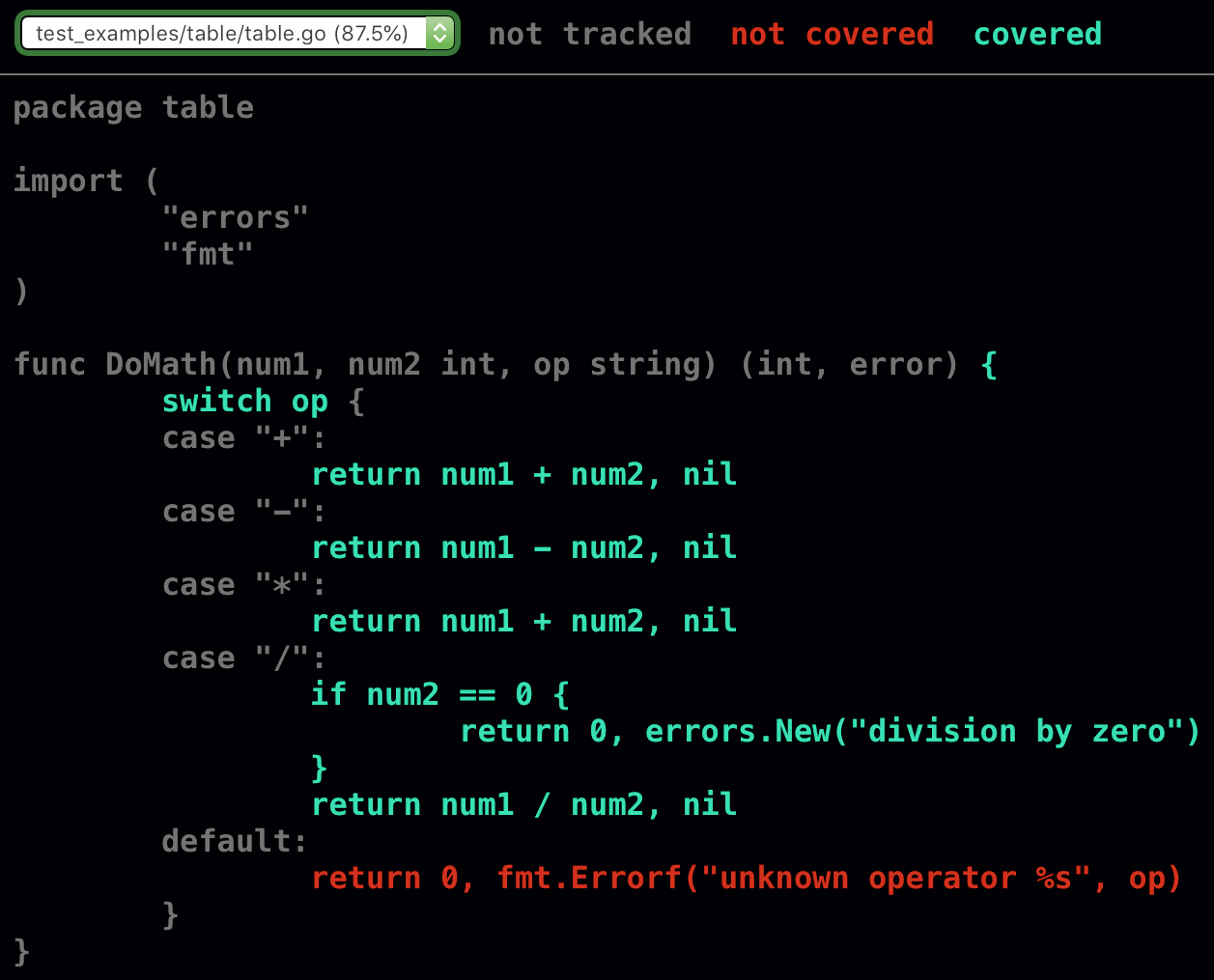
图12-1:初始测试代码覆盖率
每个测试过的文件都会出现在左上角的组合框中。源代码有三种颜色。灰色表不可测试的代码行,绿色表已被测试覆盖的代码,红色表未经测试的代码。通过观察颜色,可以看出我们没有对default分支编写测试,即对函数传递错误的运算符时。下面将这种情况添加到测试列表中:
{"bad_op", 2, 2, "?", 0, `unknown operator ?`},重新运行go test -v -cover -coverprofile=c.out和go tool cover -html=c.out,可在图12-2中看到测试代码覆盖率为100%。
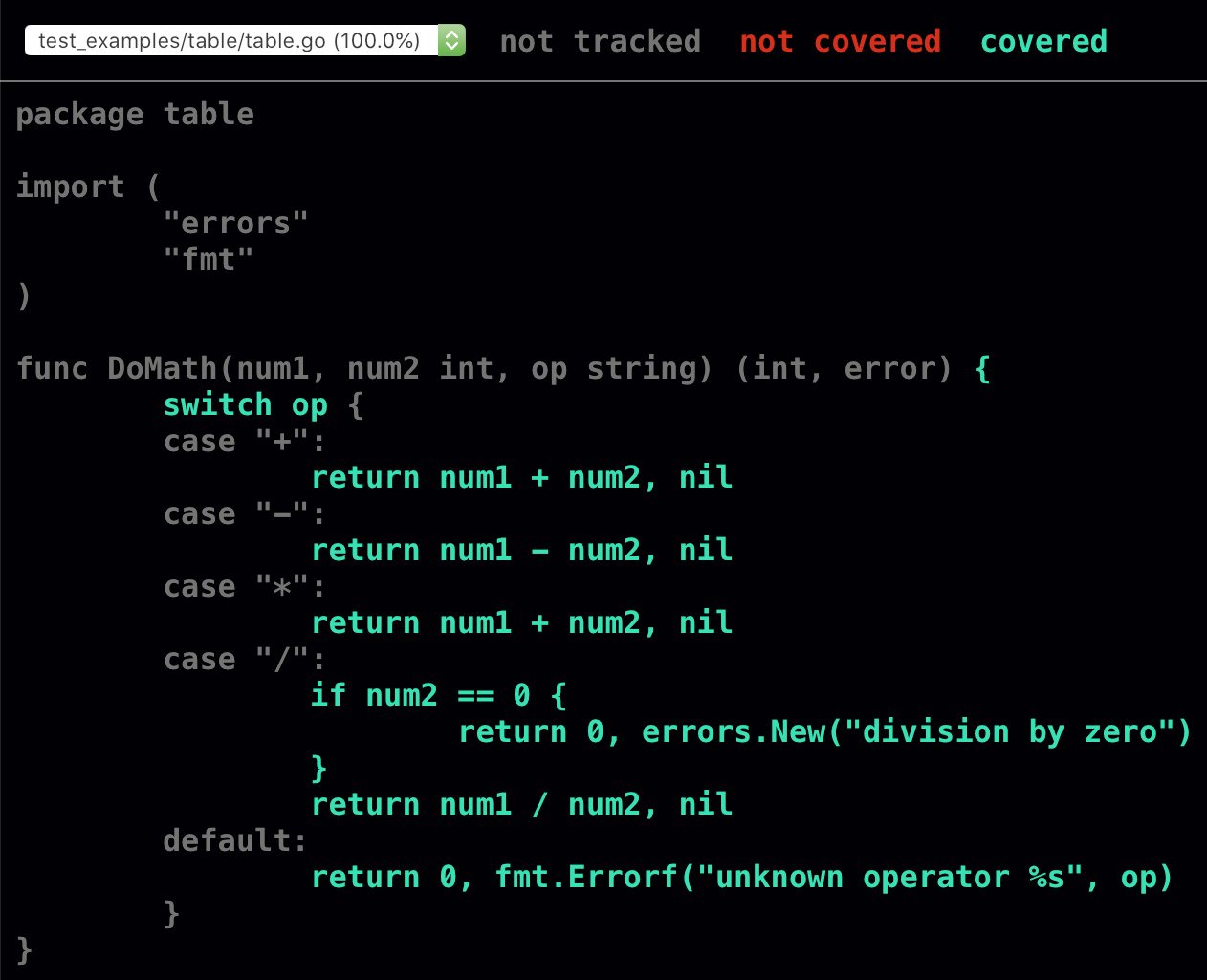
图12-2:最终测试代码覆盖率
代码覆盖率非常棒,但也有不足。虽然有100%的覆盖率,但代码中却有一个bug。不知读者有没有注意到?如果没有,可以添加另一个测试用例然后运行测试:
{"another_mult", 2, 3, "*", 6, ""},可以看到如下错误:
table_test.go:57: Expected 6, got 5在乘法用例中有一处笔误。对乘法使用了加号。(复制、粘贴代码时要格外小心!)修改代码,再次运行go test -v -cover -coverprofile=c.out和go tool cover -html=c.out,测试会正常通过。
警告:代码覆盖率很有必要,但并不足够。覆盖率为100%的代码仍可能存在bug。