大家好,我是君哥。
前段时间滴滴的故障相信大家都知道了。中断业务 12 小时定级为 P0 级故障一点都不冤。

故障回顾
网上有传言是运维人员升级 k8s 时,本来计划是从 1.12 版本升级到 1.20,但是操作失误选错了版本,操作了集群降级到低版本。
从下面滴滴技术的博客中也可以看到滴滴的升级方案:
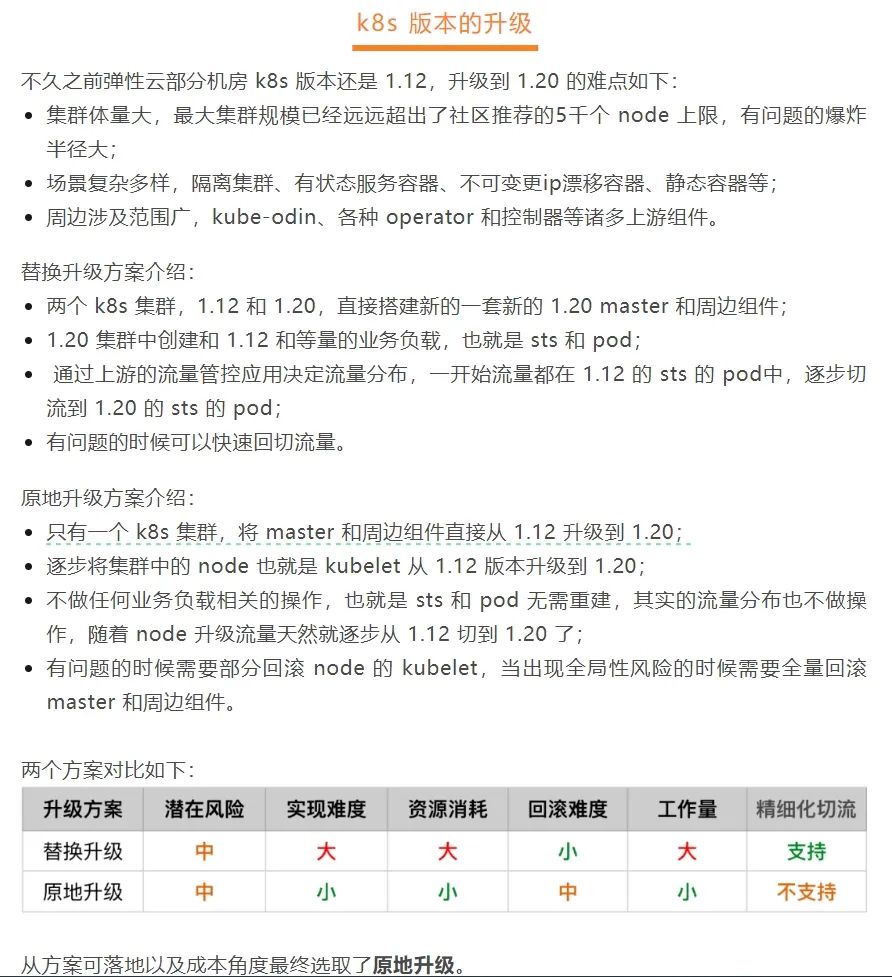
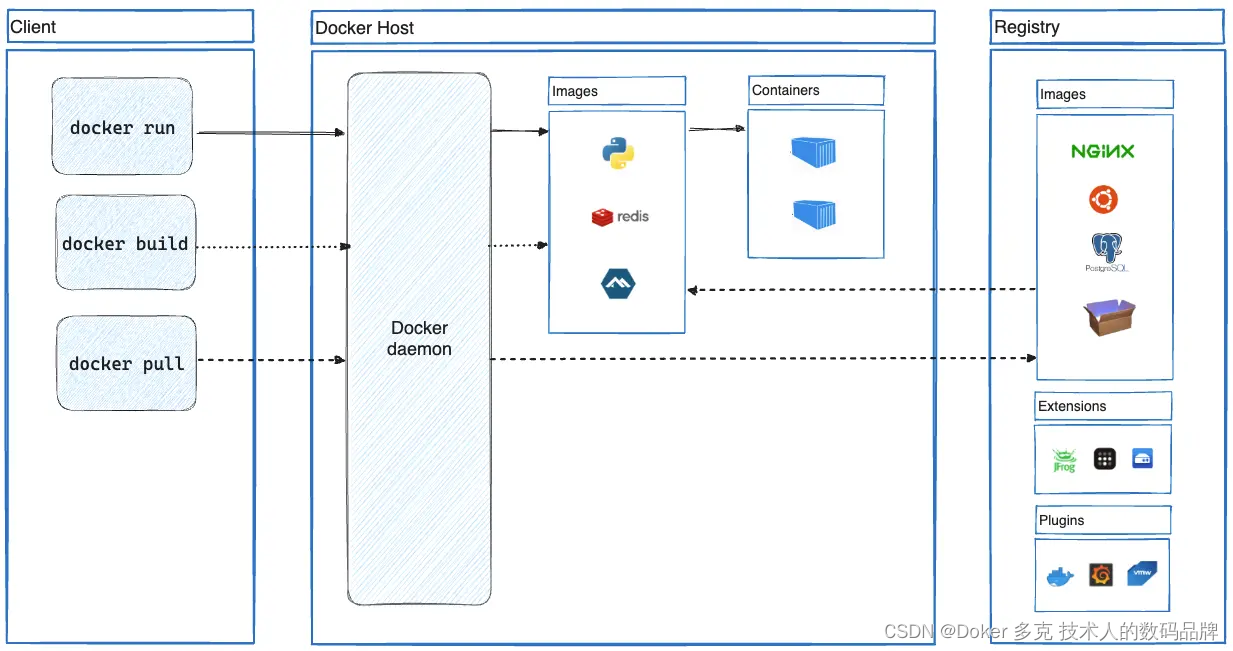
滴滴为了降低升级成本,选择了原地升级的方式。首先升级 master,然后升级 node。我们一起看一下 k8s 官方架构:
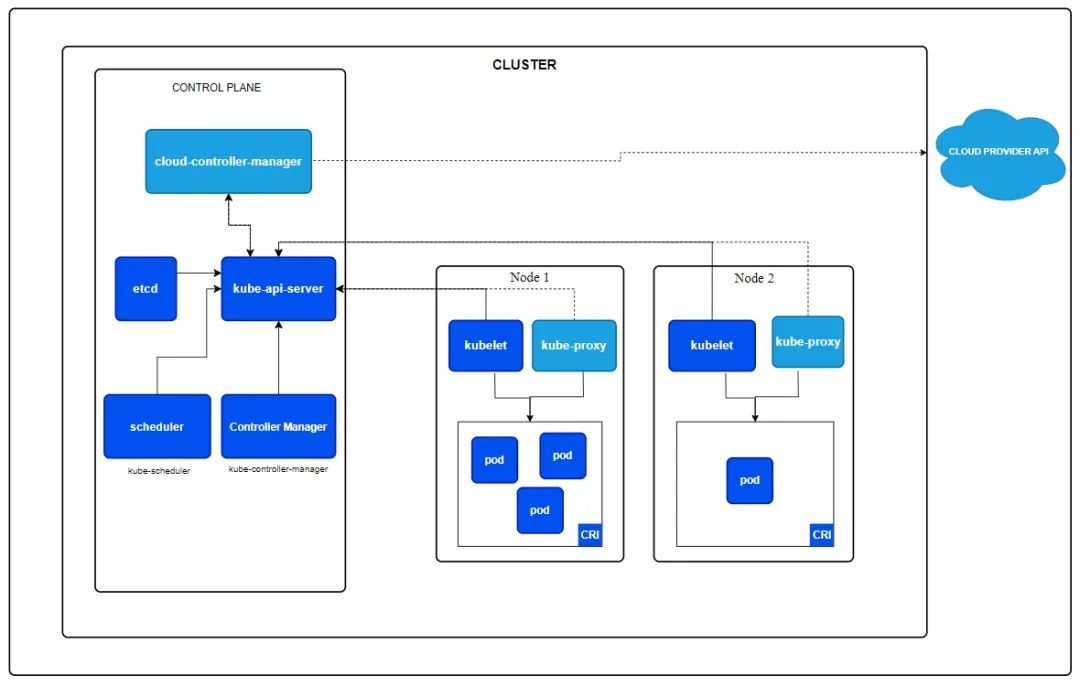
master(官网图中叫 CONTROL PLANE) 节点由 3 个重要的组件组成:
-
cloud-controller-manager:负责容器编排;
-
kube-api-server:为 Node 节点提供 api 注册服务;
-
scheduler:负责任务调度。
Node 节点向 kube-api-server 注册成功后,才可以运行 Pod。从滴滴的博客中可以看到,采用原地升级的方式,升级了 master 之后,逐步升级 Node,Node 会有一个重新注册的过程,不过既然选择这个方案,运维人员应该反复演练过,重新注册耗时应该非常短,用户无感知。
但是 master 选错版本发生降级时,会把 kube-api-server 污染,Node 节点注册 master 失败,又不能快速回滚,这样 Node 节点被集群认为是非健康节点,上面的 pod 被 kill 掉,服务停止。
集群隔离
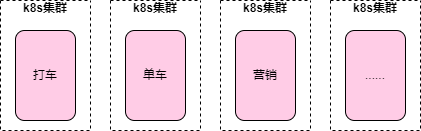
这次故障大家讨论的话题还有一个比较热门的就是 k8s 集群隔离,因为多个业务比如打车业务、单车业务同时挂,说明都在一个集群上,没有单独建集群来做隔离,这可能也是博客中说的“最大集群规模已经远远超出了社区推荐的5千个 node 上限”的原因。
当然也有可能当时野蛮生长的时候,为了快速上线开展业务,就多个业务建在了一个集群上,后来可能也有过拆分的想法,但发现业务上升空间已经很小,现有集群可以维持,所以就搁置了。
拆分成多个集群好处很明显,业务隔离,故障隔离,可靠性增加,就拿这次升级来说,先升级一个不太关键、业务量也比较小的集群做试点,升级成功了再逐个升级其他集群。
但缺点也很明显,运维复杂度增加,成本增加。
升级方案
工作这些年,也参与过一些大规模的平台重构,但原地升级真的是没有接触过,主要原因就是架构师们不太愿意选择原地升级的方案。而他们主要出于下面考虑:
-
业务系统原地重构升级,不像推翻重做能够更彻底地升级改造;
-
考虑对业务影响最小,一般是要通过灰度发布渐进地把流量切过去;
-
替换升级的方案,更能展现团队的产出。
对于滴滴这样的大公司,相信运维团队大咖如云,无论采用哪种方案,肯定都是经过反复验证的,或许不要选错版本,原地升级也没有问题。
降本增效
看了微博上滴滴道歉的留言区,好多人猜测这次事故的原因是降本增效,裁掉了一线高成本的运维,保留了成本低的新人。
从数据上来看,出于降本增效的目的,滴滴这两年确实少了很多人,但我不相信这是造成事故的直接原因。
在快速增长的阶段,确实需要投入大量的技术人员来建设系统。但国内互联网规模也基本见顶了,一个业务经营这么多年,不会再有爆发式地增长,系统也已经非常稳定。这样的背景下,公司确实用不了这么多技术人员了,留下部分人员来维护就够了。
所以,无论哪家公司,降本增效是业务稳定后必定会经历的阶段。想想滴滴这次 12 小时故障的损失,能比养 1000 个技术人员的成本高吗?
对于我们研发人员,如果有机会进入快速增长的公司,那就抓住机会多挣钱,被裁员的时候平常心看待就可以了,想在一家公司干到退休太难了。同时也要看到自己给公司带来的价值,千万不要认为我们技术厉害就比那个 PPT 工程师更有价值。
总结
本文根据网上流传的滴滴故障的原因,分析了升级方案和降本增效。最后,又快年末了,希望大家都能维护好自己的系统,不要发生严重故障影响自己的年底考核。