TCP重传机制
TCP针对数据包丢失的情况,会通过重传机制解决,包括像超时重传、快速重传、选择确认SACK、D-SACK
超时重传
TCP会设置一个定时器,如果在发送数据之后的规定时间内,没有收到对方的ACK报文,就会触发重新发送数据。那么这个规定的时间应该设置为多少呢?这里有两个时间的概念
-
RTT(Round-Trip Time):往返时延,也就是从发送数据开始到接收应答报文的时间
-
RTO(Retransimission Timeout):超时重传时间,在数据发送之后开始,如果RTO时间内没有收到ACK报文,就会重新发送报文
超时重传时间如果设置的太小,会导致数据包还没有到达对方主机,或者是对方确认应答还没有到达本机时,就重新发送数据包,导致重复发送、网络负荷增大;如果设置的太大,会导致丢包后重新发送数据包的空闲时间太长,降低传输效率。
所以超时重传的时间应该略大于往返时延,这才能保证不会太大或太小。
由于网络是不断波动和变化的,所以RTT往返时延和RTO不会是一个固定的值。在Linux系统中,为了得到RTO,需要对RTT进行采样,然后加权计算出平滑RTT值,同时采样波动范围。根据RFC的标准以及大量的实验不断调试,最终得出了超时重传的这么一个策略:
-
超时 间隔加倍:每当需要超时重传时,就将下一次的超时重传时间设置为原先的两倍。连续的两次超时,就说明网络环境差,不宜反复发送
超时重传是以时间作为重传的标准,需要等待超时才触发重传,所以它时间相对比较长,有没有更快的方式能够感知数据包丢失而触发重传呢?
快速重传
与超时重传不同,快速重传以数据作为标注,触发重传机制。
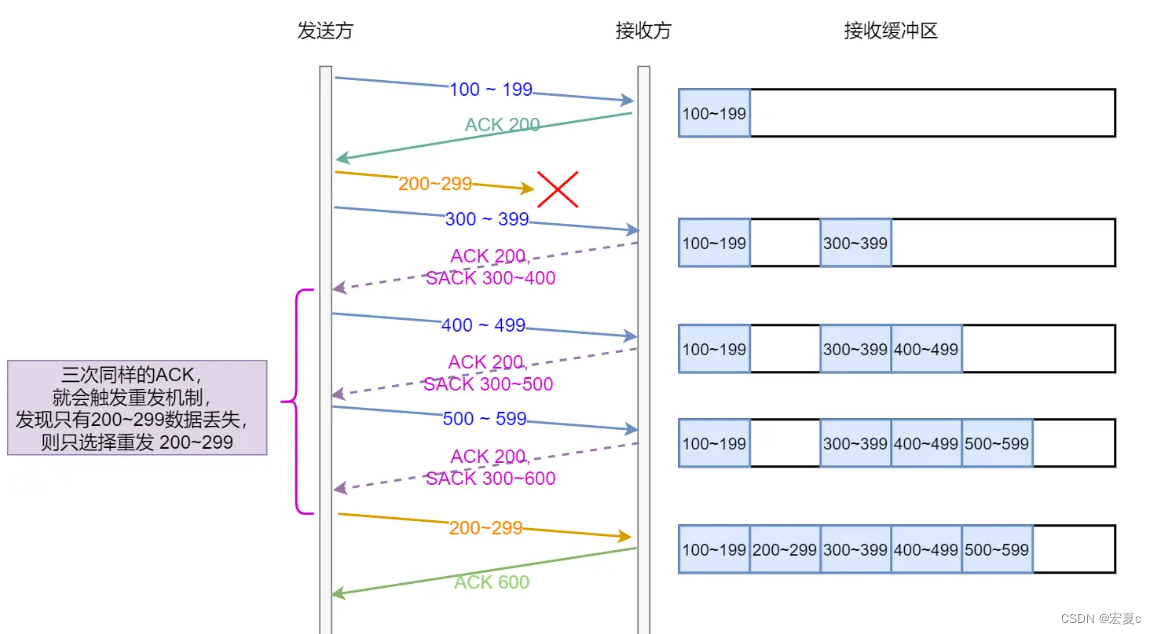
快速重传是指,当连续三次收到相同序号的ACK报文,就认为数据包丢失,需要重传,而不用等待超时再重传。
但快速重传面临着一个问题,是重传一个报文,还是包括该报文之后的所有报文?
-
如果重传一个报文,在连续多个报文丢失的情况下,一次重传无法重传所有丢失的报文,需要触发下一次重传
-
如果重传所有报文,可能导致重复发送已经被对方成功接收的数据,导致资源浪费
所以为了解决这个问题,有了之后的选择确认SACK
选择确认SACK
通过选择确认(Selective ACK),能够重传对方缺少的数据,而不重传已经成功被对方接收的数据。
要使用选择确认SACK,就需要在建立TCP连接时,在TCP报文头部的选项字段中加上”允许SACK“。
当接收方发生数据缺失时,就把确实报文的序号范围添加到TCP报文头部中,用来告知发送方哪些序号的报文需要重发。一个数据块有两个边界,指明一个边界就要用掉4个字节(因为边界指的就是序号,一个序号占4个字节),而TCP选项字段最长可达40字节。
D-SACK
Duplicate SACK,通过SACK字段,来告诉对方哪些数据被重复接收了。
导致数据的重复发送主要有两个场景,一个是没有收到ACK报文,另一个是网络延迟。
D-SACK的唯一作用就是能够让发送方知道,重传的原因,是因为自己发送的数据丢失了,还是对方的ACK报文丢失了,还是因为网络阻塞导致的数据延迟。