原文链接:https://arxiv.org/abs/2308.03755
1. 引言
完全稀疏检测器在基于激光雷达的3D目标检测中有较高的效率和有效性,特别是对于长距离场景而言。
但是,由于点云的稀疏性,完全稀疏检测器面临的一大困难是中心特征丢失(CFM),即因为点云往往分布在物体表面,物体的中心特征通常会缺失。FSD引入实例级表达,通过聚类获取实例,并提取实例级特征进行边界框预测,以避免使用物体中心特征。但由于实例级表达有较强的归纳偏好,其泛化性不足。例如,聚类时需要对各类预定义阈值,且难以找到最优值;在拥挤的场景中可能使得多个实例被识别为一个实体,导致漏检。
本文提出FSDv2,丢弃了FSD中的实例级表达,以追求更高的泛化性。本文引入虚拟体素以替代FSD中的实例,这些虚拟体素通过体素化投票中心得到。为减轻投票质量低带来的影响,虚拟体素被输入轻量级的稀疏虚拟体素混合器(VVM)增强特征,聚合属于同一物体不同虚拟体素的特征,得到覆盖整个实例的特征。VVM模拟了FSD中的实例级特征提取,但不显式地生成实例,以避免产生手工的归纳偏好。由于虚拟体素位于物体中心附近,可将虚拟体素作为“锚点”,从中预测边界框;这可减轻正负样本的不平衡性。
2. 相关工作
2.1 密集检测器
密集检测器(如VoxelNet和PointPillars)将点云转化为密集的3D体素或2D BEV,并使用密集的3D卷积或2D卷积处理。
2.2 半密集检测器
半密集检测器(如SECOND和CenterPoint)将点云转化为稀疏3D体素,使用稀疏3D卷积处理后得到2D密集BEV特征,输入检测头进行检测。其余方法使用Transformer结构增强稀疏主干。
2.3 完全稀疏检测器
完全稀疏检测器(如PointRCNN和VoteNet)基于点云进行检测,无需将点云转化为体素。FSD避免了点云处理中耗时的操作。
3. 准备知识
3.1 FSDv1的整体设计
FSDv1主要包含3部分:(1)点特征提取:使用稀疏体素特征提取器提取体素特征,然后使用基于MLP的颈部网络将体素特征转化为点特征。最后使用轻量级的逐点MLP进行逐点分类和中心投票。(2)聚类:将连接组件标签(CCL)应用在投票的中心,以将点聚类为实例。(3)实例特征提取和边界框预测:详见下文。
3.2 稀疏实例识别
FSDv1实例特征提取的核心是稀疏实例识别(SIR)。
首先,初始的实例点特征输入MLP,并通过最大池化得到实例特征,与实例各点的特征拼接,输入到另一MLP压缩通道维度。迭代执行上述步骤后,将最大池化的结果用于边界框预测。该方法类似一系列PointNet层。
4. 方法
4.1 总体结构
如下图所示,首先使用稀疏体素特征提取器作为主干,并使用MLP用于逐点分类和中心投票(与FSDv1相同)。FSDv2使用虚拟体素化替代聚类,并使用虚拟体素混合器混合不同虚拟体素的特征,用于预测边界框。
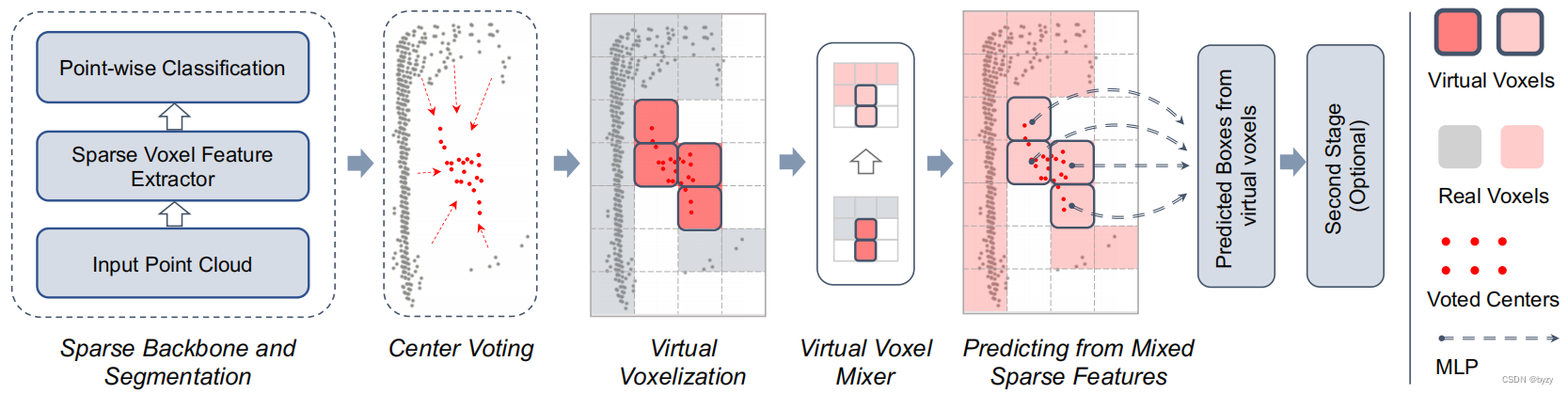
4.2 虚拟体素化
4.2.1 虚拟体素
使用投票中心创建虚拟体素。具体来说,对于每个前景点,预测偏移量得到投票中心。然后将各投票中心与原始点云的并集体素化。虚拟体素即至少包含一个投票中心的体素,而仅含真实点的体素则称为真实体素。
虽然投票中心可能有很多,但虚拟体素一般较少,因为投票中心往往彼此接近,且体素大小会设置得比通常更大(主干已经捕捉了细粒度特征,此处无需高分辨率)。
4.2.2 虚拟体素特征编码
引入虚拟体素编码器,类似FSDv1中的SIR结构,区别在于FSDv1提取实例特征而本文提取体素特征。首先为投票中心生成特征,此处将生成投票中心的点的(经过主干编码后的)特征作为投票中心特征,并将预测偏移量作为额外特征以与真实点区分。对于真实点则设置虚拟偏移量0。然后使用SIR结构聚合虚拟体素内真实点和虚拟点的特征。
4.3 虚拟体素混合器
虚拟体素混合器(VVM)用于混合虚拟体素特征、真实体素特征和主干输出的多尺度特征。
4.3.1 混合虚拟体素特征的动机
当中心投票效果不佳时,一个物体的中心附近可能会有多个虚拟体素,但这些体素没有交互。
4.3.2 混合虚拟体素与真实体素的动机
由于虚拟体素来自预测的前景点,当预测不准时会有前景信息损失。
4.3.3 混合多尺度特征
多尺度特征包含主干输出的多尺度真实体素特征和4.1节中得到的虚拟/真实体素特征。由于特征是稀疏而不规则的,多尺度特征融合不能像图像一样进行通道维度的拼接。
设(相对于虚拟体素特征的)步长 s s s下的稀疏特征为 F s ∈ R N s × C s F_s\in\mathbb{R}^{N_s\times C_s} Fs∈RNs×Cs,其中 N s N_s Ns为体素数, C s C_s Cs为通道数。体素的坐标为 I s ∈ R N s × 3 I_s\in\mathbb{R}^{N_s\times 3} Is∈RNs×3,转化到 s ~ \tilde{s} s~步长下的坐标为 I s s ~ I_s^{\tilde{s}} Iss~。虚拟体素化得到的特征为 F 1 F_1 F1。首先将 I s I_s Is转化为 I s 1 I_s^1 Is1:
I s 1 = I s × s + ⌊ s / 2 ⌋ I_s^1=I_s\times s+\lfloor{s/2}\rfloor Is1=Is×s+⌊s/2⌋
按下式得到聚合的稀疏特征和体素坐标:
F a g g = Concat ( Linear ( F 1 ) , Linear ( F 2 ) , ⋯ , Linear ( F L ) ) I a g g = Concat ( I 1 , I 2 1 , ⋯ , I L 1 ) F_{agg}=\text{Concat}(\text{Linear}(F_1),\text{Linear}(F_2),\cdots,\text{Linear}(F_L))\\ I_{agg}=\text{Concat}(I_1,I_2^1,\cdots,I_L^1) Fagg=Concat(Linear(F1),Linear(F2),⋯,Linear(FL))Iagg=Concat(I1,I21,⋯,IL1)
其中线性层用于将特征转换为相同的通道数。
注意 I a g g I_{agg} Iagg可能包含重复元素,因为不同尺寸的体素可能有相同的坐标。本文使用动态池化操作DP来去除重复坐标,将重复坐标对应的特征求取均值,得到单一特征。
4.3.4 VVM的模型结构
使用SparseUNet处理上述聚合结果。
4.4 讨论:聚类v.s.虚拟体素
当中心投票一致时,所有投票中心位于同一虚拟体素内,假设聚类是完美的,则本文的虚拟体素化方法与FSDv1的实例表达类似。
但当中心投票不一致时,会导致多个虚拟体素,每个体素编码了物体的部分形状。虚拟体素混合器使得虚拟体素之间可以交互,以编码完整几何信息。此时也与FSDv1的实例表达类似。
总的来说,本文的方法可以避免SIR中的手工参数设计,使得模型更简单通用。
4.5 虚拟体素分配
4.5.1 潜在的设计选择
传统的分配方法对于虚拟体素而言是次优的。因为:
- 虚拟体素不总是填充物体中心,特别是对于远处或大型物体。因此,基于中心的分配方法是不可行的。
- 基于锚框的方法需要逐类的超参数(如锚框大小),这和本文提高泛化性的设计思路冲突。
- 最近体素分配方法(将离中心最近的体素分配给对应的物体)会导致模糊性且阻碍优化。因为多个虚拟体素可能位于同一物体中心附近,但只有一个能作为匹配结果。
4.5.2 本文的方法:边界框内体素分配
本文将边界框内的所有虚拟体素作为正样本。
- 由于虚拟体素数远少于真实体素数,不会导致不同物体的正样本数不平衡。且能提高点很少的物体的召回率。
- 由于虚拟体素分布于物体中心附近,考虑所有虚拟体素不会导致回归目标有较大方差。
- 由于真实的边界框标注不会重叠,且点云的稀疏性保证边界框内不包含背景噪声,使得这种分配方法可靠。这解释了为什么基于图像的2D检测需要更加复杂的策略。
4.5.3 虚拟体素位置定义
直接的方法是将体素的几何中心作为虚拟体素的位置,但会导致不精确性和模糊性,因为体素的大小可能会超过一些小物体的大小。
本文考虑体素内点的分布,将体素的位置定义为所含点的加权中心:
x ˉ = ∑ i = 0 N − 1 I ( x i ) x i ∑ i = 0 N − 1 I ( x i ) \bar{x}=\frac{\sum_{i=0}^{N-1}I(x_i)x_i}{\sum_{i=0}^{N-1}I(x_i)} xˉ=∑i=0N−1I(xi)∑i=0N−1I(xi)xi
其中
I ( x ) = { 1 , 若 x ∈ F α , 若 x ∉ F I(x)=\left\{\begin{matrix}1,& 若x\in \mathbb{F}\\\alpha,&若x\notin \mathbb{F}\end{matrix}\right. I(x)={1,α,若x∈F若x∈/F
其中 F \mathbb{F} F为前景点(包含原始点和投票中心)集合, α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1]。
4.6 虚拟体素头
VVM输出的虚拟体素特征会输入一组MLP预测最终边界框。本文类似CenterPoint进行类别分组。分类分支使用Focal损失,回归分支使用L1损失,回归对象包含虚拟体素几何中心到物体边界框质心的偏移量、尺寸的对数以及朝向角的正余弦。
5. 实验
5.3 主要结果
在WOD数据集和Argoverse数据集上,本文的方法能达到SotA;在nuScenes数据集上,本文的方法能与SotA性能相当。
5.4 聚类v.s.虚拟体素
5.4.1 统计数据
- 对于大型物体,通常对应多个虚拟体素,且虚拟体素的数量大于聚类簇的数量,这表明VVM的必要性。
- 对小型物体,虚拟体素和簇的数量都很少,此时二者功能相当。
- 大型车辆的真实体素比簇和虚拟体素的数量多很多,这表明使用真实体素进行预测会导致不同大小物体的不平衡,而使用较少的虚拟体素预测能减轻这一问题。
5.4.2 拥挤场景的性能
若一个物体和与其最近的同类物体的距离小于2m,则定义该物体处于拥挤场景。性能分解表明,相比于FSDv1,FSDv2在拥挤场景物体上的性能提升比常规场景更大。
5.4.3 消除归纳偏好的有效性
实验表明,FSDv1随训练轮数的增加,性能逐渐饱和;而FSDv2的性能持续上升。
5.5 主要消融研究
5.5.1 基准方案设置
- 不生成投票中心,但保留投票损失作为额外监督。
- 仅对真实点使用体素化和体素编码,没有虚拟体素。
- 真实体素不通过混合器,直接输入检测头预测结果。
- 由于虚拟体素分配策略对小物体检测有重要影响,保留之。
实验表明,逐步增加本文提出的模块能在各数据集上一致提高性能。且混合器和虚拟体素对相对大型的物体有性能提升。
5.6 每个组件的性能分析
5.6.1 虚拟体素的有效性
为理解虚拟体素机制的作用,本文设计退化策略,即为预测的中心投票偏移量乘上一个缩放因数 s ∈ [ 0 , 1 ] s\in[0,1] s∈[0,1],当 s = 1 s=1 s=1时为FSDv2的正常情况; s = 0 s=0 s=0时虚拟体素完全退化。实验表明:
- 大型物体在大缩放因数下的性能较好。因为大型物体的中心包含空体素的可能性更高。
- 缩放因数对小型物体的影响很小。因为此时的偏移量很小,不同缩放因数下的虚拟体素位置接近。
- 对于barrier类别,大缩放因数能极大地提升性能。这是因为通常它们相邻放置,小缩放因数会导致从两个相邻实例的边界预测,导致模糊性。
5.6.2 虚拟体素编码器(VVE)的作用
将投票中心的特征置零后进行编码(这样,虚拟体素的特征仅来自真实点)。实验表明,上述改动会导致性能下降,且VVE对小物体的性能提升更明显。
5.6.3 虚拟体素混合器的输入
考虑三种组合:(1)仅输入虚拟体素;(2)输入虚拟体素和真实体素;(3)输入虚拟体素和多尺度体素。实验表明引入真实体素能极大提高性能,多尺度体素能在多数类别上进一步提高性能。
5.6.4 虚拟体素分配的作用
实验表明:
- 略微增大小物体的GT框能帮助分配更多标签,但过分增大会因为噪声或边界框重叠而降低性能。
- 使用虚拟体素质心比几何中心对小物体更有利,进一步使用加权质心能进一步提高性能。
使用最近虚拟体素分配方法会导致性能严重下降,但增加分配的虚拟体素数量能减小性能下降。考虑最近的10个虚拟体素时性能达到饱和。
5.6.5 虚拟体素大小
实验表明,性能对虚拟体素的大小不敏感,且更大的体素能有略高的性能,这是因为此时大型物体的虚拟体素更少,不同大小物体的样本不平衡性被减轻。
5.7 运行时间评估
实验表明,FSDv2比FSDv1有更高的性能和效率。其中FSDv2的虚拟体素化与体素编码比FSDv1的聚类有更快的速度,但混合器考虑了真实体素,比FSDv1的SIR更慢。