传统批次处理方法
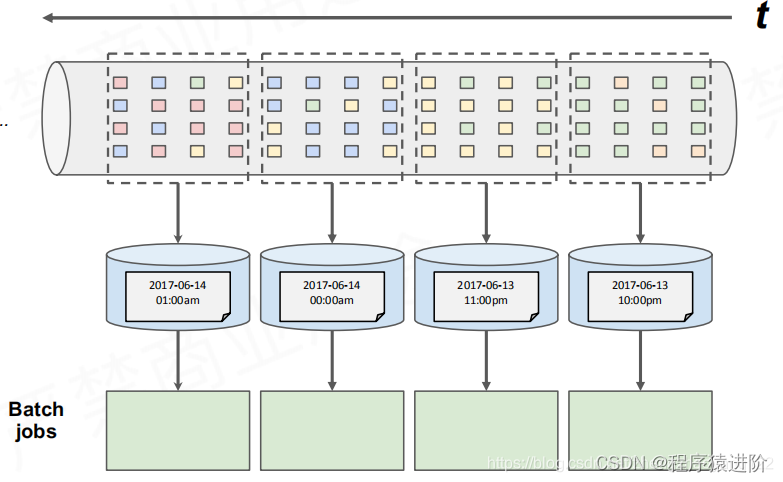
【1】持续收取数据(kafka等),以window时间作为划分,划分一个一个的批次档案(按照时间或者大小等);
【2】周期性执行批次运算(Spark/Stom等);
传统批次处理方法存在的问题:
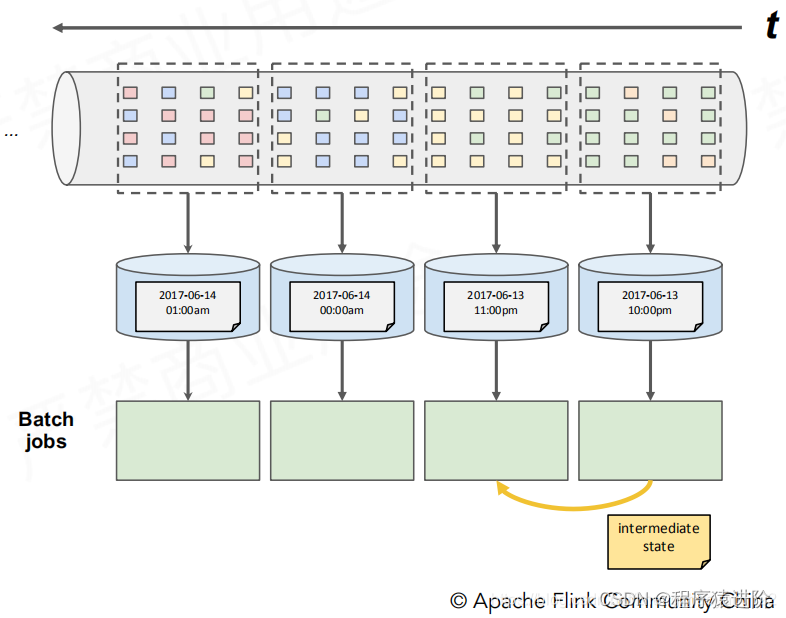
【1】假设计算每小时出现特定事件的转换次数(例如:1、2…),但某个事件正好处于1到2之间就尴尬了。需要将1点处理一半的结果带到2点这个批次中进行运算。而这个划分跟我们事件发生的时间也是有误差的。
【2】在分布式多线程的情况下,如果接收到事件的顺序颠倒了,又该如何处理?
理想方法
累积状态:表示过去历史接收过的所有事件。可以是计数或者机器模型等等。
 我们要处理一个持续维护的状态时,最适合的方式就是状态流处理(累积状态和维护状态+时间,是不是该收的结果都收到了)
我们要处理一个持续维护的状态时,最适合的方式就是状态流处理(累积状态和维护状态+时间,是不是该收的结果都收到了)
【1】有状态流处理作为一种新的持续过程范式,处理连续的数据;
【2】产生准确的结果;
【3】实时可用的结果仅为模型的自然结果;
流式处理
流处理系统或者流处理引擎都是数据驱动的,而不是定期或者人为的去触发。数据也没有物理边界。
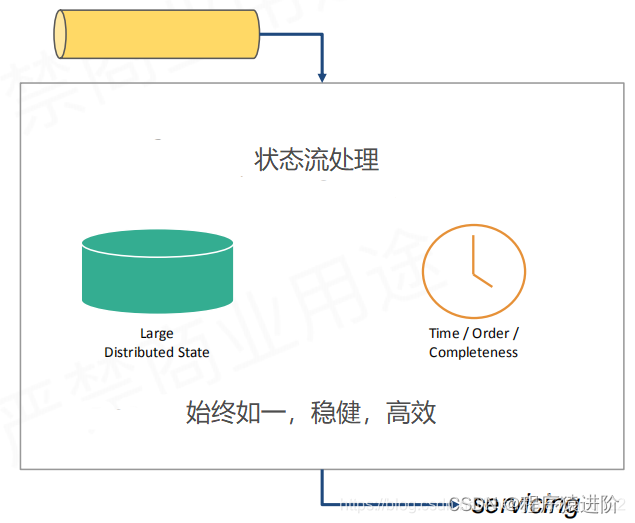
一般系统都会把操作符放上去,等待数据的到来进行计算。如下是一个逻辑模型(DAG)
分散式流式处理
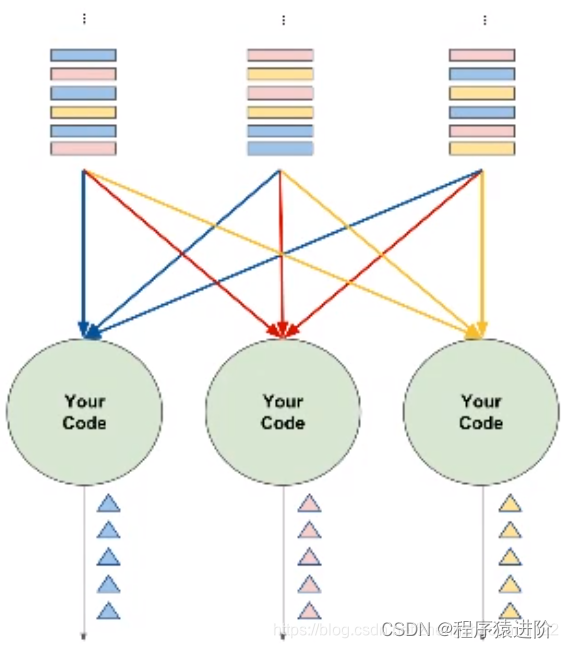
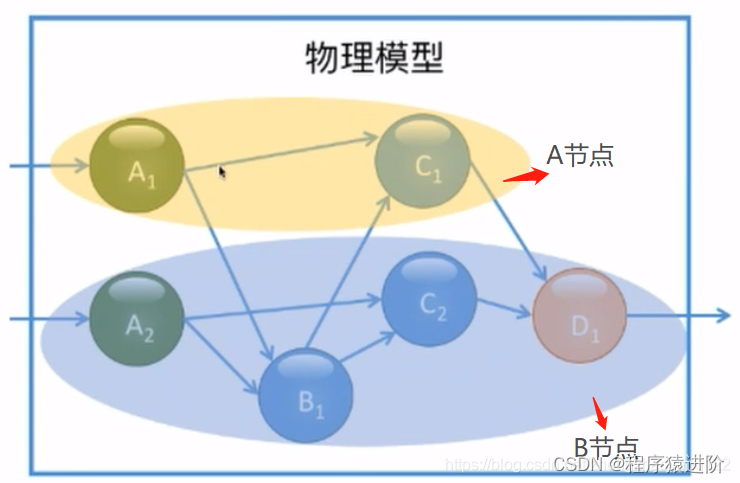
【1】从数据中选择一个属性作为key对输入流进行分区;
【2】使用多个实例,每个实例负责部分key的存储,根据Hash值,相同的key一定落在相同的分区进行处理;
【3】根据流式数据处理的DAG模型,有对应如下的分布式流处理的实例模型。例如A算子拥有两个实例,上游的实例节点可能同时与下游的一个或多个节点进行传输。这些实例根据系统或者人为的因素分配在不同的节点之上。节点与节点之间数据传输也会涉及网络之间的占用。本地的传输就不需要走网络
有状态分散式流式处理
定义一个变量X,输出结果依据这个X,这个X就是一个状态。有状态分散的流失处理引擎,当状态可能会累计非常大。当key比较多的时候就会超出单台节点的负荷量。这个x就应该有状态后台使用memory去维护它。【数据倾斜】
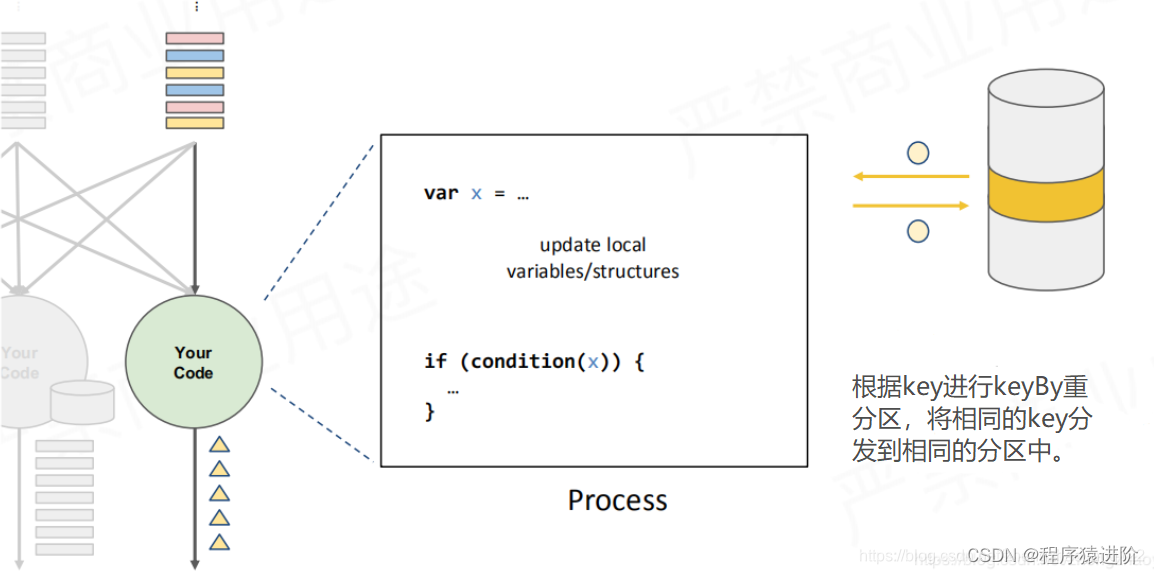
状态容错(State Fault Tolerance)
状态挂了,如何确保状态拥有精确一次(exactly-onceguarantee)的容错保证?就是通过定期的快照+事件日志位置。我们先假设一个简单的场景,如下,一个队列在不断的传输数据。单一的process在处理数据。这个process没处理一个数据都会累计一个状态。如何为这个process做一个容错。做法就是没处理完一笔,更改完状态之后,就做一次快照(包含它处理的数据在队列中的位置和它处理到的位置以及当时的状态进行对比)
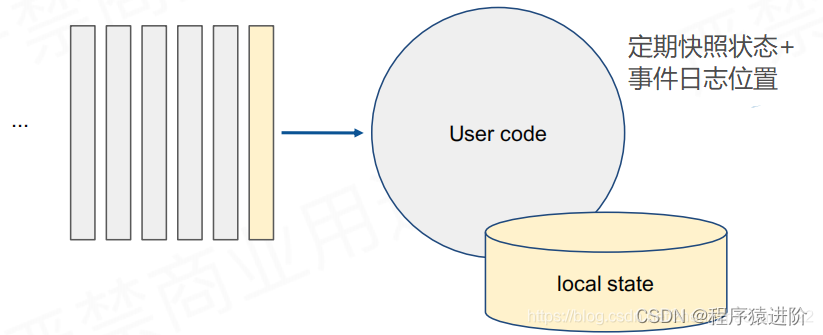
举个例子:如下我处理到第二笔数据,我就会记录下第二个位置在进入process之前的信息(位置X+状态@X)
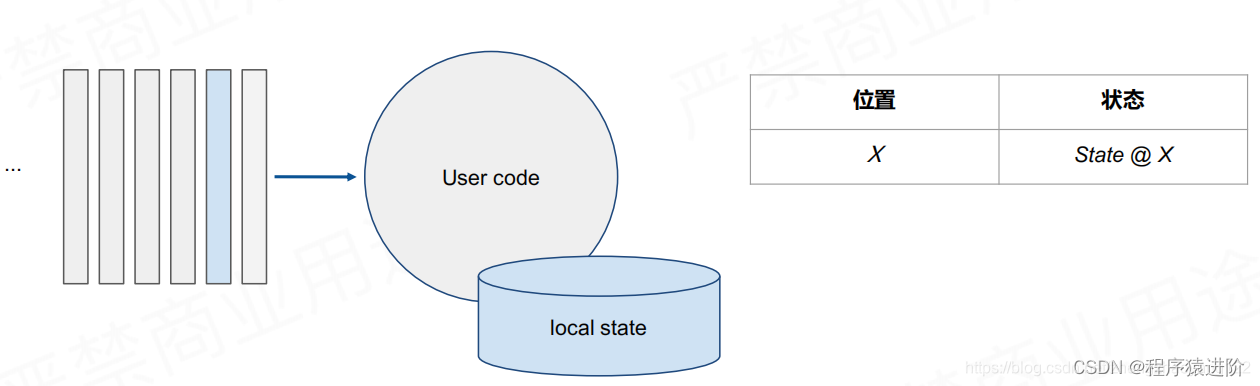
当进入process处理的时候出现了fail时,Flink就会根据上一次的位置+状态进行恢复。
如何在分散式场景下替多个拥有本地状态的运算子产生一个全域一致的快照(global consistent snapshot)?
方式一:更改该任务流过的所有运算子的状态。比较笨,有一个副作用,就是我处理完这笔数据,它应该就到了一个process,我本应该做其他数据的处理了,可是为了全局一致性快照就会停止前面和当前的process的运算来保证全局一致性。
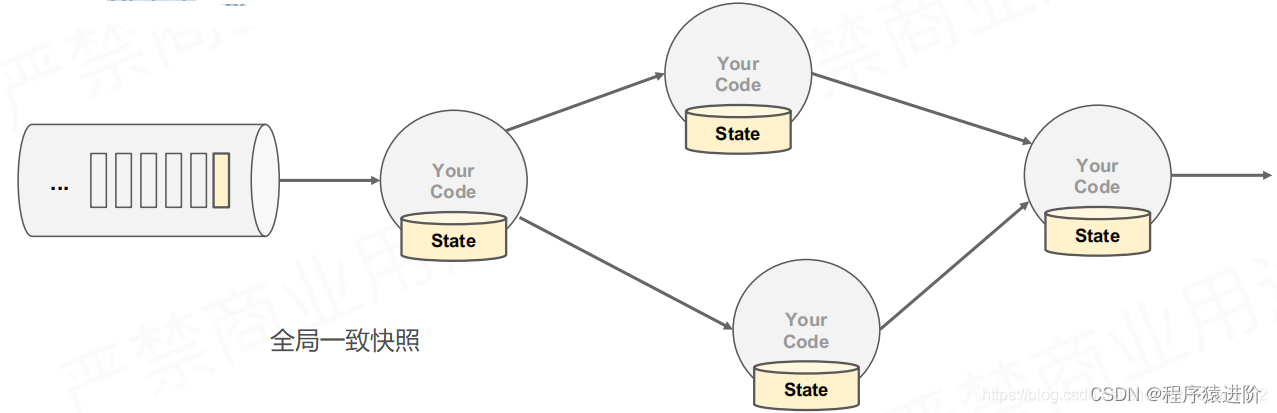
分散式状态容错
通过checkpoint实现分散式状态容错
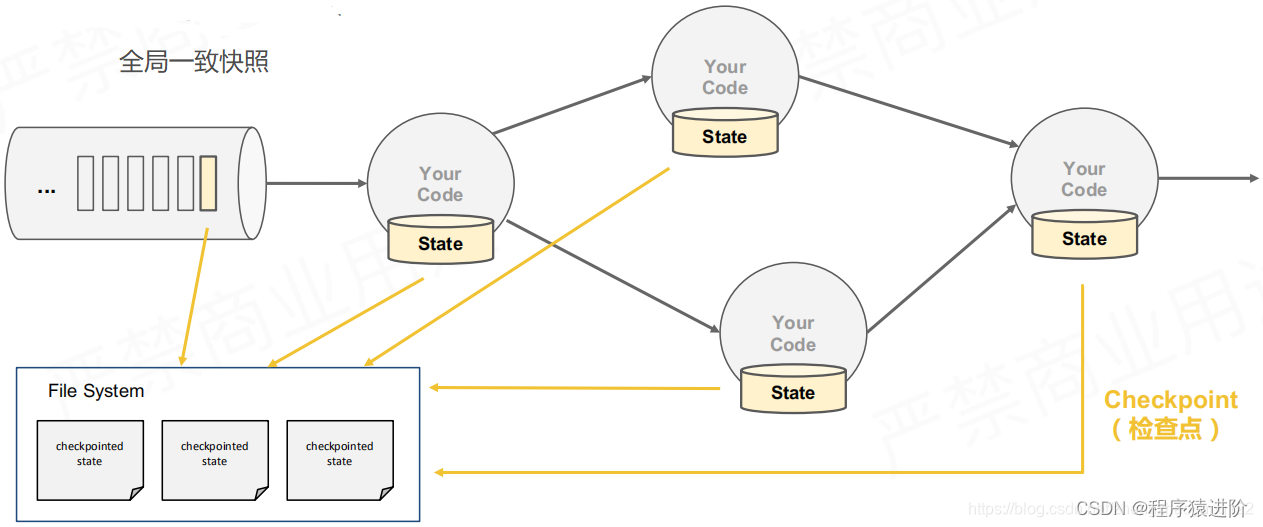
每一个运算子它本地都有一个维护一个状态,当要产生一个检查点(checkpoit)的时候,都会将这个检查点存储在一个更小的分布式文件系统DFS中。当出现某个算子fail之后,就会从所有的checkpoint中获取所有算子的上一个状态进行恢复。把消息队列的位置也进行恢复。也就是多线程工作,每一个任务在DFS中就可以看作一个线程,它们数据存储的key就是这个任务,每一个算子的处理状态都会按照处理顺序添加进去。
分布式快照(Distributed Snapshots)
更重要是时如何在不中断运算的前提下生成快照?其实就是给每一个任务标记一个checkpoint n不同的任务这个n是不同的,相同的任务在不同的算子里面它是相同的。具体我们把这个分解后看看。
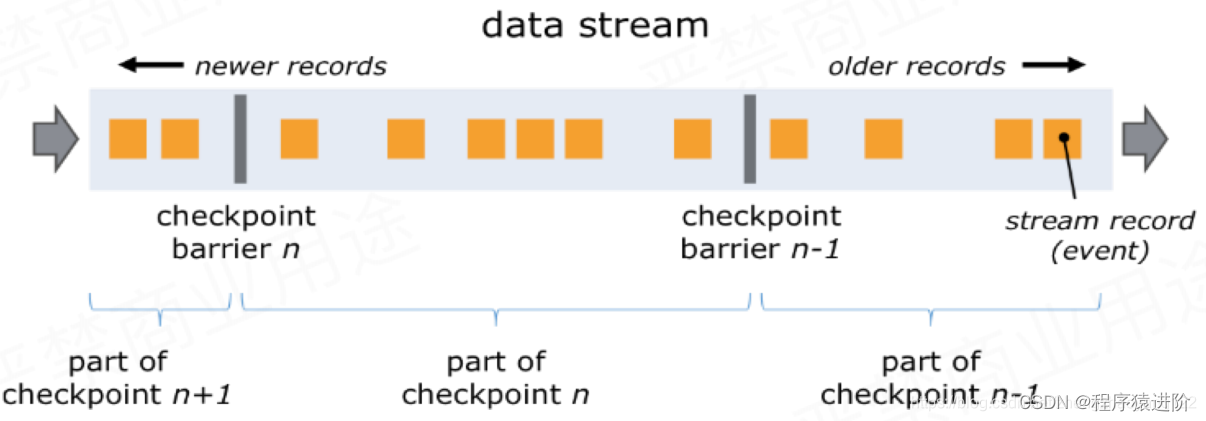
【1】如下图,当我们从数据源获取数据的时候,其实我们已经开始有状态了,这个时候我们可以把任务处理的整个过程抽象成如下图中的一张表。
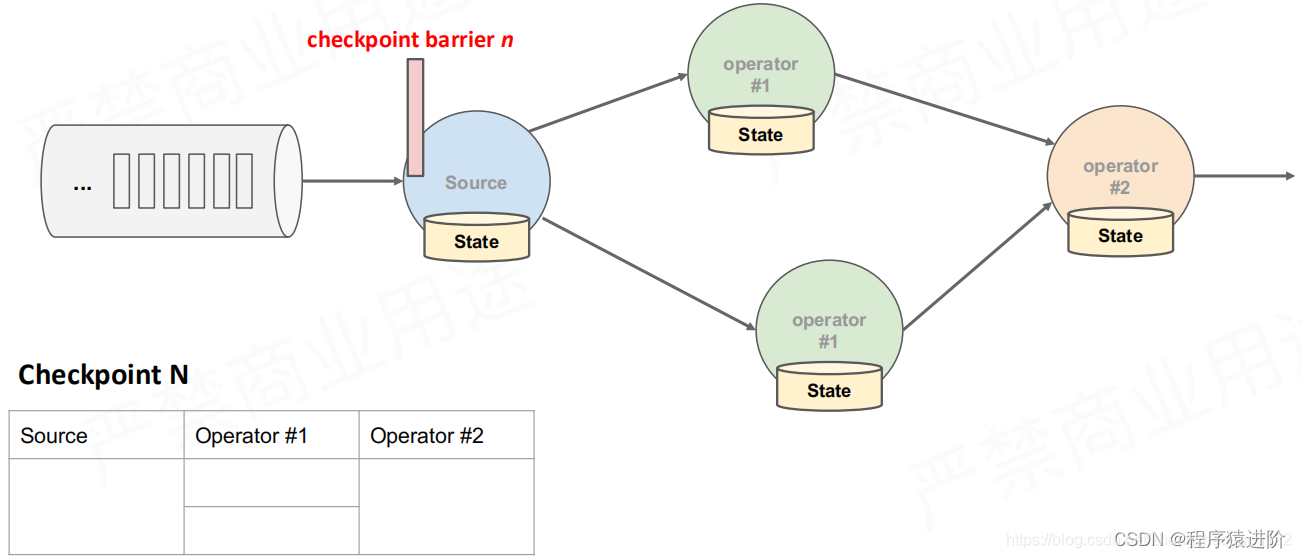
【2】首先是数据源的状态,就是数据在操作前的一个位置offset进行快照存储,如下图所示:
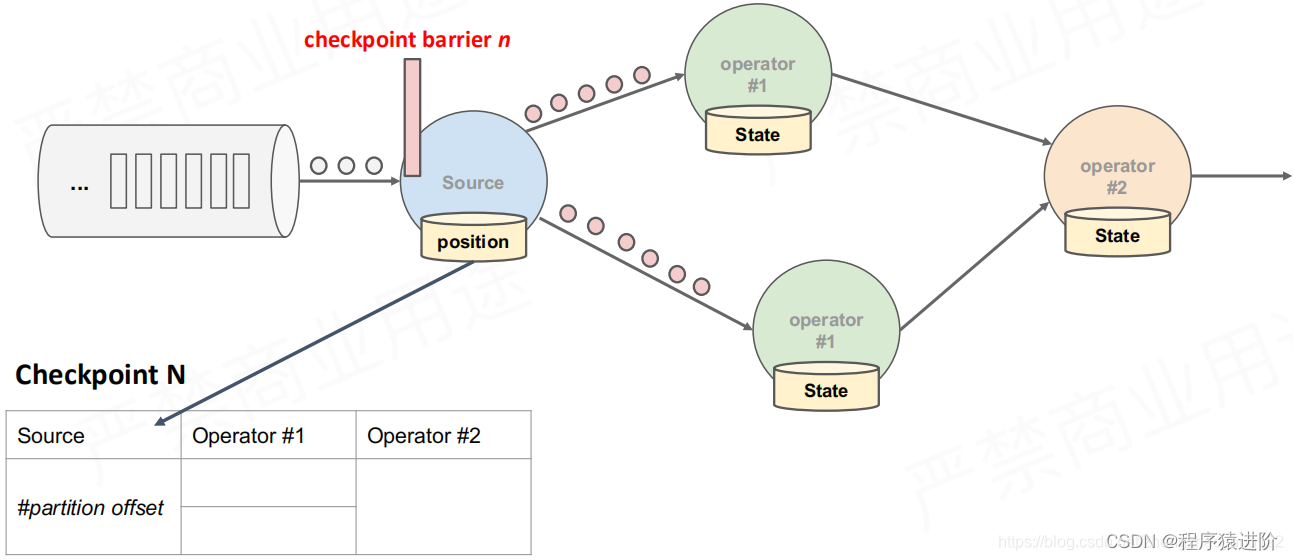
【3】当获取到数据源之后,就进入算子中进行处理,此时就会对数据进入之前的状态进行checkpoint。记录一个savepoint。
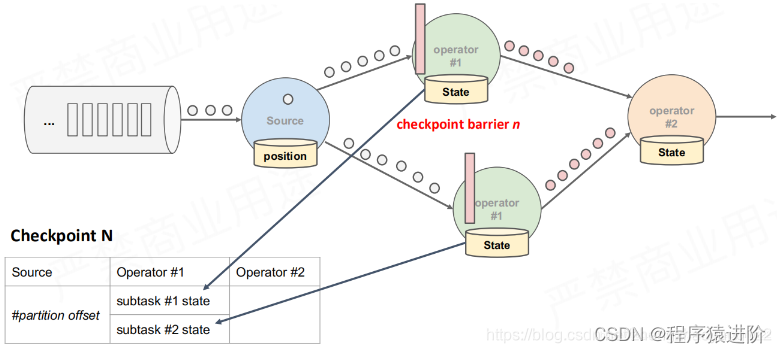
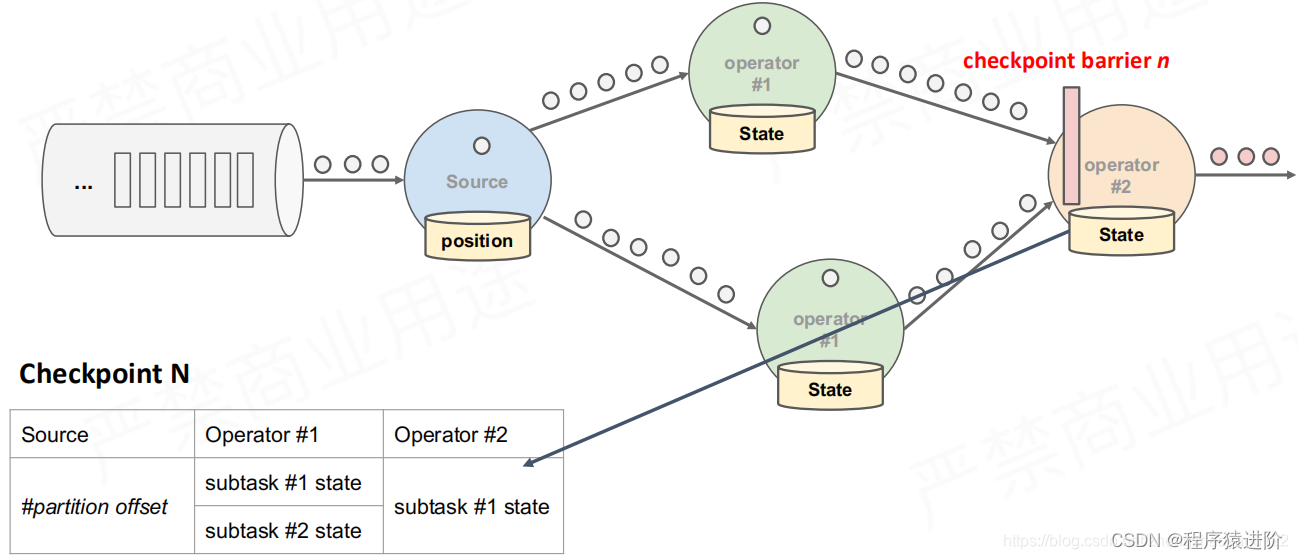
【4】在最后一次操作前(输出)也会记录checkpoint。在这个过程中,其实前面的算子也在产生不同的 checkpoint n-1 等。如果要进行恢复使用的话,必须是一个complete完整的Checkpoint。只有部分数据的Checkpoint是不能使用的。
状态维护(State Management)
本地维护的这个状态可能非常非常大。后端的管理系统一般使用内存维护这些状态。
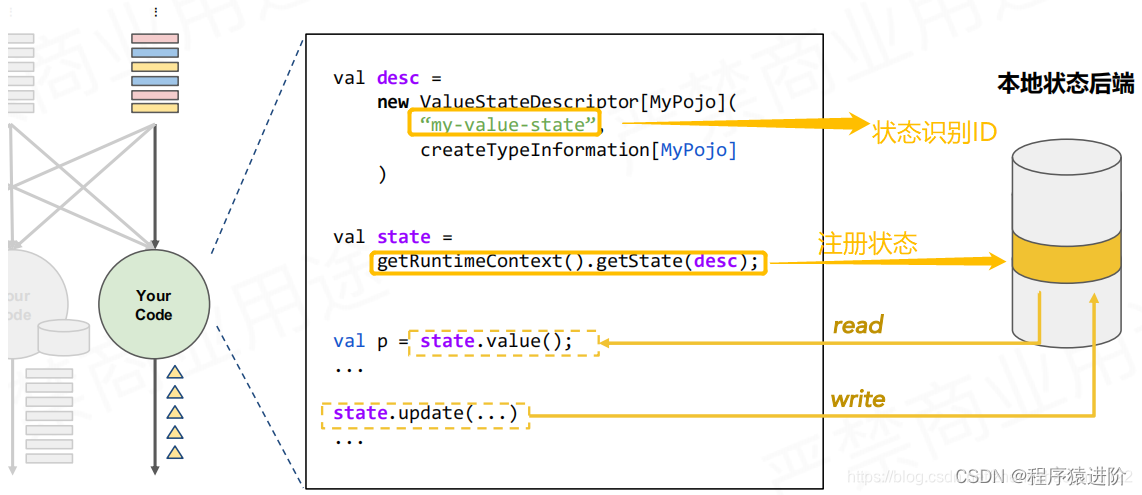
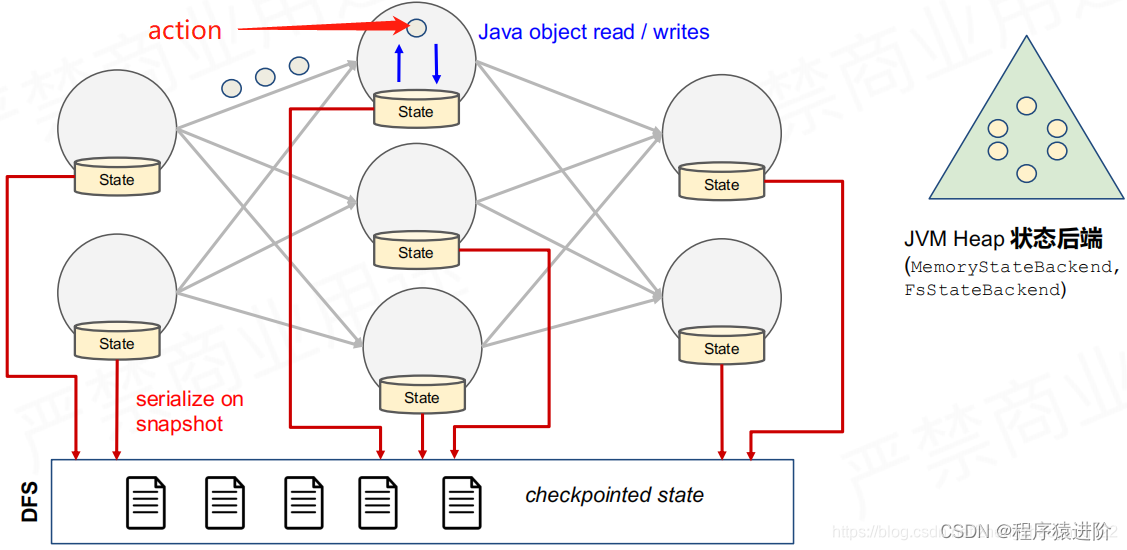
Flink提供了两种状态后端:JVM Heap状态后端,适合比较小的状态,量不要很大。当运算子action要读取状态的时候,都是一个Java对象的read或者write。当要产生一个检查点的时候,需要将每个运算子的本地状态数据通过序列化存储在DFS中,
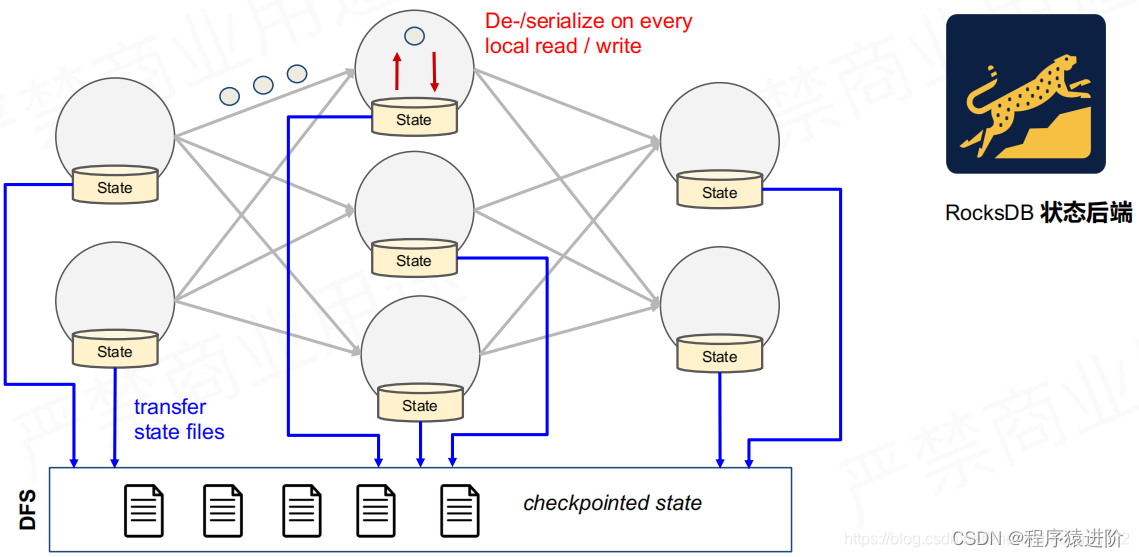
当状态非常大的时候就不能使用JVM Heap的时候,就需要用到RocksDB。当算子需要读取的时候本地state的时候需要进行序列化操作从而节省内存,同时,当需要进行checkpoint到DFS时,也少了序列化的步骤。它也会给本地存储一份,当fail的时候就可以很快恢复,提高效率。
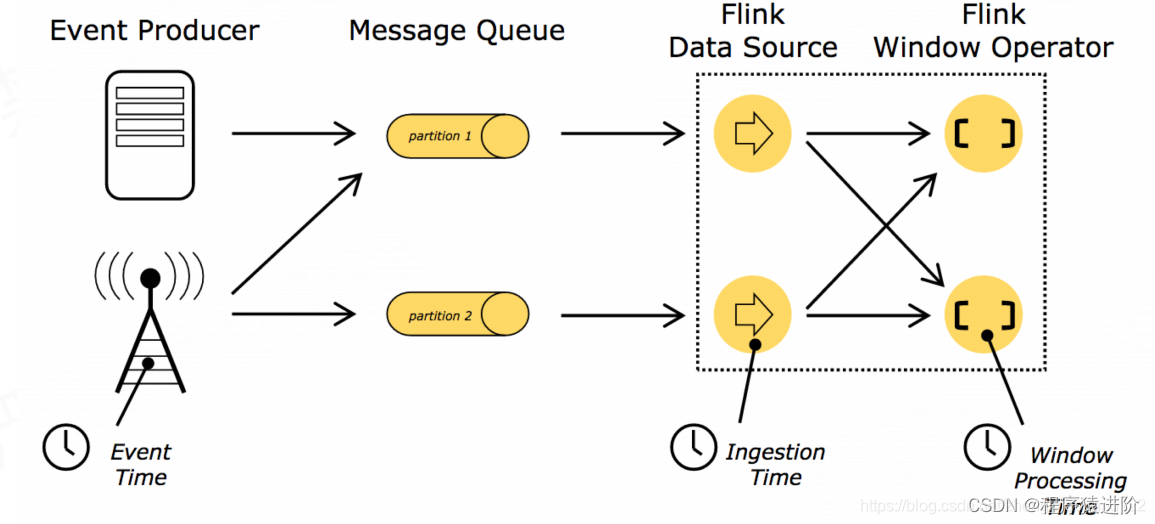
Event-time 处理
EventTime是事件产生的时间。
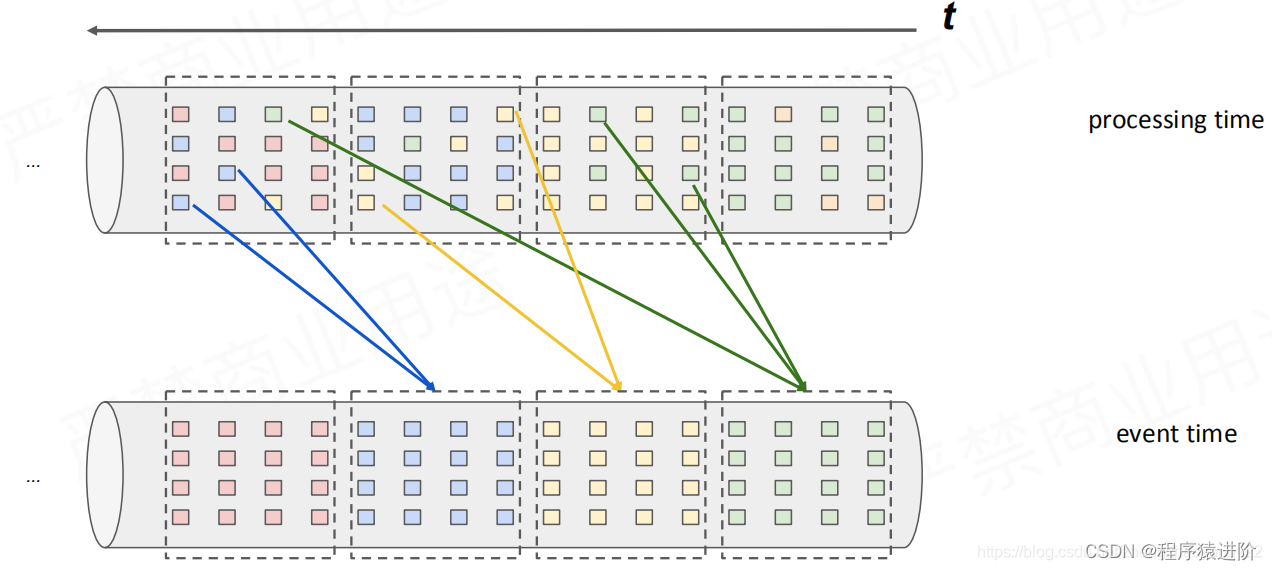
下面是一张,程序处理时间与事件发生时间的时间差的一张对比图来更好的理解EventTime。
Event-Time 处理
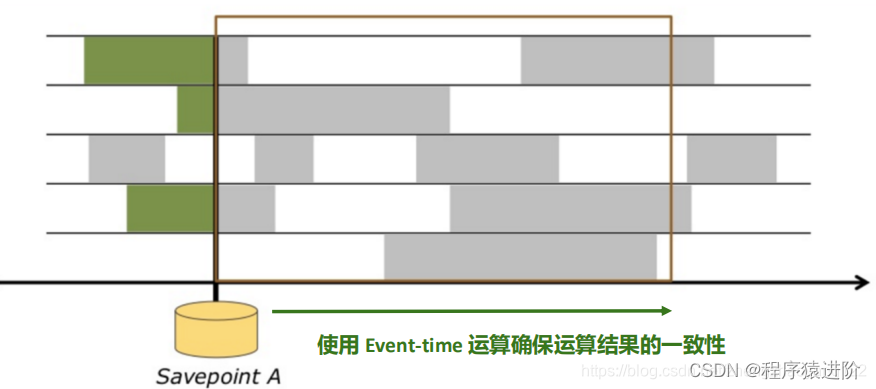
也就是说我们要统计的3-4点之间的数据,程序4点结束这个执行不是根据window时间,而是根据event-Time。

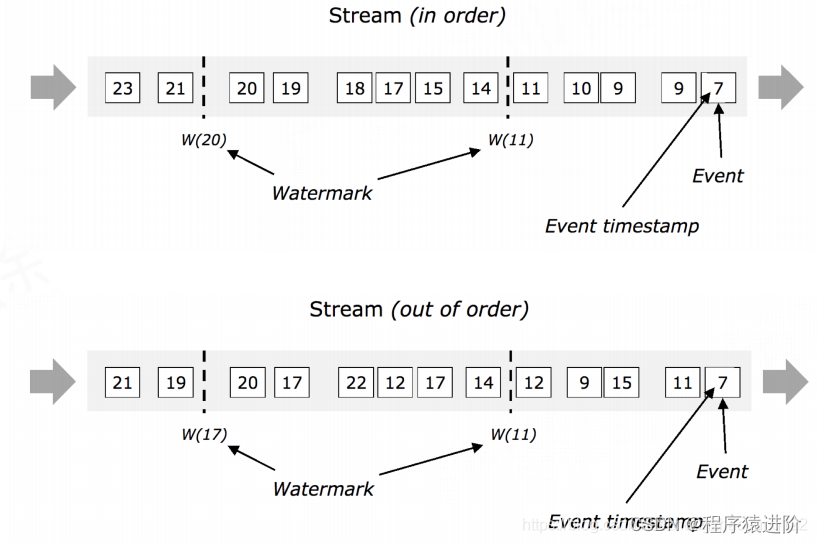
Watermarks
Flink是watermarks实现Event-Time功能的。在Flink里面也属于一个特殊事件,精髓是当某个运算子收到一个带有时间戳t的watermark后就不会再收到任何小于该时间戳的事件了。也就是当window需要统计4点的数据时,例如我们每5分钟发一次watermark,那么当window收到4.05的watermark的时候才会去统计4点之前的数据(下一次)。如果4.05收到了4点之前的数据的话,Flink1.5会把这个事件输出到旁路输出(side output),你可以获取出来,进行处理。目前有一个问题就是:如果某个Stream Partition 没有输入了,也就没有Watermarks。那么window就没办法进行处理了。当多个数据流的watermarks不相同的时候,Flink会取最小的watermarks进行运算。可以在接收到资源的时候通过代码设置watermarks。
OutputTag<String> outputTag = new OutputTag<String>("side-output") {};
状态保存与迁移(Savenpoints and Job Migration)
可以想成:一个手动产生的检查点(CheckPoint):保存点记录某一个流失应用中的所有运算中的状态。当触发SavePoint之后,Flink提供了两种选择停止消费或者继续运算,根据场景定义。
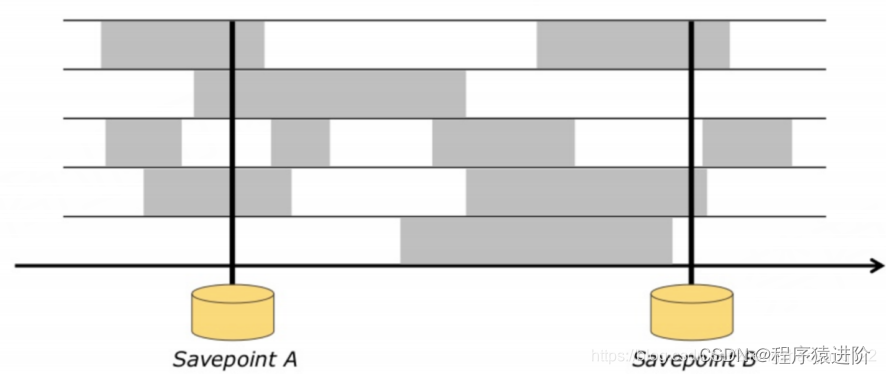
执行停止之前,产生一个保存点。就可以解决上面提到的3个问题。
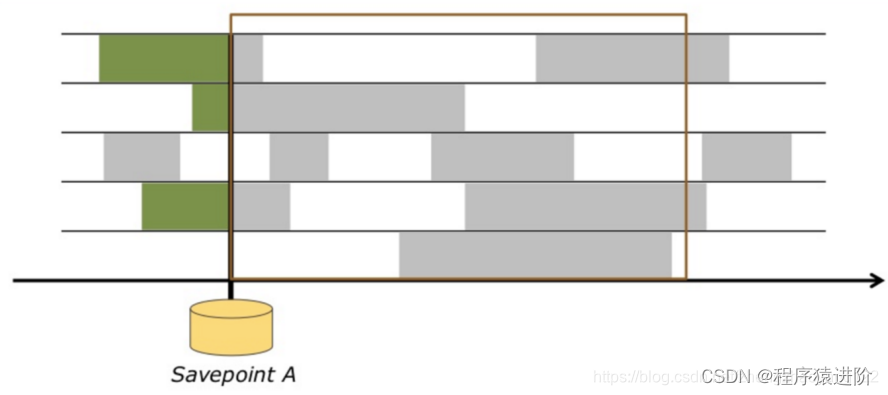
从保存点恢复新的执行,这个时候,例如我们重启花了30分钟,这段事件kafka还在不断的接收新的数据。恢复之后,Flink就需要从当时记录的kafka位置赶上最新的位置。这个时候利用Event-Time处理新的数据都是事件发生时的数据,这个时候再跟程序执行的时间比较就更能体现Event-time的价值。