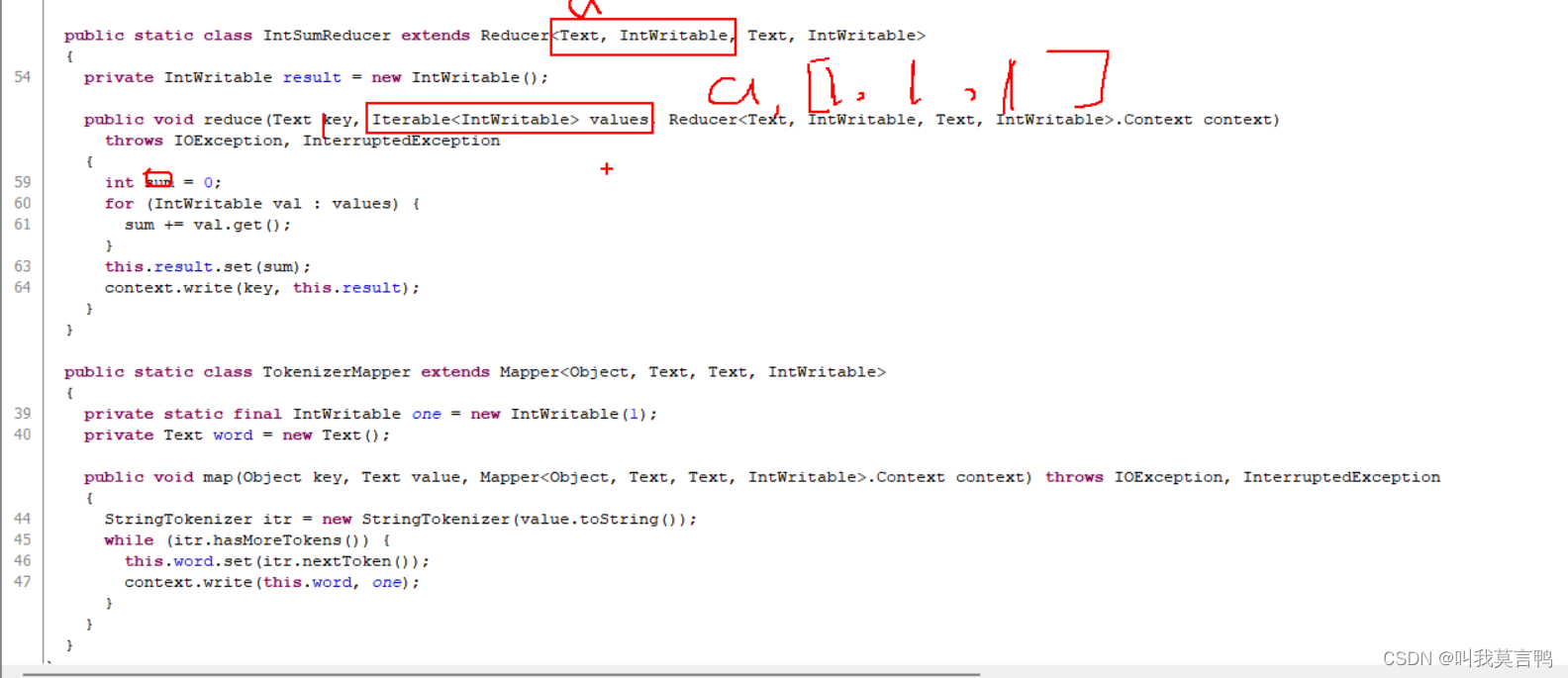
客户端向NN请求上传文件
NN回应可以上传
请求上传块,返回DN
所以后面就比较慢
找最近的服务器进行
64K发到1节点,1节点立刻发给2节点,同时1节点自动开始落盘,这里,3个节点是同时落盘的. 因为缓存是在内存中,而持久化是将数据存到磁盘上.
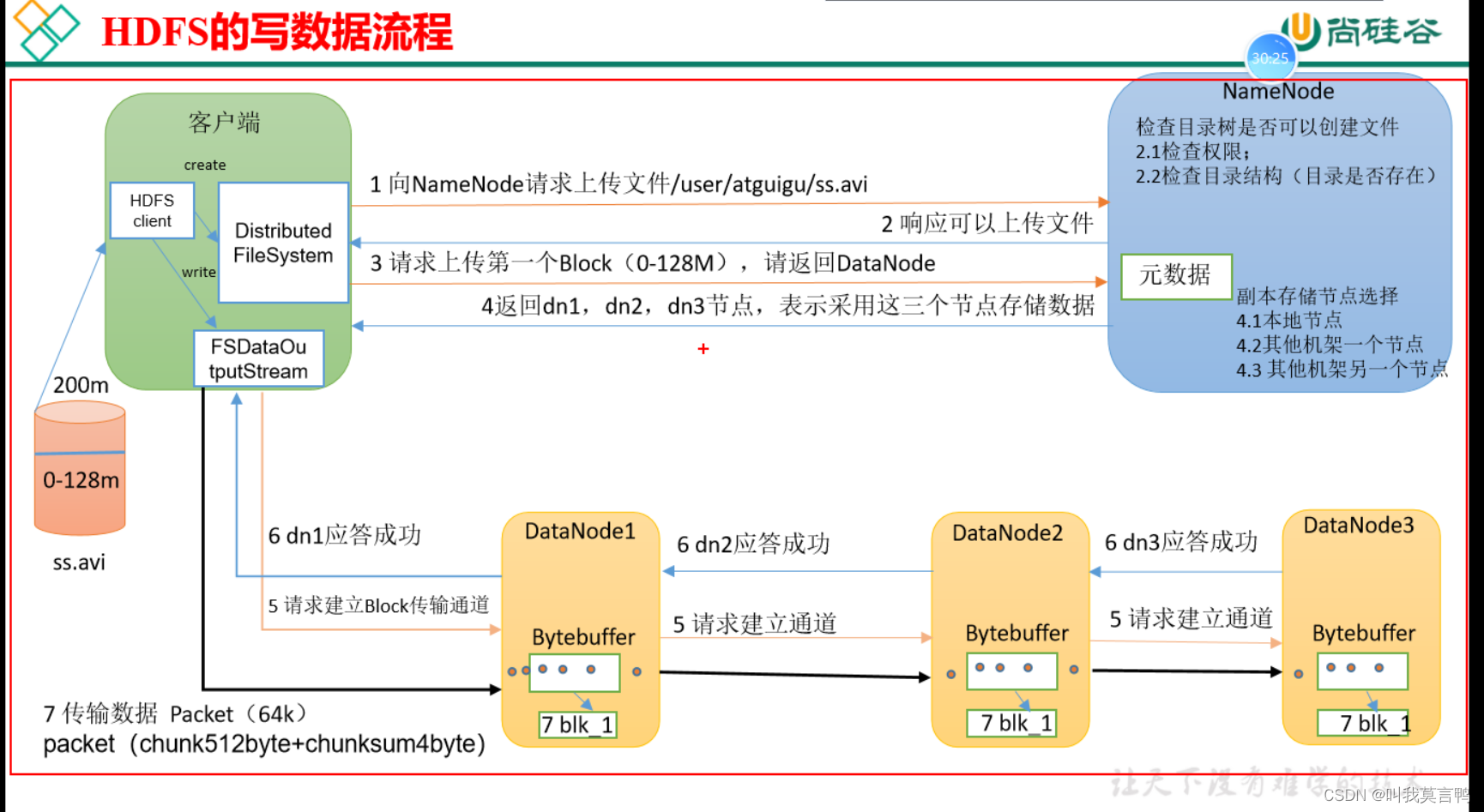
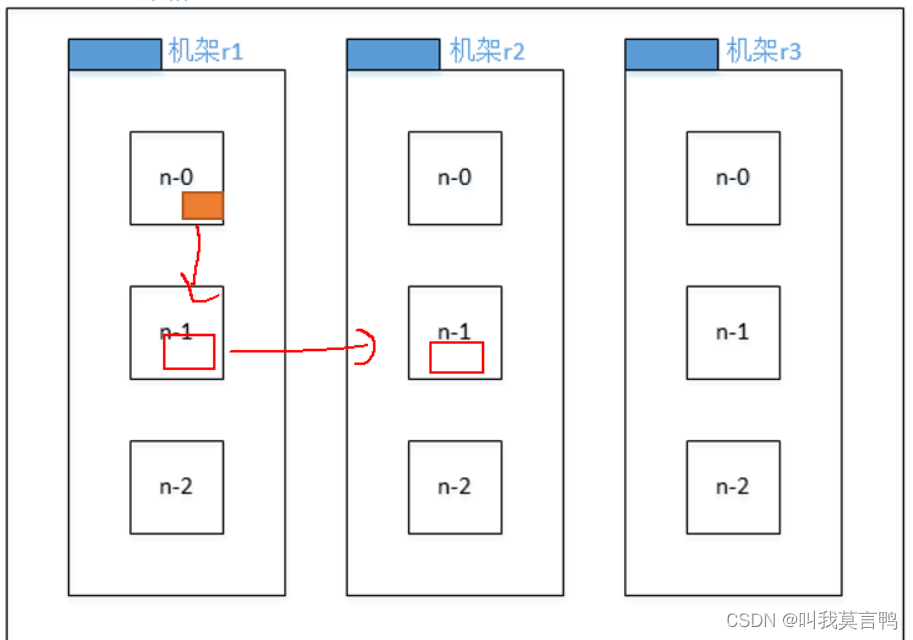
副本节点选择:
1.安全:放不同机架
2.速率:放同一机架
结合后,机架1放1台 机架2放2台
确保当只需要2台时,有一台在机架2上
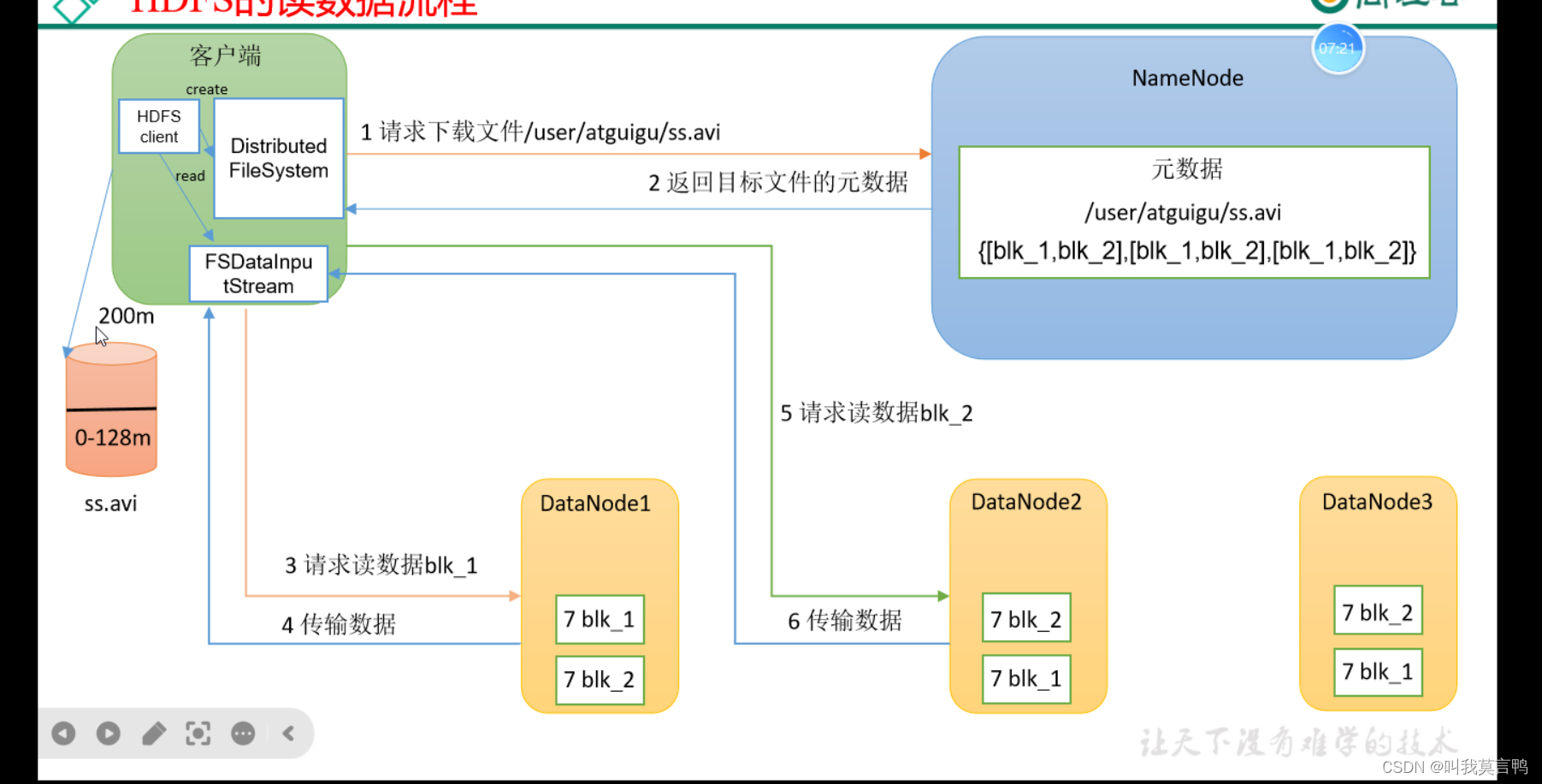
客户端是并行读取,但是落盘是顺序落盘的(注意这里是没有隐藏序列号的)
NN 内存和磁盘都有,
一个新文件来保存元数据的变更记录
放入内存中
fsimage元数据
edit 记录
不明白!!!
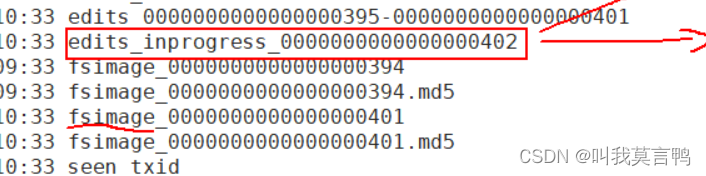
100W条数据,或者1小时到达,2NN要合并了,Edits会不会停止?
方式: 产生一个最新的空的日志,让2NN把旧的拿走
流程:
1.NN启动 : 加载元数据和日志到内存
2.客户端请求操作
3. NN更新操作日志
注意元数据是不修改的 修改的只是日志
但是,元数据和修改日志,是一对一的
4. NN进行操作
5. 到达条件 滚动
6. 2NN拿走回滚文件, 更新元数据,加载到内存,
7. 2NN将新的元数据发送给NN,NN更新元数据

数据块 一个数据块带一个meta文件,meta文件就是数据块的描述信息(数据长度 校验和 时间戳)
注意 当NN启动并且加载到内存后,还不能开,必须先将DN向NN注册,同时上报,以后每6小时都上报所有块信息.
这些操作都是在内存中完成的
这时候内存中: fsi edits 元数据目录 这才是整体NN
NN会监控DN,每三秒连接一次.
三秒未连接会触发超时处理,10分钟+30秒未连接,节点G
MapReduce(已经被淘汰了)
优点:
- 易编程
- 高扩展性:直接 加机器
- 高容错:机器挂了,可以转移到另一个节点 默认可以重试4次
- 适合PB级以上数据的离线处理: 不方便处理流式数据
分与合
分:按照128M分
合: 按照需求分区
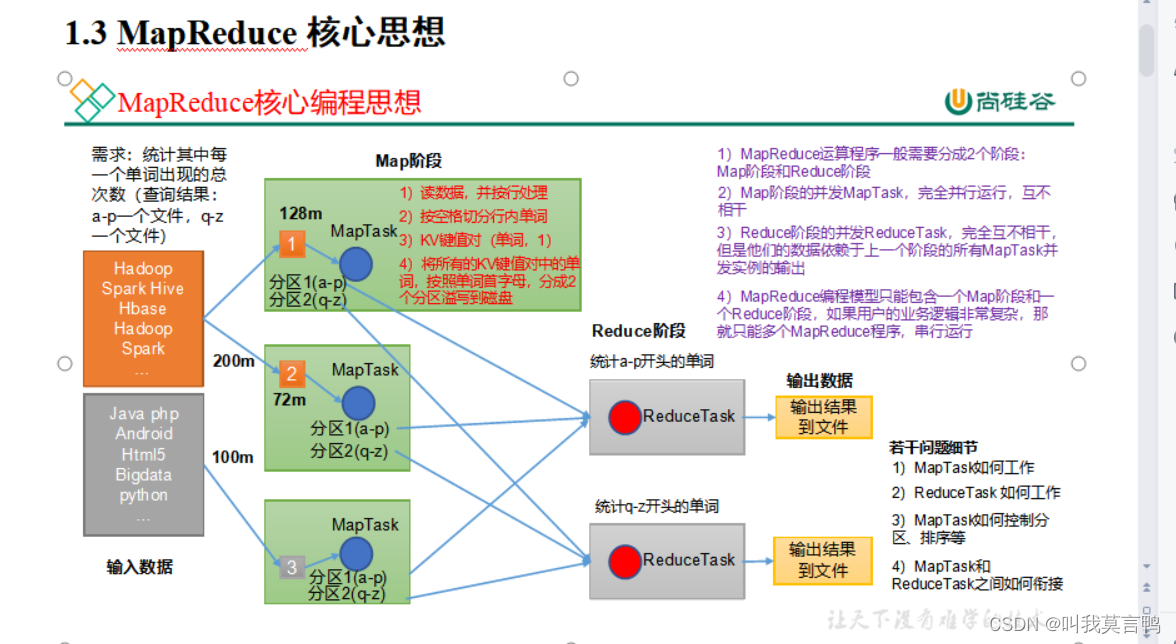
ReduceTask数量取决于分区数量

都是KV的格式