引言:
北京时间:2023/7/16/14:32,摆烂至今,在耍这方面,谁能比我行,哈哈哈,乐观!欠了一堆课要补,等我们把线程相关知识学完,对于系统编程方面我们搞定的就差不多了,以前学习的有关系统知识已经足够我们用了,更广泛的拓展需要自己去摸索,当然前提是以前有关的知识进行了一定的复习,这个复习过程具体我也不知道什么时候进行,走一步看一步吧!当然学了这么久,也不是白学,对于体系结构,底层原理等知识,我们肯定是有较强的理解,复习只是为了加强理解和巩固印证,然后就是细节方面知识,总的来说,对于一个模块,大方向存在,但是具体的细节较为模糊,然后剩下比较重要的就是代码实操方面,当然,这块具体也要等复习的时候来,目前对于我来说,更重要的还是算法题,当然说多了,也就是代码能力。可惜,自从回到家之后,都没有把作息调整的很好,追剧、看小说、下棋、刷视屏样样精通,学习的时间几乎没有,把控不住,耍的时候有多快乐,现在就有多痛苦,摆烂了一个多星期之后,把能追的剧、能看的小说、下棋该升的段位,咱们都搞定了,并全部卸载,现在唯一能造成我们摆烂的就只有刷视屏,要不是微信不能卸载,不然,我们近乎无敌之身,我们现在唯一需要做的就是把作息给调整过来,只要早睡一到两天,我相信,我们就能按照预期前进,废话不多说,今天是暑假最为关键的一个转折点,记录字数较多,下篇博客引言,让我们看看我们到底能不能实现吧!今天就让我们承接上篇博客有关进程控制相关知识,来看一看进程并发等知识吧!

深入线程控制
在上篇博客中,我们重点学习了有关线程控制方面的知识,当然也就是线程创建,线程终止,线程等待,并且将线程终止的4种方法详细介绍,当然介绍线程终止的本质,是为了主线程可以更好的完成线程等待,从而实现线程之间有序的协作和交互,提高程序的执行效率和并发性能。 所以对于线程终止来说,它只是为了配合线程等待使用而已,并且在上篇博客中,我们介绍相应接口的同时,我们知道线程等待过程,它不是傻傻的干等,它可以获取对应线程的退出结果(pthread_join()接口详解),回顾了线程等待和线程终止之后,此时我们来深入探讨一下线程创建相关问题,在上篇博客中,对于线程创建我们只是详细的介绍了一下对应接口的参数,并没有对其的使用进行详细介绍,所以接下来我们对其使用进行进一步的介绍,如下代码所示:
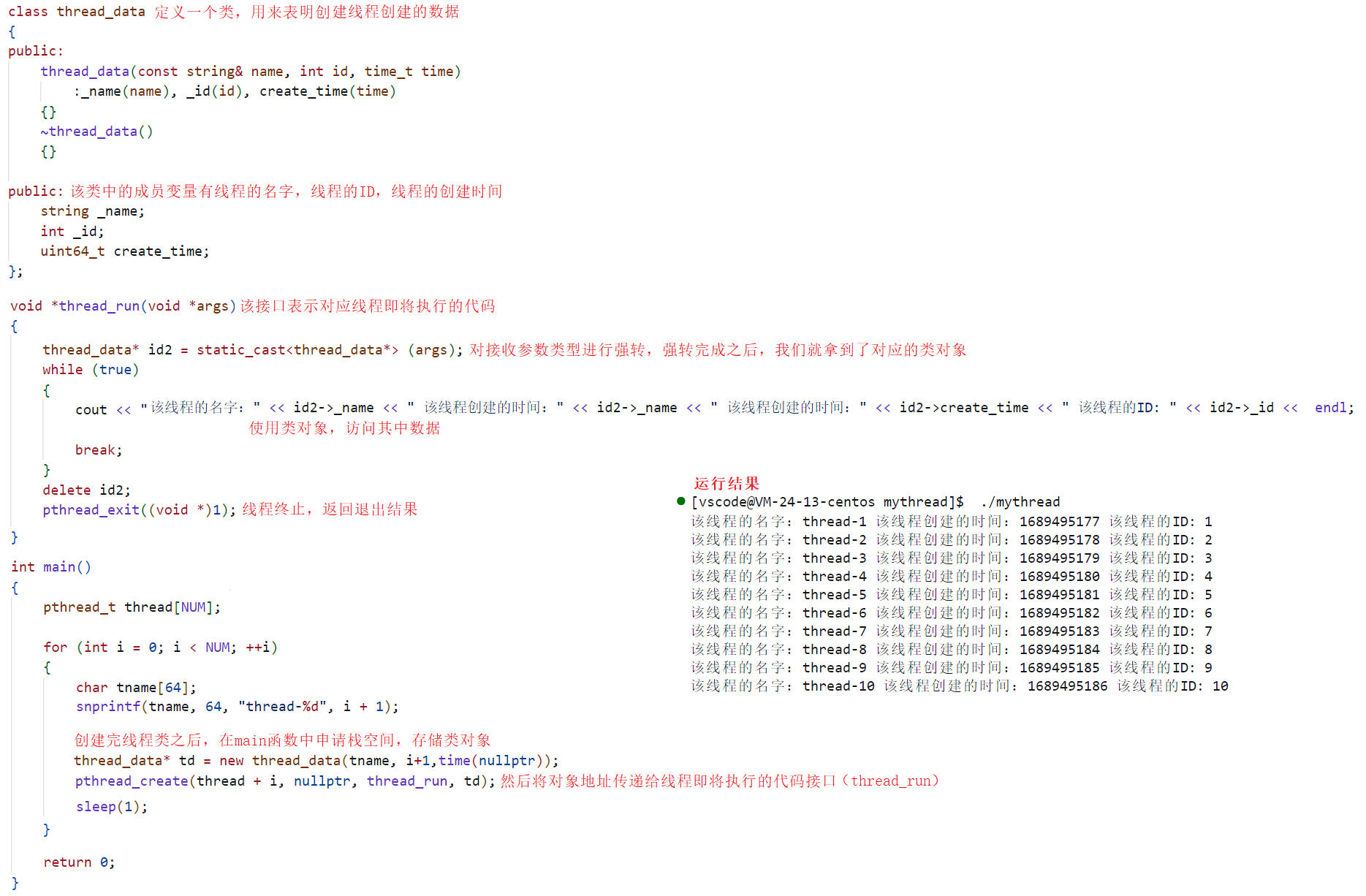
此时通过上图,我们可以发现,在进行线程创建的时候,不仅可以提供一个普通变量或者是数组变量,我们也可以提供一个类对象,在这个类中,我们可以进行特定的内容编写,如线程名字、线程ID、线程创建时间、线程状态、线程功能等!然后再申请地址空间,从而让该对象可以供给给别的函数接口使用,最后在对应接口中(线程任务)获取到对应的内容。当然,明白了这点之后,在线程终止时,我们也可以将对应的信息通过返回结果返回给主线程,如下图所示:

根据上图,此时我们就能看出,不仅仅只有在创建线程,对线程执行接口传参时,可以传类对象,在线程终止,返回退出结果时,我们也可以使用类对象的形式进行返回,虽然本质都是因为在进行接口设计时,对应参数必须是指针类型,所以此时我们就能明白,线程创建和线程终止过程中的深入使用情况,并且明白,不同的线程运行执行不同代码段,也就是执行不同的接口,完成不同的任务,并且进行不同的传参,不同的退出结果返回,实现并发运行的同时,完成不同的任务,使代码执行效率大大提高。
什么是线程分离
搞定了上述有关线程创建、线程终止、线程等待相关知识,此时我们就会发现,主线程在进行线程等待的时候,主线程需要处于等待(阻塞)状态,那么学过进程控制我们都知道,父进程在等待子进程的时候,有两种不同的等待方式,一种是阻塞式等待,一种是是非阻塞式等待(轮询等待),那么同理,对于主线程等待来说,也是两种情况,一种是阻塞式等待,一种是非阻塞式等待,那么在之前学习有关SIGCHLD信号时,我们就知道,无论是阻塞式等待,还是非阻塞式等待,都会造成父进程的效率损失,同理,在主线程等待时,也会造成效率损失,并且我们知道,在父进程等待子进程过程,我们可以使用子进程的SIGCHLD信号解决这一问题,那么在线程相关知识中,我们应该如何解决这个问题呢?答案显然就是分离线程,接口:pthread_detach,基本使用形式:int pthread_detach(pthread_t thread); 显然该接口在使用上非常的简单,和取消线程一样,只要告诉它线程ID就行,如下代码所示:

明白,一个线程如果被分离,就无法再被等待(pthread_join),否则就会报错,所以明白了这点,此时我们就知道,如果一个线程被分离,那么该创建线程就不需要被等待,从而就可以实现主线程不需要对该线程进行等待, 提高主线程的代码执行效率等…
什么是线程库
搞定了上述有关线程分离相关的知识,此时对于线程控制相关的知识我们搞定的都差不多了,当然关于有关加锁方面的知识,这里我们先不做详谈,接下来先让我们来认识一下有关线程库相关的知识,在谈线程库之前,我们从一个小问题出发,就是系统如何管理我们的线程,这个问题对于学过进程,学过底层的我们来说,并不是什么大问题,还是那两个字,管理,当然也就是先描述,再组织,具体如何描述,在之前学习线程概念时,我们谈到过的TCP结构体,就是对线程的描述,同理之前我们在学习文件系统相关知识时,FILE结构体就是对被加载文件的描述,并且此时要明白,FILE结构体是C库中一个重要的结构体,它可以帮助我们在使用C库中相关文件接口时,找到对应文件结构体的地址(struct file),具体就是因为FILE结构体中存在着一个数组指针,并且此时这个数组表示的是一个指针数组,当然也就是我们常说的文件描述符表,FILE结构体根据指针找到数组,再根据数组下标找到对应的函数指针,当然此时的这个函数指针表示的也就是对应文件的地址。明白了这点之后,对于线程来说同理,在Linux系统中因为轻量级进程的设计原因,Linux系统并不存在真正的线程,所以和C库一样,进行了一层用户级封装,也就是目前在谈的线程库,当然我们昨天使用的pthread.h头文件就是线程库中的一个重要部分,并且明白在线程库中和C库一样,也存在一个结构体,也就是TCB,同理在TCB中存在着一个指向数组的指针,利用该指针,我们就可以通过TCB找到对应的线程ID,最终找到该线程的地址,然后被CPU执行。
明白了上述知识,我们对什么是LWP,什么是TCB,什么是线程库和它们之间联系、作用,我们就有了一定的理解,此时我们再结合之前学习的有关知识(动静态库),我们明白,无论是什么库,本质首先肯定是存储在磁盘上,然后再是内存,最终凭借页表的映射关系,将对应的地址存储在地址空间中的共享区中,最终凭借线程共享地址空间,让每一个线程访问到对应的地址,访问到对应的数据(动态库),当然这块知识的具体过程想要彻底明白,是有一定难度的,想要真正搞懂,就一定要看到底层源代码的执行过程,这里我们先不详谈,我们把每一小步具体是如何执行的搞明白就行。此时我们只需要知道,每一个动态库,当然这里指的是线程库,它在被调用时,是存储在地址空间中的共享区中,如下图所示:
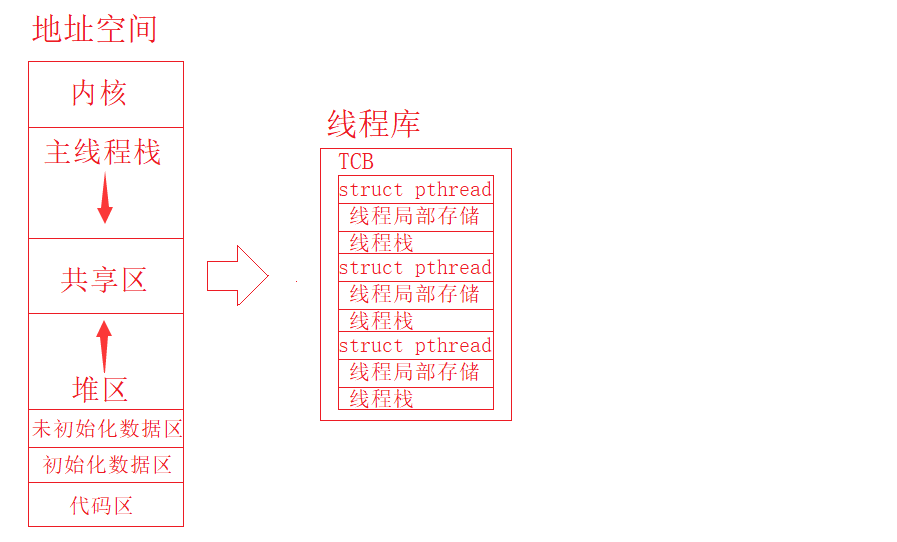
所以此时我们明白,线程库的本质就是对应的线程TCB和对应的LWP,此时在调用线程库时,我们就可以根据线程库中的LWP找到对应线程的TCB结构体,再根据TCB结构体找到对应的线程ID,最终根据线程ID找到对应的地址,从而根据地址,让CPU找到对应需要执行的代码。值得注意的是:此时的线程ID表示的就是线程在地址空间上的地址,如下图所示:
深入理解线程独立的栈结构
根据上图,此时我们还会发现,在线程TCB中不仅存在struct pthread,还会存在线程局部存储和线程栈,那么此时就有疑问了,在地址空间中,不是只有一个栈空间吗?是所有线程共用地址空间的栈吗?答案肯定是否定的,从之前有关线程概念的知识,我们知道,所有的线程都有自己独立的栈结构,所以此时我们就要明白一个点,就是主线程用的是地址空间中的栈,次线程用的是库中提供的栈,只有这样才能让它们在具有独立栈结构的同时,互不影响,当然此时要明白,由于库是位于共享区,所以库中的栈本质还是在地址空间上,只不过是在共享区上而已。再深入也就是因为地址空间本质是在内存中存储,所以最终也就是在内存的不同位置申请对应的空间供给给线程使用。明白了这个知识点,此时就会有一定的疑问,在Linux系统中,我们使用的不是轻量级进程吗,在对系统创建轻量级进程的过程中,如何获取到对应的栈结构呢?所以接下来我么就来谈谈有关创建轻量级进程的系统调用接口:clone,当然我们在线程库中使用的pthread_create接口就是对clone系统接口的一个封装,从而实现轻量级进程概念到线程的转换,clone接口基本使用方式:int clone(int (*fn)(void *), void *child_stack, int flags, void *arg); 这个接口我们不详谈,我们只要明白,其中第一个参数表示的就是该轻量级进程需要执行的函数接口,第二个参数child_stack此时表示的就是我们上述所说,库中提供的栈空间就行,也就是说在pthread_create接口中,为了调用系统调用接口clone,它就需要开辟一个栈空间,然后再把该栈空间通过参数的形式传递给轻量级进程,从而实现每一个次线程使用的都是库提供的栈空间。
如何理解线程局部存储
同理上图,在线程TCB中除了对应线程的属性信息,栈空间,每一个线程还有一个线程局部存储,那么线程局部存储具体是什么呢?谈到这个,此时我们再来谈谈线程的栈空间,当我们创建某个线程去执行某个函数,我们肯定是将对应函数的地址(函数名)作为参数传递给该线程创建接口(pthread_create),当线程创建接口接收到该地址时,由于需要去调用clone接口,此时就需要去开辟一个栈空间提供给clone接口使用,此时有了该栈空间,被创建线程需要执行函数的地址(函数参数)和该函数中的临时变量、临时数据就可以被保存,最终线程通过参数的形式就获取到了需要执行接口的地址,并且在对应该线程的栈空间中也可以找到对应函数接口的临时变量和临时数据。所以此时我们就可以明白,如果多个线程执行同一代码段中的函数接口,此时每一个线程在创建时,都会接收到该函数接口的地址,都会有自己独立的栈空间,并且这些栈空间中,都会存放对应该接口的临时变量和临时数据,具体如何将该函数的临时变量和数据拷贝到线程自己独立的栈上,这个问题这里不详谈,我们只要明白,无论是多个线程执行同一个函数接口,还是多个线程执行完全不同的函数接口,都是通过将对应函数接口的地址直接传给对应的线程,然后再把该函数接口对应栈区上的变量和数据拷贝到线程独立的栈上,所以最终明白,对于线程这种拥有自己独立栈空间的执行流来说,地址空间中栈区上的数据一般都是不止一份的 ,每一个线程的栈空间中都可能存在,只有像初始化数据区、未初始化数据区这种存储全局变量的结构,它们当中的数据,才是唯一的,所有线程共享的。明白了这个之后,搞定什么是线程局部存储就如同喝水一样,也就是说,为了让全局变量可以像栈上的局部变量一样,让每一个线程的栈空间中私有一份,此时就有了线程局部存储的概念,目的就是为了让全局变量私有化(不共享),当然本质就是让线程不直接去访问那个全局变量,而是在自己的局部存储中申请一块地址去存储它。最后一个问题,如何实现线程局部存储呢?很简单,只要在一个全局变量前面加上__thread就行,也就是__thread int g_val = 10;
线程的互斥与同步
搞定了上述有关线程库相关的所有知识,此时我们正式进入线程相关学习中最重要的概念,线程的同步与互斥,在之前学习线程相关概念时,我们知道线程的运行是并发运行,但是通过CPU的执行过程,我们可以发现,如果仅仅只有单个CPU的话,线程是达不到并发运行,因为需要通过时间片进行轮转运行,只有当处于多核处理器下,线程才能真正实现并发运行,所以当线程处于并发运行,那么此时就会面临很多问题,当然问题的本质是由线程共享资源引起,也就是如果一个进程下两个相同的进程同时访问该进程地址空间中的同一份资源,并且存在修改操作(竞态条件),那么此时程序就会出现问题,所以为了解决这个问题,伴随着线程并发运行,就出现了加锁、原子性、临界资源、临界区等概念!这里我们先简单介绍一下什么是临界资源、什么是临界区、什么是原子操作、什么是加锁,首先临界区和临界资源是互相匹配的一个概念,临界资源指的就是只允许一个线程单独访问的共享资源,临界区同理,所以为了让共享资源变成临界资源,此时就需要使用加锁或者是其它同步机制(原子操作、信号量、互斥量)来完成,所以明白,无论是加锁还是原子操作本质就是在让共享资源变成临界资源而已,注意:原子操作的本质是一种不可分割的操作,具有不可分割性和原子性,也就是保证线程在访问某一共享资源时,要么完全执行成功,要么完全不执行,这样也能很好的避免竞态条件的发生。
线程互斥
明白了上述知识,此时我们就来谈一谈什么是线程互斥,当然具体是通过代码操作来看看如何让一个线程完成互斥,让一份资源从共享资源变为临界资源,当然这块知识属于比较麻烦的一块知识,不是那么容易就能搞定了,这里我们先来认识几个有关线程加锁相关的接口,pthread_mutex_t mutex;定义一个锁,pthread_mutex_init(&mutex, nullptr);初始化一个锁, pthread_mutex_lock(&mutex);进行加锁,pthread_mutex_unlock(&mutex);进行解锁,pthread_mutex_destroy(&mutex);对锁进行销毁。了解了这几个接口之后,我们就能来看看,具体是如何对一份共享资源实现加锁,使其变为临界资源,如下代码所示:

此时通过上述代码对共享资源进行加锁,就可以很好的将该共享资源进行保护,让其不会发生竞态条件,但是此时还会面临一个问题,也就是我们定义的锁本身也是一个全局变量(共享资源),那么就会导致锁不能得到保护,造成锁的竞态条件,可能就会导致一个线程刚完成加锁,准备访问对应的临界资源,但是锁突然又被另一个线程解开了,同理,最终造成代码出现问题,所以上述代码有待改进,当然对于线程互斥相关的知识还有待我们深入理解,这里由于时间原因,该篇博客就讲到这,下篇博客,我们再深入理解线程间的互斥和同步。