比赛详情
比赛地址
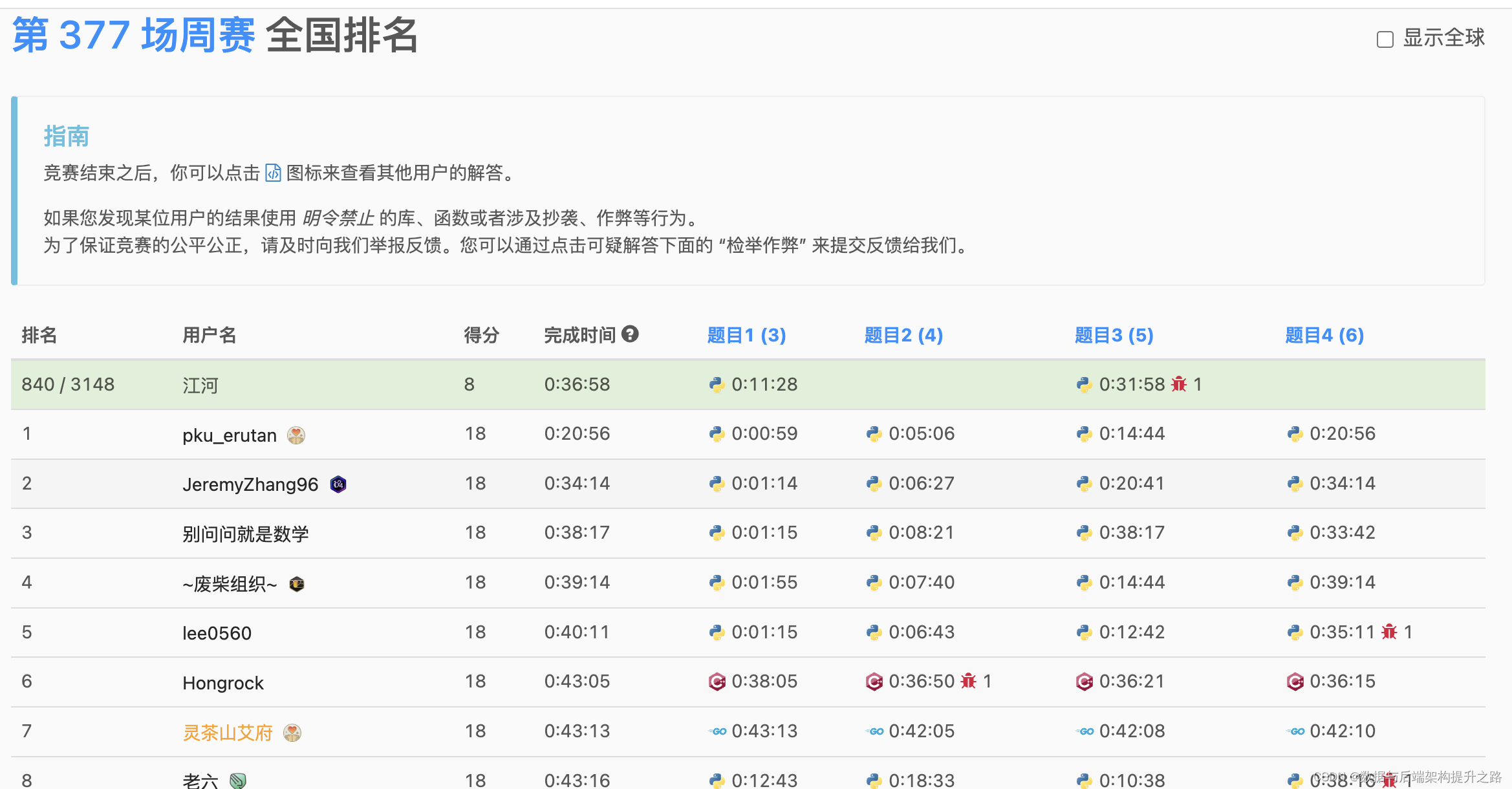
- 题目一很简单
- 题目二主要是题目长了点,其实解法很常规(比赛后才意识到)
- 题目三套用Dijkstra算法
- 题目四没时间解答水平还有待提升(其实就是需要灵活组合运用已知的算法,有点类似大模型的Agent)
题解和思路
第一题:最小数字游戏
class Solution:def numberGame(self, nums: List[int]) -> List[int]:nums.sort()arr = []# 每一轮中,Alice 先移除最小元素,然后 Bob 移除最小元素while nums:# Alice 移除最小元素alice_num = nums.pop(0) if nums else None# Bob 移除最小元素bob_num = nums.pop(0) if nums else None# Bob 先将他的元素添加到 arrif bob_num is not None:arr.append(bob_num)# 然后 Alice 添加她的元素if alice_num is not None:arr.append(alice_num)return arr第二题:移除栅栏得到的正方形田地的最大面积
from typing import Listclass Solution:def maximizeSquareArea(self, m: int, n: int, hFences: List[int], vFences: List[int]) -> int:def getGaps(fences, size):fences = sorted([1] + fences + [size]) #开始和结束的栏杆编号加入数组gaps = [fences[i+1] - fences[i] for i in range(len(fences) - 1)] # 计算相邻栏杆的距离combinations = set()for i in range(len(gaps)): # traverse the gaps starting from each and calculating all possible gap groupssum_ = 0for j in range(i, len(gaps)): # traverse gaps combinations from the start and step by step sums up the widthssum_ += gaps[j]combinations.add(sum_) # 把所有相邻的栏杆举例的可能组合计算出来return combinationsmod = 10**9 + 7hGaps = getGaps(hFences, m)vGaps = getGaps(vFences, n)max_area = 0for gap in hGaps:if gap in vGaps:max_area = max(max_area, gap ** 2) # 计算面积return max_area % mod if max_area > 0 else -1上面的解法有点绕,下面提供一个直观的写法。时间复杂度稍微高点也能Accept
mod = 10 ** 9 + 7
class Solution:def maximizeSquareArea(self, m: int, n: int, hFences: List[int], vFences: List[int]) -> int:a = [1] + hFences + [m]b = [1] + vFences + [n]tmp = set()for i in range(len(a)):for j in range(i):tmp.add(abs(a[i] - a[j]))ans = -1for i in range(len(b)):for j in range(i):if abs(b[i] - b[j]) in tmp:ans = max(ans, (b[i] - b[j]) * (b[i] - b[j]))return -1 if ans == -1 else ans % mod第三题:转换字符串的最小成本 I
import heapq
from typing import List
from collections import defaultdictclass Solution:def minimumCost(self, source: str, target: str, original: List[str], changed: List[str], cost: List[int]) -> int:# 构建图graph = defaultdict(dict)for o, c, co in zip(original, changed, cost):if c not in graph[o] or graph[o][c] > co:graph[o][c] = co# 缓存用于存储已计算的转换成本cost_cache = {}# Dijkstra 算法def dijkstra(src, tgt):if src == tgt:return 0if (src, tgt) in cost_cache:return cost_cache[(src, tgt)]visited = set()min_heap = [(0, src)] # (cost, node)while min_heap:curr_cost, curr_node = heapq.heappop(min_heap)if curr_node in visited:continuevisited.add(curr_node)if curr_node == tgt:cost_cache[(src, tgt)] = curr_costreturn curr_costfor neighbor, edge_cost in graph[curr_node].items():if neighbor not in visited:heapq.heappush(min_heap, (curr_cost + edge_cost, neighbor))cost_cache[(src, tgt)] = float('inf')return float('inf')# 计算总成本total_cost = 0for s, t in zip(source, target):cost = dijkstra(s, t)if cost == float('inf'):return -1total_cost += costreturn total_cost
第四题:转换字符串的最小成本 II
这道题目的总体思路是解决一个字符串替换问题,其中目标是找出将给定的源字符串 source 转换为目标字符串 target 的最小成本。解决这个问题的方法涉及几个关键步骤:
-
字符串编码:使用 Trie 树来处理字符串集合。Trie 树是一种有效的数据结构,用于存储和检索字符串集合。在这个场景中,每个节点代表一个字符,路径从根到特定节点表示一个字符串。通过这种方式,可以为
original和changed数组中的每个字符串分配一个唯一的数字标识符。 -
构建图并计算最短路径:在 Trie 树的帮助下,为每一对原始和更改后的字符串建立一个有向图,并将转换成本作为边的权重。使用 Dijkstra 算法来计算图中任意两点之间的最短路径,这是为了找出将任意
original字符串替换为任意changed字符串的最小成本。 -
动态规划(DFS):通过动态规划来确定将
source转换为target的最小总成本。这一步涉及到递归地检查每个字符和每个可能的字符串替换,来计算不同替换方案的累积成本。动态规划通过记忆化(缓存中间结果)来提高效率,避免重复计算相同的子问题。 -
处理特殊情况:代码中还需要处理一些特殊情况,如当
source和target在某个位置上的字符已经相等时,无需进行替换。
总体而言,这个问题的解决方案是一个综合应用 Trie 树、图论(特别是最短路径算法)和动态规划的复杂算法。它需要精确地处理字符串之间的关系和转换成本,以找出将一个字符串转换为另一个字符串的最小成本路径。
import heapq
from typing import List# TrieNode 是 Trie 树的节点,每个节点存储了指向其子节点的引用和该节点所表示字符串的唯一标识符(sid)
class TrieNode:def __init__(self):# 存储 26 个字母的子节self.children = [None] * 26# 字符串的唯一标识符self.sid = -1# Trie 类是用于存储字符串集合的 Trie 树的实现。它提供了 put 方法来将字符串添加到 Trie 树中,并分配或检索字符串的唯一标识符。
class Trie:def __init__(self):# Trie 树的根节点self.root = TrieNode()# 用于给新字符串分配唯一标识符self.sid = 0def put(self, s):# 将字符串 `s` 添加到 Trie 树中,并返回其唯一标识符# 如果字符串已存在,则返回其现有标识符node = self.rootfor ch in s:index = ord(ch) - ord('a')if not node.children[index]:node.children[index] = TrieNode()node = node.children[index]if node.sid < 0:node.sid = self.sidself.sid += 1return node.sidclass Dijkstra:def __init__(self, size):# 图中节点的数量self.size = size# 图的邻接表表示self.graph = [[] for _ in range(size)]def add_edge(self, u, v, weight):# 向图中添加一条边从 `u` 到 `v`,权重为 `weight`self.graph[u].append((v, weight))def shortest_path(self, start):distances = [float('inf')] * self.sizedistances[start] = 0pq = [(0, start)]while pq:current_distance, current_vertex = heapq.heappop(pq)if current_distance > distances[current_vertex]:continuefor neighbor, weight in self.graph[current_vertex]:distance = current_distance + weightif distance < distances[neighbor]:distances[neighbor] = distanceheapq.heappush(pq, (distance, neighbor))return distancesclass Solution:# 计算将字符串 `source` 转换为 `target` 的最小成本# 使用 Trie 树来存储 `original` 和 `changed` 中的字符串及其唯一标识符# 使用 Dijkstra 算法计算字符串之间的最短转换路径# 使用动态规划(通过 `dfs` 函数)来寻找最小成本的转换序列def minimumCost(self, source: str, target: str, original: List[str], changed: List[str], cost: List[int]) -> int:inf = 1e13trie = Trie()m = len(cost)# 初始化 Dijkstra 算法dijkstra_solver = Dijkstra(m * 2)for i, c in enumerate(cost):x = trie.put(original[i])y = trie.put(changed[i])dijkstra_solver.add_edge(x, y,min(c, dijkstra_solver.graph[x][y] if y in dijkstra_solver.graph[x] else inf))# 计算最短路径shortest_paths = [dijkstra_solver.shortest_path(i) for i in range(trie.sid)]# 动态规划n = len(source)memo = [-1] * n# dfs 是一个辅助递归函数,用于动态规划。它计算从当前索引 i 开始,# 将 source 的剩余部分转换为 target 的最小成本。def dfs(i):# 递归函数,用于计算将 source[i:] 转换为 target[i:] 的最小成本if i >= n:return 0 # 递归边界:当 i 超过 source 的长度时,返回 0if memo[i] != -1:return memo[i] # 如果当前索引的结果已经被计算过,则直接返回res = inf # 初始化当前索引的最小成本为无穷大if source[i] == target[i]:res = dfs(i + 1) # 如果当前字符相同,无需替换,直接计算下一个字符的成本p, q = trie.root, trie.root # 初始化两个 Trie 指针,分别用于遍历 source 和 target# 尝试替换 source 中从索引 i 开始的所有可能的子串for j in range(i, n):index_p = ord(source[j]) - ord('a') # 计算 source[j] 在 Trie 中的索引index_q = ord(target[j]) - ord('a') # 计算 target[j] 在 Trie 中的索引p = p.children[index_p] if p else None # 获取source[j] 在 Trie 中的节点q = q.children[index_q] if q else None # 获取target[j] 在 Trie 中的节点if p is None or q is None:break # 如果任一指针到达 Trie 的末端,表示前缀树中无法找到于source[i:j]或target[i:j]相匹配的字符串终止接下来的寻找if p.sid >= 0 and q.sid >= 0:# 如果当前子串在 original 和 changed 中都存在,则计算替换成本# 将当前子串替换成目标子串的成本加上剩余子串转换的成本res = min(res, shortest_paths[p.sid][q.sid] + dfs(j + 1))memo[i] = res # 将结果存储在 memo 中,避免重复计算return resans = dfs(0)return -1 if ans >= inf else int(ans)# 示例使用
sol = Solution()
print(sol.minimumCost("abcd", "acbe", ["a", "b", "c", "c", "e", "d"], ["b", "c", "b", "e", "b", "e"],[2, 5, 5, 1, 2, 20]))
思考:如果只是为了获取每个字符串的唯一id为什么要用前缀树?
- 处理大量可能重复的字符串时,Trie 树通过共享公共前缀,减少了重复处理相同前缀的字符串的需要。在如果一个字符串的前缀已经存在于 Trie 树中,那么代码只处理新的、独特的后缀部分。
- Trie 树的查找和插入操作的时间复杂度大致为字符串长度的线性时间(O(m),其中 m 是字符串长度),这比在哈希表或平衡二叉搜索树中处理字符串(尤其是长字符串)要高效。
- 虽然 Trie 树的空间复杂度可能比简单的哈希表高,但它通过共享公共前缀在处理大量相似字符串时变得更加空间高效。
- Trie 树特别适合于需要快速检索和更新大量字符串的应用场景,如自动补全、拼写检查器、字符串排序等。
下面展示了不用前缀树的写法会超时:
import heapq
from typing import Listclass Dijkstra:def __init__(self, size):self.size = sizeself.graph = [[] for _ in range(size)]def add_edge(self, u, v, weight):self.graph[u].append((v, weight))def shortest_path(self, start):distances = [float('inf')] * self.sizedistances[start] = 0pq = [(0, start)]while pq:current_distance, current_vertex = heapq.heappop(pq)if current_distance > distances[current_vertex]:continuefor neighbor, weight in self.graph[current_vertex]:distance = current_distance + weightif distance < distances[neighbor]:distances[neighbor] = distanceheapq.heappush(pq, (distance, neighbor))return distancesclass Solution:def minimumCost(self, source: str, target: str, original: List[str], changed: List[str], cost: List[int]) -> int:inf = 1e13string_to_id = {}id_counter = 0def get_id(s: str) -> int:nonlocal id_counterif s not in string_to_id:string_to_id[s] = id_counterid_counter += 1return string_to_id[s]m = len(original)dijkstra_solver = Dijkstra(m * 2)for i, c in enumerate(cost):x = get_id(original[i])y = get_id(changed[i])dijkstra_solver.add_edge(x, y, min(c, dijkstra_solver.graph[x][y] if y in dijkstra_solver.graph[x] else inf))shortest_paths = [dijkstra_solver.shortest_path(i) for i in range(id_counter)]n = len(source)memo = [-1] * ndef dfs(i):if i >= n:return 0if memo[i] != -1:return memo[i]res = infif source[i] == target[i]:res = dfs(i + 1)for j in range(i, n):src_substring = source[i:j+1]tgt_substring = target[i:j+1]if src_substring in string_to_id and tgt_substring in string_to_id:src_id = string_to_id[src_substring]tgt_id = string_to_id[tgt_substring]res = min(res, shortest_paths[src_id][tgt_id] + dfs(j + 1))memo[i] = resreturn resans = dfs(0)return -1 if ans >= inf else int(ans)
相关知识
LeetCode之团灭字典树相关题目-CSDN博客
LeetCode之团灭Dijkstra算法_leetcode 迪杰斯特拉-CSDN博客