问题分析
在计算机的世界里,一个问题的解决方案永远不止一种。但是取舍过后,最合适的只剩唯一。当然,你能想到的解决方案的多少,与你对这个问题的理解程度是息息相关的。对于一个问题的理解程度,与你的技术视野紧密不可分。你想到而能不能做到,与你的技术实力直接挂钩。好像不止是计算机世界哈,哪个世界都这样!
比如说让你来实现OOP机制。咱们先不说完整的,就聚焦属性继承,你会如何实现。经常看我文章的小伙伴可能比较奇怪,为什么我总是问类型这样的问题?因为研究底层与研究应用层不同,或者说你用研究应用层的思维来研究底层也可以,但是效果一定不会太好。
就我自身来说,我研究底层,第一件事情就是让自己身处设计者的角度,以设计者的思维来思考问题,来理解思想,来阅读代码。每次问这样的问题,意在此。设计者思维是一种试图理解思维,学习思维是一种批判思维。
言归正传,我都能猜出来大家会如何实现,上代码
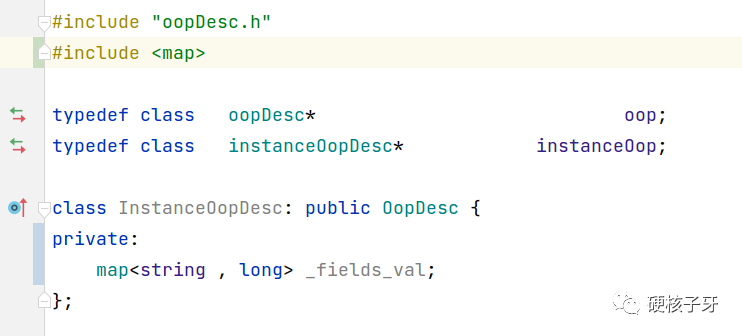
解释下这段代码:oop是所有Java对象在hotpot中的存在形式,klass是所有Java类在hotspot中的存在形式。现在需要在对象中存储实例数据,毫无疑问需要用到容器,毫无疑问map是最合适的容器。
你如果用Java来实现,确实只能这样写。因为Java作为应用层语言,除了Unsafe提供了简单的操作内存的方法外,Java是没有内存处理能力的。而且写Java程序,聚焦业务实现即可。你的代码性能好不好,吃不吃内存,安不安全,本质还是取决于你选择的JVM是否优秀。
如果hotspot这样去实现,也可以哈。只不过不够优秀,可能会听到来自其他编程语言的鄙视。何为优秀的程序,当下能实现的,达到时间与空间完美结合。如果这样实现的话,会存在内存浪费过于严重的问题。这个我就不解释了,我之前的文章有讲过。传送门
那hotshot是如何实现的呢?内存编织。即在一块事先申请好的内存中,按照属性类型,给它分一块相同大小的内存块,织入进去。我之前写的那篇文章,这里没有展开讲。本篇文章,对,展开细讲这里。
这里面有这些问题需要我们来作答:
-
这个事先申请好的内存,得申请多大
-
属性有可能是bool、char、short、int、long、oop,如何编织能做到既节省内存又内存对齐
-
织入的时候是无状态的,即你在访问一个对象的属性的时候,不能通过oop.a这样直接找到,那怎么办呢
-
采用内存编织的方式创建对象一定就不会内存浪费了吗
分配多大内存
就如你打算给你素未谋面的男女朋友买双鞋子,谁知道他她多大脚呢?猜一下?合适了说你阅人无数,不合适说你不上心。哎,太难了,还是算吧。
怎么算呢?你脑海中得有一张图?不,是两张图。什么图?对象的内存布局图。
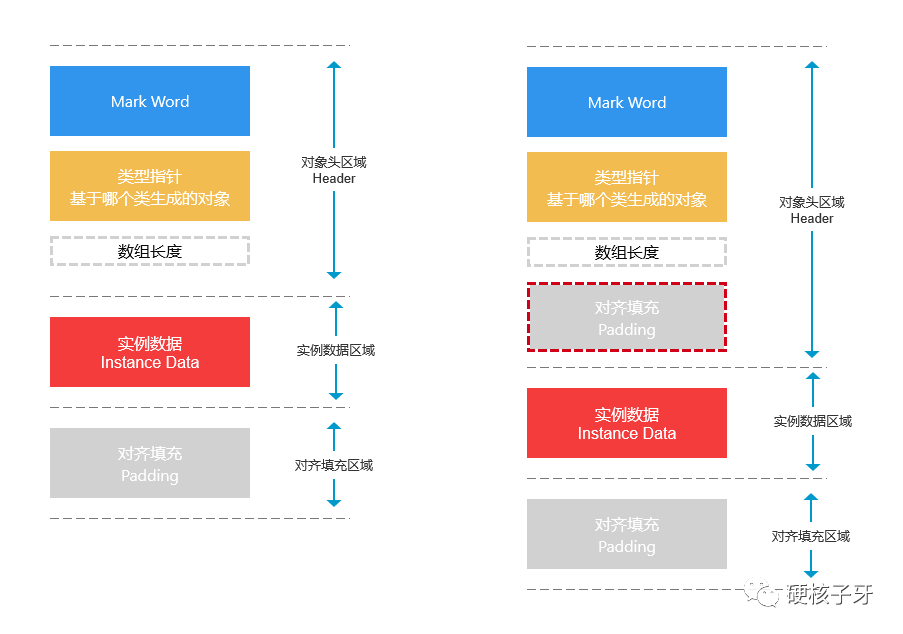
那第四个问题就有答案了:还是会存在内存浪费,灰色的padding区域就是为了对齐而填充的区域,即浪费的内存。但是这个浪费是很少的了,是可以接受的了,是目前条件下可以做到的最好的了。
这里面每个区域占用内存大小的细节如下:
-
Mark Word:在32位机器下,占4B。在64位机器下,占8B。本篇文章说的是64位机
-
类型指针:又名klass pointer,开启指针压缩占4B,关闭指针压缩是8B。默认是开启的。开启指针压缩占4B是指有效数据占4B,这块区域在内存中还是占8B。这个区域很重要,怎么理解这个重要呢?一、这个区域跟第三个问题的答案有关,后面讲;二、指针压缩的开启或关闭,对内存结构图有影响。对比两幅图就能看出来,会多出一个填充区域。这个细节,后面讲
-
数组长度:如果是数组对象,占4B。如果非数组对象,占0B,即不会出现
-
实例数据:这块是核心影响区域,等下细讲
-
对齐填充:所有的oop必须8B对齐,这个约定。如果一个oop只有12B,比如new object就是12B,无法被8整除,末尾补4B的0
我们说大多数情况:64位机器,开启指针压缩,非数组对象,如果提前分配内存,目前只有实例数据这一块区域的大小是不确定的。这块也是最难确定的。hotspot是怎么做的呢?统计每种数据类型的大小,然后进行统一运算。上代码
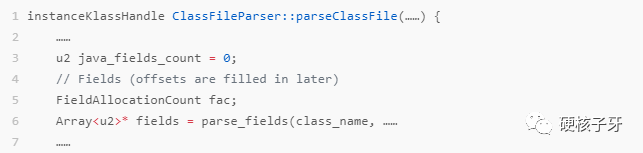
parse_fields就是用来解析字节码文件中的属性信息的。只不过为了配合内存编织的实现,除了解析,还需要统计每种类型的属性的数量。统计到的信息存储到对象FieldAllocationCount中。计算细节如下图:
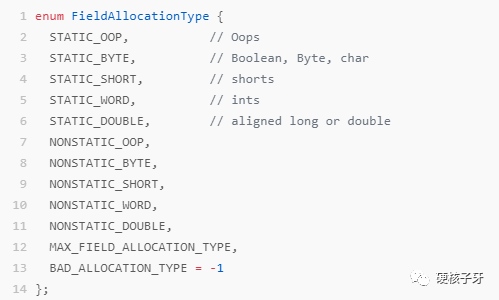
就不卖关子了,hotspot中将boolean、byte、char都当成c++层面的byte来处理,即算作占1B。其他的Java类型映射哪个C++类型,看注释就能知晓。静态属性与非静态属性是分开统计的,为什么呢?因为存储的位置不同。静态属性在Class对象对应的oop上,非静态属性在new出来的oop上。
这里面有个细节,Java中的char是2B,这边当成1B处理,不会出问题吗?不会。hotspot底层做了工作,具体怎么做的。后面讲。
统计完以后,就可以知晓即将创建的对象占多少字节了,伪代码如下
8 + 4 + oop * count + byte * count……没有容器何谈编织。那现在有了容器,该如何织入呢?
编织细节
同样是64位机。先说关闭指针压缩情况下的编织细节,开启指针压缩的情况有些许特殊。
hotspot支持三种编织规则:
-
allocation_style=0:属性按由大到小的顺序进行织入,oop优先。编织顺序为oop、long/double、int、short/char、byte。织入所有属性后如果对象大小非8B对齐,尾部增加填充区域。填充字节数是多少?这个公式就交给聪明的大家了。
-
allocation_style=1:属性还是按由大到小的属性进行织入,不过这种方式,oop最后织入。同样,非8B对齐依然需要补填充区域。
-
allocation_style=2:这种规则会将子类的oop与父类oop综合起来考虑,略显复杂,后面有空细讲
我想,大家是不是有这个疑惑:为什么不能从小到大进行织入。非不为也,实不能也。自己悟一下咯。
上面有段标红的文字:开启指针压缩占4B是指有效数据占4B,这块区域在内存中还是占8B。这里其实就是开启或关闭指针压缩的核心区别所在。
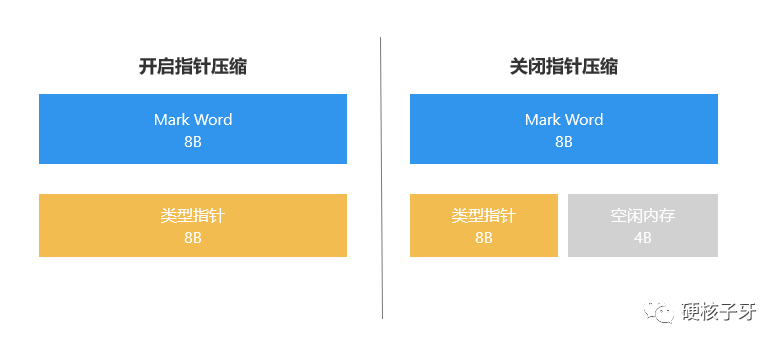
不管是否开启指针压缩,这块区域都要吃掉8B内存。那在关闭指针压缩的情况下,这块区域就浪费掉了4B内存。能忍?可忍可不忍。hotspot给了你选择权。通过修改-XX:+/-CompactFields的值,可以选择让hotspot是否往这块间隙中织入属性。默认是开启的。可以通过如下代码测试
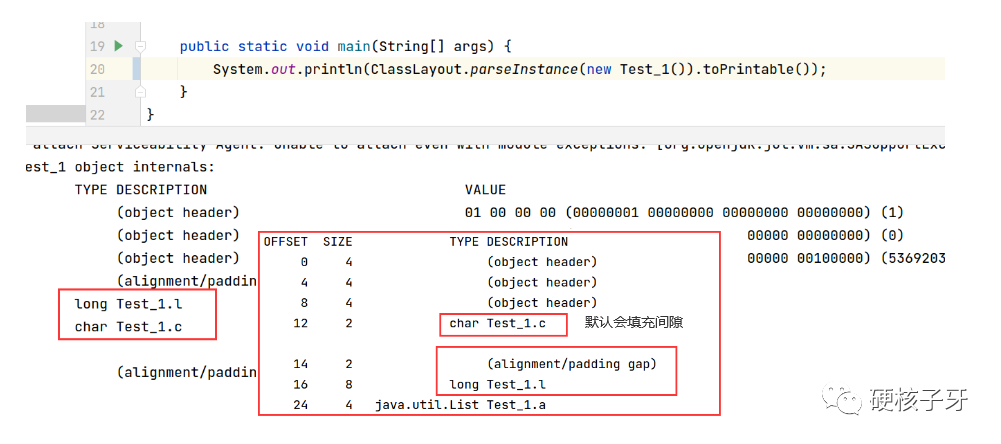
hotspot就是通过这三套规则进行属性织入,达到既节省内存又内存对齐的效果。默认是allocation_style=1的那种。
如何访问属性
到这里就剩最后一个问题了:如何访问。之前有问题提过这里,今天细看源码发现不太对。访问细节是这样子的
oop.类型指针.fields.offset因为oop只是一块内存,并不知道哪块内存里存储的是什么属性。所以hotspot的方式是通过类型指针找到这个oop对象的klass,klass中有所有的属性信息,存储在数组中。通过属性的名称+签名找到具体访问的属性的所有信息,这个信息中就有这个offset。这个offset还不是对象中的offset,是索引。拿到这个索引再进行运算,才能真正找到属性在oop中的位置。有点抽象,举个例子。
比如Java类中有两个char,是按照代码顺序织入的。如果我想访问c2:
-
通过oop.类型指针拿到Test类对应的klass
-
通过调用findField,传入属性名+签名拿到c2的完整信息及offset
-
再调用注入char_offset_addr(offset)计算得到c2在oop中的内存地址
-
进行访问拿到c2的数据

那field.offset是何时计算出来的呢

结语
如果你每次都是因为native而对hotspot源码束手无策,如果你每次都是因为底层而无法深入研究下去,如果你深入骨子里的想成为技术大牛,欢迎跟着我学习,关注我的公众号,找我咨询课程。跟我学底层,一定不会踩坑,一定学有所得。