C++内存管理机制(侯捷)
本文是学习笔记,仅供个人学习使用。如有侵权,请联系删除。
参考链接
Youtube: 侯捷-C++内存管理机制
Github课程视频、PPT和源代码: https://github.com/ZachL1/Bilibili-plus
第一讲primitives的笔记
截至2024年1月10日17点09分,花费一天的时间完成《C++内存管理——从平地到万丈高楼》第一讲的学习,主要学习了new delete, array new,placement new,以及allocator的几个设计版本。
文章目录
- C++内存管理机制(侯捷)
- 2 内存分配的每一层面
- 3 四个层面的基本用法
- 4 基本构件之一new delete expression上
- 5 基本构件之一new delete expression中
- 6 基本构件之一new delete expression下
- 7 Array new
- 8 placement new
- 9 重载
- 10 重载示例(上)
- 11 重载示例(下)
- 12 Per class allocator
- 13 Per class allocator 2
- 14 Static allocator
- 15 Macro for static allocator
- 16 New Handler
- 后记
2 内存分配的每一层面
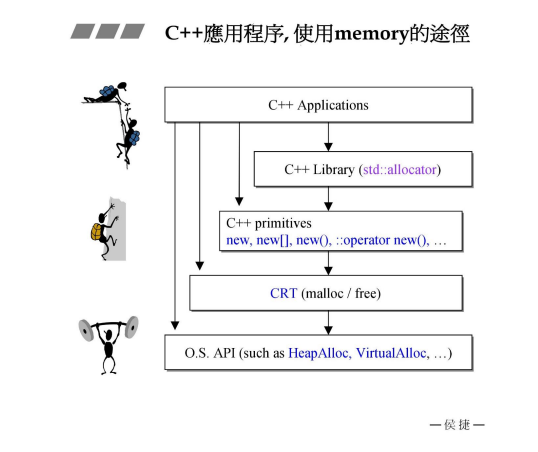
C++的 applications可以调用STL,里面会有allocator进行内存分配;也可以使用C++ 基本工具primitives,比如new, new[], new(), ::operator new();还可以使用更底层的malloc和free分配和释放内存。最底层的是系统调用,比如HeapAlloc,VirtualAlloc等。
HeapAlloc,VirtualAlloc的介绍
HeapAlloc 和 VirtualAlloc 是 Windows 操作系统中用于内存分配的两个重要的系统调用。
-
HeapAlloc:
-
描述:
HeapAlloc用于在指定的堆中分配一块指定大小的内存。 -
参数:
hHeap: 指定要分配内存的堆的句柄。dwFlags: 分配选项,例如是否可以共享内存等。dwBytes: 要分配的内存大小,以字节为单位。
-
返回值: 成功时返回分配内存块的指针,失败时返回
NULL。 -
示例:
HANDLE hHeap = GetProcessHeap(); LPVOID lpMemory = HeapAlloc(hHeap, 0, 1024); // 在默认堆中分配 1024 字节的内存
-
-
VirtualAlloc:
-
描述:
VirtualAlloc用于在进程的虚拟地址空间中分配、保留或提交内存。 -
参数:
lpAddress: 指定欲分配的内存的首选地址。可以指定为NULL,系统会自动选择合适的地址。dwSize: 要分配的内存大小,以字节为单位。flAllocationType: 分配类型,例如是保留、提交还是同时进行。flProtect: 内存保护选项,指定内存区域的访问权限。
-
返回值: 成功时返回分配内存块的起始地址,失败时返回
NULL。 -
示例:
LPVOID lpMemory = VirtualAlloc(NULL, 1024, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
-
这两个系统调用都是用于在程序运行时动态分配内存。HeapAlloc 通常与堆相关联,而 VirtualAlloc 则更为底层,允许更多的灵活性,例如手动指定内存地址,控制内存保护选项等。在实际使用中,选择使用哪个取决于具体的需求和使用场景。
C++ memory primitives介绍

malloc,free和new delete的区别
malloc、free、new 和 delete 是在C和C++中用于内存管理的操作符和函数。它们之间有一些重要的区别:
-
malloc和free(C语言):-
malloc用于在堆上分配一块指定大小的内存,返回分配内存的首地址。int *ptr = (int *)malloc(sizeof(int)); -
free用于释放先前由malloc分配的内存。free(ptr); -
在C中,
malloc和free是标准库函数,不涉及构造函数和析构函数,只是简单的内存分配和释放。
-
-
new和delete(C++语言):-
new用于在堆上分配一块指定大小的内存,并调用对象的构造函数来初始化对象。int *ptr = new int; -
delete用于释放由new分配的内存,并调用对象的析构函数。delete ptr; -
在C++中,
new和delete不仅仅是内存分配和释放的操作符,还会处理对象的构造和析构,因此它们更适用于处理对象。
-
总的来说,主要区别包括:
malloc和free是C语言标准库函数,适用于内存分配和释放,不涉及构造和析构。new和delete是C++语言中的操作符,用于动态对象的创建和销毁,涉及构造和析构。- 在C++中,不应该混合使用
malloc/free和new/delete,因为它们有不同的内存管理方式和处理构造析构的机制。如果你在C++中使用new,应该使用相应的delete来释放内存,而不是free。
3 四个层面的基本用法
对malloc,new,allocator进行测试
#include <iostream>
#include <complex>
#include <memory> //std::allocator
#include <ext\pool_allocator.h> //欲使用 std::allocator 以外的 allocator, 就得自行 #include <ext/...>
namespace jj01
{
void test_primitives()
{cout << "\ntest_primitives().......... \n";void* p1 = malloc(512); //512 bytesfree(p1);complex<int>* p2 = new complex<int>; //one objectdelete p2; void* p3 = ::operator new(512); //512 bytes::operator delete(p3);//以下使用 C++ 標準庫提供的 allocators。
//其接口雖有標準規格,但實現廠商並未完全遵守;下面三者形式略異。
#ifdef _MSC_VER//以下兩函數都是 non-static,定要通過 object 調用。以下分配 3 個 ints.int* p4 = allocator<int>().allocate(3, (int*)0); allocator<int>().deallocate(p4,3);
#endif
#ifdef __BORLANDC__//以下兩函數都是 non-static,定要通過 object 調用。以下分配 5 個 ints.int* p4 = allocator<int>().allocate(5); allocator<int>().deallocate(p4,5);
#endif
#ifdef __GNUC__//以下兩函數都是 static,可通過全名調用之。以下分配 512 bytes.//void* p4 = alloc::allocate(512); //alloc::deallocate(p4,512); //以下兩函數都是 non-static,定要通過 object 調用。以下分配 7 個 ints. void* p4 = allocator<int>().allocate(7); allocator<int>().deallocate((int*)p4,7); //以下兩函數都是 non-static,定要通過 object 調用。以下分配 9 個 ints. void* p5 = __gnu_cxx::__pool_alloc<int>().allocate(9); __gnu_cxx::__pool_alloc<int>().deallocate((int*)p5,9);
#endif
}
} //namespace
复习C++的语法:临时对象调用成员函数的用法
int* p4 = allocator<int>().allocate(5);
allocator<int>().deallocate(p4,5);
这行C++代码涉及到模板、临时对象以及动态内存分配,下面是对该行代码的详细介绍:
int* p4 = allocator<int>().allocate(5);
-
allocator<int>():allocator是 C++ 标准库中的分配器类,用于分配和释放内存。<int>是模板参数,指定了分配器要操作的类型为int。allocator<int>()创建了一个临时的allocator对象。这是一个匿名对象,即在一行代码内创建并使用,不会被显式地命名。这样的对象通常用于执行一些简短的任务而不需要长时间存活。
-
.allocate(5):allocate是allocator类的成员函数,用于分配指定数量的未初始化内存块,并返回指向第一个元素的指针。5是要分配的元素数量。
-
int* p4:int*声明了一个指向整数的指针。p4是指针变量的名称。
综合起来,该行代码的作用是使用 allocator<int> 创建了一个临时的分配器对象,并调用其 allocate 函数分配了大小为 5 * sizeof(int) 字节的内存块。然后,将分配的内存块的首地址赋给 int* p4,使 p4 成为该内存块的指针。请注意,这里的内存块中的元素并没有被初始化,如果需要使用这些元素,必须进行相应的初始化操作。这样的代码在某些特殊场景下,例如需要手动管理内存的情况,可能会用到。
对#ifdef后面的_MSC_VER,__BORLANDC__,__GNUC__进行解释:
这段代码使用了条件编译指令 #ifdef,根据不同的编译器选择性地编译不同的代码块。以下是对这些宏的解释:
-
#ifdef _MSC_VER:_MSC_VER是 Microsoft Visual Studio 编译器的宏,它的值对应于编译器的版本号。- 如果代码正在使用 Microsoft Visual Studio 编译器编译,那么这个条件为真,相关的代码块会被编译。
- 在这个条件下,使用
allocator<int>对象分配和释放内存。
-
#ifdef __BORLANDC__:__BORLANDC__是 Borland 编译器的宏,用于检查是否正在使用 Borland 编译器。- 如果代码正在使用 Borland 编译器编译,那么这个条件为真,相关的代码块会被编译。
- 在这个条件下,使用
allocator<int>对象分配和释放内存。
-
#ifdef __GNUC__:__GNUC__是 GNU 编译器(例如,gcc 和 g++)的宏。- 如果代码正在使用 GNU 编译器编译,那么这个条件为真,相关的代码块会被编译。
- 在这个条件下,有两个不同的分配和释放内存的方式:
- 一个使用
allocator<int>对象。 - 另一个使用 GNU C++ 库中的
__gnu_cxx::__pool_alloc<int>()对象。
- 一个使用
总体来说,这段代码在不同的编译环境下,使用不同的方式进行内存分配和释放。这样的条件编译可以使代码适应不同的编译器和环境。
下图中的__GNUC__的版本是2.9,它里面的分配器叫做alloc

下图是__GNUC__版本4.9的分配器,叫做__gnu_cxx::__pool_alloc指的是上面的alloc分配器

4 基本构件之一new delete expression上
new expression
new的过程:调用operator new分配内存(内部调用mlloc函数),指针转型,然后调用构造函数。
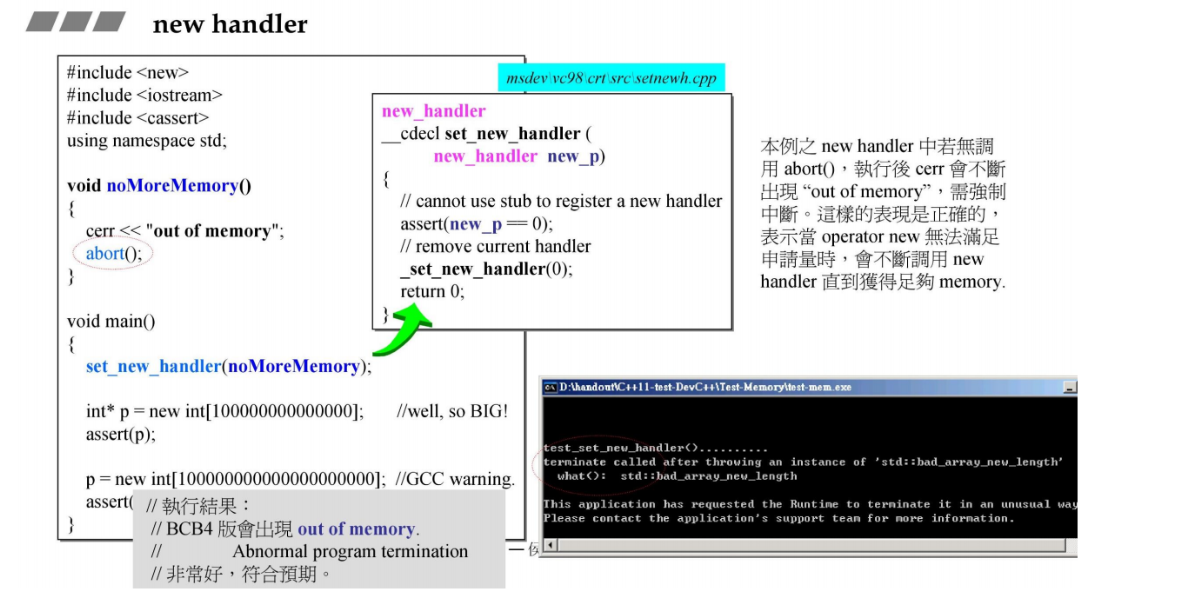
下图中右上角operator new的实现,这是vc98版本的源代码,里面调用malloc函数,如果malloc无法分配内存,就一直在while循环中,它调用_callnewh,这是一个new handler用于处理内存失败的情况,比如释放一部分内存等。
_callnewh 不是 C++ 标准中的函数,而是可能是用户定义的一个函数。通常情况下,这类函数的名字以 _new_handler 结尾,用于处理内存分配失败的情况。
在 C++ 中,当 new 表达式无法分配所需的内存时,会调用用户指定的 new_handler 函数。new_handler 是一个函数指针,指向一个用户定义的函数,其原型通常为:
typedef void (*new_handler)();
这个函数可以尝试释放内存、扩大内存池,或者执行其他操作来尝试解决内存不足的问题。如果 new_handler 能够成功处理内存不足的情况,它返回;如果不能处理,它可以选择抛出异常或者终止程序。
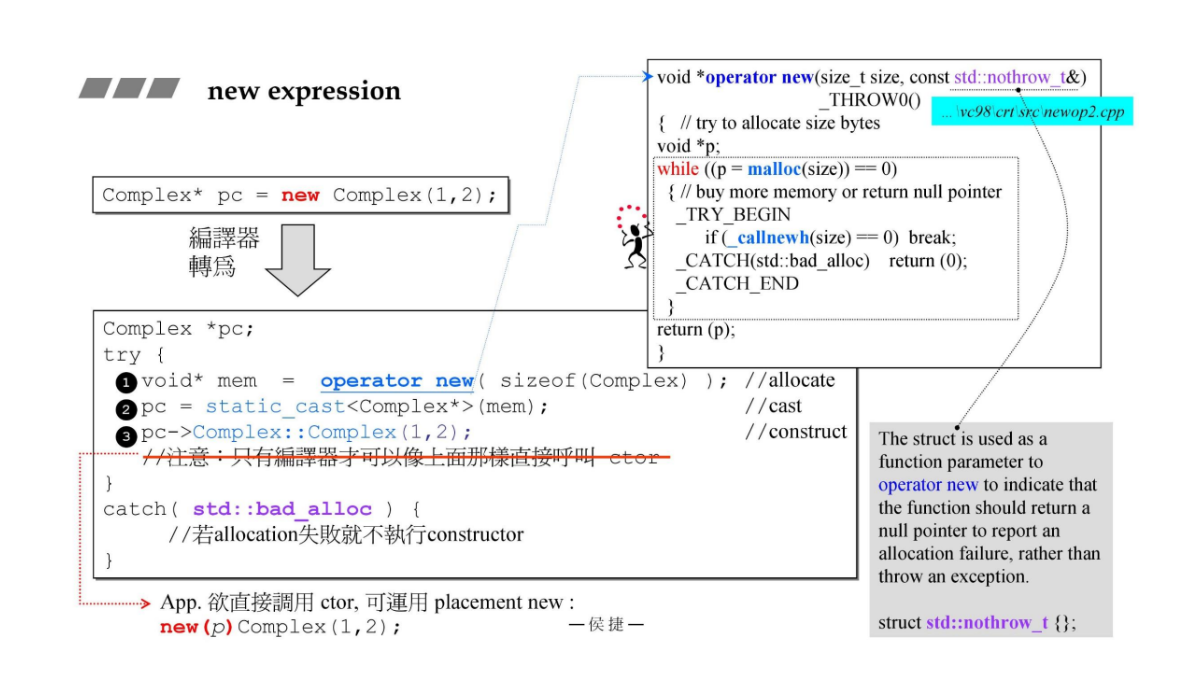
当使用 new 运算符创建对象时,整个过程包括以下几个步骤:
-
调用
operator new分配内存:operator new是一个用于动态内存分配的函数,它负责分配指定大小的内存块,并返回该内存块的指针。在内部,operator new可能调用标准库的malloc或其他分配函数来完成实际的内存分配。- 例如:
void* rawMemory = operator new(sizeof(MyClass));
-
指针转型:
- 分配得到的原始内存的指针是
void*类型的,因为operator new并不知道具体分配的是什么类型的对象。因此,需要将void*转换为所需类型的指针。 - 例如:
MyClass* objPtr = static_cast<MyClass*>(rawMemory);
- 分配得到的原始内存的指针是
-
调用构造函数:
-
通过转型后的指针,调用对象的构造函数进行初始化。这是为了确保对象在分配内存后能够执行必要的初始化操作。
-
例如:
new (objPtr) MyClass(/* constructor arguments */); -
上述语法使用了定位
new(placement new)运算符,它将在指定的内存位置调用构造函数。这允许我们在已分配的内存中构造对象,而不是在默认构造函数中执行内存分配。
-
综合来说,使用 new 运算符的过程涉及内存分配、指针类型转换和构造函数的调用,确保对象能够正确地初始化。在对象的生命周期结束时,还需要通过 delete 运算符释放内存,并调用对象的析构函数。
继续补充定位new运算符:
定位 new 运算符是 C++ 中的一种特殊形式的内存分配运算符,用于在指定的内存位置上创建对象。它的语法如下:
new (pointer) Type(initializer);
其中:
pointer是指定的内存地址,通常是一个指针。Type是要创建的对象的类型。initializer是可选的构造函数参数,用于初始化对象。
定位 new 主要用于以下情况:
-
在预分配的内存块中创建对象:
void* memory = operator new(sizeof(MyClass)); // 分配内存 MyClass* obj = new (memory) MyClass(/* constructor arguments */); // 在指定内存位置创建对象 -
在数组中创建对象:
void* memory = operator new[](sizeof(MyClass) * 5); // 分配数组内存 MyClass* objArray = new (memory) MyClass[5]; // 在数组内存中创建对象 -
用于自定义的内存管理:
定位new允许程序员有更多的控制权,可以通过指定特定的内存地址,使用自定义的内存管理策略。
需要特别注意的是,使用定位 new 运算符后,必须手动调用对象的析构函数来释放资源,否则可能导致内存泄漏。示例如下:
obj->~MyClass(); // 手动调用析构函数
operator delete(memory); // 手动释放内存
在现代 C++ 中,为了避免手动管理内存和调用析构函数,更推荐使用智能指针、标准容器以及 RAII(资源获取即初始化)等方式,以提高代码的可维护性和安全性。
5 基本构件之一new delete expression中
delete的动作:先调用析构函数,然后释放内存。
operator delete里面调用free。

6 基本构件之一new delete expression下
构造函数ctor和析构函数dtor直接调用

下面显示不能直接调用构造函数,而只有编译器会进行隐式调用。调用时在vc6编译通过,在GCC中编译失败。
A* pA = new A(1); //ctor. this=000307A8 id=1
cout << pA->id << endl; //1
//! pA->A::A(3); //in VC6 : ctor. this=000307A8 id=3//in GCC : [Error] cannot call constructor 'jj02::A::A' directly//! A::A(5); //in VC6 : ctor. this=0013FF60 id=5// dtor. this=0013FF60 //in GCC : [Error] cannot call constructor 'jj02::A::A' directly// [Note] for a function-style cast, remove the redundant '::A'
测试代码如下:
#include <iostream>
#include <string>
//#include <memory> //std::allocator namespace jj02
{class A
{
public:int id;A() : id(0) { cout << "default ctor. this=" << this << " id=" << id << endl; }A(int i) : id(i) { cout << "ctor. this=" << this << " id=" << id << endl; }~A() { cout << "dtor. this=" << this << " id=" << id << endl; }
};void test_call_ctor_directly()
{cout << "\ntest_call_ctor_directly().......... \n"; string* pstr = new string;cout << "str= " << *pstr << endl;//! pstr->string::string("jjhou"); //[Error] 'class std::basic_string<char>' has no member named 'string'
//! pstr->~string(); //crash -- 其語法語意都是正確的, crash 只因為上一行被 remark 起來嘛. cout << "str= " << *pstr << endl;//------------A* pA = new A(1); //ctor. this=000307A8 id=1cout << pA->id << endl; //1
//! pA->A::A(3); //in VC6 : ctor. this=000307A8 id=3//in GCC : [Error] cannot call constructor 'jj02::A::A' directly//! A::A(5); //in VC6 : ctor. this=0013FF60 id=5// dtor. this=0013FF60 //in GCC : [Error] cannot call constructor 'jj02::A::A' directly// [Note] for a function-style cast, remove the redundant '::A'cout << pA->id << endl; //in VC6 : 3//in GCC : 1 delete pA; //dtor. this=000307A8 //simulate newvoid* p = ::operator new(sizeof(A)); cout << "p=" << p << endl; //p=000307A8pA = static_cast<A*>(p);
//! pA->A::A(2); //in VC6 : ctor. this=000307A8 id=2//in GCC : [Error] cannot call constructor 'jj02::A::A' directly cout << pA->id << endl; //in VC6 : 2//in GCC : 0 //simulate deletepA->~A(); //dtor. this=000307A8 ::operator delete(pA); //free()
}
} //namespace
7 Array new
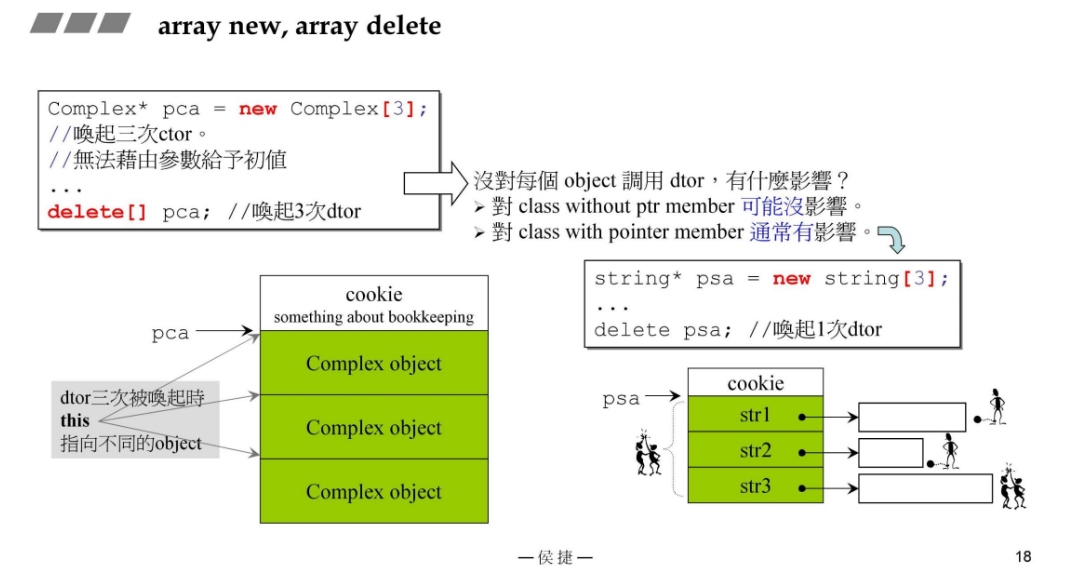
Complex* pca = new Complex[3]; // 调用三次构造函数
delete[] pca; // 唤起三次析构函数, 这是正确的string* psa = new string[3];
delete psa; // 唤起一次析构函数,这是错误的
对于 delete[] pca;,编译器会通过运行时信息来确定需要释放的内存块的数量,因为在动态数组分配时,会在数组的前面(通常)记录数组的大小信息。这个信息通常被称为“cookie”或“size”,它使得 delete[] 知道要调用多少次析构函数,并释放相应数量的内存。这种信息是由编译器自动管理的。
但是,当你使用 delete pca; 尝试删除一个使用 new[] 分配的数组时,会导致未定义的行为,因为编译器可能无法正确获取数组的大小信息。这样的操作可能会导致内存泄漏和未能正确调用对象的析构函数。因此,为了正确的内存管理,应该始终使用相匹配的 new 和 delete 或 new[] 和 delete[] 运算符。
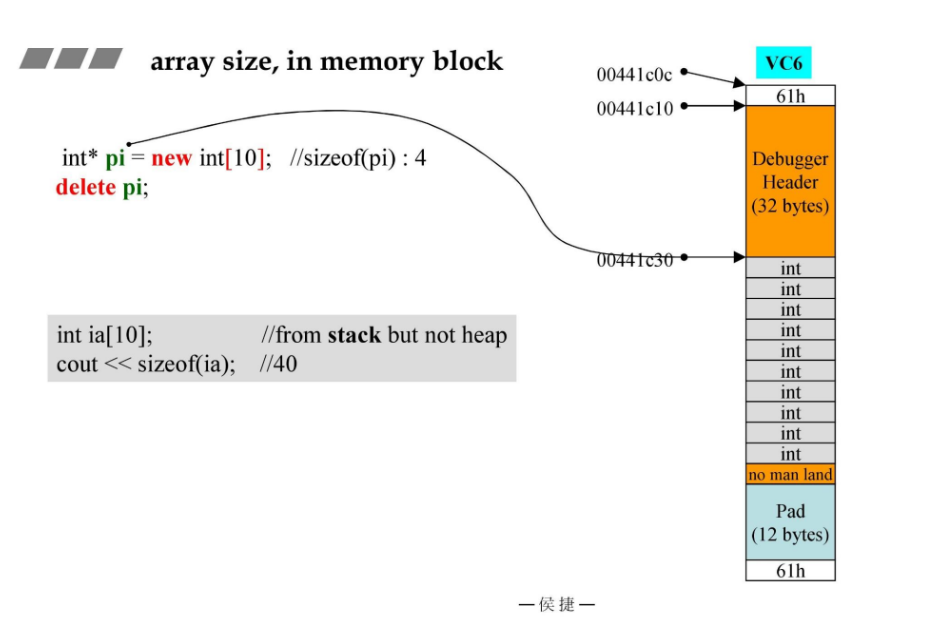
下面右侧的图是new int[10]的内存布局,其中灰色的表示具体的数据,橙色的是debug模式下添加的内存,最上面和最下面的两个0x61(61H)是cookie,记录整体内存分配的大小。61H实际上是60H,表示内存分配的大小,后面1H意思是占用最后一位,表示内存分配出去。浅蓝色的pad表示补齐,填补到16的倍数。
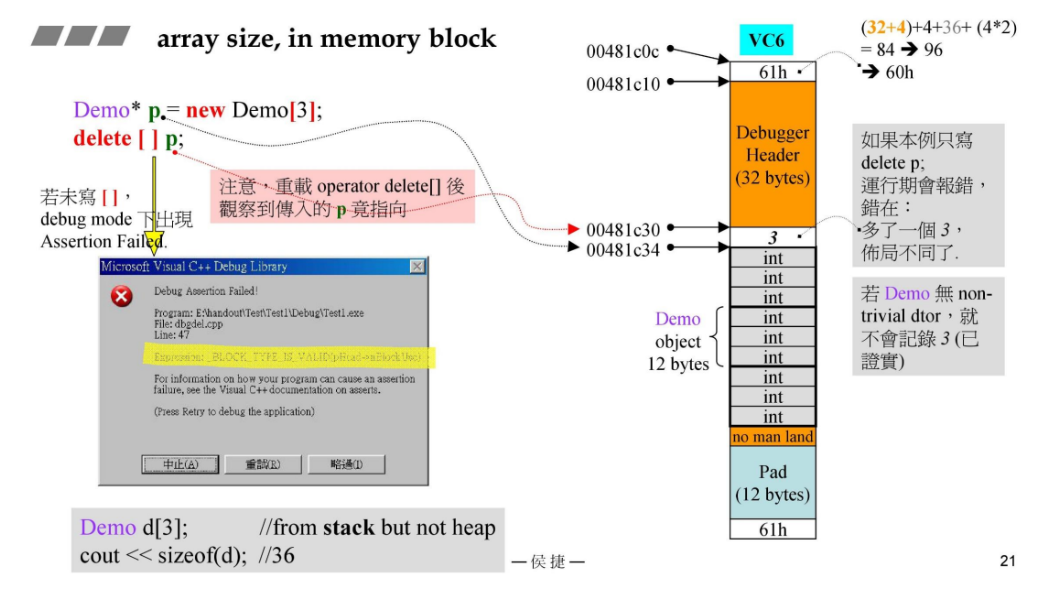
下面的Demo中有3个int型的成员变量,所以每个Demo对象的大小是12B(每个int型是 4B)
8 placement new
placement new允许我们将对象建构在allocated memory中。
#include<new>
char* buf = new char[sizeof(Complex) * 3]; // 已经分配了内存
Complex* pc = new(buf)Complex(1, 2); // 把上面分配的内存位置传进来delete[] buf;
其中Complex* pc = new(buf)Complex(1, 2);这句话会被编译器转换为下图中的1,2,3三行,分别调用operator new(和上文看到的不同,这里需要第二个参数,表示位置,这个函数只是传回这个位置,不再分配内存),指针转型,调用构造函数。
这种用法被称为 “placement new”,它允许程序员在指定的内存位置上创建对象。这通常用于特殊的内存管理场景,例如在预分配的内存池中创建对象。

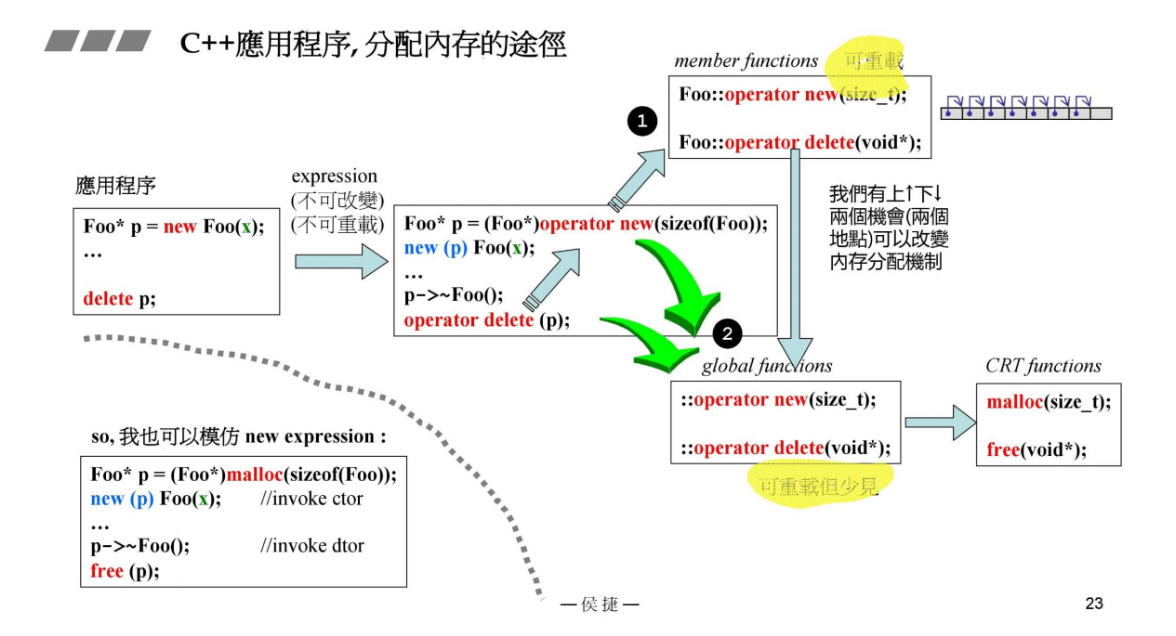
9 重载
C++应用程序,分配内存的途径
一个类里面可重载operator new 和 operator delete,从而改变内存的分配机制
C++容器分配内存的途径
容器会走分配器,分配器会调用::operator new和::operator delete,底层也是调用malloc和free。
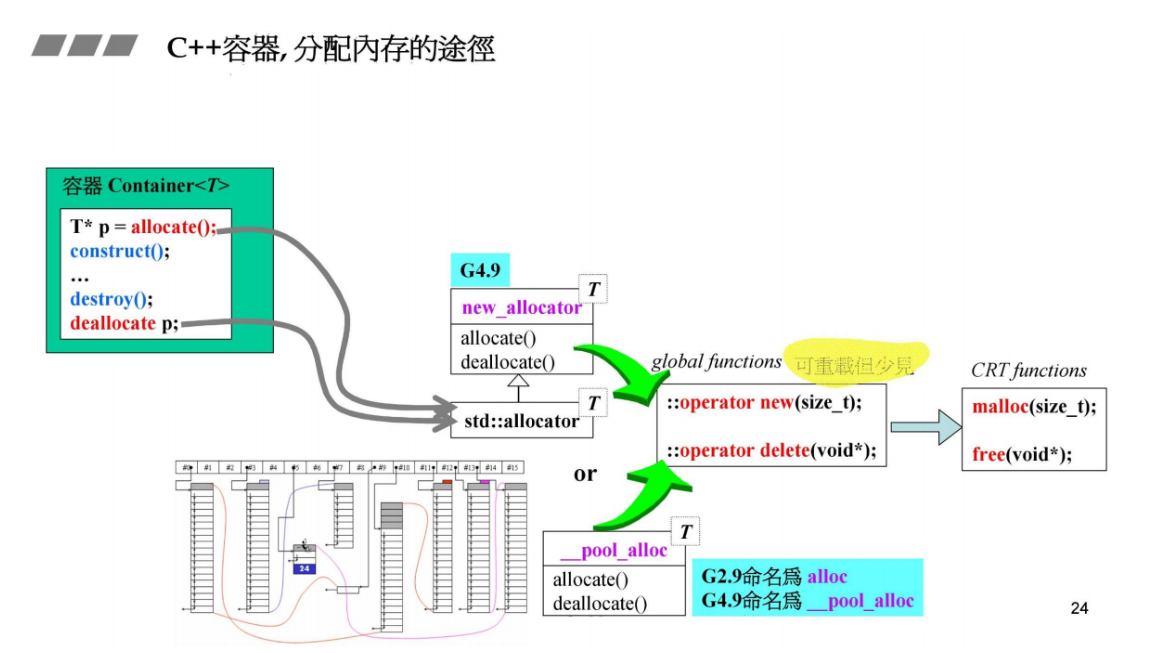
在 C++ 中,容器使用分配器(Allocator)来进行内存分配和释放。分配器是负责管理容器内部元素内存的组件。下面是容器分配内存的一般途径:
-
容器使用分配器:
- C++ 容器(如
std::vector、std::list、std::map等)通常使用分配器来分配和释放内存。分配器是容器的一部分,负责处理元素的内存分配和释放操作。
- C++ 容器(如
-
分配器调用
::operator new和::operator delete:- 分配器的实现通常会调用全局作用域下的
::operator new来分配内存,并在需要释放内存时调用::operator delete。 ::operator new和::operator delete是 C++ 中的全局内存分配和释放函数。它们底层可能调用标准库的malloc和free。
- 分配器的实现通常会调用全局作用域下的
-
底层可能调用
malloc和free:malloc和free是 C 标准库中的内存分配和释放函数,用于分配和释放原始的、未构造的内存块。C++ 的::operator new和::operator delete可能在底层调用这些函数。
总体来说,C++ 容器使用分配器来管理内存,而分配器可能在其实现中调用 ::operator new 和 ::operator delete,从而涉及到底层的内存分配函数 malloc 和 free。这种设计允许用户自定义容器的内存管理行为,以适应不同的需求。用户可以通过提供自定义分配器来实现特定的内存分配策略。
重载全局的::operator new 和::operator delete
由于是全局的函数,这个影响很大。
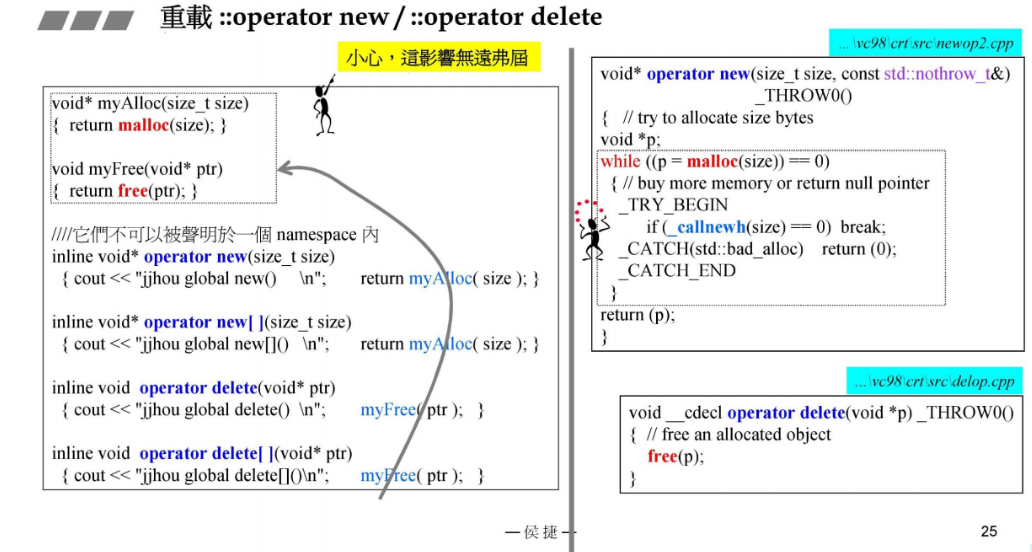
在一个类中重载operator new和operator delete
类内部重载之后,编译器会来调用
同样的道理,也可以重载operator new[] 和operator delete[]
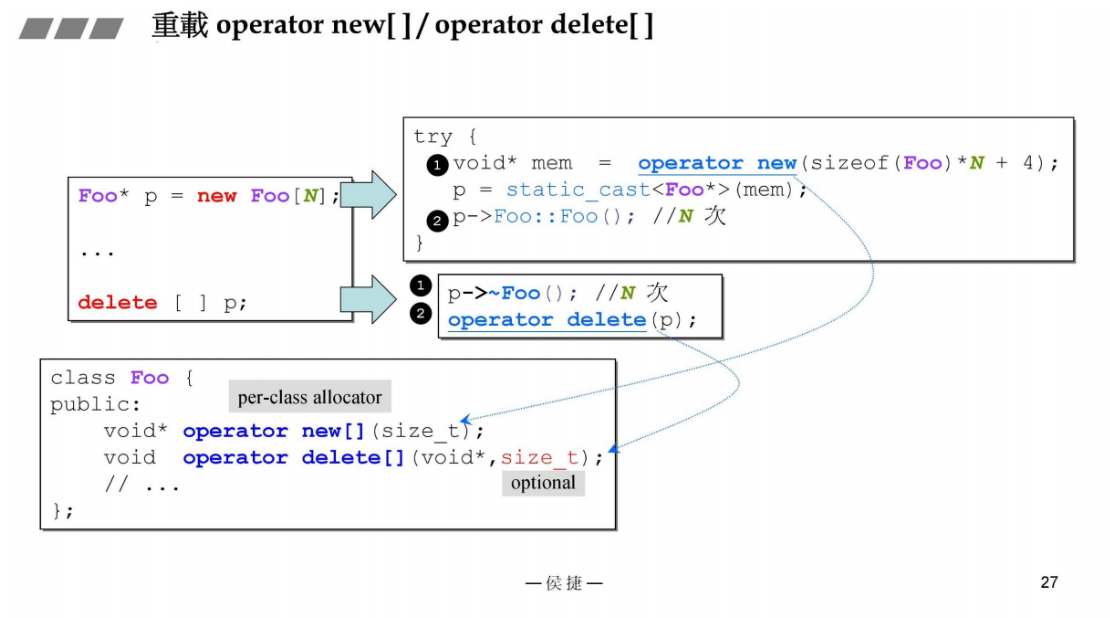
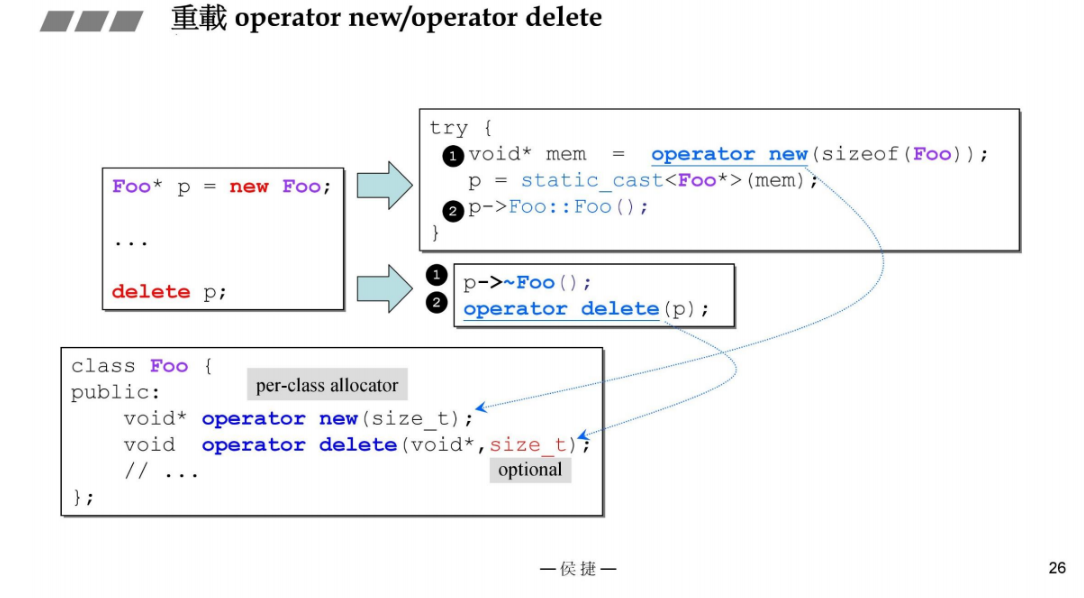
10 重载示例(上)
类内部重载上述4种操作的接口如下所示:
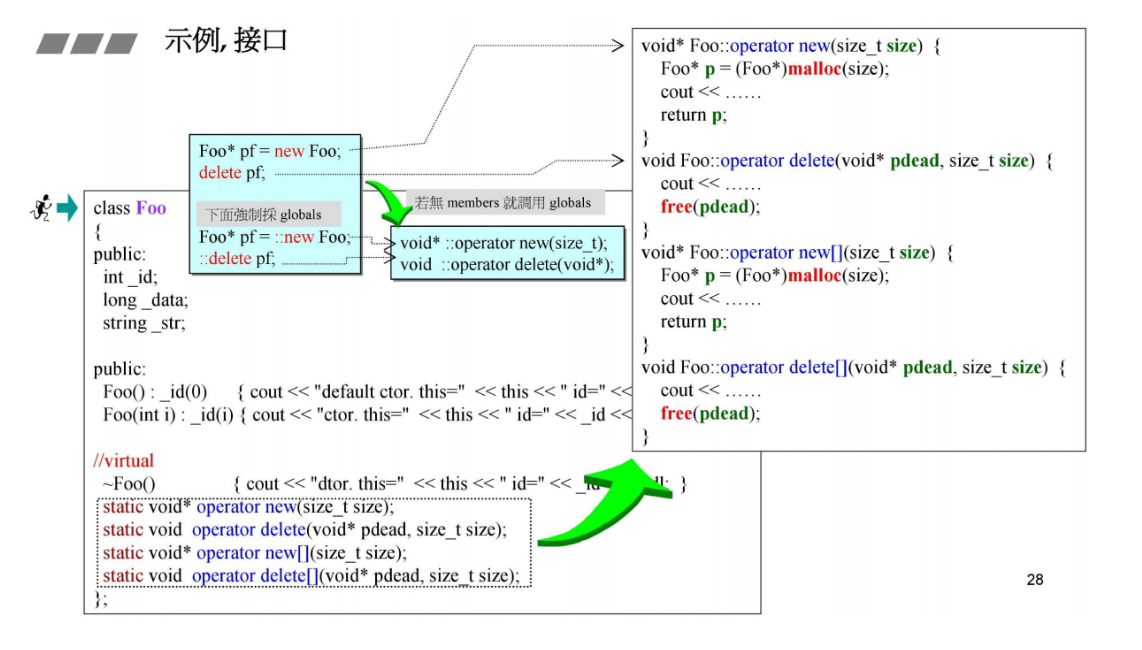
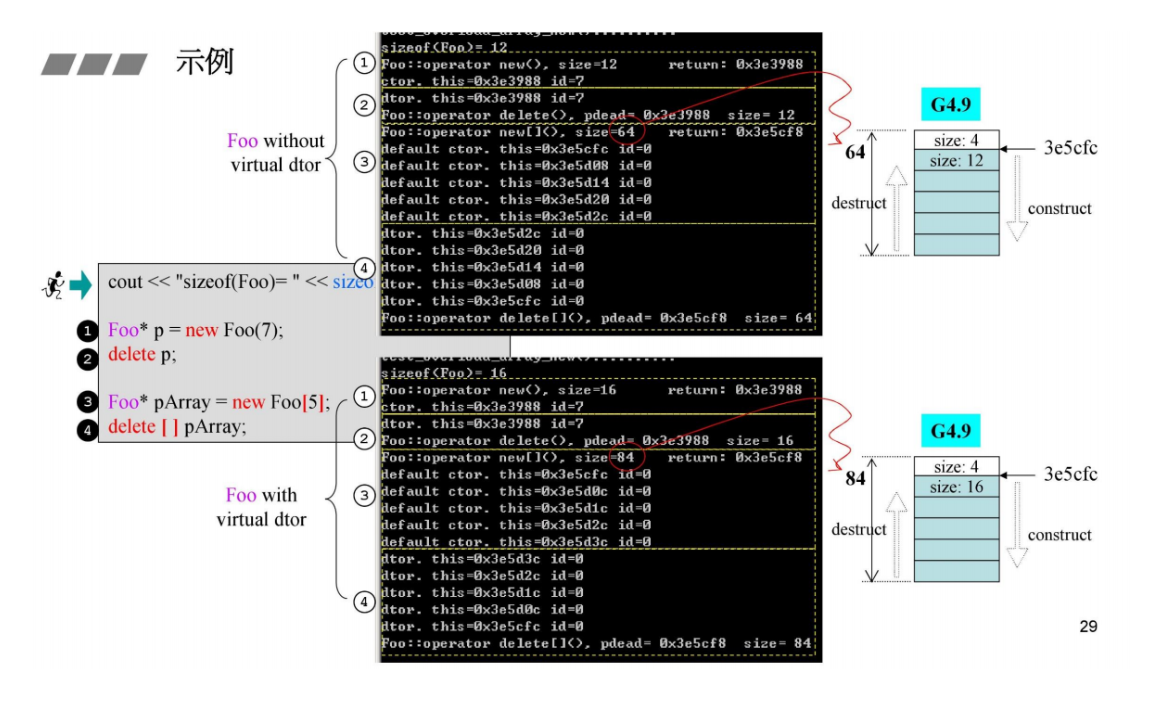
测试上述一个类中重载new,delete, new[], delete[]的用法
下图右侧可以看到,在GNU C++4.9版本中构造是从上到下,析构是从下到上。
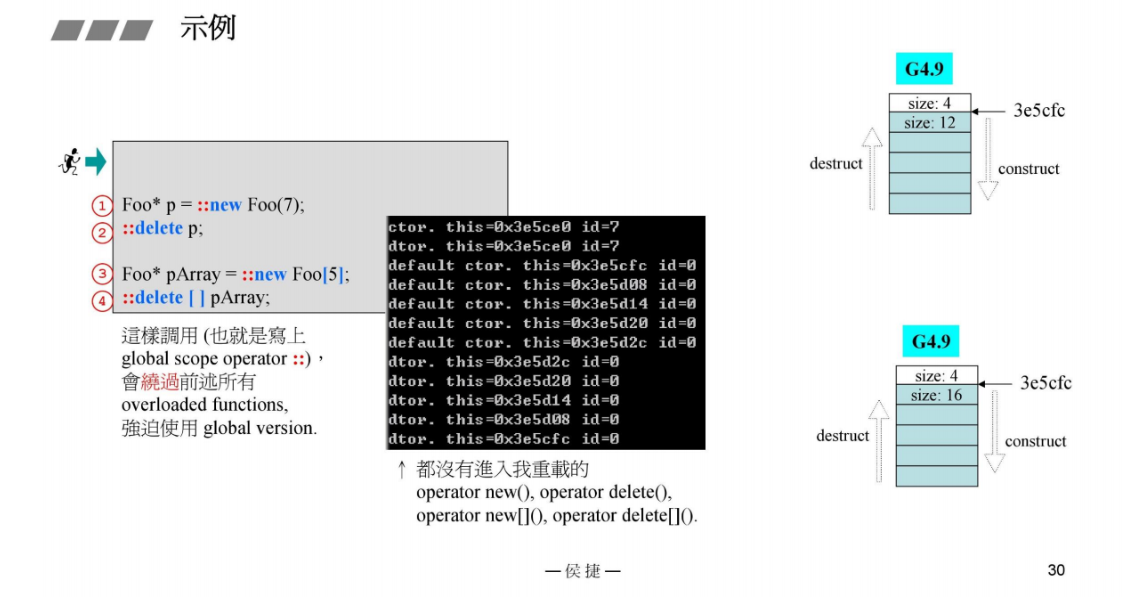
下面是使用全局new和delete的测试
11 重载示例(下)
placement new的重载,new() 和 delete()

placement new的重载第一参数必须是size_t类型
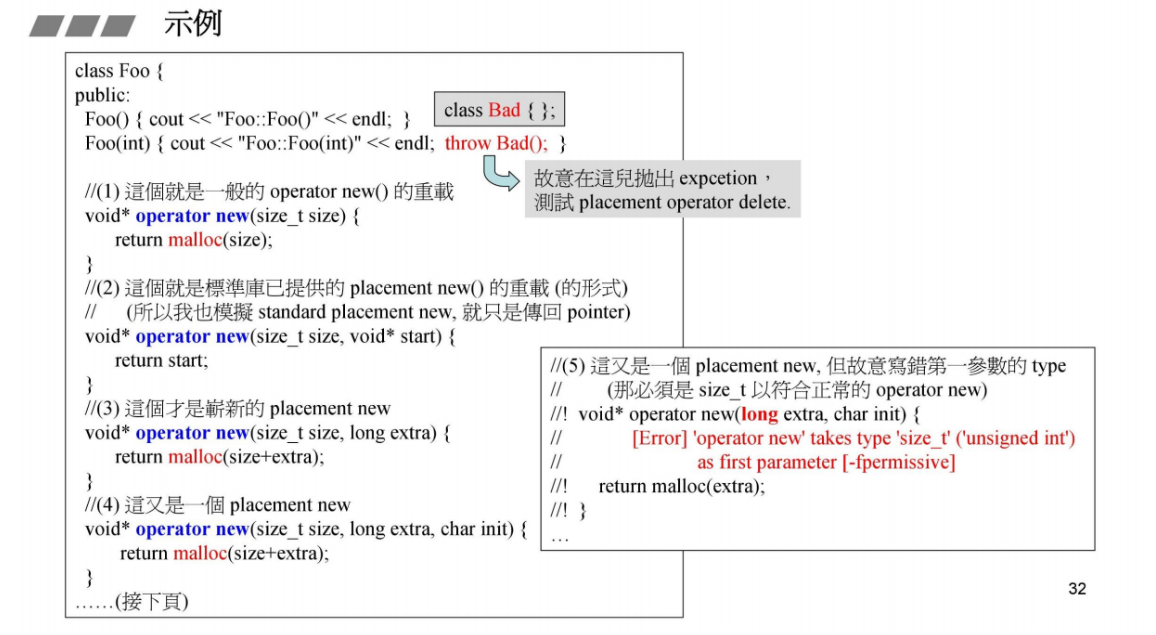
对于如何区分operator new 和 placement new,就要看调用的时候怎么用了。在调用时,编译器会根据传递给 new 表达式的参数来匹配适当的重载版本。

测试代码
#include <vector> //for testnamespace jj07
{class Bad { };
class Foo
{
public:Foo() { cout << "Foo::Foo()" << endl; }Foo(int) { cout << "Foo::Foo(int)" << endl; // throw Bad(); }//(1) 這個就是一般的 operator new() 的重載 void* operator new(size_t size) {cout << "operator new(size_t size), size= " << size << endl;return malloc(size); }//(2) 這個就是標準庫已經提供的 placement new() 的重載 (形式)// (所以我也模擬 standard placement new 的動作, just return ptr) void* operator new(size_t size, void* start) { cout << "operator new(size_t size, void* start), size= " << size << " start= " << start << endl;return start;}//(3) 這個才是嶄新的 placement new void* operator new(size_t size, long extra) { cout << "operator new(size_t size, long extra) " << size << ' ' << extra << endl;return malloc(size+extra);}//(4) 這又是一個 placement new void* operator new(size_t size, long extra, char init) { cout << "operator new(size_t size, long extra, char init) " << size << ' ' << extra << ' ' << init << endl;return malloc(size+extra);}//(5) 這又是一個 placement new, 但故意寫錯第一參數的 type (它必須是 size_t 以滿足正常的 operator new)
//! void* operator new(long extra, char init) { //[Error] 'operator new' takes type 'size_t' ('unsigned int') as first parameter [-fpermissive]
//! cout << "op-new(long,char)" << endl;
//! return malloc(extra);
//! } //以下是搭配上述 placement new 的各個 called placement delete. //當 ctor 發出異常,這兒對應的 operator (placement) delete 就會被喚起. //應該是要負責釋放其搭檔兄弟 (placement new) 分配所得的 memory. //(1) 這個就是一般的 operator delete() 的重載 void operator delete(void*,size_t){ cout << "operator delete(void*,size_t) " << endl; }//(2) 這是對應上述的 (2) void operator delete(void*,void*){ cout << "operator delete(void*,void*) " << endl; }//(3) 這是對應上述的 (3) void operator delete(void*,long){ cout << "operator delete(void*,long) " << endl; }//(4) 這是對應上述的 (4) //如果沒有一一對應, 也不會有任何編譯報錯 void operator delete(void*,long,char){ cout << "operator delete(void*,long,char) " << endl; }private:int m_i;
};//-------------
void test_overload_placement_new()
{cout << "\n\n\ntest_overload_placement_new().......... \n";Foo start; //Foo::FooFoo* p1 = new Foo; //op-new(size_t)Foo* p2 = new (&start) Foo; //op-new(size_t,void*)Foo* p3 = new (100) Foo; //op-new(size_t,long)Foo* p4 = new (100,'a') Foo; //op-new(size_t,long,char)Foo* p5 = new (100) Foo(1); //op-new(size_t,long) op-del(void*,long)Foo* p6 = new (100,'a') Foo(1); //Foo* p7 = new (&start) Foo(1); //Foo* p8 = new Foo(1); ////VC6 warning C4291: 'void *__cdecl Foo::operator new(unsigned int)'//no matching operator delete found; memory will not be freed if//initialization throws an exception
}
} //namespace
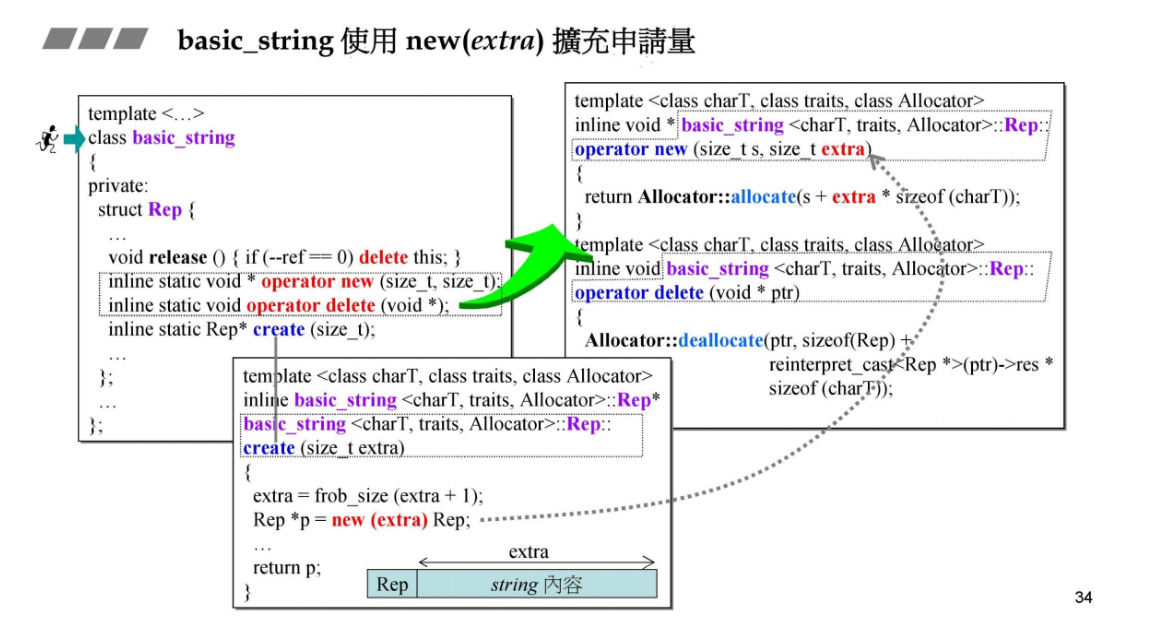
basic_string使用new(extra)扩充申请量
重载了operator new,其实是placement new。因为用法为new(extra) Rep;
12 Per class allocator
内存池是一种用于管理和分配内存的机制,它可以提高内存分配的效率,减少内存碎片,并降低动态内存分配的开销。在 C++ 中,内存池通常通过重载 operator new 和 operator delete 来实现。
下面简要描述一下内存池的概念,并提供一个简单的示意图:
-
内存池概念:
- 内存池是一块预先分配的内存区域,它被划分为多个小块,每个小块可以被分配给程序使用。
- 内存池通常由一个或多个链表、堆栈或其他数据结构来管理,以追踪哪些内存块是空闲的,哪些是已分配的。
- 内存池的目的是减少因频繁的内存分配和释放而引起的性能开销。
-
示意图:
+------------------------------------+ | Memory Pool | +------------------------------------+ | Free Block 1 | Free Block 2 | +------------------+-----------------+ | Allocated Block 1 | +------------------------------------+ | Free Block 3 | Free Block 4 | +------------------+-----------------+- 上面的示意图展示了一个简单的内存池,其中包含多个内存块,有一些是空闲的,有一些是已经分配给程序使用的。
- 每个内存块的大小可能不同,取决于内存池的设计。
- 空闲的内存块可以通过链表或其他数据结构连接在一起,以便快速分配。
-
内存池的操作:
- 当程序需要分配内存时,内存池会从空闲块中选择一个合适的块分配给程序。
- 当程序释放内存时,将相应的内存块标记为空闲,并重新加入空闲块链表,以便下次分配使用。
-
自定义内存池的示例:
class MemoryPool { private:struct Block {size_t size;Block* next;};Block* freeList;public:MemoryPool(size_t poolSize) {// 初始化内存池void* memory = ::operator new(poolSize);freeList = static_cast<Block*>(memory);freeList->size = poolSize;freeList->next = nullptr;}void* allocate(size_t size) {// 从内存池中分配内存if (!freeList || freeList->size < size) {// 内存不足,或者没有空闲块,可以根据实际情况扩展内存池return nullptr;}Block* allocatedBlock = freeList;freeList = freeList->next;return static_cast<void*>(allocatedBlock);}void deallocate(void* ptr) {// 释放内存到内存池Block* block = static_cast<Block*>(ptr);block->next = freeList;freeList = block;} };上述示例为了简洁,省略了一些内存池的管理细节,实际的内存池实现可能需要更复杂的数据结构和算法。
引入内存池的考量:
很多new要分配内存,用malloc分配一大块(内存池),然后分成小块,减少malloc的调用次数。
另外,想要减少cookie的用量。
下面是对类Screen进行内存设置的例子,这里是设计的第一版本
在Screen类中引入一个指针next,它的大小是4B,用于串联链表。如下图所示
再看一下delete操作,把指针p回收到单向链表中,放到链表的头指针位置

看看怎么使用自定义的内存分配模式:
如下图右侧所示,左边间隔8表示每个Screen对象内存分配的大小为8B,说明每个Screen分配的时候没有cookie。
右边间隔16,表示每个Screen对象内存分配的大小为16B,这是因为对象分配的时候上下加了cookie,最上面和最下面的cookie大小共为8B。

下面是测试代码
#include <cstddef>
#include <iostream>
namespace jj04
{
//ref. C++Primer 3/e, p.765
//per-class allocator class Screen {
public:Screen(int x) : i(x) { };int get() { return i; }void* operator new(size_t);void operator delete(void*, size_t); //(2)
//! void operator delete(void*); //(1) 二擇一. 若(1)(2)並存,會有很奇怪的報錯 (摸不著頭緒) private:Screen* next;static Screen* freeStore;static const int screenChunk;
private:int i;
};
Screen* Screen::freeStore = 0;
const int Screen::screenChunk = 24;void* Screen::operator new(size_t size)
{Screen *p;if (!freeStore) {//linked list 是空的,所以攫取一大塊 memory//以下呼叫的是 global operator newsize_t chunk = screenChunk * size;freeStore = p =reinterpret_cast<Screen*>(new char[chunk]);//將分配得來的一大塊 memory 當做 linked list 般小塊小塊串接起來for (; p != &freeStore[screenChunk-1]; ++p)p->next = p+1;p->next = 0;}p = freeStore;freeStore = freeStore->next;return p;
}//! void Screen::operator delete(void *p) //(1)
void Screen::operator delete(void *p, size_t) //(2)二擇一
{//將 deleted object 收回插入 free list 前端(static_cast<Screen*>(p))->next = freeStore;freeStore = static_cast<Screen*>(p);
}//-------------
void test_per_class_allocator_1()
{ cout << "\ntest_per_class_allocator_1().......... \n"; cout << sizeof(Screen) << endl; //8 size_t const N = 100;
Screen* p[N]; for (int i=0; i< N; ++i)p[i] = new Screen(i); //輸出前 10 個 pointers, 用以比較其間隔 for (int i=0; i< 10; ++i) cout << p[i] << endl; for (int i=0; i< N; ++i)delete p[i];
}
} //namespace
13 Per class allocator 2
设计类里面的allocator的第二版本
这里和第一版本的最大不同是设计上采用union
在C++中,union 是一种特殊的数据结构,允许在相同的内存位置存储不同类型的对象。它的每个成员共享相同的内存空间,只能同时使用一个成员。union 提供了一种有效利用内存的方式。
struct AirplaneRep {unsigned long miles; // 4Bchar type; // 1B// 由于对齐,这5B会变成8B
};
union {AirplaneRep rep;Airplane* next;
}

下面是重载operator delete,然后是测试结果
间隔8和间隔16解释同allocator, 1。

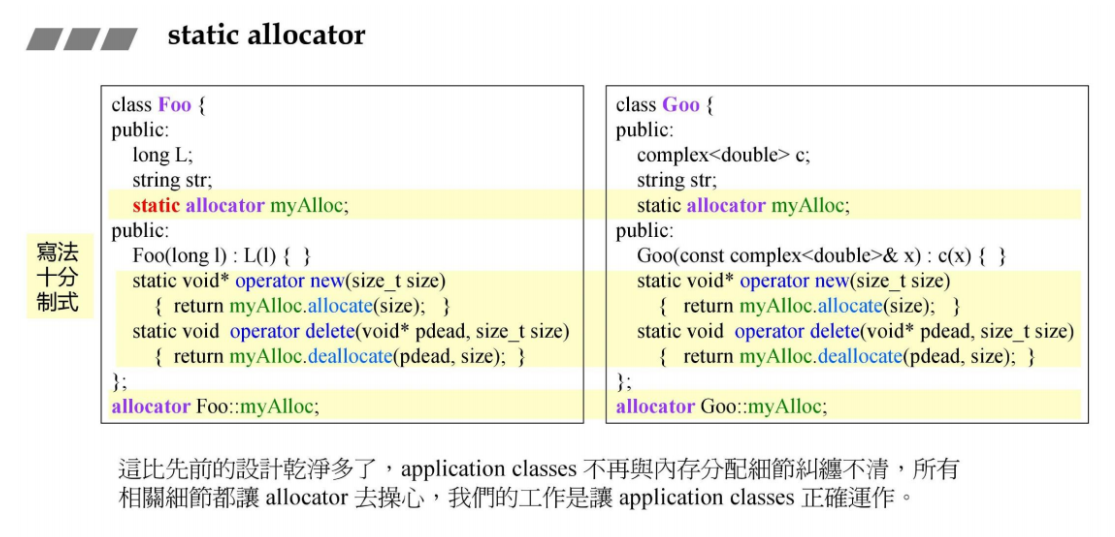
14 Static allocator
下面是内存分配的第三版本
从软件工程的角度看,上面的operator new和operator delete对于不同 类都要重载,明显不是一个好的解法,下面是将allocator抽象成一个类。
allocator类中定义allocate和deallocate函数,用于分配和回收。
下图中右侧是具体的实现,这里每次分配CHUNK个大小的一大块,然后切割成小块,用链表串起来。

具体的类进行内存分配的时候,只需要调用allocator即可
具体的测试如下:由于上面的CHUNK设置为5,可以看到下图右侧部分,每5个对象的内存空间是连续的(间隔都是一个对象的大小),而每个大块之间是不连续的。

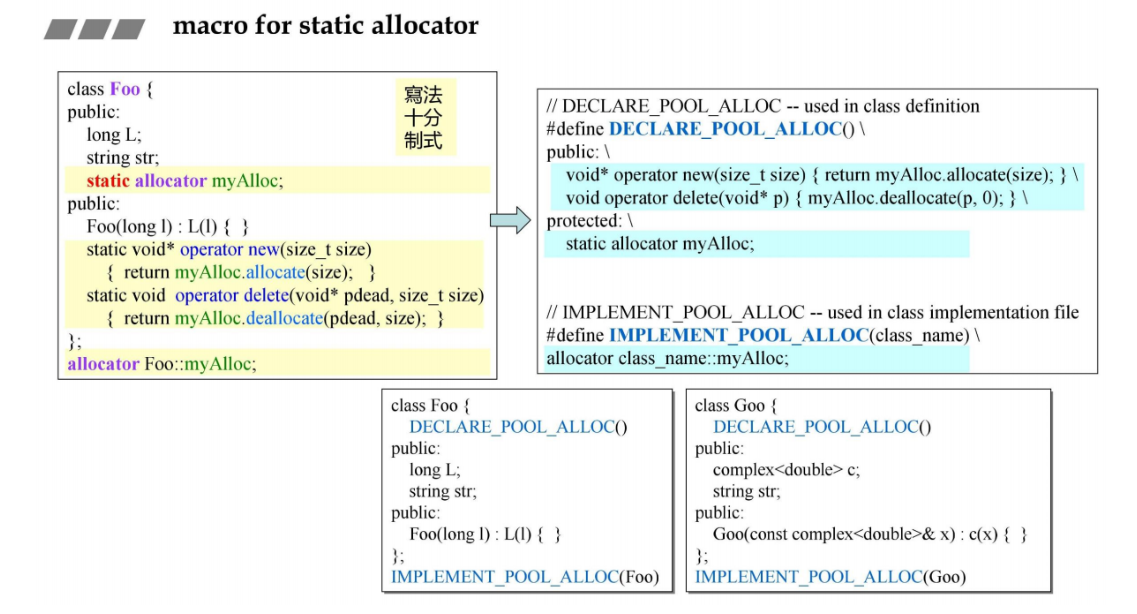
15 Macro for static allocator
下面是类分配内存的第四个版本:使用macro。
把allocator的部分拿出来用宏来定义
在C++中,宏(macro)是一种预处理指令,用于在编译过程中执行文本替换。宏通常通过 #define 关键字定义,并在代码中通过宏名称来调用。它们是一种简单的文本替换机制,可以用于创建常量、函数替代、条件编译等。
在宏定义的末尾使用反斜杠是为了告诉编译器该宏定义将在下一行继续。如果在宏定义的最后一行没有使用反斜杠,那么编译器会认为宏定义结束了。
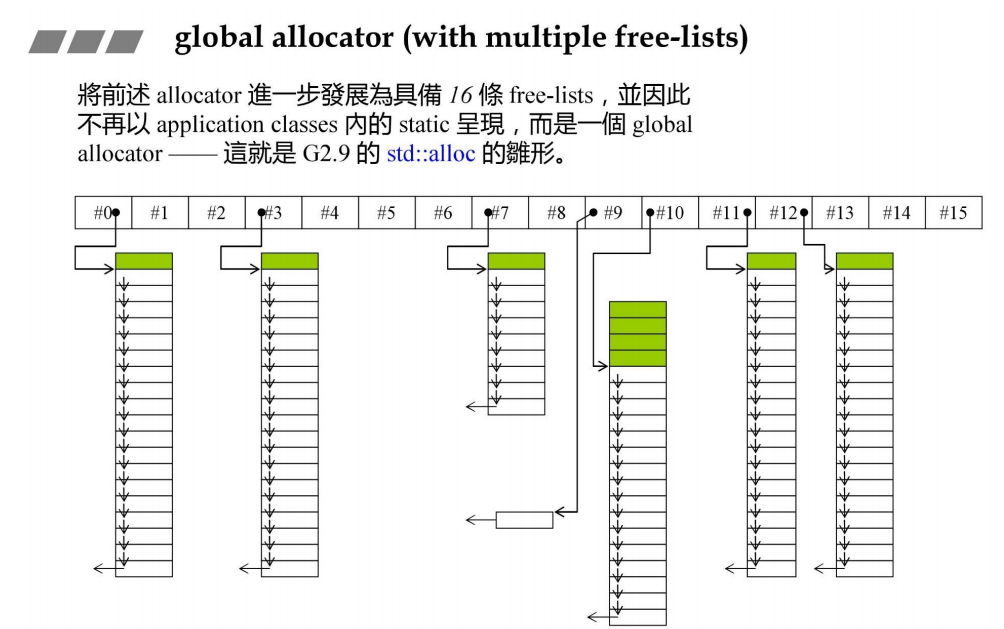
标准库中的allocator
其中一种分配器有16条自由链表,来应对不同大小的块分配,不同的大小的类对象,分配到不同的链表中。
16 New Handler
new handler
new handler 是一个与 C++ 内存分配和 new 操作符相关的概念。它是一个函数指针,指向一个用户定义的函数,该函数负责处理 new 操作符无法满足内存分配请求时的情况。
当 new 操作符无法分配所需的内存时,它会调用与之关联的 new handler。new handler 可以执行一些操作,例如释放一些已分配的内存、尝试扩展堆的大小、选择性地抛出异常,或者执行其他用户定义的操作。
使用 set_new_handler 函数设置 new handler:
#include <new>
#include <iostream>void customNewHandler() {std::cerr << "Memory allocation failed! Custom new handler called." << std::endl;std::terminate(); // 终止程序或者执行其他处理
}int main() {std::set_new_handler(customNewHandler);// 尝试分配大块内存int* arr = new int[1000000000000]; // 如果分配失败,会调用 customNewHandlerreturn 0;
}
在上述示例中,通过 set_new_handler 函数设置了一个自定义的 new handler,即 customNewHandler。当 new 操作符在尝试分配非常大的内存块时失败,会调用这个自定义的 new handler。
注意事项:
new handler是全局的,一旦设置,会在程序的生命周期内一直有效,直到被其他set_new_handler覆盖。- 如果
new handler返回,new操作符会再次尝试分配内存,如果还失败,则再次调用new handler。这个过程会一直重复,直到new handler抛出异常或者不返回(例如调用std::terminate())。 - 在 C++11 及以后的版本中,可以使用
std::get_new_handler获取当前的new handler,以便在需要时进行保存和恢复。
使用 new handler 可以提供一些灵活性,允许程序员在内存分配失败的情况下采取定制的操作,而不是默认的行为(即抛出 std::bad_alloc 异常)。

set_new_handler的例子
在C++中,=default 和 =delete 是两个特殊的关键字,用于指定和控制类的特殊成员函数的生成和使用。
-
=default:=default用于显式要求编译器生成默认实现的特殊成员函数(默认构造函数、复制构造函数、移动构造函数、复制赋值运算符、移动赋值运算符、析构函数)。- 通过
=default,可以确保编译器生成的函数符合默认行为,并且可以通过显式声明而不定义的方式,将这些函数声明为“使用默认实现”。 - 示例:
class MyClass { public:// 使用默认实现的特殊成员函数MyClass() = default; // 默认构造函数MyClass(const MyClass&) = default; // 复制构造函数MyClass(MyClass&&) = default; // 移动构造函数MyClass& operator=(const MyClass&) = default; // 复制赋值运算符MyClass& operator=(MyClass&&) = default; // 移动赋值运算符~MyClass() = default; // 析构函数 };
-
=delete:-
=delete用于删除特殊成员函数或其他函数的默认实现,使得在某些情况下,编译器将会拒绝生成默认实现。 -
通过
=delete,可以防止某些函数的调用,或者阻止生成某些函数。 -
示例:
class NoCopyClass { public:NoCopyClass() = default; // 默认构造函数// 禁止复制构造和复制赋值NoCopyClass(const NoCopyClass&) = delete;NoCopyClass& operator=(const NoCopyClass&) = delete; }; -
在上述示例中,通过
=delete明确禁止了复制构造和复制赋值,使得这个类无法被复制。
-
这两个关键字的使用使得代码更加明确,能够更好地表达程序员的意图,并且在一些情况下,可以帮助编译器进行更好的优化。=default 和 =delete 主要用于提高代码的清晰性、安全性和性能。
下图中的一句话:=default,=delete可以用于operator new/ new[], operator delete/ delete[]以及它们的重载。

对operator new/ new[], operator delete/ delete[]的测试:使用=default, = delete

后记
花费一天的时间完成《C++内存管理——从平地到万丈高楼》第一讲的学习,对C++内存分配有了浅显的认识,希望跟着侯捷老师后续的讲解,逐渐加深对C++内存分配的理解。