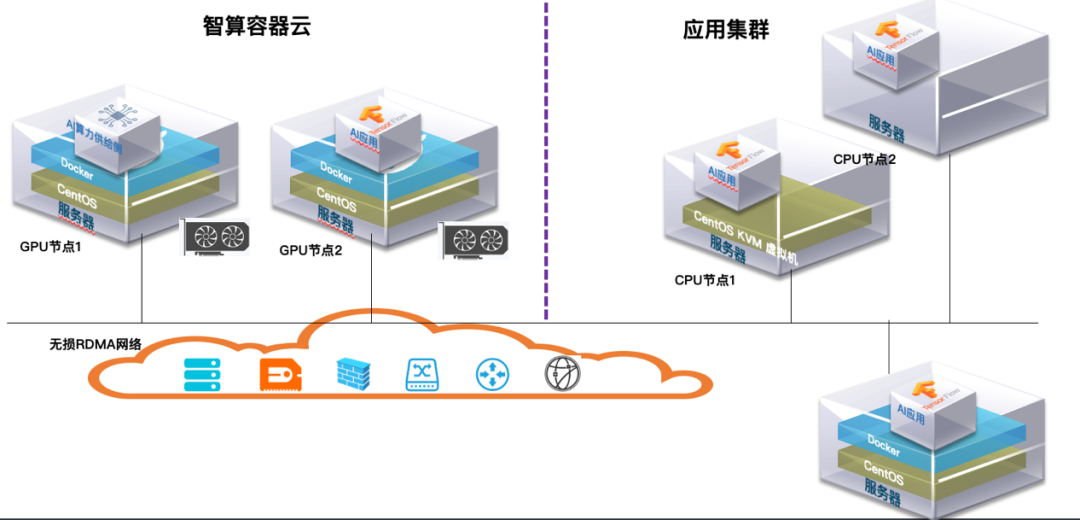
1 简介
简称:CNN,convolutional neural network
应用场景:图像识别与分类(CNN),看图说话(CNN+RNN)等
优越性:和多层感知机相比,cnn可以识别独特的模式,可以自动从数据中提取特征。一般机器学习需要特征工程,cnn可以自动识别,极大代替或取代了特征工程
和多层感知机原理不同点:层包含卷积层,池化层。但也是一种前馈神经网络
输入与输出:输入可为图像,输出为目标分类个数(比如图像目标分5类,则输出可定义有5个输出单元)
2 概念
用例子说明:识别图像里的数字是几,数字0-9,用cnn,则输出有10个单元,输入image为28x28像素彩色图片,每个像素为0-255的灰度值
2.1 识别手写数字流程简介

可简单理解为从一个图像提取出多个简单的小图像(因为要模式识别,多个模式,提取特征),然后从这些小图像输出预测
第一层卷积运算后,变成了28x28x4的结果,可以理解为4张28x28的图像
第二层池化运算后,变成了14x14x4的结果,可理解为4张14x14的图像(变小了)(卷积和池化运算原理后面说)
第二层卷积和池化类似,卷积后图像多了,池化后尺寸小了
第五层可理解为将第四层池化运算后的结果拉伸为1维向量(可以看成特征)
第六层为感知机的隐层,经过隐层计算得到输出。本例为分类问题,输出为各分类概率,加和为1
cnn和mlp(多层感知机)工作流程也一样,包括前馈运算和反馈学习阶段(比如梯度下降)。
2.2 卷积运算
卷积是数学概念,定义为一个卷积核函数在输入信号上序列化的积分计算,比较抽象,看个例子
卷积运算原理和人眼识别物体原理差不多。比如一个图片有很多物品,目标找到图片中所有的鞋子,人眼判断会经历这些流程:1扫描图片:需要看完整个图片,才能知道有多少鞋子 2模式识别,人眼能看出鞋子是因为大脑知道鞋子长什么样,脑海会有一个关于鞋子的模板图案 3模式匹配:扫描图片过程,当看到和鞋子模式高度匹配的地方,就记下这个位置的下标。扫描完成后,所有下标所在位置大概率会有鞋子
卷积核可以看作上例中的鞋子模板,鞋子模板和原始图像匹配的结果叫特征图,是一个二维的灰度图,再看个书里的例子
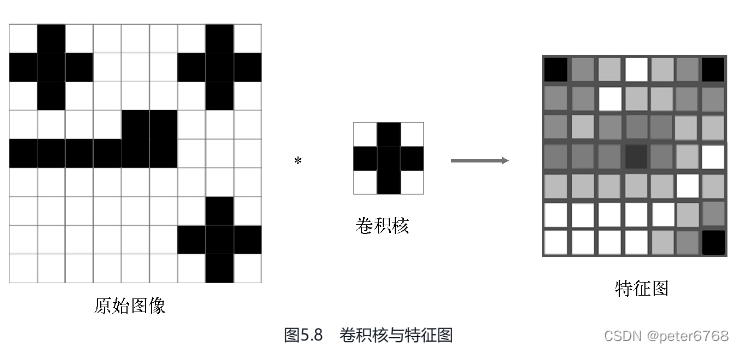
2.2.1 数学上的卷积运算
接上图,用一个卷积核扫描完原始图像一遍,即可看作完成一次卷积运算
卷积运算结果是特征图尺寸会比原始图像尺寸小,如果不像让特征图尺寸变化,可以在原始图像四周加padding(边距)
可以用多个卷积核(多个模式)对原始图像识别,对应会有数量和卷积核数量相等的特征图生成
卷积运算会越来越小,是因为特征图有一定尺寸,经过卷积运算就会减小
卷积运算越来越厚是因为模式(或特征,或卷积核)越来越多,比如需要从图像识别出多个类别的有用信息
2.3 池化运算
可以理解为对卷积运算得到的特征图取粗粒度信息。即以一定尺寸窗口对特征图扫描,将窗口对应的像素进行运算,比如有取最大,取平均等运算。和卷积不同的是,池化运算的扫描是无重叠的扫描。
比如对一个图像的首行进行取最大池化运算:

2.4 立体卷积核
对于第二个卷积层,其输入是有厚度的特征图。此时如何选择第二层卷积层的卷积核?卷积核需要有核输入特征图厚度一致的卷积核,然后窗口大小自己取。此时卷积核变成一个三维的长方体
2.5 超参数与参数
超参数:即训练过程人为指定值的参数,不会变化的参数,比如网络层数,每层神经元个数,都是训练前指定好的
参数数量和mlp相比:参数数量少很多,如果mlp全连接,因为笛卡积会导致参数很多
池化层没参数:只有固定的运算,指定窗口大小,除此之外不需要参数
2.6 其他
2.6.1 反向传播算法
cnn也用反向传播算法(BP),怎么使用:只要可微分,就可以用pytorch的backward反向求导
cnn优越性在哪:1 可实现各种图像运算。比如锐化,模糊图像,都可看作特定权重的cnn运算。也就是说,可以用cnn实现图像运算 2 池化运算可以提取大尺度特征,可以理解为整体特征(一座山在山里看不到山全貌,离开山离远点可以看全貌,就指这个全貌)。整体特征可以帮神经网络从整体上把握分类。
可以参考教材里一张图
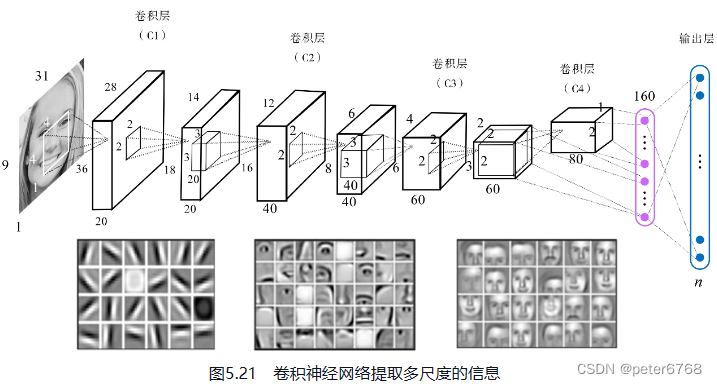
3 手写数字识别器
3.1 准备
导入相关库,定义超参数
import torch
from torch import nn
from torch import optim
from torch.nn import functional as Fimport torchvision.datasets
import torchvision.transformsimport matplotlib.pyplot
import numpy as npclass CNN():def exec(self):self.prepare()def prepare(self):self.prepare_params()self.prepare_data()def prepare_params(self):self.image_size = 28self.num_classes = 10self.num_epochs = 20self.batch_size = 64if __name__ == '__main__':CNN.exec()3.2 数据准备
pytorch也有自带的数据,比如这个手写数据集(MNIST)
import torch
from torch import nn
from torch import optim
from torch.nn import functional as Ffrom torchvision import datasets
from torchvision import transformsfrom matplotlib import pyplot
import numpy as npclass CNN():def exec(self):self.prepare()self.test_show()def prepare(self):self.prepare_params()self.prepare_data()def prepare_params(self):print('begin prepare params')self.image_size = 28self.num_classes = 10self.num_epochs = 20self.batch_size = 64def prepare_data(self):print('begin prepare data')self.train_data = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)self.test_data = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())indices = range(len(self.test_data))self.indices_verify = indices[:5000]self.indices_test = indices[5000:] self.sampler_verify = torch.utils.data.sampler.SubsetRandomSampler(self.indices_verify)self.sampler_test = torch.utils.data.sampler.SubsetRandomSampler(self.indices_test)self.train_loader = torch.utils.data.DataLoader(dataset=self.train_data, batch_size=self.batch_size, shuffle=True)self.validation_loader = torch.utils.data.DataLoader(dataset=self.test_data, batch_size=self.batch_size, shuffle=False, sampler=self.sampler_verify)self.test_loader = torch.utils.data.DataLoader(dataset=self.test_data, batch_size=self.batch_size, shuffle=False, sampler=self.sampler_test)def test_show(self):print('begin test show')index = 200img_np = self.train_data[index][0].numpy()pyplot.imshow(img_np[0, ...])pyplot.show()if __name__ == '__main__':CNN().exec()
dataloader用途:1 批量加载数据 2 数据太多加载不到内存时,可用dataloder批量加载
sampler用途:可以按指定顺序从数据集获取数据批次

3.3 构建网络
调用torch.nn.Module构造cnn。
先构造ConvNet类,其父类是nn.Module,因为父类包含很多神经网络通用计算方法
再重写__init__()和forward()函数。forward在网络正向运行时会被自动调用,负责数据前传,并构造计算图
其三,定义retrieve_features()函数,可提取网络中各个卷积层权重,分析神经网络时会用到
class ConCNN(nn.Module):def __init__(self):super(ConCNN, self).__init__()self.depth = [4, 8] # number of conv core in every layerself.conv1 = nn.Conv2d(1, 4, 5, padding=2)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(self.depth[0], self.depth[1], 5, padding=2)self.fc1 = nn.Linear((image_size // 4)**2 * self.depth[1], 512)self.fc2 = nn.Linear(512, num_classes)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.pool(x)x = self.conv2(x)x = F.relu(x)x = self.pool(x)x = x.view(-1, (image_size // 4)**2 * self.depth[1])x = F.relu(self.fc1(x))x = F.dropout(x, training=self.training)x = self.fc2(x)x = F.log_softmax(x, dim=1)return xdef retrieve_features(self, x):feature_map1 = F.relu(self.conv1(x))x = self.pool(feature_map1)feature_map2 = F.relu(self.conv2(x))return feature_map1, feature_map2forward中用到dropout用途:神经网络常会出现过拟合,dropout可减弱此现象。思想是每次训练按一定概率随机丢弃一些神经元进行训练,最后在泛化测试时再用所有神经元

3.4 运行模型
if __name__ == '__main__':cnn_util = CNNUtil()cnn = CNN()cost = nn.CrossEntropyLoss()optimizer = optim.SGD(cnn.parameters(), lr=0.01, momentum=0.9)record, weights = [], []for epoch in range(num_epochs):train_rights = []for batch_index, (data, target) in enumerate(cnn_util.train_loader):data, target = data.clone().requires_grad_(True), target.clone.detach()cnn.train()output = cnn(data)loss = cost(output, target)optimizer.zero_grad()loss.backward()optimizer.step()right = rightness(output, target)train_rights.append(right)if batch_index % 1000 == 0:cnn.eval()val_rights = []for (data, target) in cnn_util.validation_loader:data, target = data.clone().requires_grad_(True), target.clone.detach()output = cnn(data)right = rightness(output, target)val_rights.append(right)train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))print(f'no.{epoch}, {batch_index*len(data)}/{len(cnn_util.train_loader.dataset)}')print(f'loss:{loss.data}, train accu:{train_r[0]/train_r[1]}, verify accu:{val_r[0]/val_r[1]}')record.append((100 - 100 * train_r[0] / train_r[1], 100 - 100 * val_r[0] / val_r[1]))weights.append([cnn.conv1.weight.data.clone(), cnn.conv1.bias.data.clone(), cnn.conv2.weight.data.clone(), cnn.conv2.bias.data.clone()])其中,cnn.train()和cnn.eval()用来打开和关闭所有dropout层。因为dropout可以在训练时关闭,在验证和测试时打开

3.5 测试模型
cnn.eval()vals = []for data, target in cnn_util.test_loader:data, target = data.clone().detach().requires_grad_(True), target.clone().detach()output = cnn(data)val = rightness(output, target)vals.append(val)rights = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals]))right_rate = rights[0] / rights[1]print(f'test scores:{right_rate}')# plotpyplot.figure(figsize=(10, 7))pyplot.plot(record)pyplot.xlabel('steps')pyplot.ylabel('error rate')pyplot.show()

4 分析CNN
4.1 第一层卷积核与特征图
print('plot conv1 cores')pyplot.figure(figsize=(8, 6))for i in range(4):pyplot.subplot(1, 4, i + 1)pyplot.imshow(cnn.conv1.weight.data.numpy()[i, 0, ...])pyplot.show()
看不太懂,随便找一张图片(index=1000,数字9),看下图片对应的特征图
index = 1000input_x = cnn_util.test_data[index][0].unsqueeze(0)feature_maps = cnn.retrieve_features(input_x)pyplot.figure(figsize=(8, 6))for i in range(4):pyplot.subplot(1, 4, i + 1)pyplot.imshow(feature_maps[0][0, i, ...].data.numpy())pyplot.show()
看着像是模糊相关的处理
4.2 第二层卷积核与特征图
pyplot.figure(figsize=(15, 10))for i in range(4):for j in range(8):pyplot.subplot(4, 8, i * 8 + j + 1)pyplot.imshow(cnn.conv2.weight.data.numpy()[j, i, ...])pyplot.show()
因为第一层卷积层输出四个特征图,所以对第二个卷积层来说,一个卷积层有4个厚度,即有4个在第一个卷积层的卷积核。
# plot conv2 feature mappyplot.figure(figsize=(8, 6))for i in range(8):pyplot.subplot(2, 4, i + 1)pyplot.imshow(feature_maps[1][0, i, ...].data.numpy())pyplot.show()
更抽象了
4.3 cnn健壮性实验
先训练,完了找一个原图像平移,验证cnn是否可识别出平移后的数字是几
发现抗干扰很好,特征图基本与不平移相比没什么变化