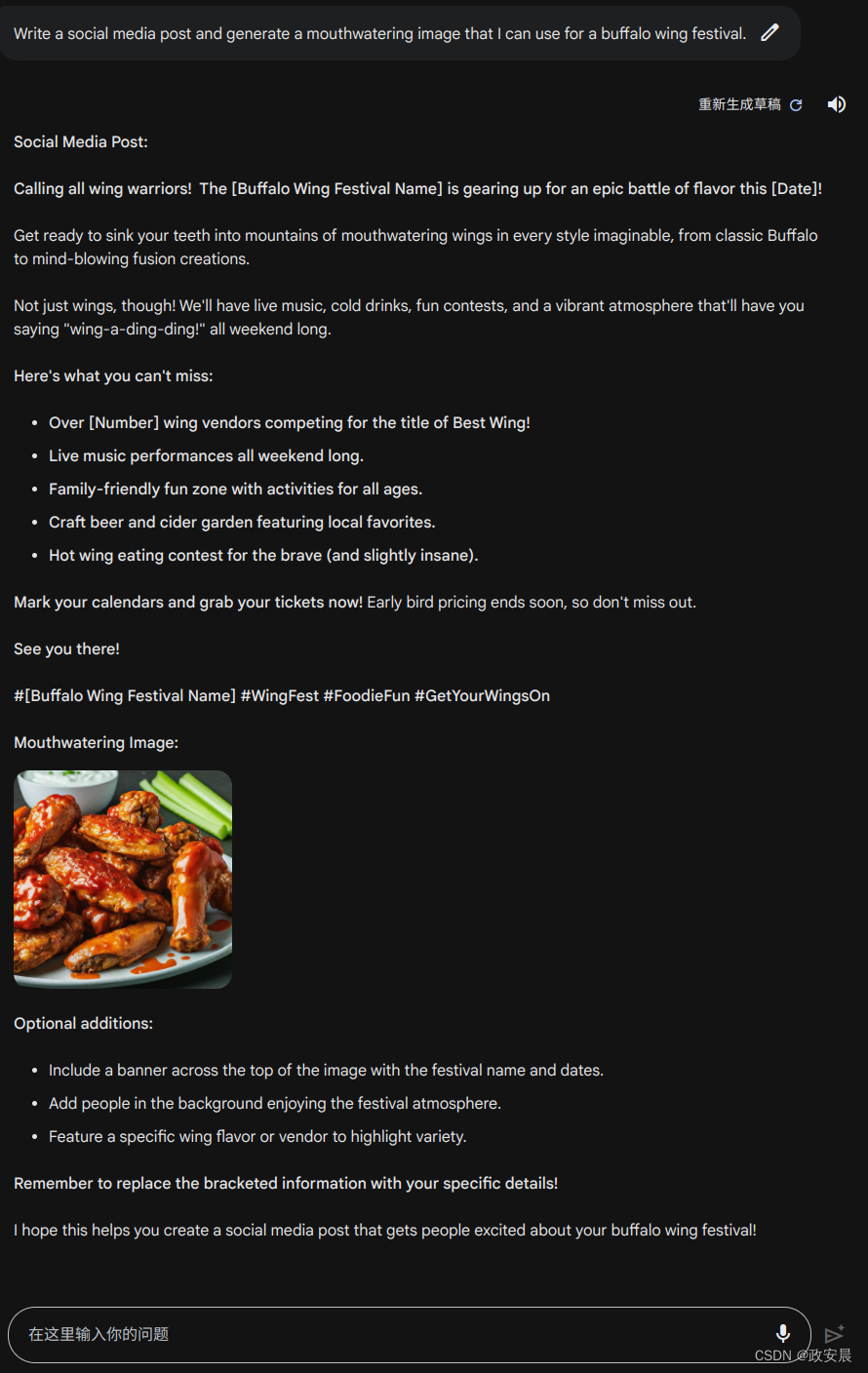
训练一个玛丽奥玩游戏的 RL 代理
原文:
pytorch.org/tutorials/intermediate/mario_rl_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整的示例代码
作者: 冯元松, Suraj Subramanian, 王浩, 郭宇章。
这个教程将带你了解深度强化学习的基础知识。最后,你将实现一个能够自己玩游戏的 AI 马里奥(使用双深度 Q 网络)。
虽然这个教程不需要 RL 的先验知识,但你可以通过这些 RL 概念来熟悉,还可以使用这个方便的 速查表作为参考。完整的代码在这里可用。
%%bash
pip install gym-super-mario-bros==7.4.0
pip install tensordict==0.2.0
pip install torchrl==0.2.0
import torch
from torch import nn
from torchvision import transforms as T
from PIL import Image
import numpy as np
from pathlib import Path
from collections import deque
import random, datetime, os# Gym is an OpenAI toolkit for RL
import gym
from gym.spaces import Box
from gym.wrappers import FrameStack# NES Emulator for OpenAI Gym
from nes_py.wrappers import JoypadSpace# Super Mario environment for OpenAI Gym
import gym_super_mario_brosfrom tensordict import TensorDict
from torchrl.data import TensorDictReplayBuffer, LazyMemmapStorage
RL 定义
环境 代理与之交互并学习的世界。
动作 a a a:代理对环境的响应。所有可能动作的集合称为动作空间。
状态 s s s:环境的当前特征。环境可能处于的所有可能状态的集合称为状态空间。
奖励 r r r:奖励是环境向代理提供的关键反馈。这是驱使代理学习并改变其未来行动的动力。在多个时间步骤上的奖励的聚合被称为回报。
最优动作-值函数 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a):给出了如果你从状态 s s s 开始,采取任意动作 a a a,然后在每个未来时间步骤中采取最大化回报的动作的预期回报。 Q Q Q 可以说代表了状态中动作的“质量”。我们试图近似这个函数。
环境
初始化环境
在马里奥中,环境由管道、蘑菇和其他组件组成。
当马里奥执行一个动作时,环境会以改变的(下一个)状态、奖励和其他信息做出响应。
# Initialize Super Mario environment (in v0.26 change render mode to 'human' to see results on the screen)
if gym.__version__ < '0.26':env = gym_super_mario_bros.make("SuperMarioBros-1-1-v0", new_step_api=True)
else:env = gym_super_mario_bros.make("SuperMarioBros-1-1-v0", render_mode='rgb', apply_api_compatibility=True)# Limit the action-space to
# 0\. walk right
# 1\. jump right
env = JoypadSpace(env, [["right"], ["right", "A"]])env.reset()
next_state, reward, done, trunc, info = env.step(action=0)
print(f"{next_state.shape},\n {reward},\n {done},\n {info}")
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/gym/envs/registration.py:555: UserWarning:WARN: The environment SuperMarioBros-1-1-v0 is out of date. You should consider upgrading to version `v3`./opt/conda/envs/py_3.10/lib/python3.10/site-packages/gym/envs/registration.py:627: UserWarning:WARN: The environment creator metadata doesn't include `render_modes`, contains: ['render.modes', 'video.frames_per_second']/opt/conda/envs/py_3.10/lib/python3.10/site-packages/gym/utils/passive_env_checker.py:233: DeprecationWarning:`np.bool8` is a deprecated alias for `np.bool_`. (Deprecated NumPy 1.24)(240, 256, 3),0.0,False,{'coins': 0, 'flag_get': False, 'life': 2, 'score': 0, 'stage': 1, 'status': 'small', 'time': 400, 'world': 1, 'x_pos': 40, 'y_pos': 79}
预处理环境
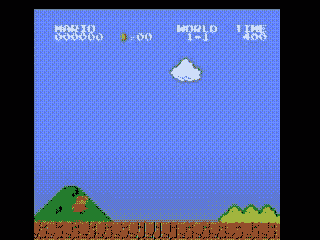
环境数据通过 next_state 返回给代理。正如你在上面看到的,每个状态由一个 [3, 240, 256] 大小的数组表示。通常这比我们的代理需要的信息更多;例如,马里奥的行动不取决于管道或天空的颜色!
我们使用包装器在将环境数据发送给代理之前对其进行预处理。
GrayScaleObservation 是一个常见的包装器,用于将 RGB 图像转换为灰度图像;这样做可以减小状态表示的大小而不丢失有用的信息。现在每个状态的大小为:[1, 240, 256]
ResizeObservation 将每个观察结果缩小为一个正方形图像。新的大小:[1, 84, 84]
SkipFrame 是一个自定义包装器,继承自 gym.Wrapper 并实现 step() 函数。因为连续帧变化不大,我们可以跳过 n 个中间帧而不会丢失太多信息。第 n 帧聚合了每个跳过帧累积的奖励。
FrameStack 是一个包装器,允许我们将环境的连续帧压缩成一个观察点,以供我们的学习模型使用。这样,我们可以根据前几帧中他的移动方向来确定马里奥是着陆还是跳跃。
class SkipFrame(gym.Wrapper):def __init__(self, env, skip):"""Return only every `skip`-th frame"""super().__init__(env)self._skip = skipdef step(self, action):"""Repeat action, and sum reward"""total_reward = 0.0for i in range(self._skip):# Accumulate reward and repeat the same actionobs, reward, done, trunk, info = self.env.step(action)total_reward += rewardif done:breakreturn obs, total_reward, done, trunk, infoclass GrayScaleObservation(gym.ObservationWrapper):def __init__(self, env):super().__init__(env)obs_shape = self.observation_space.shape[:2]self.observation_space = Box(low=0, high=255, shape=obs_shape, dtype=np.uint8)def permute_orientation(self, observation):# permute [H, W, C] array to [C, H, W] tensorobservation = np.transpose(observation, (2, 0, 1))observation = torch.tensor(observation.copy(), dtype=torch.float)return observationdef observation(self, observation):observation = self.permute_orientation(observation)transform = T.Grayscale()observation = transform(observation)return observationclass ResizeObservation(gym.ObservationWrapper):def __init__(self, env, shape):super().__init__(env)if isinstance(shape, int):self.shape = (shape, shape)else:self.shape = tuple(shape)obs_shape = self.shape + self.observation_space.shape[2:]self.observation_space = Box(low=0, high=255, shape=obs_shape, dtype=np.uint8)def observation(self, observation):transforms = T.Compose([T.Resize(self.shape, antialias=True), T.Normalize(0, 255)])observation = transforms(observation).squeeze(0)return observation# Apply Wrappers to environment
env = SkipFrame(env, skip=4)
env = GrayScaleObservation(env)
env = ResizeObservation(env, shape=84)
if gym.__version__ < '0.26':env = FrameStack(env, num_stack=4, new_step_api=True)
else:env = FrameStack(env, num_stack=4)
将上述包装器应用于环境后,最终包装的状态由 4 个灰度连续帧堆叠在一起组成,如上图左侧所示。每次马里奥执行一个动作,环境会以这种结构的状态做出响应。该结构由一个大小为 [4, 84, 84] 的三维数组表示。
代理
我们创建一个类Mario来代表游戏中的我们的代理。马里奥应该能够:
-
行动根据当前状态(环境的)的最优动作策略。
-
记住经验。经验 = (当前状态,当前动作,奖励,下一个状态)。马里奥缓存并稍后回忆他的经验以更新他的动作策略。
-
随着时间的推移学习更好的动作策略
class Mario:def __init__():passdef act(self, state):"""Given a state, choose an epsilon-greedy action"""passdef cache(self, experience):"""Add the experience to memory"""passdef recall(self):"""Sample experiences from memory"""passdef learn(self):"""Update online action value (Q) function with a batch of experiences"""pass
在接下来的部分中,我们将填充马里奥的参数并定义他的函数。
行动
对于任何给定的状态,代理可以选择执行最优动作(利用)或随机动作(探索)。
马里奥以self.exploration_rate的机会随机探索;当他选择利用时,他依赖于MarioNet(在Learn部分中实现)提供最优动作。
class Mario:def __init__(self, state_dim, action_dim, save_dir):self.state_dim = state_dimself.action_dim = action_dimself.save_dir = save_dirself.device = "cuda" if torch.cuda.is_available() else "cpu"# Mario's DNN to predict the most optimal action - we implement this in the Learn sectionself.net = MarioNet(self.state_dim, self.action_dim).float()self.net = self.net.to(device=self.device)self.exploration_rate = 1self.exploration_rate_decay = 0.99999975self.exploration_rate_min = 0.1self.curr_step = 0self.save_every = 5e5 # no. of experiences between saving Mario Netdef act(self, state):"""Given a state, choose an epsilon-greedy action and update value of step.Inputs:state(``LazyFrame``): A single observation of the current state, dimension is (state_dim)Outputs:``action_idx`` (``int``): An integer representing which action Mario will perform"""# EXPLOREif np.random.rand() < self.exploration_rate:action_idx = np.random.randint(self.action_dim)# EXPLOITelse:state = state[0].__array__() if isinstance(state, tuple) else state.__array__()state = torch.tensor(state, device=self.device).unsqueeze(0)action_values = self.net(state, model="online")action_idx = torch.argmax(action_values, axis=1).item()# decrease exploration_rateself.exploration_rate *= self.exploration_rate_decayself.exploration_rate = max(self.exploration_rate_min, self.exploration_rate)# increment stepself.curr_step += 1return action_idx
缓存和回忆
这两个函数充当马里奥的“记忆”过程。
cache(): 每次马里奥执行一个动作时,他将experience存储到他的记忆中。他的经验包括当前状态,执行的动作,动作的奖励,下一个状态,以及游戏是否完成。
recall(): 马里奥随机从他的记忆中抽取一批经验,并用它来学习游戏。
class Mario(Mario): # subclassing for continuitydef __init__(self, state_dim, action_dim, save_dir):super().__init__(state_dim, action_dim, save_dir)self.memory = TensorDictReplayBuffer(storage=LazyMemmapStorage(100000, device=torch.device("cpu")))self.batch_size = 32def cache(self, state, next_state, action, reward, done):"""Store the experience to self.memory (replay buffer)Inputs:state (``LazyFrame``),next_state (``LazyFrame``),action (``int``),reward (``float``),done(``bool``))"""def first_if_tuple(x):return x[0] if isinstance(x, tuple) else xstate = first_if_tuple(state).__array__()next_state = first_if_tuple(next_state).__array__()state = torch.tensor(state)next_state = torch.tensor(next_state)action = torch.tensor([action])reward = torch.tensor([reward])done = torch.tensor([done])# self.memory.append((state, next_state, action, reward, done,))self.memory.add(TensorDict({"state": state, "next_state": next_state, "action": action, "reward": reward, "done": done}, batch_size=[]))def recall(self):"""Retrieve a batch of experiences from memory"""batch = self.memory.sample(self.batch_size).to(self.device)state, next_state, action, reward, done = (batch.get(key) for key in ("state", "next_state", "action", "reward", "done"))return state, next_state, action.squeeze(), reward.squeeze(), done.squeeze()
学习
马里奥在幕后使用DDQN 算法。DDQN 使用两个 ConvNets - Q o n l i n e Q_{online} Qonline和 Q t a r g e t Q_{target} Qtarget - 分别近似最优动作值函数。
在我们的实现中,我们在 Q o n l i n e Q_{online} Qonline和 Q t a r g e t Q_{target} Qtarget之间共享特征生成器features,但为每个分类器保持单独的 FC。 θ t a r g e t \theta_{target} θtarget( Q t a r g e t Q_{target} Qtarget的参数)被冻结以防止通过反向传播进行更新。相反,它会定期与 θ o n l i n e \theta_{online} θonline同步(稍后会详细介绍)。
神经网络
class MarioNet(nn.Module):"""mini CNN structureinput -> (conv2d + relu) x 3 -> flatten -> (dense + relu) x 2 -> output"""def __init__(self, input_dim, output_dim):super().__init__()c, h, w = input_dimif h != 84:raise ValueError(f"Expecting input height: 84, got: {h}")if w != 84:raise ValueError(f"Expecting input width: 84, got: {w}")self.online = self.__build_cnn(c, output_dim)self.target = self.__build_cnn(c, output_dim)self.target.load_state_dict(self.online.state_dict())# Q_target parameters are frozen.for p in self.target.parameters():p.requires_grad = Falsedef forward(self, input, model):if model == "online":return self.online(input)elif model == "target":return self.target(input)def __build_cnn(self, c, output_dim):return nn.Sequential(nn.Conv2d(in_channels=c, out_channels=32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1),nn.ReLU(),nn.Flatten(),nn.Linear(3136, 512),nn.ReLU(),nn.Linear(512, output_dim),)
TD 估计和 TD 目标
学习涉及两个值:
TD 估计 - 给定状态 s s s的预测最优 Q ∗ Q^* Q∗
T D e = Q o n l i n e ∗ ( s , a ) {TD}_e = Q_{online}^*(s,a) TDe=Qonline∗(s,a)
TD 目标 - 当前奖励和下一个状态 s ′ s' s′中估计的 Q ∗ Q^* Q∗的聚合
a ′ = a r g m a x a Q o n l i n e ( s ′ , a ) a' = argmax_{a} Q_{online}(s', a) a′=argmaxaQonline(s′,a)
T D t = r + γ Q t a r g e t ∗ ( s ′ , a ′ ) {TD}_t = r + \gamma Q_{target}^*(s',a') TDt=r+γQtarget∗(s′,a′)
因为我们不知道下一个动作 a ′ a' a′会是什么,所以我们使用在下一个状态 s ′ s' s′中最大化 Q o n l i n e Q_{online} Qonline的动作 a ′ a' a′。
请注意,我们在td_target()上使用@torch.no_grad()装饰器来禁用梯度计算(因为我们不需要在 θ t a r g e t \theta_{target} θtarget上进行反向传播)。
class Mario(Mario):def __init__(self, state_dim, action_dim, save_dir):super().__init__(state_dim, action_dim, save_dir)self.gamma = 0.9def td_estimate(self, state, action):current_Q = self.net(state, model="online")[np.arange(0, self.batch_size), action] # Q_online(s,a)return current_Q@torch.no_grad()def td_target(self, reward, next_state, done):next_state_Q = self.net(next_state, model="online")best_action = torch.argmax(next_state_Q, axis=1)next_Q = self.net(next_state, model="target")[np.arange(0, self.batch_size), best_action]return (reward + (1 - done.float()) * self.gamma * next_Q).float()
更新模型
当马里奥从他的重放缓冲区中采样输入时,我们计算 T D t TD_t TDt和 T D e TD_e TDe,并将这个损失反向传播到 Q o n l i n e Q_{online} Qonline以更新其参数 θ o n l i n e \theta_{online} θonline( α \alpha α是传递给optimizer的学习率lr)
θ o n l i n e ← θ o n l i n e + α ∇ ( T D e − T D t ) \theta_{online} \leftarrow \theta_{online} + \alpha \nabla(TD_e - TD_t) θonline←θonline+α∇(TDe−TDt)
θ t a r g e t \theta_{target} θtarget不通过反向传播进行更新。相反,我们定期将 θ o n l i n e \theta_{online} θonline复制到 θ t a r g e t \theta_{target} θtarget
θ t a r g e t ← θ o n l i n e \theta_{target} \leftarrow \theta_{online} θtarget←θonline
class Mario(Mario):def __init__(self, state_dim, action_dim, save_dir):super().__init__(state_dim, action_dim, save_dir)self.optimizer = torch.optim.Adam(self.net.parameters(), lr=0.00025)self.loss_fn = torch.nn.SmoothL1Loss()def update_Q_online(self, td_estimate, td_target):loss = self.loss_fn(td_estimate, td_target)self.optimizer.zero_grad()loss.backward()self.optimizer.step()return loss.item()def sync_Q_target(self):self.net.target.load_state_dict(self.net.online.state_dict())
保存检查点
class Mario(Mario):def save(self):save_path = (self.save_dir / f"mario_net_{int(self.curr_step // self.save_every)}.chkpt")torch.save(dict(model=self.net.state_dict(), exploration_rate=self.exploration_rate),save_path,)print(f"MarioNet saved to {save_path} at step {self.curr_step}")
将所有内容整合在一起
class Mario(Mario):def __init__(self, state_dim, action_dim, save_dir):super().__init__(state_dim, action_dim, save_dir)self.burnin = 1e4 # min. experiences before trainingself.learn_every = 3 # no. of experiences between updates to Q_onlineself.sync_every = 1e4 # no. of experiences between Q_target & Q_online syncdef learn(self):if self.curr_step % self.sync_every == 0:self.sync_Q_target()if self.curr_step % self.save_every == 0:self.save()if self.curr_step < self.burnin:return None, Noneif self.curr_step % self.learn_every != 0:return None, None# Sample from memorystate, next_state, action, reward, done = self.recall()# Get TD Estimatetd_est = self.td_estimate(state, action)# Get TD Targettd_tgt = self.td_target(reward, next_state, done)# Backpropagate loss through Q_onlineloss = self.update_Q_online(td_est, td_tgt)return (td_est.mean().item(), loss)
日志记录
import numpy as np
import time, datetime
import matplotlib.pyplot as pltclass MetricLogger:def __init__(self, save_dir):self.save_log = save_dir / "log"with open(self.save_log, "w") as f:f.write(f"{'Episode':>8}{'Step':>8}{'Epsilon':>10}{'MeanReward':>15}"f"{'MeanLength':>15}{'MeanLoss':>15}{'MeanQValue':>15}"f"{'TimeDelta':>15}{'Time':>20}\n")self.ep_rewards_plot = save_dir / "reward_plot.jpg"self.ep_lengths_plot = save_dir / "length_plot.jpg"self.ep_avg_losses_plot = save_dir / "loss_plot.jpg"self.ep_avg_qs_plot = save_dir / "q_plot.jpg"# History metricsself.ep_rewards = []self.ep_lengths = []self.ep_avg_losses = []self.ep_avg_qs = []# Moving averages, added for every call to record()self.moving_avg_ep_rewards = []self.moving_avg_ep_lengths = []self.moving_avg_ep_avg_losses = []self.moving_avg_ep_avg_qs = []# Current episode metricself.init_episode()# Timingself.record_time = time.time()def log_step(self, reward, loss, q):self.curr_ep_reward += rewardself.curr_ep_length += 1if loss:self.curr_ep_loss += lossself.curr_ep_q += qself.curr_ep_loss_length += 1def log_episode(self):"Mark end of episode"self.ep_rewards.append(self.curr_ep_reward)self.ep_lengths.append(self.curr_ep_length)if self.curr_ep_loss_length == 0:ep_avg_loss = 0ep_avg_q = 0else:ep_avg_loss = np.round(self.curr_ep_loss / self.curr_ep_loss_length, 5)ep_avg_q = np.round(self.curr_ep_q / self.curr_ep_loss_length, 5)self.ep_avg_losses.append(ep_avg_loss)self.ep_avg_qs.append(ep_avg_q)self.init_episode()def init_episode(self):self.curr_ep_reward = 0.0self.curr_ep_length = 0self.curr_ep_loss = 0.0self.curr_ep_q = 0.0self.curr_ep_loss_length = 0def record(self, episode, epsilon, step):mean_ep_reward = np.round(np.mean(self.ep_rewards[-100:]), 3)mean_ep_length = np.round(np.mean(self.ep_lengths[-100:]), 3)mean_ep_loss = np.round(np.mean(self.ep_avg_losses[-100:]), 3)mean_ep_q = np.round(np.mean(self.ep_avg_qs[-100:]), 3)self.moving_avg_ep_rewards.append(mean_ep_reward)self.moving_avg_ep_lengths.append(mean_ep_length)self.moving_avg_ep_avg_losses.append(mean_ep_loss)self.moving_avg_ep_avg_qs.append(mean_ep_q)last_record_time = self.record_timeself.record_time = time.time()time_since_last_record = np.round(self.record_time - last_record_time, 3)print(f"Episode {episode} - "f"Step {step} - "f"Epsilon {epsilon} - "f"Mean Reward {mean_ep_reward} - "f"Mean Length {mean_ep_length} - "f"Mean Loss {mean_ep_loss} - "f"Mean Q Value {mean_ep_q} - "f"Time Delta {time_since_last_record} - "f"Time {datetime.datetime.now().strftime('%Y-%m-%dT%H:%M:%S')}")with open(self.save_log, "a") as f:f.write(f"{episode:8d}{step:8d}{epsilon:10.3f}"f"{mean_ep_reward:15.3f}{mean_ep_length:15.3f}{mean_ep_loss:15.3f}{mean_ep_q:15.3f}"f"{time_since_last_record:15.3f}"f"{datetime.datetime.now().strftime('%Y-%m-%dT%H:%M:%S'):>20}\n")for metric in ["ep_lengths", "ep_avg_losses", "ep_avg_qs", "ep_rewards"]:plt.clf()plt.plot(getattr(self, f"moving_avg_{metric}"), label=f"moving_avg_{metric}")plt.legend()plt.savefig(getattr(self, f"{metric}_plot"))
让我们开始玩吧!
在这个示例中,我们运行了 40 个剧集的训练循环,但为了马里奥真正学会他的世界的方式,我们建议至少运行 40,000 个剧集的循环!
use_cuda = torch.cuda.is_available()
print(f"Using CUDA: {use_cuda}")
print()save_dir = Path("checkpoints") / datetime.datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
save_dir.mkdir(parents=True)mario = Mario(state_dim=(4, 84, 84), action_dim=env.action_space.n, save_dir=save_dir)logger = MetricLogger(save_dir)episodes = 40
for e in range(episodes):state = env.reset()# Play the game!while True:# Run agent on the stateaction = mario.act(state)# Agent performs actionnext_state, reward, done, trunc, info = env.step(action)# Remembermario.cache(state, next_state, action, reward, done)# Learnq, loss = mario.learn()# Logginglogger.log_step(reward, loss, q)# Update statestate = next_state# Check if end of gameif done or info["flag_get"]:breaklogger.log_episode()if (e % 20 == 0) or (e == episodes - 1):logger.record(episode=e, epsilon=mario.exploration_rate, step=mario.curr_step)
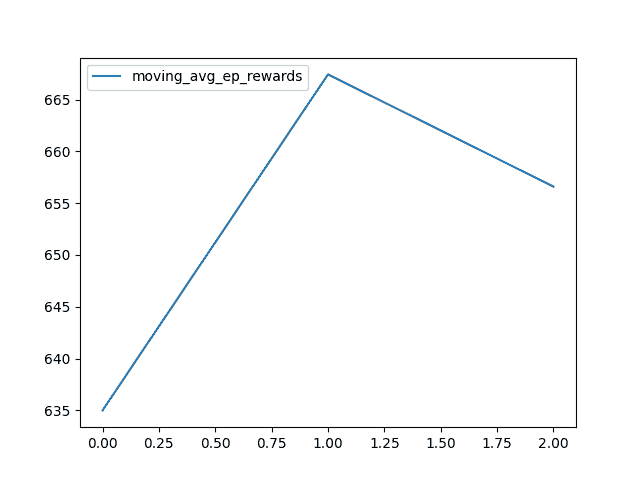
Using CUDA: TrueEpisode 0 - Step 163 - Epsilon 0.9999592508251706 - Mean Reward 635.0 - Mean Length 163.0 - Mean Loss 0.0 - Mean Q Value 0.0 - Time Delta 1.991 - Time 2024-02-03T05:50:09
Episode 20 - Step 5007 - Epsilon 0.9987490329557962 - Mean Reward 667.429 - Mean Length 238.429 - Mean Loss 0.0 - Mean Q Value 0.0 - Time Delta 60.318 - Time 2024-02-03T05:51:09
Episode 39 - Step 8854 - Epsilon 0.9977889477081997 - Mean Reward 656.6 - Mean Length 221.35 - Mean Loss 0.0 - Mean Q Value 0.0 - Time Delta 48.643 - Time 2024-02-03T05:51:58
结论
在本教程中,我们看到如何使用 PyTorch 训练一个玩游戏的 AI。您可以使用相同的方法来训练 AI 玩OpenAI gym中的任何游戏。希望您喜欢这个教程,欢迎在我们的 github联系我们!
脚本的总运行时间:(1 分钟 51.993 秒)
下载 Python 源代码:mario_rl_tutorial.py
下载 Jupyter 笔记本:mario_rl_tutorial.ipynb
Sphinx-Gallery 生成的画廊
Pendulum:使用 TorchRL 编写您的环境和转换
原文:
pytorch.org/tutorials/advanced/pendulum.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整示例代码
作者:Vincent Moens
创建环境(模拟器或物理控制系统的接口)是强化学习和控制工程的一个整合部分。
TorchRL 提供了一套工具在多种情境下实现这一点。本教程演示了如何使用 PyTorch 和 TorchRL 从头开始编写一个摆模拟器。它受到了OpenAI-Gym/Farama-Gymnasium 控制库中 Pendulum-v1 实现的启发。

简单摆
关键收获:
-
如何在 TorchRL 中设计环境:- 编写规格(输入、观察和奖励);- 实现行为:种子、重置和步骤。
-
转换您的环境输入和输出,并编写您自己的转换;
-
如何使用
TensorDict通过codebase传递任意数据结构。在这个过程中,我们将涉及 TorchRL 的三个关键组件:
-
environments
-
transforms
-
models(策略和值函数)
为了展示 TorchRL 环境可以实现的功能,我们将设计一个无状态环境。有状态的环境会跟踪最新遇到的物理状态,并依赖于此来模拟状态之间的转换,而无状态的环境期望在每一步提供当前状态,以及采取的动作。TorchRL 支持这两种类型的环境,但无状态环境更通用,因此涵盖了 TorchRL 环境 API 中更广泛的功能特性。
建模无状态环境使用户完全控制模拟器的输入和输出:可以在任何阶段重置实验或从外部主动修改动态。然而,这假设我们对任务有一定控制,这并不总是情况:解决一个我们无法控制当前状态的问题更具挑战性,但具有更广泛的应用范围。
无状态环境的另一个优点是可以实现批量执行转换模拟。如果后端和实现允许,可以在标量、向量或张量上无缝执行代数操作。本教程提供了这样的示例。
本教程将按以下结构展开:
-
我们将首先熟悉环境的属性:其形状(
batch_size),其方法(主要是step()、reset()和set_seed())以及最后的规格。 -
在编写完我们的模拟器后,我们将演示如何在训练过程中使用转换。
-
我们将探索从 TorchRL 的 API 中产生的新途径,包括:转换输入的可能性,模拟的向量化执行以及通过模拟图进行反向传播的可能性。
-
最后,我们将训练一个简单的策略来解决我们实现的系统。
from collections import defaultdict
from typing import Optionalimport numpy as np
import torch
import tqdm
from tensordict.nn import TensorDictModule
from tensordict.tensordict import TensorDict, TensorDictBase
from torch import nnfrom torchrl.data import BoundedTensorSpec, CompositeSpec, UnboundedContinuousTensorSpec
from torchrl.envs import (CatTensors,EnvBase,Transform,TransformedEnv,UnsqueezeTransform,
)
from torchrl.envs.transforms.transforms import _apply_to_composite
from torchrl.envs.utils import check_env_specs, step_mdpDEFAULT_X = np.pi
DEFAULT_Y = 1.0
设计新环境类时需要注意的四个方面:
-
EnvBase._reset(),这段代码用于在(可能是随机的)初始状态下重置模拟器; -
EnvBase._step()编码了状态转移动态; -
EnvBase._set_seed()`实现种子机制; -
环境规范。
让我们首先描述手头的问题:我们想要建模一个简单的摆锤,我们可以控制施加在其固定点上的扭矩。我们的目标是将摆锤放在向上位置(按照惯例,角位置为 0)并使其保持在该位置静止。为了设计我们的动态系统,我们需要定义两个方程:遵循动作(施加的扭矩)的运动方程和构成我们目标函数的奖励方程。
对于运动方程,我们将根据以下方式更新角速度:
θ ˙ t + 1 = θ ˙ t + ( 3 ∗ g / ( 2 ∗ L ) ∗ sin ( θ t ) + 3 / ( m ∗ L 2 ) ∗ u ) ∗ d t \dot{\theta}_{t+1} = \dot{\theta}_t + (3 * g / (2 * L) * \sin(\theta_t) + 3 / (m * L²) * u) * dt θ˙t+1=θ˙t+(3∗g/(2∗L)∗sin(θt)+3/(m∗L2)∗u)∗dt
其中 θ ˙ \dot{\theta} θ˙是角速度(弧度/秒), g g g是重力, L L L是摆长, m m m是质量, θ \theta θ是角位置, u u u是扭矩。然后根据以下方式更新角位置
θ t + 1 = θ t + θ ˙ t + 1 d t \theta_{t+1} = \theta_{t} + \dot{\theta}_{t+1} dt θt+1=θt+θ˙t+1dt
我们将奖励定义为
r = − ( θ 2 + 0.1 ∗ θ ˙ 2 + 0.001 ∗ u 2 ) r = -(\theta² + 0.1 * \dot{\theta}² + 0.001 * u²) r=−(θ2+0.1∗θ˙2+0.001∗u2)
当角度接近 0(摆锤向上位置)、角速度接近 0(无运动)且扭矩也为 0 时,将最大化奖励。
编码一个动作的效果:_step()
步骤方法是首要考虑的事项,因为它将编码我们感兴趣的模拟。在 TorchRL 中,EnvBase类有一个EnvBase.step()方法,接收一个带有"action"条目的tensordict.TensorDict实例,指示要执行的操作。
为了方便从tensordict中读取和写入数据,并确保键与库期望的一致,模拟部分已被委托给一个私有的抽象方法_step(),该方法从tensordict中读取输入数据,并写入一个新的tensordict,其中包含输出数据。
_step()方法应该执行以下操作:
- 读取输入键(如
"action")并根据这些执行模拟;- 检索观察值、完成状态和奖励;
- 将一组观察值以及对应条目中的奖励和完成状态写入新的
TensorDict。
接下来,step()方法将合并step()的输出到输入的tensordict中,以强制执行输入/输出的一致性。
对于有状态的环境,通常会是这样的:
>>> policy(env.reset())
>>> print(tensordict)
TensorDict(fields={action: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),observation: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([]),device=cpu,is_shared=False)
>>> env.step(tensordict)
>>> print(tensordict)
TensorDict(fields={action: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),next: TensorDict(fields={done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),observation: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),reward: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([]),device=cpu,is_shared=False),observation: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([]),device=cpu,is_shared=False)
请注意,根tensordict没有改变,唯一的修改是出现了一个包含新信息的新"next"条目。
在摆锤示例中,我们的_step()方法将从输入的tensordict中读取相关条目,并在施加了由"action"键编码的力后计算摆锤的位置和速度。我们计算摆锤的新角位置"new_th"为前一个位置"th"加上新速度"new_thdot"乘以时间间隔dt的结果。
由于我们的目标是将摆锤竖起并保持在那个位置静止,我们的cost(负奖励)函数对于接近目标和低速度的位置具有较低的值。实际上,我们希望阻止远离“向上”位置和/或速度远离 0 的位置。
在我们的示例中,EnvBase._step()被编码为静态方法,因为我们的环境是无状态的。在有状态的设置中,需要self参数,因为需要从环境中读取状态。
def _step(tensordict):th, thdot = tensordict["th"], tensordict["thdot"] # th := thetag_force = tensordict["params", "g"]mass = tensordict["params", "m"]length = tensordict["params", "l"]dt = tensordict["params", "dt"]u = tensordict["action"].squeeze(-1)u = u.clamp(-tensordict["params", "max_torque"], tensordict["params", "max_torque"])costs = angle_normalize(th) ** 2 + 0.1 * thdot**2 + 0.001 * (u**2)new_thdot = (thdot+ (3 * g_force / (2 * length) * th.sin() + 3.0 / (mass * length**2) * u) * dt)new_thdot = new_thdot.clamp(-tensordict["params", "max_speed"], tensordict["params", "max_speed"])new_th = th + new_thdot * dtreward = -costs.view(*tensordict.shape, 1)done = torch.zeros_like(reward, dtype=torch.bool)out = TensorDict({"th": new_th,"thdot": new_thdot,"params": tensordict["params"],"reward": reward,"done": done,},tensordict.shape,)return outdef angle_normalize(x):return ((x + torch.pi) % (2 * torch.pi)) - torch.pi
重置模拟器:_reset()
我们需要关注的第二个方法是 _reset() 方法。与 _step() 一样,它应该在输出的 tensordict 中写入观察条目,并可能包含一个完成状态(如果省略完成状态,则父方法 reset() 将填充为 False)。在某些情况下,要求 _reset 方法接收来自调用它的函数的命令(例如,在多代理设置中,我们可能希望指示需要重置哪些代理)。这就是为什么 _reset() 方法也期望一个 tensordict 作为输入,尽管它可以完全为空或为 None。
父类 EnvBase.reset() 进行一些简单的检查,就像 EnvBase.step() 一样,例如确保在输出 tensordict 中返回一个 "done" 状态,并且形状与规格期望的匹配。
对我们来说,唯一需要考虑的是 EnvBase._reset() 是否包含所有预期的观察结果。再次强调,由于我们正在处理无状态环境,我们将摆锤的配置传递给名为 "params" 的嵌套 tensordict。
在这个例子中,我们不传递完成状态,因为这对于 _reset() 不是强制性的,而且我们的环境是非终止的,因此我们总是期望它为 False。
def _reset(self, tensordict):if tensordict is None or tensordict.is_empty():# if no ``tensordict`` is passed, we generate a single set of hyperparameters# Otherwise, we assume that the input ``tensordict`` contains all the relevant# parameters to get started.tensordict = self.gen_params(batch_size=self.batch_size)high_th = torch.tensor(DEFAULT_X, device=self.device)high_thdot = torch.tensor(DEFAULT_Y, device=self.device)low_th = -high_thlow_thdot = -high_thdot# for non batch-locked environments, the input ``tensordict`` shape dictates the number# of simulators run simultaneously. In other contexts, the initial# random state's shape will depend upon the environment batch-size instead.th = (torch.rand(tensordict.shape, generator=self.rng, device=self.device)* (high_th - low_th)+ low_th)thdot = (torch.rand(tensordict.shape, generator=self.rng, device=self.device)* (high_thdot - low_thdot)+ low_thdot)out = TensorDict({"th": th,"thdot": thdot,"params": tensordict["params"],},batch_size=tensordict.shape,)return out
环境元数据:env.*_spec
规格定义了环境的输入和输出域。重要的是,规格准确定义了在运行时将接收到的张量,因为它们经常用于在多进程和分布式设置中携带有关环境的信息。它们还可以用于实例化懒惰定义的神经网络和测试脚本,而无需实际查询环境(例如,对于真实世界的物理系统来说,这可能是昂贵的)。
我们的环境中必须编码的四个规格:
-
EnvBase.observation_spec: 这将是一个CompositeSpec实例,其中每个键都是一个观察(CompositeSpec可以被视为规格字典)。 -
EnvBase.action_spec: 它可以是任何类型的规格,但要求它对应于输入tensordict中的"action"条目; -
EnvBase.reward_spec: 提供有关奖励空间的信息; -
EnvBase.done_spec: 提供有关完成标志空间的信息。
TorchRL 规格分为两个通用容器:input_spec 包含步骤函数读取的信息的规格(分为包含动作的 action_spec 和包含其余所有内容的 state_spec),以及 output_spec 编码步骤输出的规格(observation_spec、reward_spec 和 done_spec)。一般来说,您不应直接与 output_spec 和 input_spec 交互,而只应与它们的内容交互:observation_spec、reward_spec、done_spec、action_spec 和 state_spec。原因是规格在 output_spec 和 input_spec 中以非平凡的方式组织,这两者都不应直接修改。
换句话说,observation_spec 和相关属性是输出和输入规格容器内容的便捷快捷方式。
TorchRL 提供多个 TensorSpec 子类 来编码环境的输入和输出特征。
规格形状
环境规格的主要维度必须与环境批处理大小匹配。这是为了强制确保环境的每个组件(包括其转换)都具有预期输入和输出形状的准确表示。这是在有状态设置中应准确编码的内容。
对于非batch-locked环境,例如我们示例中的环境(见下文),这是无关紧要的,因为环境批处理大小很可能为空。
def _make_spec(self, td_params):# Under the hood, this will populate self.output_spec["observation"]self.observation_spec = CompositeSpec(th=BoundedTensorSpec(low=-torch.pi,high=torch.pi,shape=(),dtype=torch.float32,),thdot=BoundedTensorSpec(low=-td_params["params", "max_speed"],high=td_params["params", "max_speed"],shape=(),dtype=torch.float32,),# we need to add the ``params`` to the observation specs, as we want# to pass it at each step during a rolloutparams=make_composite_from_td(td_params["params"]),shape=(),)# since the environment is stateless, we expect the previous output as input.# For this, ``EnvBase`` expects some state_spec to be availableself.state_spec = self.observation_spec.clone()# action-spec will be automatically wrapped in input_spec when# `self.action_spec = spec` will be called supportedself.action_spec = BoundedTensorSpec(low=-td_params["params", "max_torque"],high=td_params["params", "max_torque"],shape=(1,),dtype=torch.float32,)self.reward_spec = UnboundedContinuousTensorSpec(shape=(*td_params.shape, 1))def make_composite_from_td(td):# custom function to convert a ``tensordict`` in a similar spec structure# of unbounded values.composite = CompositeSpec({key: make_composite_from_td(tensor)if isinstance(tensor, TensorDictBase)else UnboundedContinuousTensorSpec(dtype=tensor.dtype, device=tensor.device, shape=tensor.shape)for key, tensor in td.items()},shape=td.shape,)return composite
可重现的实验:种子
对环境进行种子操作是初始化实验时的常见操作。EnvBase._set_seed()的唯一目的是设置包含的模拟器的种子。如果可能的话,这个操作不应该调用reset()或与环境执行交互。父类EnvBase.set_seed()方法包含一个机制,允许使用不同的伪随机和可重现种子对多个环境进行种子化。
def _set_seed(self, seed: Optional[int]):rng = torch.manual_seed(seed)self.rng = rng
将事物包装在一起:EnvBase类
最后,我们可以组合这些部分并设计我们的环境类。规格初始化需要在环境构建过程中执行,因此我们必须确保在PendulumEnv.__init__()内调用_make_spec()方法。
我们添加了一个静态方法PendulumEnv.gen_params(),它确定性地生成一组在执行过程中使用的超参数:
def gen_params(g=10.0, batch_size=None) -> TensorDictBase:"""Returns a ``tensordict`` containing the physical parameters such as gravitational force and torque or speed limits."""if batch_size is None:batch_size = []td = TensorDict({"params": TensorDict({"max_speed": 8,"max_torque": 2.0,"dt": 0.05,"g": g,"m": 1.0,"l": 1.0,},[],)},[],)if batch_size:td = td.expand(batch_size).contiguous()return td
通过将homonymous属性设置为False,我们将环境定义为非batch_locked。这意味着我们不会强制输入的tensordict具有与环境相匹配的batch-size。
以下代码将组合我们上面编码的部分。
class PendulumEnv(EnvBase):metadata = {"render_modes": ["human", "rgb_array"],"render_fps": 30,}batch_locked = Falsedef __init__(self, td_params=None, seed=None, device="cpu"):if td_params is None:td_params = self.gen_params()super().__init__(device=device, batch_size=[])self._make_spec(td_params)if seed is None:seed = torch.empty((), dtype=torch.int64).random_().item()self.set_seed(seed)# Helpers: _make_step and gen_paramsgen_params = staticmethod(gen_params)_make_spec = _make_spec# Mandatory methods: _step, _reset and _set_seed_reset = _reset_step = staticmethod(_step)_set_seed = _set_seed
测试我们的环境
TorchRL 提供了一个简单的函数check_env_specs()来检查一个(转换后的)环境是否具有与其规格所规定的输入/输出结构相匹配的结构。让我们试一试:
env = PendulumEnv()
check_env_specs(env)
check_env_specs succeeded!
我们可以查看我们的规格,以便对环境签名进行可视化表示:
print("observation_spec:", env.observation_spec)
print("state_spec:", env.state_spec)
print("reward_spec:", env.reward_spec)
observation_spec: CompositeSpec(th: BoundedTensorSpec(shape=torch.Size([]),space=ContinuousBox(low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),device=cpu,dtype=torch.float32,domain=continuous),thdot: BoundedTensorSpec(shape=torch.Size([]),space=ContinuousBox(low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),device=cpu,dtype=torch.float32,domain=continuous),params: CompositeSpec(max_speed: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.int64,domain=continuous),max_torque: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous),dt: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous),g: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous),m: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous),l: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous), device=cpu, shape=torch.Size([])), device=cpu, shape=torch.Size([]))
state_spec: CompositeSpec(th: BoundedTensorSpec(shape=torch.Size([]),space=ContinuousBox(low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),device=cpu,dtype=torch.float32,domain=continuous),thdot: BoundedTensorSpec(shape=torch.Size([]),space=ContinuousBox(low=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True),high=Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, contiguous=True)),device=cpu,dtype=torch.float32,domain=continuous),params: CompositeSpec(max_speed: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.int64,domain=continuous),max_torque: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous),dt: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous),g: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous),m: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous),l: UnboundedContinuousTensorSpec(shape=torch.Size([]),space=None,device=cpu,dtype=torch.float32,domain=continuous), device=cpu, shape=torch.Size([])), device=cpu, shape=torch.Size([]))
reward_spec: UnboundedContinuousTensorSpec(shape=torch.Size([1]),space=ContinuousBox(low=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True),high=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True)),device=cpu,dtype=torch.float32,domain=continuous)
我们也可以执行一些命令来检查输出结构是否符合预期。
td = env.reset()
print("reset tensordict", td)
reset tensordict TensorDict(fields={done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([]),device=None,is_shared=False),terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([]),device=None,is_shared=False)
我们可以运行env.rand_step()来从action_spec域中随机生成一个动作。由于我们的环境是无状态的,必须传递一个包含超参数和当前状态的tensordict。在有状态的情况下,env.rand_step()也可以完美运行。
td = env.rand_step(td)
print("random step tensordict", td)
random step tensordict TensorDict(fields={action: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),next: TensorDict(fields={done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([]),device=None,is_shared=False),reward: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([]),device=None,is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([]),device=None,is_shared=False),terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([]),device=None,is_shared=False)
转换环境
为无状态模拟器编写环境转换比为有状态模拟器稍微复杂一些:转换需要在下一次迭代时读取的输出条目需要在下一步调用meth.step()之前应用逆转换。这是展示 TorchRL 转换所有功能的理想场景!
例如,在以下转换后的环境中,我们对["th", "thdot"]条目进行unsqueeze操作,以便能够沿着最后一个维度堆叠它们。我们还将它们作为in_keys_inv传递,以便在下一次迭代中将它们作为输入传递时将它们压缩回原始形状。
env = TransformedEnv(env,# ``Unsqueeze`` the observations that we will concatenateUnsqueezeTransform(unsqueeze_dim=-1,in_keys=["th", "thdot"],in_keys_inv=["th", "thdot"],),
)
编写自定义转换
TorchRL 的转换可能不涵盖所有希望在环境执行后执行的操作。编写一个转换并不需要太多的努力。与环境设计一样,编写转换有两个步骤:
-
正确获取动态(正向和反向);
-
调整环境规格。
转换可以在两种设置中使用:独立使用时,它可以作为一个Module。它也可以附加到一个TransformedEnv。类的结构允许在不同上下文中自定义行为。
Transform的框架可以总结如下:
class Transform(nn.Module):def forward(self, tensordict):...def _apply_transform(self, tensordict):...def _step(self, tensordict):...def _call(self, tensordict):...def inv(self, tensordict):...def _inv_apply_transform(self, tensordict):...
有三个入口点(forward()、_step()和inv()),它们都接收tensordict.TensorDict实例。前两个最终将通过in_keys指示的键,并对每个键调用_apply_transform()。如果提供了Transform.out_keys,结果将写入由Transform.out_keys指向的条目(如果没有,则in_keys将使用转换后的值进行更新)。如果需要执行逆转换,将执行类似的数据流,但使用Transform.inv()和Transform._inv_apply_transform()方法,并跨in_keys_inv和out_keys_inv键列表。以下图总结了环境和重放缓冲区的这种流程。
转换 API
在某些情况下,一个转换不会以单元方式在一部分键上工作,而是会在父环境上执行一些操作或者与整个输入的tensordict一起工作。在这些情况下,应重新编写_call()和forward()方法,可以跳过_apply_transform()方法。
让我们编写新的转换,计算位置角的sine和cosine值,因为这些值对我们学习策略比原始角度值更有用:
class SinTransform(Transform):def _apply_transform(self, obs: torch.Tensor) -> None:return obs.sin()# The transform must also modify the data at reset timedef _reset(self, tensordict: TensorDictBase, tensordict_reset: TensorDictBase) -> TensorDictBase:return self._call(tensordict_reset)# _apply_to_composite will execute the observation spec transform across all# in_keys/out_keys pairs and write the result in the observation_spec which# is of type ``Composite``@_apply_to_compositedef transform_observation_spec(self, observation_spec):return BoundedTensorSpec(low=-1,high=1,shape=observation_spec.shape,dtype=observation_spec.dtype,device=observation_spec.device,)class CosTransform(Transform):def _apply_transform(self, obs: torch.Tensor) -> None:return obs.cos()# The transform must also modify the data at reset timedef _reset(self, tensordict: TensorDictBase, tensordict_reset: TensorDictBase) -> TensorDictBase:return self._call(tensordict_reset)# _apply_to_composite will execute the observation spec transform across all# in_keys/out_keys pairs and write the result in the observation_spec which# is of type ``Composite``@_apply_to_compositedef transform_observation_spec(self, observation_spec):return BoundedTensorSpec(low=-1,high=1,shape=observation_spec.shape,dtype=observation_spec.dtype,device=observation_spec.device,)t_sin = SinTransform(in_keys=["th"], out_keys=["sin"])
t_cos = CosTransform(in_keys=["th"], out_keys=["cos"])
env.append_transform(t_sin)
env.append_transform(t_cos)
将观察结果连接到“observation”条目上。del_keys=False确保我们保留这些值供下一次迭代使用。
cat_transform = CatTensors(in_keys=["sin", "cos", "thdot"], dim=-1, out_key="observation", del_keys=False
)
env.append_transform(cat_transform)
再次,让我们检查一下我们的环境规格是否与接收到的一致:
check_env_specs(env)
check_env_specs succeeded!
执行一个轨迹
执行一个轨迹是一系列简单的步骤:
-
重置环境
-
只要某个条件未满足:
-
根据策略计算一个动作
-
执行给定此动作的步骤
-
收集数据
-
进行
MDP步骤
-
-
收集数据并返回
这些操作已经方便地包装在rollout()方法中,我们在下面提供一个简化版本。
def simple_rollout(steps=100):# preallocate:data = TensorDict({}, [steps])# reset_data = env.reset()for i in range(steps):_data["action"] = env.action_spec.rand()_data = env.step(_data)data[i] = _data_data = step_mdp(_data, keep_other=True)return dataprint("data from rollout:", simple_rollout(100))
data from rollout: TensorDict(fields={action: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),cos: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.bool, is_shared=False),next: TensorDict(fields={cos: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.bool, is_shared=False),observation: Tensor(shape=torch.Size([100, 3]), device=cpu, dtype=torch.float32, is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([100]),device=None,is_shared=False),reward: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),sin: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),terminated: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([100]),device=None,is_shared=False),observation: Tensor(shape=torch.Size([100, 3]), device=cpu, dtype=torch.float32, is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([100]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([100]),device=None,is_shared=False),sin: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),terminated: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([100, 1]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([100]),device=None,is_shared=False)
批量计算
我们教程的最后一个未探索的部分是我们在 TorchRL 中批量计算的能力。因为我们的环境对输入数据形状没有任何假设,所以我们可以无缝地在数据批次上执行它。更好的是:对于像我们的摆锤这样的非批量锁定环境,我们可以在不重新创建环境的情况下即时更改批量大小。为此,我们只需生成所需形状的参数。
batch_size = 10 # number of environments to be executed in batch
td = env.reset(env.gen_params(batch_size=[batch_size]))
print("reset (batch size of 10)", td)
td = env.rand_step(td)
print("rand step (batch size of 10)", td)
reset (batch size of 10) TensorDict(fields={cos: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),observation: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10]),device=None,is_shared=False),sin: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),terminated: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10]),device=None,is_shared=False)
rand step (batch size of 10) TensorDict(fields={action: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),cos: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),next: TensorDict(fields={cos: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),observation: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10]),device=None,is_shared=False),reward: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),sin: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),terminated: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10]),device=None,is_shared=False),observation: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([10]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10]),device=None,is_shared=False),sin: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),terminated: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10]),device=None,is_shared=False)
使用一批数据执行一个轨迹需要我们在轨迹函数之外重置环境,因为我们需要动态定义批量大小,而rollout()不支持这一点:
rollout = env.rollout(3,auto_reset=False, # we're executing the reset out of the ``rollout`` calltensordict=env.reset(env.gen_params(batch_size=[batch_size])),
)
print("rollout of len 3 (batch size of 10):", rollout)
rollout of len 3 (batch size of 10): TensorDict(fields={action: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),cos: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.bool, is_shared=False),next: TensorDict(fields={cos: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),done: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.bool, is_shared=False),observation: Tensor(shape=torch.Size([10, 3, 3]), device=cpu, dtype=torch.float32, is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10, 3]),device=None,is_shared=False),reward: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),sin: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),terminated: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10, 3]),device=None,is_shared=False),observation: Tensor(shape=torch.Size([10, 3, 3]), device=cpu, dtype=torch.float32, is_shared=False),params: TensorDict(fields={dt: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),g: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),l: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),m: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False),max_speed: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.int64, is_shared=False),max_torque: Tensor(shape=torch.Size([10, 3]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10, 3]),device=None,is_shared=False),sin: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),terminated: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.bool, is_shared=False),th: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),thdot: Tensor(shape=torch.Size([10, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},batch_size=torch.Size([10, 3]),device=None,is_shared=False)
训练一个简单的策略
在这个例子中,我们将使用奖励作为可微目标来训练一个简单的策略,比如一个负损失。我们将利用我们的动态系统是完全可微的这一事实,通过轨迹返回反向传播并调整我们的策略权重,以直接最大化这个值。当然,在许多情况下,我们所做的假设并不成立,比如可微系统和对底层机制的完全访问。
然而,这只是一个非常简单的例子,展示了如何在 TorchRL 中使用自定义环境编写训练循环。
让我们首先编写策略网络:
torch.manual_seed(0)
env.set_seed(0)net = nn.Sequential(nn.LazyLinear(64),nn.Tanh(),nn.LazyLinear(64),nn.Tanh(),nn.LazyLinear(64),nn.Tanh(),nn.LazyLinear(1),
)
policy = TensorDictModule(net,in_keys=["observation"],out_keys=["action"],
)
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/lazy.py:181: UserWarning:Lazy modules are a new feature under heavy development so changes to the API or functionality can happen at any moment.
和我们的优化器:
optim = torch.optim.Adam(policy.parameters(), lr=2e-3)
训练循环
我们将依次:
-
生成一个轨迹
-
对奖励求和
-
通过这些操作定义的图进行反向传播
-
裁剪梯度范数并进行优化步骤
-
重复
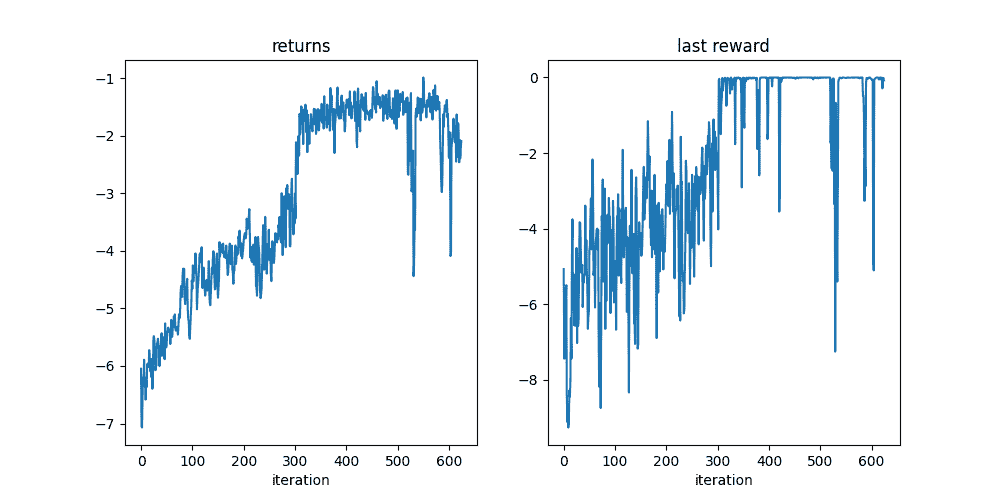
在训练循环结束时,我们应该有一个接近 0 的最终奖励,这表明摆锤向上并保持静止。
batch_size = 32
pbar = tqdm.tqdm(range(20_000 // batch_size))
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optim, 20_000)
logs = defaultdict(list)for _ in pbar:init_td = env.reset(env.gen_params(batch_size=[batch_size]))rollout = env.rollout(100, policy, tensordict=init_td, auto_reset=False)traj_return = rollout["next", "reward"].mean()(-traj_return).backward()gn = torch.nn.utils.clip_grad_norm_(net.parameters(), 1.0)optim.step()optim.zero_grad()pbar.set_description(f"reward: {traj_return: 4.4f}, "f"last reward: {rollout[..., -1]['next', 'reward'].mean(): 4.4f}, gradient norm: {gn: 4.4}")logs["return"].append(traj_return.item())logs["last_reward"].append(rollout[..., -1]["next", "reward"].mean().item())scheduler.step()def plot():import matplotlibfrom matplotlib import pyplot as pltis_ipython = "inline" in matplotlib.get_backend()if is_ipython:from IPython import displaywith plt.ion():plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)plt.plot(logs["return"])plt.title("returns")plt.xlabel("iteration")plt.subplot(1, 2, 2)plt.plot(logs["last_reward"])plt.title("last reward")plt.xlabel("iteration")if is_ipython:display.display(plt.gcf())display.clear_output(wait=True)plt.show()plot()
0%| | 0/625 [00:00<?, ?it/s]
reward: -6.0488, last reward: -5.0748, gradient norm: 8.518: 0%| | 0/625 [00:00<?, ?it/s]
reward: -6.0488, last reward: -5.0748, gradient norm: 8.518: 0%| | 1/625 [00:00<02:36, 3.99it/s]
reward: -7.0499, last reward: -7.4472, gradient norm: 5.073: 0%| | 1/625 [00:00<02:36, 3.99it/s]
reward: -7.0499, last reward: -7.4472, gradient norm: 5.073: 0%| | 2/625 [00:00<02:32, 4.08it/s]
reward: -7.0685, last reward: -7.0408, gradient norm: 5.552: 0%| | 2/625 [00:00<02:32, 4.08it/s]
reward: -7.0685, last reward: -7.0408, gradient norm: 5.552: 0%| | 3/625 [00:00<02:29, 4.15it/s]
reward: -6.5154, last reward: -5.9086, gradient norm: 2.526: 0%| | 3/625 [00:00<02:29, 4.15it/s]
reward: -6.5154, last reward: -5.9086, gradient norm: 2.526: 1%| | 4/625 [00:00<02:29, 4.14it/s]
reward: -6.2004, last reward: -5.9401, gradient norm: 7.964: 1%| | 4/625 [00:01<02:29, 4.14it/s]
reward: -6.2004, last reward: -5.9401, gradient norm: 7.964: 1%| | 5/625 [00:01<02:29, 4.14it/s]
reward: -6.2566, last reward: -5.4981, gradient norm: 4.446: 1%| | 5/625 [00:01<02:29, 4.14it/s]
reward: -6.2566, last reward: -5.4981, gradient norm: 4.446: 1%| | 6/625 [00:01<02:28, 4.17it/s]
reward: -5.8926, last reward: -8.4134, gradient norm: 2.108: 1%| | 6/625 [00:01<02:28, 4.17it/s]
reward: -5.8926, last reward: -8.4134, gradient norm: 2.108: 1%|1 | 7/625 [00:01<02:27, 4.19it/s]
reward: -6.3541, last reward: -9.1257, gradient norm: 2.045: 1%|1 | 7/625 [00:01<02:27, 4.19it/s]
reward: -6.3541, last reward: -9.1257, gradient norm: 2.045: 1%|1 | 8/625 [00:01<02:26, 4.20it/s]
reward: -6.2071, last reward: -8.8872, gradient norm: 11.97: 1%|1 | 8/625 [00:02<02:26, 4.20it/s]
reward: -6.2071, last reward: -8.8872, gradient norm: 11.97: 1%|1 | 9/625 [00:02<02:26, 4.20it/s]
reward: -6.5838, last reward: -9.2693, gradient norm: 3.34: 1%|1 | 9/625 [00:02<02:26, 4.20it/s]
reward: -6.5838, last reward: -9.2693, gradient norm: 3.34: 2%|1 | 10/625 [00:02<02:26, 4.21it/s]
reward: -6.2601, last reward: -9.0436, gradient norm: 4.874: 2%|1 | 10/625 [00:02<02:26, 4.21it/s]
reward: -6.2601, last reward: -9.0436, gradient norm: 4.874: 2%|1 | 11/625 [00:02<02:25, 4.21it/s]
reward: -6.3676, last reward: -8.2883, gradient norm: 2.542: 2%|1 | 11/625 [00:02<02:25, 4.21it/s]
reward: -6.3676, last reward: -8.2883, gradient norm: 2.542: 2%|1 | 12/625 [00:02<02:25, 4.21it/s]
reward: -5.9768, last reward: -8.4551, gradient norm: 2.931: 2%|1 | 12/625 [00:03<02:25, 4.21it/s]
reward: -5.9768, last reward: -8.4551, gradient norm: 2.931: 2%|2 | 13/625 [00:03<02:25, 4.22it/s]
reward: -5.9597, last reward: -8.0172, gradient norm: 5.493: 2%|2 | 13/625 [00:03<02:25, 4.22it/s]
reward: -5.9597, last reward: -8.0172, gradient norm: 5.493: 2%|2 | 14/625 [00:03<02:24, 4.22it/s]
reward: -6.0045, last reward: -6.3726, gradient norm: 1.216: 2%|2 | 14/625 [00:03<02:24, 4.22it/s]
reward: -6.0045, last reward: -6.3726, gradient norm: 1.216: 2%|2 | 15/625 [00:03<02:24, 4.22it/s]
reward: -6.0157, last reward: -7.4454, gradient norm: 4.614: 2%|2 | 15/625 [00:03<02:24, 4.22it/s]
reward: -6.0157, last reward: -7.4454, gradient norm: 4.614: 3%|2 | 16/625 [00:03<02:24, 4.22it/s]
reward: -5.7248, last reward: -4.7793, gradient norm: 11.7: 3%|2 | 16/625 [00:04<02:24, 4.22it/s]
reward: -5.7248, last reward: -4.7793, gradient norm: 11.7: 3%|2 | 17/625 [00:04<02:24, 4.21it/s]
reward: -5.8783, last reward: -3.7558, gradient norm: 7.704: 3%|2 | 17/625 [00:04<02:24, 4.21it/s]
reward: -5.8783, last reward: -3.7558, gradient norm: 7.704: 3%|2 | 18/625 [00:04<02:24, 4.21it/s]
reward: -6.0913, last reward: -6.0003, gradient norm: 17.23: 3%|2 | 18/625 [00:04<02:24, 4.21it/s]
reward: -6.0913, last reward: -6.0003, gradient norm: 17.23: 3%|3 | 19/625 [00:04<02:24, 4.20it/s]
reward: -5.9328, last reward: -5.2019, gradient norm: 3.004: 3%|3 | 19/625 [00:04<02:24, 4.20it/s]
reward: -5.9328, last reward: -5.2019, gradient norm: 3.004: 3%|3 | 20/625 [00:04<02:24, 4.20it/s]
reward: -6.1899, last reward: -6.5583, gradient norm: 8.905: 3%|3 | 20/625 [00:05<02:24, 4.20it/s]
reward: -6.1899, last reward: -6.5583, gradient norm: 8.905: 3%|3 | 21/625 [00:05<02:23, 4.20it/s]
reward: -5.8776, last reward: -6.3394, gradient norm: 86.04: 3%|3 | 21/625 [00:05<02:23, 4.20it/s]
reward: -5.8776, last reward: -6.3394, gradient norm: 86.04: 4%|3 | 22/625 [00:05<02:23, 4.19it/s]
reward: -6.3972, last reward: -6.5765, gradient norm: 20.42: 4%|3 | 22/625 [00:05<02:23, 4.19it/s]
reward: -6.3972, last reward: -6.5765, gradient norm: 20.42: 4%|3 | 23/625 [00:05<02:23, 4.20it/s]
reward: -6.3652, last reward: -5.7013, gradient norm: 4.733: 4%|3 | 23/625 [00:05<02:23, 4.20it/s]
reward: -6.3652, last reward: -5.7013, gradient norm: 4.733: 4%|3 | 24/625 [00:05<02:22, 4.21it/s]
reward: -5.5586, last reward: -6.3572, gradient norm: 7.792: 4%|3 | 24/625 [00:05<02:22, 4.21it/s]
reward: -5.5586, last reward: -6.3572, gradient norm: 7.792: 4%|4 | 25/625 [00:05<02:22, 4.20it/s]
reward: -5.4795, last reward: -4.5168, gradient norm: 1.692: 4%|4 | 25/625 [00:06<02:22, 4.20it/s]
reward: -5.4795, last reward: -4.5168, gradient norm: 1.692: 4%|4 | 26/625 [00:06<02:22, 4.21it/s]
reward: -5.5407, last reward: -7.0325, gradient norm: 773.3: 4%|4 | 26/625 [00:06<02:22, 4.21it/s]
reward: -5.5407, last reward: -7.0325, gradient norm: 773.3: 4%|4 | 27/625 [00:06<02:22, 4.20it/s]
reward: -5.7399, last reward: -6.0130, gradient norm: 2.865: 4%|4 | 27/625 [00:06<02:22, 4.20it/s]
reward: -5.7399, last reward: -6.0130, gradient norm: 2.865: 4%|4 | 28/625 [00:06<02:22, 4.20it/s]
reward: -6.0738, last reward: -6.5728, gradient norm: 2.833: 4%|4 | 28/625 [00:06<02:22, 4.20it/s]
reward: -6.0738, last reward: -6.5728, gradient norm: 2.833: 5%|4 | 29/625 [00:06<02:21, 4.20it/s]
reward: -6.0101, last reward: -6.4175, gradient norm: 6.212: 5%|4 | 29/625 [00:07<02:21, 4.20it/s]
reward: -6.0101, last reward: -6.4175, gradient norm: 6.212: 5%|4 | 30/625 [00:07<02:21, 4.20it/s]
reward: -5.9955, last reward: -4.7723, gradient norm: 3.158: 5%|4 | 30/625 [00:07<02:21, 4.20it/s]
reward: -5.9955, last reward: -4.7723, gradient norm: 3.158: 5%|4 | 31/625 [00:07<02:21, 4.21it/s]
reward: -5.6103, last reward: -3.8313, gradient norm: 5.422: 5%|4 | 31/625 [00:07<02:21, 4.21it/s]
reward: -5.6103, last reward: -3.8313, gradient norm: 5.422: 5%|5 | 32/625 [00:07<02:20, 4.21it/s]
reward: -5.6042, last reward: -3.8542, gradient norm: 5.069: 5%|5 | 32/625 [00:07<02:20, 4.21it/s]
reward: -5.6042, last reward: -3.8542, gradient norm: 5.069: 5%|5 | 33/625 [00:07<02:20, 4.21it/s]
reward: -5.5265, last reward: -4.3386, gradient norm: 2.368: 5%|5 | 33/625 [00:08<02:20, 4.21it/s]
reward: -5.5265, last reward: -4.3386, gradient norm: 2.368: 5%|5 | 34/625 [00:08<02:20, 4.21it/s]
reward: -5.6277, last reward: -5.1658, gradient norm: 25.25: 5%|5 | 34/625 [00:08<02:20, 4.21it/s]
reward: -5.6277, last reward: -5.1658, gradient norm: 25.25: 6%|5 | 35/625 [00:08<02:20, 4.21it/s]
reward: -5.6876, last reward: -5.1197, gradient norm: 110.2: 6%|5 | 35/625 [00:08<02:20, 4.21it/s]
reward: -5.6876, last reward: -5.1197, gradient norm: 110.2: 6%|5 | 36/625 [00:08<02:19, 4.21it/s]
reward: -6.0015, last reward: -4.9656, gradient norm: 1.3: 6%|5 | 36/625 [00:08<02:19, 4.21it/s]
reward: -6.0015, last reward: -4.9656, gradient norm: 1.3: 6%|5 | 37/625 [00:08<02:19, 4.22it/s]
reward: -5.6628, last reward: -6.0784, gradient norm: 10.63: 6%|5 | 37/625 [00:09<02:19, 4.22it/s]
reward: -5.6628, last reward: -6.0784, gradient norm: 10.63: 6%|6 | 38/625 [00:09<02:19, 4.22it/s]
reward: -5.8188, last reward: -5.3053, gradient norm: 20.95: 6%|6 | 38/625 [00:09<02:19, 4.22it/s]
reward: -5.8188, last reward: -5.3053, gradient norm: 20.95: 6%|6 | 39/625 [00:09<02:19, 4.21it/s]
reward: -5.5934, last reward: -5.4250, gradient norm: 2.52: 6%|6 | 39/625 [00:09<02:19, 4.21it/s]
reward: -5.5934, last reward: -5.4250, gradient norm: 2.52: 6%|6 | 40/625 [00:09<02:19, 4.20it/s]
reward: -5.4317, last reward: -5.2191, gradient norm: 11.53: 6%|6 | 40/625 [00:09<02:19, 4.20it/s]
reward: -5.4317, last reward: -5.2191, gradient norm: 11.53: 7%|6 | 41/625 [00:09<02:19, 4.20it/s]
reward: -5.8227, last reward: -5.2263, gradient norm: 5.554: 7%|6 | 41/625 [00:10<02:19, 4.20it/s]
reward: -5.8227, last reward: -5.2263, gradient norm: 5.554: 7%|6 | 42/625 [00:10<02:19, 4.19it/s]
reward: -5.6086, last reward: -3.3930, gradient norm: 13.2: 7%|6 | 42/625 [00:10<02:19, 4.19it/s]
reward: -5.6086, last reward: -3.3930, gradient norm: 13.2: 7%|6 | 43/625 [00:10<02:18, 4.19it/s]
reward: -5.5969, last reward: -4.8821, gradient norm: 2.538: 7%|6 | 43/625 [00:10<02:18, 4.19it/s]
reward: -5.5969, last reward: -4.8821, gradient norm: 2.538: 7%|7 | 44/625 [00:10<02:18, 4.19it/s]
reward: -5.5018, last reward: -4.3099, gradient norm: 3.416: 7%|7 | 44/625 [00:10<02:18, 4.19it/s]
reward: -5.5018, last reward: -4.3099, gradient norm: 3.416: 7%|7 | 45/625 [00:10<02:18, 4.18it/s]
reward: -5.6813, last reward: -5.1515, gradient norm: 19.79: 7%|7 | 45/625 [00:10<02:18, 4.18it/s]
reward: -5.6813, last reward: -5.1515, gradient norm: 19.79: 7%|7 | 46/625 [00:10<02:18, 4.17it/s]
reward: -5.8823, last reward: -5.6010, gradient norm: 12.73: 7%|7 | 46/625 [00:11<02:18, 4.17it/s]
reward: -5.8823, last reward: -5.6010, gradient norm: 12.73: 8%|7 | 47/625 [00:11<02:18, 4.17it/s]
reward: -5.2582, last reward: -6.6556, gradient norm: 6.568: 8%|7 | 47/625 [00:11<02:18, 4.17it/s]
reward: -5.2582, last reward: -6.6556, gradient norm: 6.568: 8%|7 | 48/625 [00:11<02:17, 4.18it/s]
reward: -5.6368, last reward: -6.3310, gradient norm: 8.046: 8%|7 | 48/625 [00:11<02:17, 4.18it/s]
reward: -5.6368, last reward: -6.3310, gradient norm: 8.046: 8%|7 | 49/625 [00:11<02:17, 4.18it/s]
reward: -5.6776, last reward: -6.1928, gradient norm: 4.976: 8%|7 | 49/625 [00:11<02:17, 4.18it/s]
reward: -5.6776, last reward: -6.1928, gradient norm: 4.976: 8%|8 | 50/625 [00:11<02:17, 4.18it/s]
reward: -5.6418, last reward: -4.5608, gradient norm: 2.355: 8%|8 | 50/625 [00:12<02:17, 4.18it/s]
reward: -5.6418, last reward: -4.5608, gradient norm: 2.355: 8%|8 | 51/625 [00:12<02:17, 4.18it/s]
reward: -5.4142, last reward: -4.4533, gradient norm: 3.903: 8%|8 | 51/625 [00:12<02:17, 4.18it/s]
reward: -5.4142, last reward: -4.4533, gradient norm: 3.903: 8%|8 | 52/625 [00:12<02:16, 4.19it/s]
reward: -5.3920, last reward: -3.6933, gradient norm: 5.534: 8%|8 | 52/625 [00:12<02:16, 4.19it/s]
reward: -5.3920, last reward: -3.6933, gradient norm: 5.534: 8%|8 | 53/625 [00:12<02:16, 4.19it/s]
reward: -5.3322, last reward: -3.1984, gradient norm: 4.058: 8%|8 | 53/625 [00:12<02:16, 4.19it/s]
reward: -5.3322, last reward: -3.1984, gradient norm: 4.058: 9%|8 | 54/625 [00:12<02:16, 4.19it/s]
reward: -5.3709, last reward: -4.5488, gradient norm: 37.33: 9%|8 | 54/625 [00:13<02:16, 4.19it/s]
reward: -5.3709, last reward: -4.5488, gradient norm: 37.33: 9%|8 | 55/625 [00:13<02:16, 4.19it/s]
reward: -5.4076, last reward: -3.1880, gradient norm: 1.395: 9%|8 | 55/625 [00:13<02:16, 4.19it/s]
reward: -5.4076, last reward: -3.1880, gradient norm: 1.395: 9%|8 | 56/625 [00:13<02:16, 4.18it/s]
reward: -5.3727, last reward: -2.1695, gradient norm: 2.613: 9%|8 | 56/625 [00:13<02:16, 4.18it/s]
reward: -5.3727, last reward: -2.1695, gradient norm: 2.613: 9%|9 | 57/625 [00:13<02:15, 4.19it/s]
reward: -5.6188, last reward: -2.7869, gradient norm: 1.464: 9%|9 | 57/625 [00:13<02:15, 4.19it/s]
reward: -5.6188, last reward: -2.7869, gradient norm: 1.464: 9%|9 | 58/625 [00:13<02:15, 4.19it/s]
reward: -5.4788, last reward: -5.2309, gradient norm: 12.19: 9%|9 | 58/625 [00:14<02:15, 4.19it/s]
reward: -5.4788, last reward: -5.2309, gradient norm: 12.19: 9%|9 | 59/625 [00:14<02:16, 4.15it/s]
reward: -5.1972, last reward: -5.1203, gradient norm: 67.95: 9%|9 | 59/625 [00:14<02:16, 4.15it/s]
reward: -5.1972, last reward: -5.1203, gradient norm: 67.95: 10%|9 | 60/625 [00:14<02:15, 4.16it/s]
reward: -5.4977, last reward: -4.8712, gradient norm: 4.688: 10%|9 | 60/625 [00:14<02:15, 4.16it/s]
reward: -5.4977, last reward: -4.8712, gradient norm: 4.688: 10%|9 | 61/625 [00:14<02:15, 4.17it/s]
reward: -5.4804, last reward: -6.0890, gradient norm: 3.287: 10%|9 | 61/625 [00:14<02:15, 4.17it/s]
reward: -5.4804, last reward: -6.0890, gradient norm: 3.287: 10%|9 | 62/625 [00:14<02:14, 4.19it/s]
reward: -5.3051, last reward: -4.3689, gradient norm: 64.25: 10%|9 | 62/625 [00:15<02:14, 4.19it/s]
reward: -5.3051, last reward: -4.3689, gradient norm: 64.25: 10%|# | 63/625 [00:15<02:14, 4.19it/s]
reward: -5.3228, last reward: -4.2780, gradient norm: 9.055: 10%|# | 63/625 [00:15<02:14, 4.19it/s]
reward: -5.3228, last reward: -4.2780, gradient norm: 9.055: 10%|# | 64/625 [00:15<02:14, 4.16it/s]
reward: -5.1394, last reward: -4.0425, gradient norm: 9.393: 10%|# | 64/625 [00:15<02:14, 4.16it/s]
reward: -5.1394, last reward: -4.0425, gradient norm: 9.393: 10%|# | 65/625 [00:15<02:14, 4.17it/s]
reward: -5.2673, last reward: -4.0022, gradient norm: 8.597: 10%|# | 65/625 [00:15<02:14, 4.17it/s]
reward: -5.2673, last reward: -4.0022, gradient norm: 8.597: 11%|# | 66/625 [00:15<02:14, 4.17it/s]
reward: -5.1040, last reward: -4.5461, gradient norm: 18.81: 11%|# | 66/625 [00:15<02:14, 4.17it/s]
reward: -5.1040, last reward: -4.5461, gradient norm: 18.81: 11%|# | 67/625 [00:15<02:13, 4.17it/s]
reward: -5.3599, last reward: -4.0312, gradient norm: 34.25: 11%|# | 67/625 [00:16<02:13, 4.17it/s]
reward: -5.3599, last reward: -4.0312, gradient norm: 34.25: 11%|# | 68/625 [00:16<02:13, 4.18it/s]
reward: -5.3867, last reward: -6.7588, gradient norm: 4.311: 11%|# | 68/625 [00:16<02:13, 4.18it/s]
reward: -5.3867, last reward: -6.7588, gradient norm: 4.311: 11%|#1 | 69/625 [00:16<02:13, 4.18it/s]
reward: -5.3548, last reward: -8.1878, gradient norm: 44.19: 11%|#1 | 69/625 [00:16<02:13, 4.18it/s]
reward: -5.3548, last reward: -8.1878, gradient norm: 44.19: 11%|#1 | 70/625 [00:16<02:12, 4.18it/s]
reward: -5.3264, last reward: -6.2046, gradient norm: 6.25: 11%|#1 | 70/625 [00:16<02:12, 4.18it/s]
reward: -5.3264, last reward: -6.2046, gradient norm: 6.25: 11%|#1 | 71/625 [00:16<02:12, 4.19it/s]
reward: -5.3723, last reward: -5.9680, gradient norm: 11.1: 11%|#1 | 71/625 [00:17<02:12, 4.19it/s]
...
结论
在本教程中,我们学习了如何从头开始编码一个无状态环境。我们涉及了以下主题:
-
编码环境时需要注意的四个基本组件(
step、reset、种子和构建规范)。我们看到这些方法和类如何与TensorDict类交互; -
如何测试环境是否正确编码使用
check_env_specs(); -
如何在无状态环境的上下文中追加转换以及如何编写自定义转换;
-
如何在完全可微分的模拟器上训练策略。
脚本的总运行时间:(2 分钟 30.147 秒)
下载 Python 源代码:pendulum.py
下载 Jupyter 笔记本:pendulum.ipynb
Sphinx-Gallery 生成的画廊