💓博主CSDN主页:杭电码农-NEO💓
⏩专栏分类:项目日记-高并发内存池⏪
🚚代码仓库:NEO的学习日记🚚
🌹关注我🫵带你做项目
🔝🔝
开发环境:Visual Studio 2022

项目日记
- 1. 前言
- 2. 整体项目测试
- 3. 项目的效率上限分析
- 4. 效率上限问题的解决方法
- 5. 项目的缺陷分析
- 6. 项目总结
1. 前言
整个项目的代码和框架就已经介绍
完毕了,项目的所有代码在下面的链接:
gitee代码仓库项目源代码
本章重点:
本篇文章着重讲解本项目是如何测试的,
以及本代码的一些效率上限问题,最后会
引入基数树来对项目整体做优化
2. 整体项目测试
对本项目的测试无非就是将自己写的
内存池与C语言的malloc做对比,代码如下:
#include<cstdio>
#include<iostream>
#include<vector>
#include<thread>
#include<mutex>
#include"ConcurrentAlloc.h"
using namespace std;
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)//ntime一轮申请和释放内存的次数,round是跑多少轮,nworks是线程数
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(malloc(16));v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime.load());printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime.load());printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(ConcurrentAlloc(16));v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime.load());printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime.load());printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
int main()
{size_t n = 10000;cout << "==========================================================" << endl;BenchmarkConcurrentMalloc(n, 10, 10);cout << endl << endl;BenchmarkMalloc(n, 10, 10);cout << "==========================================================" <<endl;return 0;
}
本代码是现成的,不用在意细节
当我们运行代码后会发现,为什么我们自己写的内存池的效率比不上C语言中的malloc函数,这一点显然超出了我们的预期,下面就来分析一下项目的效率上限问题
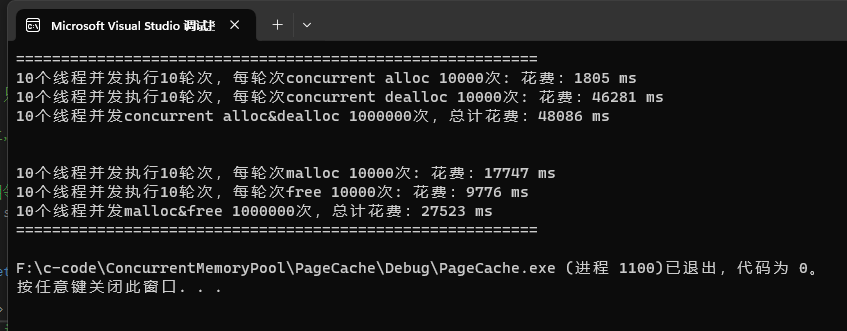
3. 项目的效率上限分析
在vs的调试中有一个性能探测器
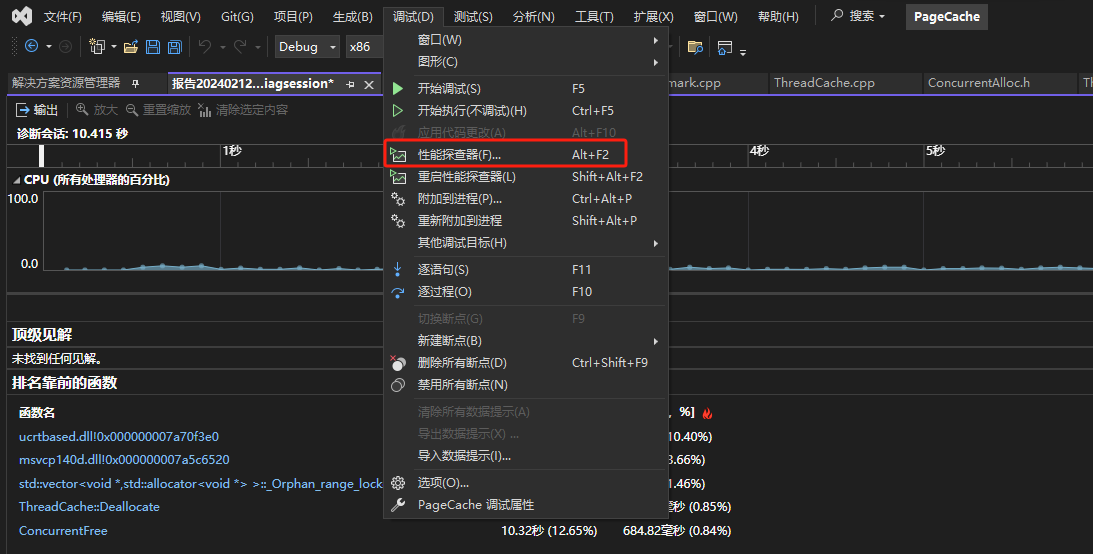
我们可以使用这个功能来分析哪个步骤比较用时,当我们完成检测后会发现,在pagecache文件中的函数耗时都比较久,其实我们隐约已经知道问题出现在哪里了,我们知道unordered_map的底层是哈希桶结构,然而find函数会将每一个桶中的链表都遍历一遍,直到找到了对应的key值,很明显这个查找的过程是比较费时的,并且如果不切换一个容器来代替unordered_map的话,在这个基础上不管怎样去优化都不会有质的提升!!!
4. 效率上限问题的解决方法
对于上面的问题显然超出了我们的能力范围,对于一个C++的初学者来说,标准库中的容器已经是很优秀的了,如果要抛弃标准库,我们也不能写出更好的,所以这里直接将TCmalloc开源项目中的解决方法给搬过来,谷歌的团队使用了一个叫基数树的结构来完美的解决此问题
基数树的文档说明: 基数树百度百科
由于基数树属于此项目的拓展内容,所以这里就不详细介绍了,完美直接把代码搬出来用就可以了!
#pragma once
#include"shared.h"
// Single-level array
template <int BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS;void** array_;public:typedef uintptr_t Number;//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap1() {//array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*) << BITS));size_t size = sizeof(void*) << BITS;size_t alignSize = AlignmentRule::_AlignUp(size, 1 << PAGE_SHIFT);array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);memset(array_, 0, sizeof(void*) << BITS);}// Return the current value for KEY. Returns NULL if not yet set,// or if k is out of range.void* get(Number k) const {if ((k >> BITS) > 0) {return NULL;}return array_[k];}// REQUIRES "k" is in range "[0,2^BITS-1]".// REQUIRES "k" has been ensured before.// Sets the value 'v' for key 'k'.void set(Number k, void* v) {array_[k] = v;}
};
之后将所有使用unordered_map的地方都替换成基数树的get和set函数即可!现在我们再来测试一下整个项目的性能如何:
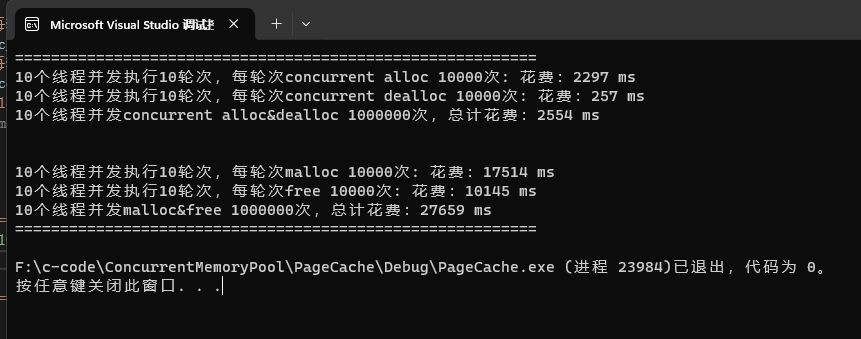
使用基数树后,整个效率就比malloc快了!
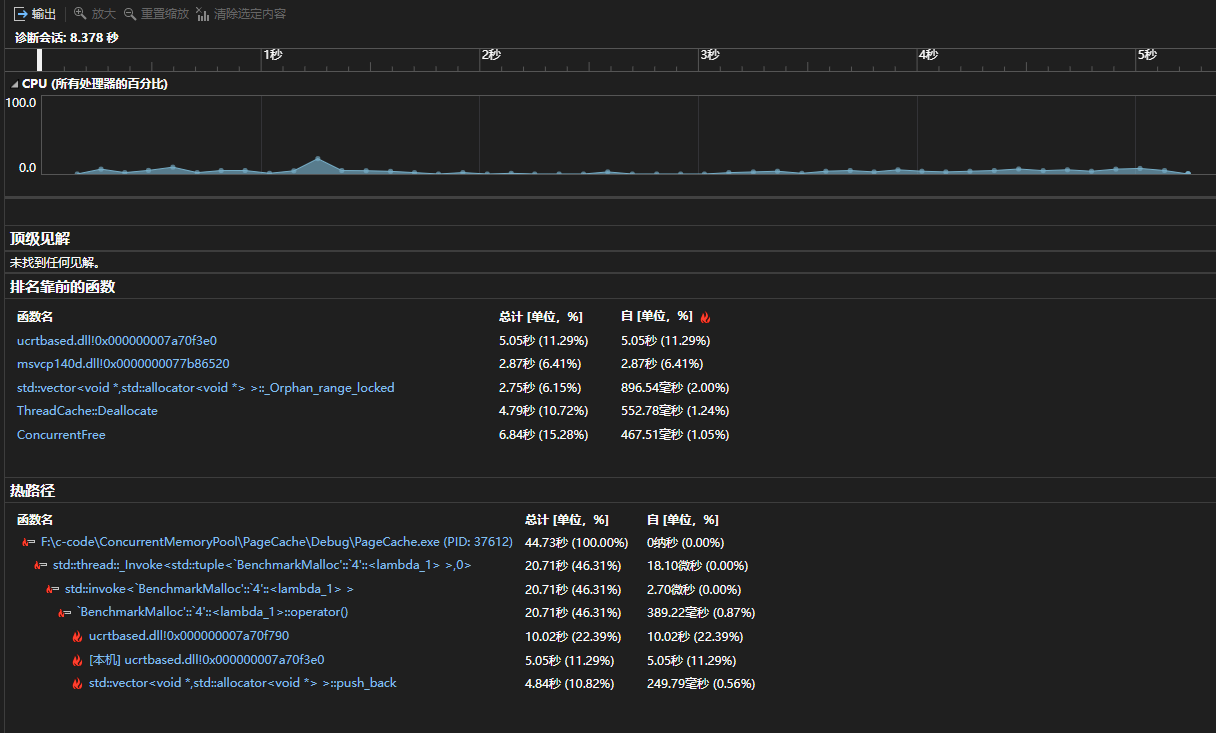
5. 项目的缺陷分析
本项目看似每一步都做的天衣无缝,申请
和释放内存一层一层不断递进,但是它有
一个致命的缺陷,那就是内存泄漏问题:
bug出现的情景:
假设线程缓存的K号桶中有10个小块儿内存挂在桶上,此时K号桶向中心缓存申请的小块儿内存个数是7个,小于了桶中小块儿内存的个数,此时会将线程缓存中的7个小块儿内存还给中心缓存,那么也就还剩下三个小块儿内存在桶中没有被还回去,此时如果没有线程来这个桶中申请或释放内存,那么这三块儿内存就会一直挂在桶上,既无法释放它,又失去了对它的控制从而造成内存泄漏!
解决bug的方式:
博主本人比较推荐的方式就是在每次使用完内存池后,手动调用一个释放内存的函数对每一个桶进行遍历,来释放还没有被使用的小块儿内存
6. 项目总结
高并发内存池项目到这里就结项了,
三层缓存结构设计的非常之巧妙,做
这个项目为了去解决某个问题,而是
去学习别人的优秀的,先进的思想





![linux信号机制[一]](https://img-blog.csdnimg.cn/direct/30d249e454374316adf51e33c7f72e06.png)