目录
一、架构及组件介绍
1.1 Hive整体架构
1.2 Hive组件
1.3 Hive数据模型(Data Model)
1.3.1 Databases
1.3.2 Tables
1.3.3 Partitions
1.3.4 Buckets
二、Hive读写文件机制
2.1 SerDe 作用
2.2 Hive读写文件流程
2.2.1 读取文件的过程
2.2.2 写入文件的过程
2.3 SerDe相关语法
2.3.1 LazySimpleSerDe分隔符指定
2.3.2 默认分隔符
2.4 Hive数据存储路径
2.4.1 默认存储路径
2.4.2 指定存储路径
一、架构及组件介绍
1.1 Hive整体架构
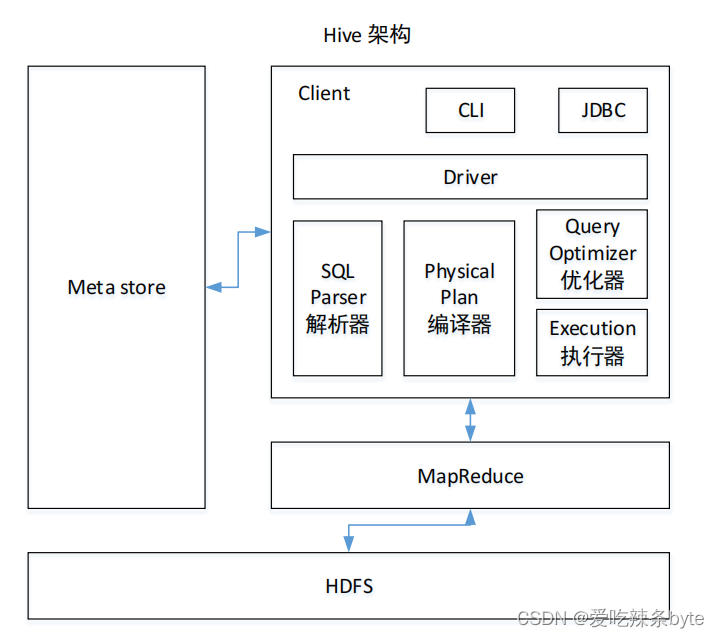
1.2 Hive组件
- 用户接口:Client
- CLI:shell命令行
- JDBC/ODBC:Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议
- WEBUI:通过浏览器访问Hive
- 元数据:Metastore
元数据通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- Hadoop
数据使用 HDFS 进行存储,使用 MapReduce 进行计算。
- 驱动器:Driver
- 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第 三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
- 编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。当下Hive支持MapReduce、Tez、Spark3种执行引擎
Driver驱动器总结:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,随后执行引擎调用执行。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
1.3 Hive数据模型(Data Model)
模型用来描述数据,组织数据和对数据进行操作。
Hive的数据模型类似于RDMS库表结构,此外它还有自己特有的模型。Hive中的数据可以在粒度级别分为三类:Table类、Partition分区、Bucket分桶。
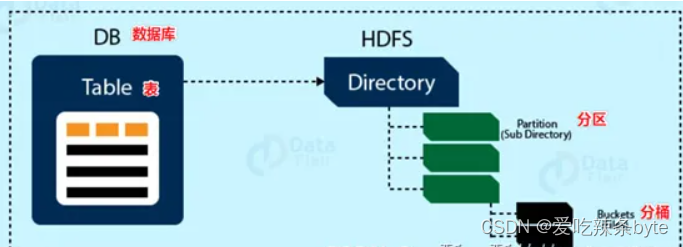
1.3.1 Databases
Hive的数据存储在HDFS上的,默认有一个根目录,在hive-site.xml配置文件中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。
Hive中的数据库在HDFS上的存储路径为:${hive.metastore.warehouse.dir}/databasename.db
比如,名为test的数据库存储路径为:/user/hive/warehouse/test.db
1.3.2 Tables
Hive表与关系数据库中的表相同,Hive中的表所对应的数据是存储在Hadoop的文件系统中,而表相关的元数据是存储在RDBMS中。Hive有两种类型的表,分别是Managed Table内部表、External Table外部表。创建表时,默是内部表。
Hive中的表的数据在HDFS上的存储路径为:${hive.metastore.warehouse.dir}/databasename.db/tablename
比如,test的数据库下t_user表存储路径为:/user/hive/warehouse/test.db/t_user
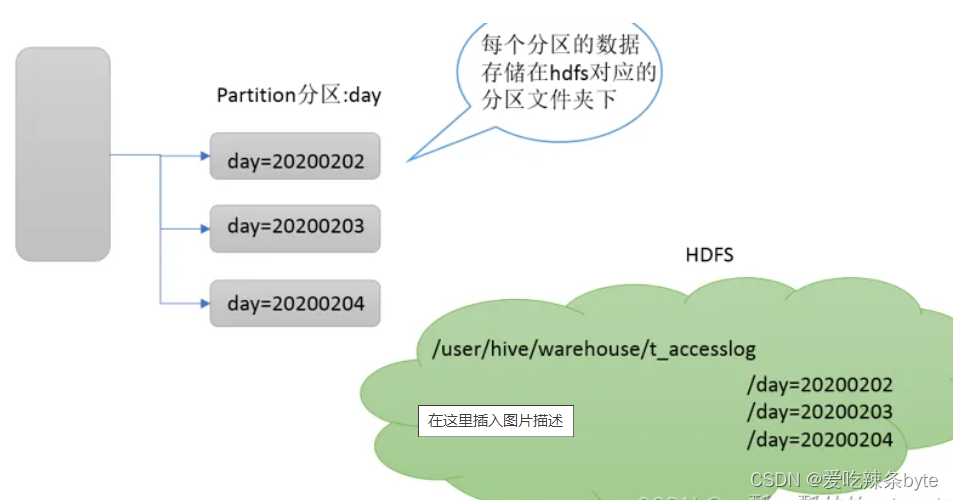
1.3.3 Partitions
Partition分区表是hive的一种优化手段表,当Hive表数据量大,查询时通过 where子句筛选指定的分区,这样的查询效率会提高很多,避免全表扫描。
Hive支持根据指定的字段进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。分区在存储层面上的表现是table表目录下以子文件夹形式存在。一个文件夹表示一个分区。子文件命名标准:分区列=分区值,Hive还支持分区下继续创建分区,所谓的多重分区。
1.3.4 Buckets
Bucket分桶表是hive的一种优化手段表。分桶是指数据表中某字段的值,经过hash计算规则将数据分为指定的若干小文件。Bucket分桶表在hdfs中表现为同一个表目录下的数据根据hash散列之后变成多个文件。分区针对的是数据的存储路径;分桶针对的是数据文件(数据粒度更细)。
分桶默认规则是:分桶编号Bucket number = hash_function(分桶字段) % 桶数量。桶编号相同的数据会被分到同一个桶当中。
ps:hash_function函数取决于分桶字段的数据类型,如果是int类型,hash_function(int) == int; 如果是其他数据类型,比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。



二、Hive读写文件机制
2.1 SerDe 作用
SerDe是Serializer、Deserializer的简称,目的是用于序列化和反序列化。序列化是对象转化为字节码的过程(写);而反序列化是字节码转换为对象(读)的过程。
# 读过程:反序列化
HDFS files --> InputFileFormat --> <key,value> --> Deserializer(反序列化) --> Row Object
# 写过程: 序列化
Row Object --> serializer(序列化) --> <key,value> --> OutputFileFormat --> HDFS files通过desc formatted tablename 查看表的相关SerDe信息,SerDe默认:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
例如以t_order 为例:
---建表
CREATE TABLE t_order (oid int ,uid int ,otime string,oamount int)
ROW format delimited FIELDS TERMINATED BY ",";---插入数据
load data local inpath "/opt/module/hive_data/t_order.txt" into table t_order;#== 查看t_order表的详细信息
desc formatted t_order;
2.2 Hive读写文件流程
DeveloperGuide - Apache Hive - Apache Software Foundation![]() https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide#DeveloperGuide-HiveSerDe
https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide#DeveloperGuide-HiveSerDe
2.2.1 读取文件的过程
- 流程:
HDFS files --> InputFileFormat --> <key,value> --> Deserializer(反序列化) --> Row Object
- 机制:
首先调用InputFormat(默认TextInputFormat)进行一行一行的读取,返回kv键值对记录(默认是一行对应一条记录)。然后调用SerDe(默认LazySimpleSerDe)的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
2.2.2 写入文件的过程
- 流程:
Row Object --> serializer(序列化) --> <key,value> --> OutputFileFormat --> HDFS files
- 机制:
将Row写入文件时,首先调用SerDe(默认LazySimpleSerDe)的Serializer将对象转换成字节序列。然后调用OutputFormat将数据写入HDFS文件中。
2.3 SerDe相关语法
SerDe语法指路:
LanguageManual DDL - Apache Hive - Apache Software Foundation![]() https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-RowFormats&SerDe在Hive建表语句中,和 SerDe相关的语法:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-RowFormats&SerDe在Hive建表语句中,和 SerDe相关的语法:
- hive的建表语法
# 建表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]- 字段解释说明
(7) ROW FORMAT:ROW FORMAT是语法关键字,以下的DELIMITED和SERDE二选其一。
- DELIMITED [FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
- SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe 。如果没有指定 ROWFORMAT 或者 ROW FORMAT DELIMITED ,将会使用自带的 SerDe 。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe , Hive 通过 SerDe 确定表 的具体的列的数据。SerDe 是 Serialize/Deserilize 的简称, hive 使用 Serde 进行行对象的序列与反序列化。
#==== 例如:支付表的建表语句
DROP TABLE IF EXISTS ods_payment_info_inc;
CREATE EXTERNAL TABLE ods_payment_info_inc
(`type` STRING COMMENT '变动类型',`ts` BIGINT COMMENT '变动时间',`data` STRUCT<id :STRING,out_trade_no :STRING,order_id :STRING,user_id :STRING,payment_type :STRING,trade_no:STRING,total_amount :DECIMAL(16, 2),subject :STRING,payment_status :STRING,create_time :STRING,callback_time:STRING,callback_content :STRING> COMMENT '数据',`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '支付表'PARTITIONED BY (`dt` STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'LOCATION '/warehouse/gmall/ods/ods_payment_info_inc/';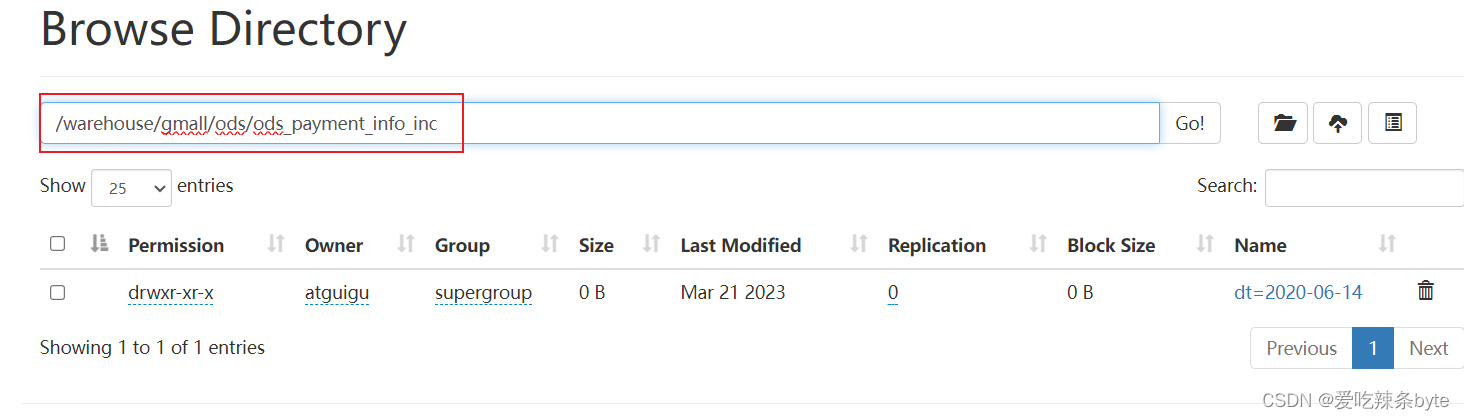
2.3.1 LazySimpleSerDe分隔符指定
LazySimpleSerDe是Hive默认的序列化类,包含4种子语法,分别用于指定字段之间、集合元素之间、map映射 kv之间、换行的分隔符号。在建表的时候可以根据数据的特点灵活搭配使用。
DELIMITED [FIELDS TERMINATED BY char] --- 字段之间的分隔符[COLLECTION ITEMS TERMINATED BY char] --- 集群元素之间的分隔符[MAP KEYS TERMINATED BY char] --- map映射kv之间的分隔符[LINES TERMINATED BY char] --- 行数据之间的分隔符2.3.2 默认分隔符
hive建表时如果没有row format语法。此时字段之间默认的分割符是’\001’
2.4 Hive数据存储路径
2.4.1 默认存储路径
Hive表默认存储路径是由 ${HIVE_HOME}/conf/hive-site.xml配置文件的hive.metastore.warehouse.dir属性指定,默认值是:/user/hive/warehouse。在该路径下,文件将根据所属的库、表,有规律的存储在对应的文件夹下。

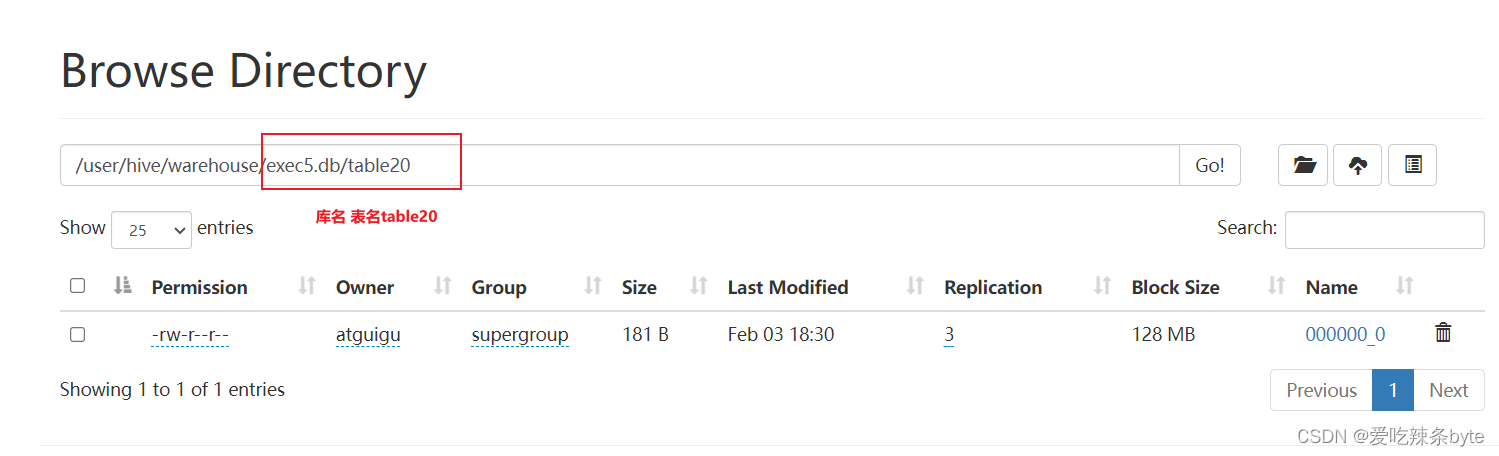
2.4.2 指定存储路径
在Hive建表的时候,可以通过location语法来更改数据在HDFS上的存储路径,使得建表加载数据更加灵活方便,语法为:LOCATION ‘<hdfs_location>’
# 建表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path] # ===指定表在 HDFS 上的存储位置。
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]# ====例如:退单表的建表语句
DROP TABLE IF EXISTS ods_order_refund_info_inc;
CREATE EXTERNAL TABLE ods_order_refund_info_inc
(`type` STRING COMMENT '变动类型',`ts` BIGINT COMMENT '变动时间',`data` STRUCT<id :STRING,user_id :STRING,order_id :STRING,sku_id :STRING,refund_type :STRING,refund_num :BIGINT,refund_amount:DECIMAL(16, 2),refund_reason_type :STRING,refund_reason_txt :STRING,refund_status :STRING,create_time:STRING> COMMENT '数据',`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '退单表'PARTITIONED BY (`dt` STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe' --指定serDELOCATION '/warehouse/gmall/ods/ods_order_refund_info_inc/'; -- 指定在hdfs上存储位置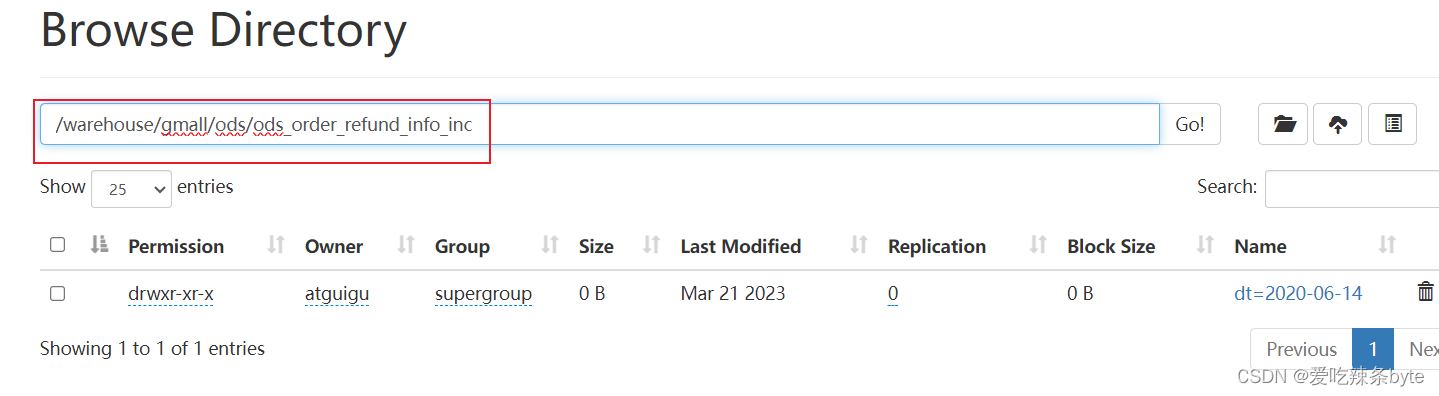







![[缓存] - 2.分布式缓存重磅中间件 Redis](https://img-blog.csdnimg.cn/direct/5f51738e7bee4276b355027229f6e512.png)