提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- Integration 系列表引擎
- 1 HDFS
- 1.1 语法
- 1.2 示例:
- 2 MySQL
- 2.1 语法
- 2.2 示例:
- 3 Kafka
- 3.1 语法
- 3.2 示例:
- 3.3 数据持久化方法
Integration 系列表引擎
- ClickHouse 提供了许多与外部系统集成的方法,包括一些表引擎。这些表引擎与其他类型的表引擎类似,可以用于将外部数据导入到ClickHouse 中,或者在 ClickHouse中直接操作外部数据源。
1 HDFS
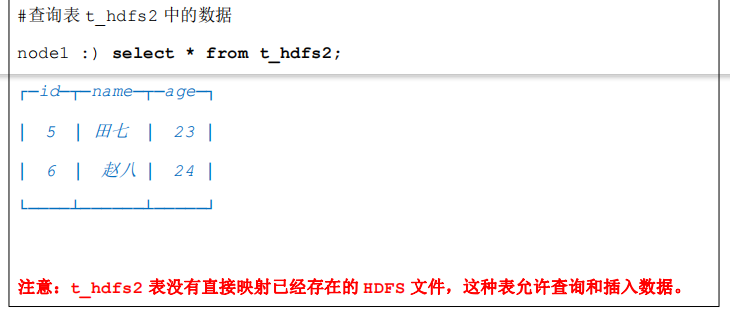
- HDFS 引擎支持 ClickHouse 直接读取 HDFS 中特定格式的数据文件,目前文件格式支持 Json,Csv文件等,ClickHouse 通过 HDFS 引擎建立的表,不会在 ClickHouse 中产生数据,读取的是 HDFS 中的数据,将HDFS 中的数据映射成 ClickHouse 中的一张表这样就可以使用 SQL 操作 HDFS 中的数据。
- ClickHouse 并不能够删除 HDFS 上的数据,当我们在 ClickHouse 客户端中删除了对应的表,只是删除了表结构,HDFS 上的文件并没有被删除,这一点跟 Hive 的外部表十分相似
1.1 语法

1.2 示例:
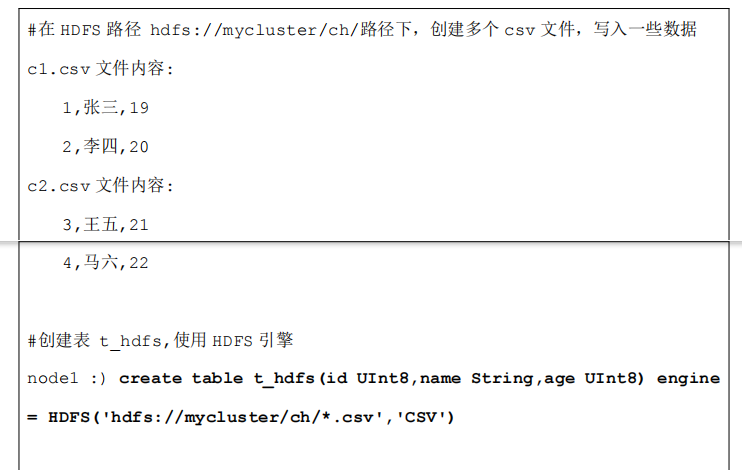

2 MySQL
- ClickHouse MySQL数据库引擎可以将MySQL 某个库下的表映射到 ClickHouse中, 使用 ClickHouse对数据进行操作。ClickHouse 同样支持 MySQL 表引擎,即映射一张 MySQL 中的表到 ClickHouse 中,使用 ClickHouse 进行数据操作,与 MySQL 数据库引 擎一样,这里映射的表只能做查询和插入操作,不支持删除和更新操作。
2.1 语法
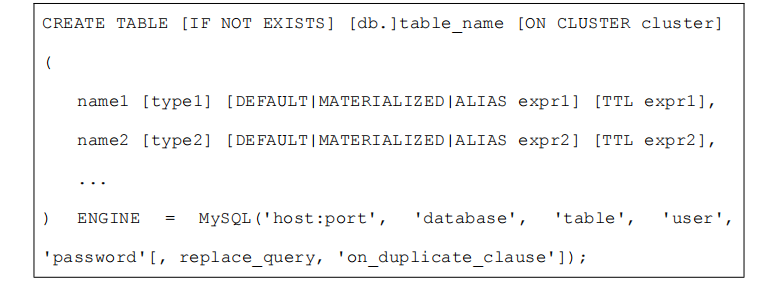

2.2 示例:


测试 replace_query :


测试 on_duplicate_clause:


3 Kafka
- ClickHouse 中还可以创建表指定为 Kafka 为表引擎,这样创建出的表可以查询到 Kafka中的流数据。对应创建的表不会将数据存入 ClickHouse 中,这里这张 kafka 引 擎表相当于一个消费者,消费 Kafka中的数据,数据被查询过后,就不会再次被查询到。
3.1 语法
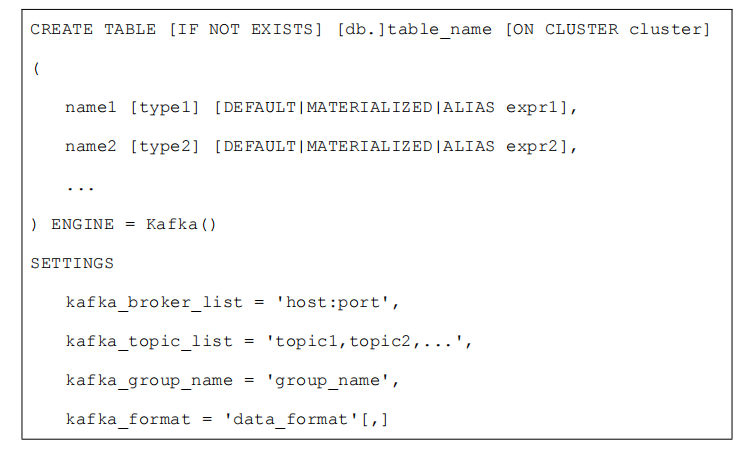

3.2 示例:


3.3 数据持久化方法


示例2