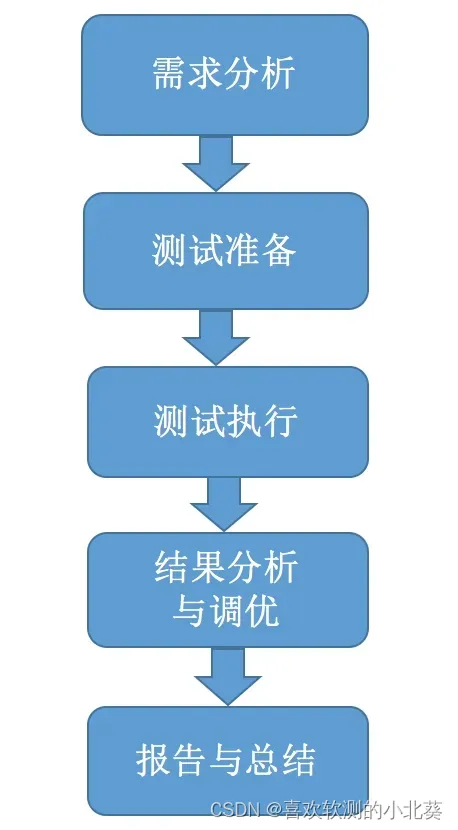
- 一. 分库分表介绍
- 二. 分库分表实践
一. 分库分表介绍
1.1 分库分表解决了什么问题
- 先说分库:
- 《高性能MySQL》中提到了两种数据库扩展方式:垂直扩展和水平扩展。前者意味着买更多性能强悍的硬件,但是总会达到扩展的天花板,且成本较高。分库则是后者的一种实现方式。
- 流量瓶颈:主要是写多的场景(读多可以通过读写分离,缓存等方式解决问题),而单集群写在大流量下是易达到瓶颈的。
- 容量瓶颈:数据量大的情况下,单集群磁盘不够存储(尤其对于订单类的业务,即使有归档等手段,也难以支撑一定时间范围内的数据存储)。
- 再说分表
- 分表主要解决单表过大问题(DBA推荐单表容量在1000万行左右):随着表增大,从经验上看会引起慢查询(即使SQL语句很简单且走了索引),分表有利于提高读写效率
1.2 分库分表的方式
分表通常可分为水平分表和垂直分表
- 垂直分表:把大表的字段拆分,拆成小表。如把order表拆成order_major(包含热点字段)和order_extra(包含冷门字段)
- 优点:热点数据分离,热点表走主库,冷门表走从库
- 水平分表:水平分表就是指以行为单位对数据进行拆分,一般分库分表指的就是水平分表
- 优点:优化单表行数过大,提高性能
1.3 分库分表的基本原理
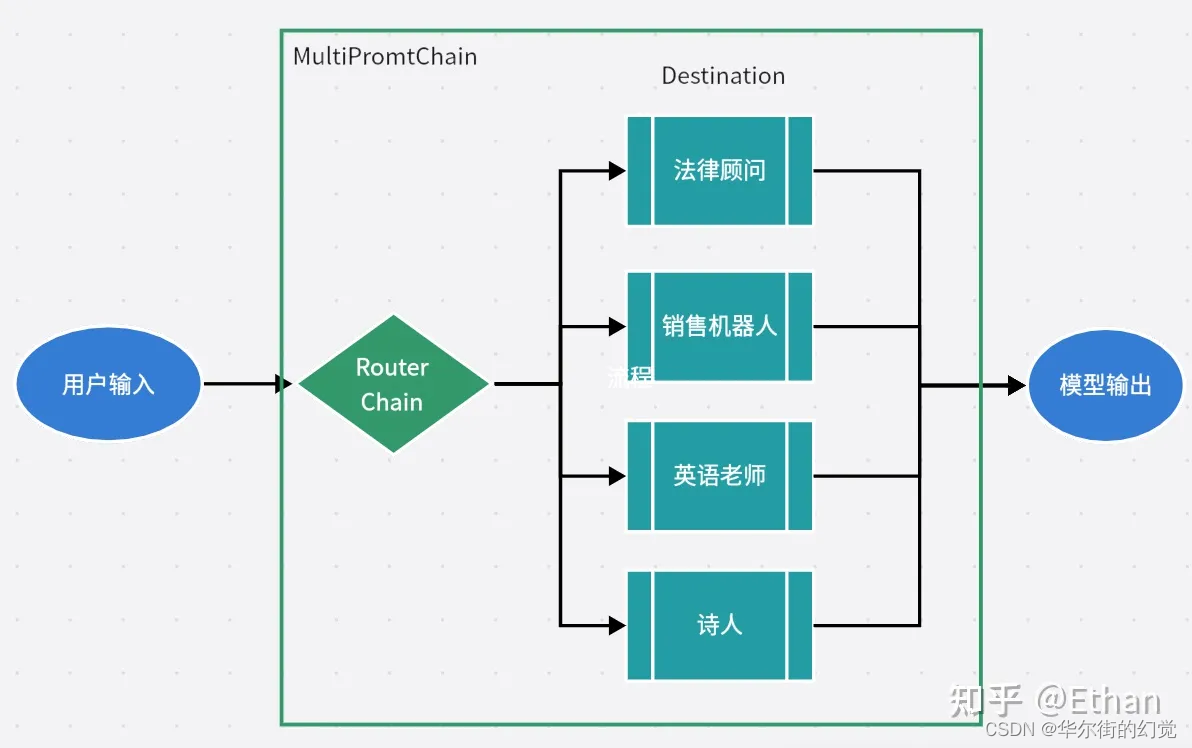
选择一个或多个路由键(routeKey,也可称分片),根据该路由键及路由规则,将SQL路由至不同的分库及分表。
- 如分10库,每库100表,路由键为userId
- 库路由规则:#userId#%10
- 表路由规则:(#userId#).intdiv(10)%100
- 代表含义:uid=100001会路由到1库0表中;uid=100329会路由到9库32表中
1.4 分库分表需要注意的问题
- (1)自增主键无法标识唯一id,需要依赖分布式ID生成服务
- (2)路由键的选择(拆分的维度):如订单表,假如又要根据订单id查询,又要根据用户id查询,该怎么解决
- 思路一:系统拆分(实现成本高)
- 思路二:建路由表(订单表以订单id为路由键;新建一张用户id与订单id的路由表,以用户id作为路由键)——> 注意分布式事务问题
- (3)分布式事务问题:跨库就会涉及到分布式事务问题,除非所有操作的表都基于相同的路由键与路由规则
- (4)路由键的选择:数据倾斜
- (5)可扩展性:如果当前已经是分库分表,未来再扩容,建议以倍数扩(如2—>4,4—>8)。不然会复杂
- (6)数据迁移过程中的平滑稳定
1.5 分库分表的实现方案
业界主要两种:服务端代理 和 客户端代理

- 服务端代理:通过部署代理服务,背后管理多个数据库实例。应用层通过一个普通的数据源(c3p0、druid、dbcp等)与代理服务器建立连接,所有的SQL语句都是发送给这个代理,由这个代理去路由底层数据库,开发人员无需关注底层逻辑
- 客户端代理:应用层内部管理了多个普通的数据源(c3p0、druid、dbcp等),每个普通数据源各自与不同的库建立连接。应用层通过路由规则路由给各个普通的数据源去执行,并返回结果。数据源代理通常也实现了JDBC规范定义的API,因此能够直接与orm框架整合。这种方案下开发人员需要修改代码
主流的实现方案对比
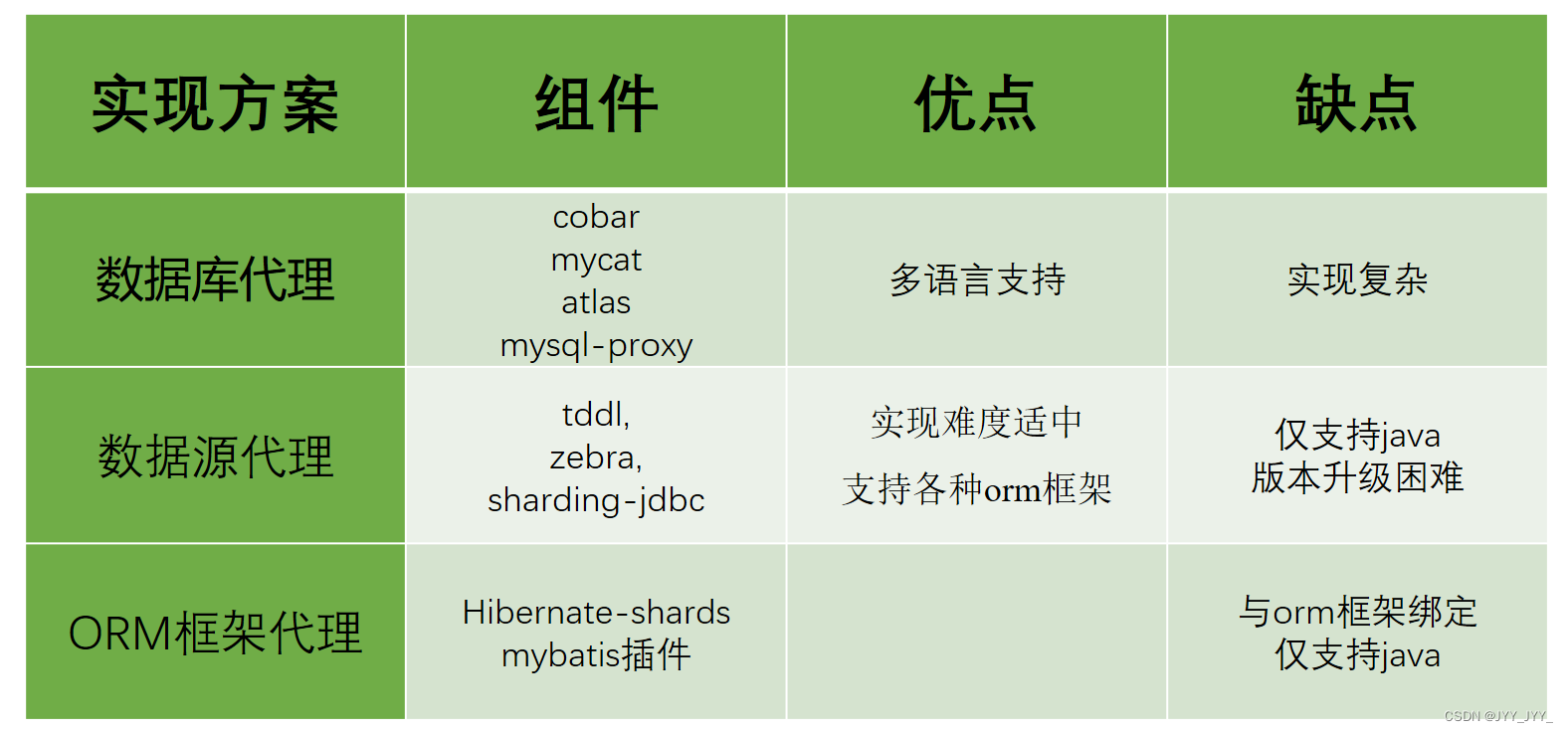
- 数据库代理
- 目前的实现方案有:阿里巴巴开源的cobar,mycat团队在cobar基础上开发的mycat,mysql官方提供的mysql-proxy,奇虎360在mysql-proxy基础开发的atlas。目前除了mycat,其他几个项目基本已经没有维护。
- 优点:多语言支持。也就是说,不论你用的php、java或是其他语言,都可以支持。原因在于数据库代理本身就实现了mysql的通信协议,你可以就将其看成一个mysql 服务器。mysql官方团队为不同语言提供了不同的客户端驱动,如java语言的mysql-connector-java,python语言的mysql-connector-python等等。因此不同语言的开发者都可以使用mysql官方提供的对应的驱动来与这个代理服务器建通信。
- 缺点:实现复杂。因为代理服务器需要实现mysql服务端的通信协议,因此实现难度较大。
- 数据源代理
- 目前的实现方案有:阿里巴巴开源的tddl,大众点评开源的zebra,当当网开源的sharding-jdbc。需要注意的是tddl的开源版本只有读写分离功能,没有分库分表,且开源版本已经不再维护。大众点评的zebra开源版本代码已经很久更新,基本上处于停滞的状态。当当网的sharding-jdbc目前算是做的比较好的,代码时有更新,文档资料比较全。
- 优点:更加轻量,可以与任何orm框架整合。这种方案不需要实现mysql的通信协议,因为底层管理的普通数据源,可以直接通过mysql-connector-java驱动与mysql服务器进行通信,因此实现相对简单。
- 缺点:仅支持某一种语言。例如tddl、zebra、sharding-jdbc都是使用java语言开发,因此对于使用其他语言的用户,就无法使用这些中间件。版本升级困难,因为应用使用数据源代理就是引入一个jar包的依赖,在有多个应用都对某个版本的jar包产生依赖时,一旦这个版本有bug,所有的应用都需要升级。而数据库代理升级则相对容易,因为服务是单独部署的,只要升级这个代理服务器,所有连接到这个代理的应用自然也就相当于都升级了。
- ORM框架代理
- 目前有hibernate提供的hibernate-shards,也可以通过mybatis插件的方式编写。相对于前面两种方案,这种方案可以说是只有缺点,没有优点。
二. 分库分表实践
2.1 路由键的选择
- 确定业务逻辑上的主体,并确认大部分数据库操作都基于这个主体进行(如用户ID)。
- 路由键在业务上不应被update,应是一个稳定的数据。且不应该为Null
- 数据倾斜问题,确保散列均匀
2.2 分库分表数决策
- 分表数量决策:
- 单表建议:不超过1000万行数据
- 通常可以预估2到5年的数据增长量,用估算出的总数据量除以总的物理分库数,再除以建议的最大数据量1000万,即可得出每个物理分库上需要创建的物理分表数
- (未来3到5年内总共的记录行数) / 单张表建议记录行数
- 分库数量决策:
- 提前规划好未来2到5年的峰值流量+容量
2.3 路由规则
- 路由键自身散列均匀:可通过取模的形式
- 例如:库路由规则:#user_id#%10;表路由规则:(#user_id#).intdiv(10)%100
- 路由键自身不散列均匀:对路由键作hash
- 例如:crc32(#user_id#)%8
2.4 其他挑战
- 自增主键:分布式自增id
- 分库分表数据迁移过程的双写:
- 思路一:mq事务消息,对于老表的事务,通过mq异步对新表重新执行,失败则补偿
- 缺点:异步极端情况下非实时(mq消息延迟),代码改动大
- 优点:老表 与 新表的最终数据一致性可保证
- 思路二:监听老表binlog,异步对新表执行。与思路一差不多
- 思路三:代码内部双写事务(设置两个事务管理器来处理)
- 优点:可通过切面形式实现,代码嵌入改造量小
- 缺点:①极端情况下无法保证两个事务的一致性(已提交事务A,准备提交B时宕机);②双写流程中接口性能下降
- 思路一:mq事务消息,对于老表的事务,通过mq异步对新表重新执行,失败则补偿
- 迁移过程整体思路:建分库分表—>双写(增量)—>刷存量—>数据核验—>切读流量—>切写流量—>下线双写—>收尾
- 小部分业务场景下没有路由键:
- 思路:空间换时间,建路由表(订单表以订单id为路由键;新建一张用户id与订单id的路由表,以用户id作为路由键)