逻辑回归处理多分类
- 1、背景描述
- 2、One vs One
- 3、One vs Rest
- 4、从Sigmoid到Softmax的推导
1、背景描述
逻辑回归本身只能用于二分类问题,如果实际情况是多分类的,那么就需要对模型进行一些改动。下面介绍三种常用的将逻辑回归用于多分类的方法
2、One vs One
OvO(One vs One)方法是指从多个类别中任意抽取出两个类别,然后将对应的样本输入到一个逻辑回归的模型中,学习到一个对这两个类别的分类器,然后重复以上的步骤,直到所有类别两两之间都学习到一个分类器
简单来说,就是让不同类别的数据两两组合训练分类器
例如,对于3分类问题,分类器的数量为 C 3 2 C_3^2 C32=3个,即可以得到3个二元分类器
分类器的数量可以使用 C k 2 C_k^2 Ck2计算,其中 k k k代表类别的数量
在预测阶段,只需要将测试样本分别输入训练阶段训练好的3个分类器进行预测,最后将3个分类器预测出的结果进行投票统计,票数最高的结果为预测结果
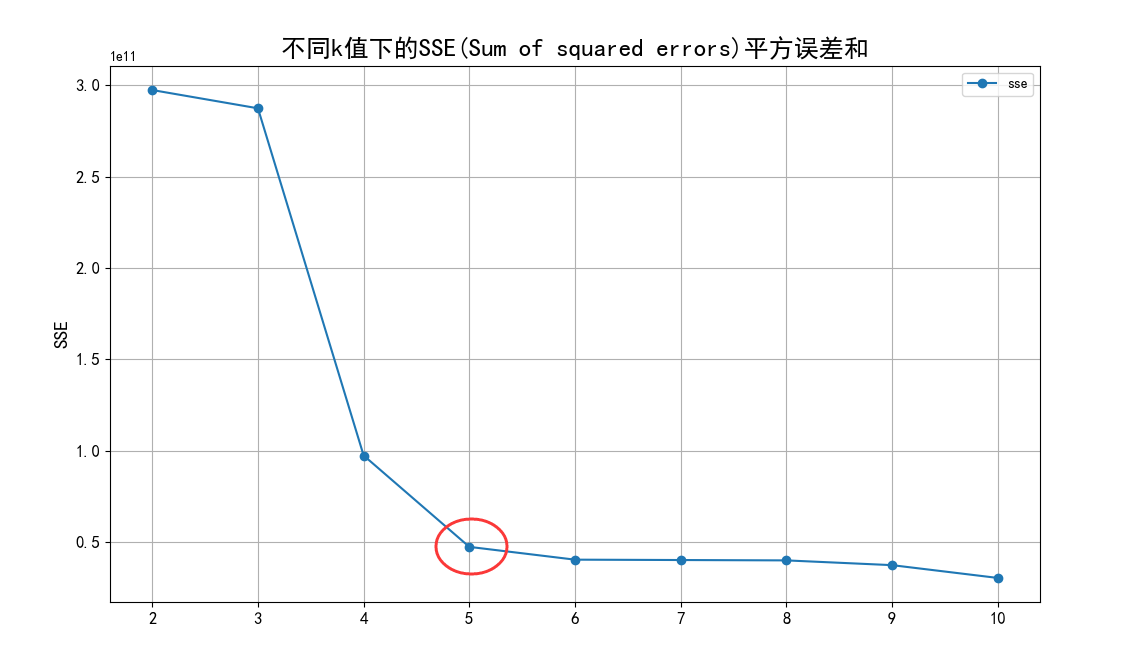
例如,下面的3分类问题:

上图(从左到右)分别为三角形与十字星训练出的分类器、三角形与正方形训练出的分类器和正方形与十字星训练出的分类器
现在,我们有一个在红色圆圈位置的数据,如下图,通过上述方法,我们如何预测的这个数据是哪一类?

将新样本分别输入训练好的3个分类器:第一个分类器会认为它是一个十字星,第二个分类器会认为它偏向三角形,第三个分类器会认为它是十字星,经过3个分类器的投票之后,可以预测红色圆圈位置所代表的数据的类别为十字星
任何一个测试样本都可以通过分类器的投票选举出预测结果,这就是OvO(One vs One)的运行方式
在OvO的方法中,当需要预测的类别变得很多的时候,那么我们需要进行训练的分类器也变得很多了,这将大大提高训练开销。但是,每一个训练器中,我们只需要输入两个类别对应的训练样本
3、One vs Rest
OvR(One vs Rest)方法从所有类别中依次选择一个类别作为1,其他所有类别作为0,来训练分类器,因此分类器的数量要比OvO的数量少得多
简单来说就是,对n种类别的样本进行分类时,分别取一种样本作为一类,将剩余的所有类型的样本看做另一类,这样就形成了n个二分类问题
例如,对于三分类问题,分类器的数量为3个,对于四分类问题,分类器的数量为4个。分类器的数量实际上就是类别的数量
在预测阶段,只需要将测试样本分别输入训练阶段训练好的3个分类器进行预测,最后将3个分类器预测出的结果进行投票统计,预测结果的确定,是根据每个分类器对其对应的类别为1的概率进行排序,选择概率最高的那个类别作为最终的预测类别
例如,下面的三分类问题:

上图(从左到右)分别为三个分类器,分类器1认为是A的概率为0.7,分类器2认为是B的概率为0.3,分类器3认为是C的概率为0.2,因此,最终的预测结果为A
4、从Sigmoid到Softmax的推导
第三种方法,我们可以直接从数学上使用Softmax函数来得到最终的结果,而Softmax函数与Sigmoid函数有着密不可分的关系,它是Sigmoid函数的更一般化表示,而Sigmoid函数是Softmax函数的一个特殊情况
在之前的文章(详见:传送门)中,我们已经推出了线性回归的结果等于对数几率(log odds),也称logit函数
l o g i t ( P ) = ln P 1 − P = ω T x logit(P)=\ln \frac{P}{1-P}=\omega^Tx logit(P)=ln1−PP=ωTx
分子表示一个事件发生的概率,分母代表这个事件不发生的概率,两者的和为1
当我们面对的情况是多个分类时,可以让k-1个类别分别对剩下的那个类别做回归,即得到k-1个logit公式
ln P ( Y = c i ∣ x ) P ( Y = c k ∣ x ) = ω i T x ( i = 1 , 2 , . . . k − 1 ) \ln \frac{P(Y=c_i|x)}{P(Y=c_k|x)}=\omega_i^Tx \;\;\;\;\;(i=1,2,...k-1) lnP(Y=ck∣x)P(Y=ci∣x)=ωiTx(i=1,2,...k−1)
于是
P ( Y = c i ∣ x ) = P ( Y = c k ∣ x ) e ω i T x P(Y=c_i|x)=P(Y=c_k|x)e^{\omega_i^Tx} P(Y=ci∣x)=P(Y=ck∣x)eωiTx
由于所有类别的可能性相加为1,因此可以得到
P ( Y = c k ∣ x ) = 1 − ∑ i = 1 k − 1 P ( Y = c i ∣ x ) = 1 − ∑ i = 1 k − 1 P ( Y = c k ∣ x ) e ω i T x P(Y=c_k|x)=1-\sum_{i=1}^{k-1}P(Y=c_i|x)=1-\sum_{i=1}^{k-1}P(Y=c_k|x)e^{\omega_i^Tx} P(Y=ck∣x)=1−i=1∑k−1P(Y=ci∣x)=1−i=1∑k−1P(Y=ck∣x)eωiTx
通过解上面的方程,可以得到关于某个样本被分类到类别 c k c_k ck的概率为
P ( Y = c k ∣ x ) = 1 1 + ∑ i = 1 k − 1 e ω i T x P(Y=c_k|x)=\frac{1}{1+\sum_{i=1}^{k-1}e^{\omega_i^Tx}} P(Y=ck∣x)=1+∑i=1k−1eωiTx1
这就是我们的Softmax函数了
参考文章:https://zhuanlan.zhihu.com/p/463149304