引言:探索AI在复杂卡牌游戏中的决策能力
在人工智能(AI)的研究领域中,游戏被视为现实世界的简化模型,常常是研究的首选平台。这些研究主要关注游戏代理的决策过程。例如,中国的传统卡牌游戏“掼蛋”(字面意思是“扔鸡蛋”)就是一个挑战性极强的游戏,在这个游戏中,即使是专业的人类玩家有时也难以做出正确的决策。而在掼蛋游戏中也流传着这样一个说法:“掼蛋打得好,适合当领导”,这也是独属人类世界的“玩法”,和某种合作行为的体现。本篇研究将探讨AI在这类复杂卡牌游戏中的决策能力,特别是它们如何通过蒙特卡洛方法和深度神经网络来掌握游戏规则,并在游戏中做出合作等复杂行为的决策。
标题:Mastering the Game of Guandan with Deep Reinforcement Learning and Behavior Regulating
公众号「夕小瑶科技说」后台回复“掼蛋”获取论文pdf。
背景介绍:掼蛋游戏的特点与挑战
掼蛋,一种起源于中国江苏省的四人固定搭档出牌型攀牌游戏,近年来迅速走红并登上了第五届全国智力运动会。游戏使用两副标准的52张牌加上四张王牌,每位玩家起始持有27张牌。掼蛋的独特之处在于其多样的可玩牌型组合,使得游戏富有娱乐性。游戏中的一种强力牌型被称为“炸弹”,这也是“掼蛋”(直译为“扔鸡蛋”)名称的由来,因为在中文里“炸弹”与“鸡蛋”谐音。掌握如何使用炸弹是游戏的难点之一,因为平均来说,玩家手中不会超过三个炸弹。
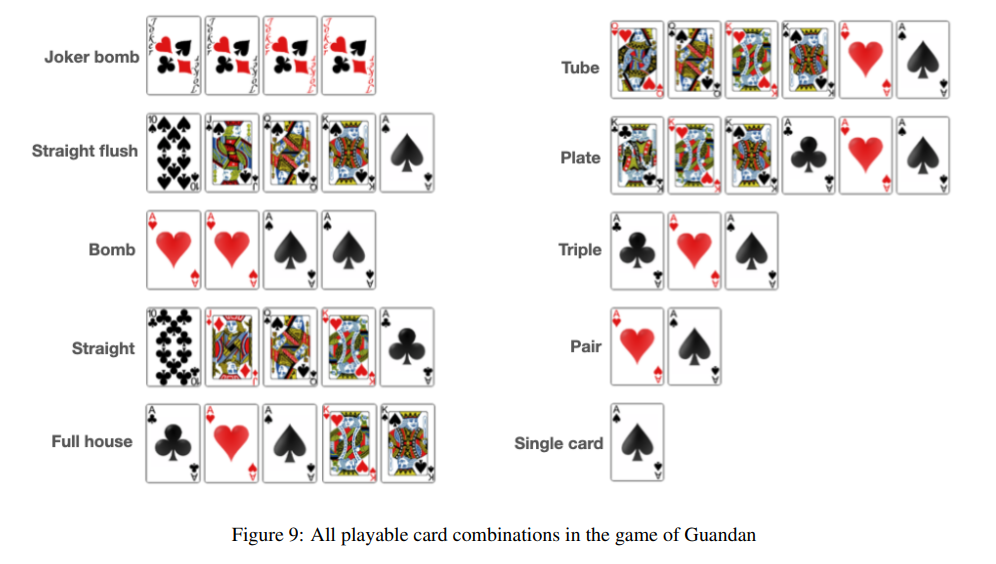
掼蛋与另一种扑克游戏斗地主类似,但由于其独特的级牌系统而有所区别。每队以二级牌开始比赛,争先将级牌升至A。
-
级牌不仅作为两队的记分系统,还具有强大的特权。例如,当前级牌可以压制所有牌型,除了王牌,而且两张红桃级牌成为百搭牌。
-
百搭牌不能代表任何王牌,但可以代表其他所有牌型,使其成为非常强大的实用牌型。例如,玩家可以利用百搭牌创建强力的牌型组合,如炸弹或同花顺,这在缺少特定牌时是不可能的。
掼蛋游戏由多个小局组成。我们将小局定义为在固定级牌下决定每位玩家排名的所有动作序列。当一队的成员率先打完手中的牌,即成为庄家,该队便赢得了小局。小局结束后,根据队员的排名,获胜队伍的级牌可以升级至多三级。当获胜队伍的级牌为A且最后没有队员成为最后一名时,整个游戏结束。
每个小局开始时(除了第一个小局),玩家必须进行一个贡品过程,其中上一小局的最后一名(住户)必须将其最高级别的牌捐赠给庄家。百搭牌不被视为最高级别的牌。为了平衡每位玩家的牌数,庄家必须返回一张不高于十的牌。
由于贡品过程与实际出牌分开,我们没有使用强化学习来帮助代理决定捐赠/返回哪张牌,而是采用了通常足够的基于规则的方法。
GuanZero框架简介:结合蒙特卡洛方法和深度神经网络
在本篇论文中研究者们提出了一个名为GuanZero的强化学习框架,旨在让AI代理不仅掌握掼蛋游戏,还能以高效的方式理解所需的行为。GuanZero框架依赖于深度蒙特卡洛(Deep Monte-Carlo,DMC)方法,利用其出色的可扩展性,同时通过精心设计的神经网络编码方案培养合作等所需行为。
蒙特卡洛(MC)方法是一种简单而有效的估算价值函数的方法,有助于发现最优策略。它们之所以简单,是因为除了通过与环境的交互获得的经验(包括状态、动作和奖励)之外,不需要对环境有完整的了解。这种经验甚至可以通过模拟获得。MC方法通过平均样本回报来解决强化学习问题。
下一节将讨论如何编码状态和动作,这些将作为输入馈送到神经网络中。
状态表示与行为编码:如何通过神经网络编码游戏状态和行为
1. 卡牌的独特编码方式
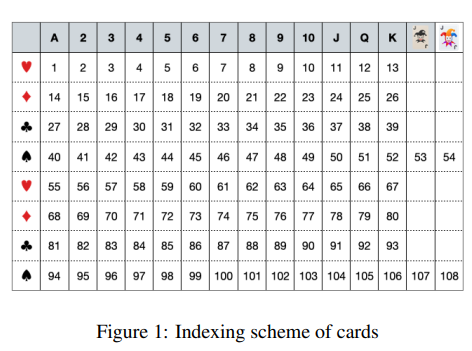
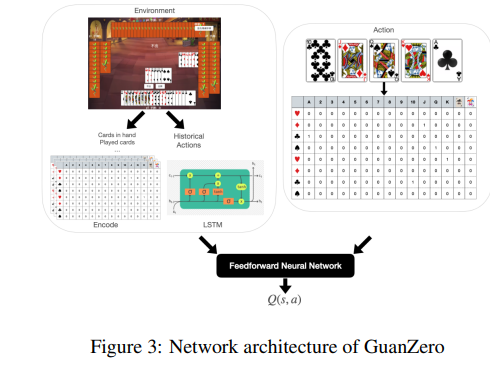
在关乎状态表示的问题上,神经网络需要能够理解和处理游戏中的各种卡牌组合。在观察了掼蛋游戏中卡牌的重要性之后,研究者们决定将每张卡牌视为一个独特的实体,并为其分配一个介于1到108之间的数字。
这种编码方式可以通过一个8x15的矩阵来可视化,其中每一行代表一个特定的花色,第四行和第八行还包括了四张王牌。在这个矩阵中,存在于玩家手中的卡牌会被设置为1,其余则为0。这样的编码方式不仅考虑了卡牌的花色和等级,还能追踪剩余卡牌的数量,这对于游戏来说至关重要。在输入到神经网络之前,这个矩阵会被展平成一个108维的一热向量。
2. 代表合作、矮化和协助行为的一热向量
在掼蛋中,合作行为被定义为玩家在能够出牌打败队友的牌时选择不出牌。这种行为通常被人类玩家所青睐,因为游戏的目标是尽快打出手中的卡牌,帮助队友同样重要。为了衡量代理执行合作行为的频率,研究者们定义了合作率这一指标。
除此之外,还有矮化行为,即玩家选择出一个大于对手最小手牌数量的牌组合,使得获胜的对手难以应对。
最后是协助行为,玩家出的牌组合小于队友的手牌数量,使得队友更容易找到应对的牌。这些行为的状态通过长度为三的一热向量来表示:
-
当不满足行为条件时,向量被设置为[1, 0, 0];
-
当满足条件时,根据玩家的选择,向量被设置为[0, 1, 0](执行行为)或[0, 0, 1](不执行行为)。
这样的设计原则为代理提供了一个简单而逻辑严密的机制来学习何时合作,何时不合作。
神经网络架构:LSTM与前馈网络的结合
神经网络的架构旨在接受状态s和行为a作为输入,并估计结果的预期累积奖励Q(s, a)。状态由一系列特征的丰富组合表示,这些特征已在表1中详细列出。为了正确处理历史行为,研究者们采用了长短期记忆网络(Long Short Term Memory ,LSTM)来捕捉行为、状态和价值之间的长期依赖性。
LSTM网络通过学习何时记住和何时忘记相关信息来实现这一点,同时通过允许梯度不变地流动,缓解了梯度消失问题。这些LSTM的属性反过来又促进了学习过程。在对历史行为进行特殊处理的同时,所有状态中的特征以及行为都被串联起来,输入到一个由六层密集层组成的前馈神经网络中,激活函数为修正线性单元(ReLU)。
分布式学习过程:如何通过并行化提高训练效率
在深度强化学习中,分布式学习过程是提高训练效率的关键策略之一。通过并行化,研究者们能够在多个环境实例中同时运行多个智能体,这样可以显著加快数据收集的速度,从而加速学习过程。
1. 分布式学习的基本原理
分布式学习的核心思想是将学习任务分散到多个计算节点上。在这种设置中,每个节点都运行一个智能体的副本,并与环境进行交互以收集数据。然后,这些数据被用来更新一个共享的全局模型。这种方法的优势在于,它允许智能体并行地探索状态空间,而不是顺序地进行,这样可以更快地覆盖更多的状态—动作对。
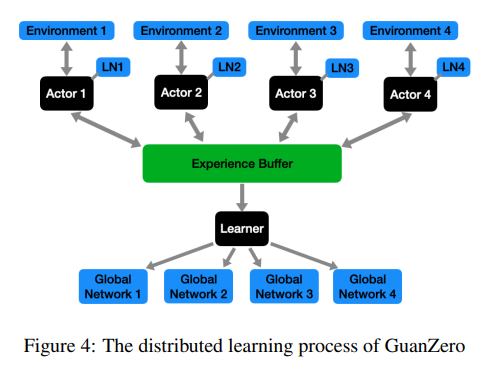
2. GuanZero的分布式学习实现
在GuanZero框架中,研究者们采用了类似于A3C(Asynchronous Advantage Actor-Critic)的分布式学习方法。为四名玩家分别设置了四个网络,分别命名为'p1'、'p2'、'p3'和'p4',并根据第一个小游戏中的出牌顺序进行分配。
然后通过将模拟任务分配给四个执行者来并行化学习过程。每个执行者在模拟智能体与环境交互时都维护一个本地网络(LN)。这些本地网络会定期与学习过程中维护的四个全局网络同步。学习过程根据执行者获得的经验来更新这些全局网络。
通过这种分布式学习方法,能够快速生成大量的样本,从而减轻了蒙特卡洛方法高方差的问题,并提高了训练效率。此外还利用了长短期记忆(LSTM)网络来捕捉动作、状态和价值之间的长期依赖关系,这进一步增强了模型的学习能力。
实验设置:对比GuanZero与其他AI代理的性能
为了验证GuanZero框架的有效性,研究者们设置了一系列实验来比较GuanZero与其他AI代理的性能。
1. 对手智能体
研究者们使用了多种类型的对手智能体,包括随机选择动作的随机智能体、基于规则的中国关牌AI算法竞赛(CGAIAC)冠军智能体,以及使用DouZero框架训练的基于强化学习的智能体。所有这些智能体都经过了充分的训练直到收敛。
2. 性能评估
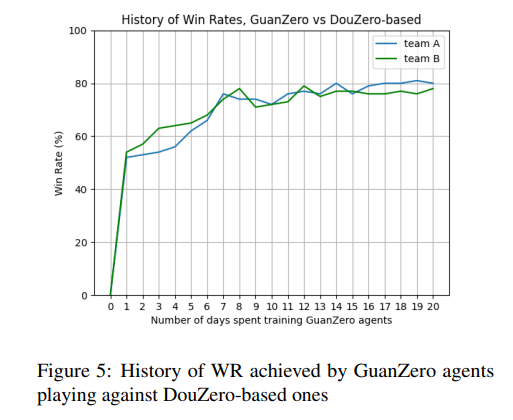
研究者们通过胜率(WR)作为评估智能体强度的唯一指标。在实验中将GuanZero智能体与上述所有对手进行对抗,并记录了胜率。
-
实验结果显示,GuanZero智能体在与随机智能体对抗时取得了压倒性的胜利,这表明随机智能体大多数时候无法做出良好的决策。
-
在与基于规则的CGAIAC智能体对抗时,GuanZero智能体面临了一定的抵抗,但随着足够数量的模拟,基于强化学习的智能体开始展现出其优势,因为它们能够找到针对规则智能体的反制动作。
-
此外,GuanZero智能体在与DouZero基础智能体的对抗中最初遇到了激烈的抵抗,但随着训练的进行,GuanZero智能体迅速获得了上风,并且训练效率令人满意,不到一周就观察到了收敛的迹象。
通过这些实验,研究者们证明了GuanZero框架在关牌游戏中的有效性,并通过行为调节机制进一步提升了智能体的性能。
行为调节的效果分析:合作、矮化和协助行为的学习过程
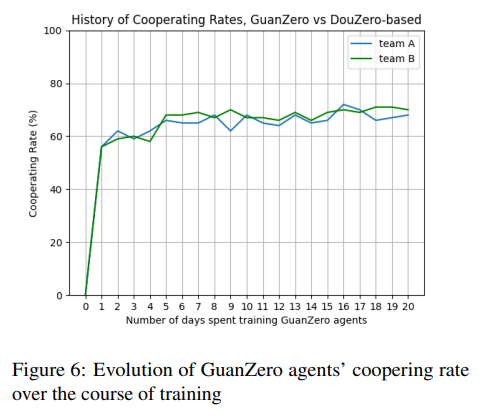
1. 合作行为的学习与效果
GuanZero通过特定的神经网络编码方案,使得代理能够学习何时合作,何时不合作。合作率的度量标准是代理实际合作的次数与合作条件满足的次数之比。训练过程中,GuanZero代理的合作率稳定在一个显著高于随机代理基线值的水平,这表明GuanZero代理成功学习了合作行为,并在实践中有效地应用了这一行为。
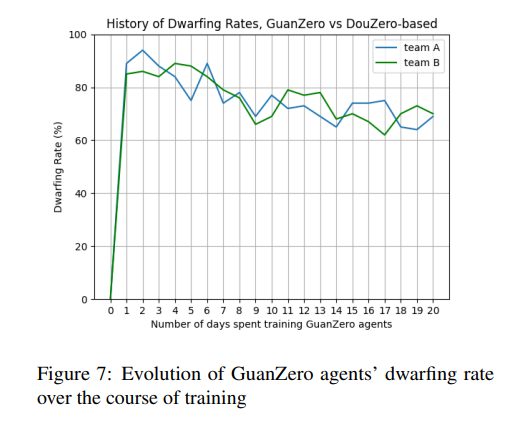
2. 矮化行为的学习与效果
GuanZero代理学习矮化行为的过程较为复杂,因为其发生条件较为严格,且出现频率较低。尽管如此,GuanZero代理最终还是学会了何时执行矮化行为。训练过程显示,矮化率有较大波动,但最终趋于稳定,代理能够在适当的时机执行矮化行为。
3. 协助行为的学习与效果
GuanZero代理在训练过程中学会了何时执行协助行为,协助率的趋势与矮化行为类似,经历了一段波动后趋于稳定。这表明GuanZero代理能够有效地学习并执行协助行为,以提高团队的整体表现。
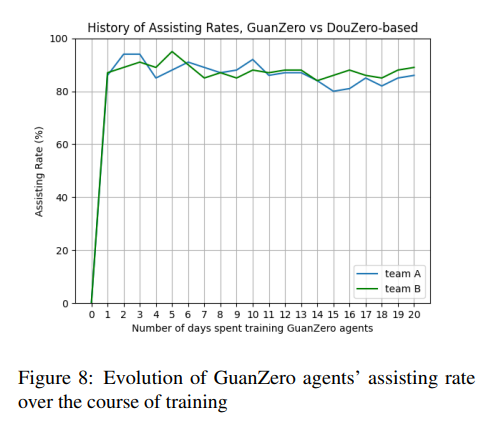
结论与未来工作:GuanZero的成就与潜在改进方向
GuanZero通过深度强化学习和行为调节成功地掌握了掼蛋游戏,并在与其他先进算法的比较中展现出了优越的性能。GuanZero代理不仅学会了游戏的基本策略,还通过特别设计的神经网络编码方案学会了合作、矮化和协助等行为,这些行为对于团队胜利至关重要。
未来的工作将集中在进一步提高GuanZero的性能和泛化能力上。尽管GuanZero在掼蛋游戏中取得了显著的成就,但其特定的行为调节方案可能难以扩展到其他游戏或应用领域。
此外,研究者们还希望探索其他形式的神经网络结构,因为当前的网络结构相对基础,更先进的神经网络不仅能够与不断增强的计算能力相匹配,还可能引导代理发现尚未想象到的新策略。
总结:AI在掼蛋游戏中的突破意义
人工智能(AI)在游戏领域的研究一直是AI研究的热点,尤其是在棋牌游戏中。近年来,AI在围棋、国际象棋等完全信息游戏中取得了显著进展,如AlphaGo和AlphaZero的成功。然而,在不完全信息的游戏中,AI面临着更大的挑战。掼蛋游戏就是一个具有巨大状态空间和复杂性的不完全信息游戏,它对AI研究提出了新的挑战。
掼蛋游戏的复杂性主要体现在其不完全信息的特性以及庞大的状态空间。传统算法如CFR在应用于多玩家设置时需要额外的调整,尤其是在需要鼓励队友间合作行为的情况下。此外,Guandan游戏中的信息集数量和合法动作数量都非常庞大,这可能会降低现有算法的效率。
-
例如,与DQN结合使用的动作消除法就是为了减少Q函数中过度估计错误的风险,这些错误可能导致学习算法收敛到次优策略。
本篇论文提出了一个名为GuanZero的强化学习框架,旨在使AI代理不仅能够掌握掼蛋游戏,而且还能以高效的方式理解所需的行为。GuanZero框架依赖于DMC的可扩展性,并通过精心设计的神经网络编码方案培养合作等所需行为。
GuanZero的神经网络架构能够处理状态和动作的丰富组合,并通过LSTM网络捕捉动作、状态和价值之间的长期依赖性。此外,研究者们还建立了一个分布式学习过程,通过并行化模拟任务来加速学习过程,并使用胜率(WR)作为评估代理强度的唯一指标。
实验结果表明,GuanZero代理在与随机代理、基于规则的CGAIAC代理以及基于DouZero的代理的对抗中均取得了胜利。特别是在与DouZero基于代理的对抗中,GuanZero代理在训练过程中迅速占据上风,并且训练效率令人满意,不到一周就出现了收敛的迹象。
总的来说,GuanZero在掼蛋游戏中的突破意义在于其能够处理复杂的状态空间和不完全信息的挑战,并通过行为调节机制学习合作等所需行为。这一突破不仅展示了AI在处理复杂棋牌游戏中的潜力,为AI能够更好模仿人类的思维提供借鉴,也为未来AI在更广泛领域的应用奠定了基础。
公众号「夕小瑶科技说」后台回复“掼蛋”获取论文pdf。