原文标题
Local word vectors guiding keyphrase extraction
摘要
自动关键词组提取是一项基本的文本信息处理任务,涉及到从文件中选择具有代表性的短语来概括其内容。这项工作提出了一种新的无监督的关键词组提取方法,其主要创新点是使用局部词嵌入(特别是GloVe向量),即从所考虑的单个文档中训练出来的嵌入。我们认为,这种对单词和关键词组的局部表示能够准确地捕捉它们在文档中的语义,因此有助于提高关键词组的提取质量。实证结果提供的证据表明,与在非常大的第三语料库或由同一科学领域的多个文档组成的更大的语料库上训练的嵌入以及其他最先进的无监督关键词组提取方法相比,局部表示确实可以带来更好的关键词组提取结果。
1.引言
关键词组提取是指从文档中选择一组短语,这些短语汇总了该文档中讨论的主要主题。自动关键词组提取是数字内容管理中的一项基本任务,因为它可用于文档索引,进而可计算文档间语义相似度,并可改善数字图书馆浏览。此外,其还提供了一种文档摘要的方法。
自动关键词组抽取的有监督机器学习方法依赖于带注释语料库。然而,人工选择每一份文件的关键词组需要投入时间和金钱,具有很大的主观性。在许多情况下,由于误解,所提取的关键词组包含一个或多个非核心主题,或者它们错过了文档中讨论的一个或多个重要主题。此外,有监督方法常常不能很好地概括来自不同内容领域的文档,而不是来自训练语料库,可能需要重新训练以处理概念漂移,而且易受文档不同词汇表和作者不同写作风格影响。
我们的方法从给定学术出版物的全文中学习到局部词向量,我们就会计算其标题和摘要中词的平均向量(参考向量);然后,从标题和摘要中提取候选关键词组,并根据它们与参考向量的余弦相似度对它们进行排序,越接近参考向量的词向量就越有代表性。
2.相关工作
2.1 自动关键词提取
有监督方法
在有监督学习中,分类器在带关键词组注释的文档上进行训练,以确定一个候选短语是否是关键短语。著名方法:的KEA系统、二值分类模型CeKE(决策阈值为0.9的朴素贝叶斯分类器) 、循环神经网络等。
无监督方法
无监督的关键词组提取方法通常遵循标准的三阶段过程。第一阶段涉及根据一些启发式方法选择候选词汇单元,例如排除停用词或选择名词或形容词。第二阶段涉及通过共现统计或句法规则测量它们的重要性来对这些词汇单元进行排名。第三阶段涉及关键词组的形成,其中排名靠前的词汇单元被用作关键字或关键词组的组成部分。著名方法:Tf-Idf、基于图的排序算法(PageRank,Hits,TextRank,SingleRank,PositionRank,CiteTextRank)等。
2.2 密集向量
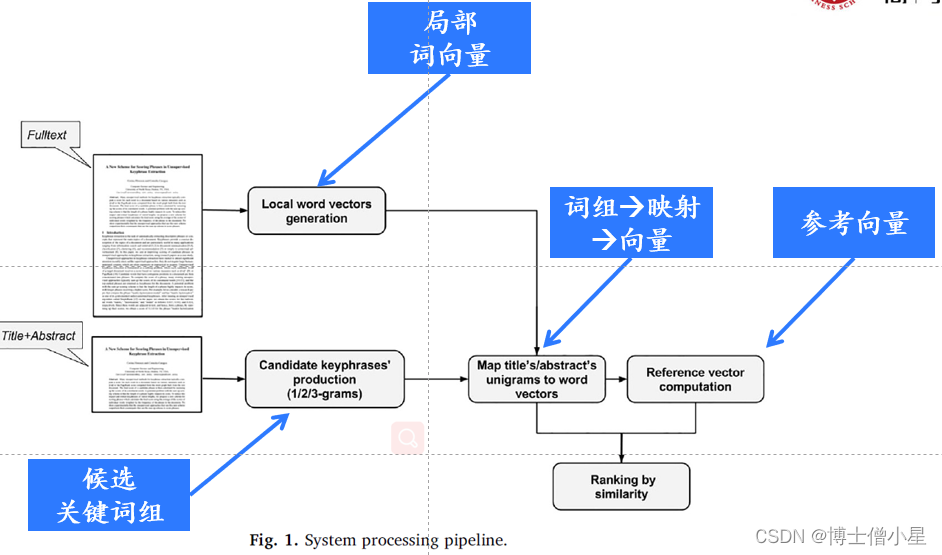
3.参考向量算法
3.1 候选词组生成
我们遵循先前关键词提取系统的选择,仅提取一元、二元和三元词组,因为这些是实验研究使用数据集中最常见的关键词。通过这种方式,我们可以将 n 的值限制为 {1, 2, 3} 来有效地减少可能作为候选关键词组的数量。因为一般情况下,文档关键词组倾向于三元组合。
候选词(一元组):是构成较长关键词组最小但最重要的部分。选择标准如下:
• 候选词字长应小于 36 且大于 2 个字符;• 不属于我们定义的停止词列表;• 不是数字;• 不包括以下字符集: ! 、 @ 、 # 、 $ 、*、 = 、 + 、。 ?, >, <, &, (,), {, }, [, ], ∣ ;候选二元组:我们选择那些候选一元组中以特定顺序出现在文本中的词作为候选二元组。我们不会将两个词的长度都低于4的那些作为候选二元组。候选三元组:处理同二元组。
3.2 候选词组打分

4.实验
4.1 章节安排
首先,介绍实证研究中使用的两个集合,以及一些有趣的统计数据;然后,描述评价框架和实验设置;最后,讨论结果,提供一个定量和定性的评估建议的方法。
4.2 数据集及统计
实证研究基于2个受欢迎的科学出版物合集:(a)Krapivin,其中包含由ACM发表的来自计算机科学领域的2304篇科学全文文章,以及作者指定和编辑更正的关键词,以及 (b) Semeval,其中包含来自ACM数字图书馆的244篇科学全文文章,以及作者指定的和读者指定的关键词。我们对这两个数据集都进行了预处理,以便将每个文档的上半部分(Krapivin的标题、摘要和Semeval的标题、摘要、类别/主题描述符以及ACM计算分类系统的一般术语)与其余部分(正文)分开。Krapivin数据集的细化过程相当简单,因为标题和摘要都清楚地标明了。Semeval较难(正文通常以标题中包含 “Introduction”一词的衍生词的部分开始)。
表1显示了每个集合中每个不同长度(词数)的关键词组的频率。可以看到,大多数关键词组是二元组,然后是一元组/三元组。带有4到6个单词的关键短语出现的频率较低,同时也存在一些带有7到9个单词的异常值。

4.3 实验步骤

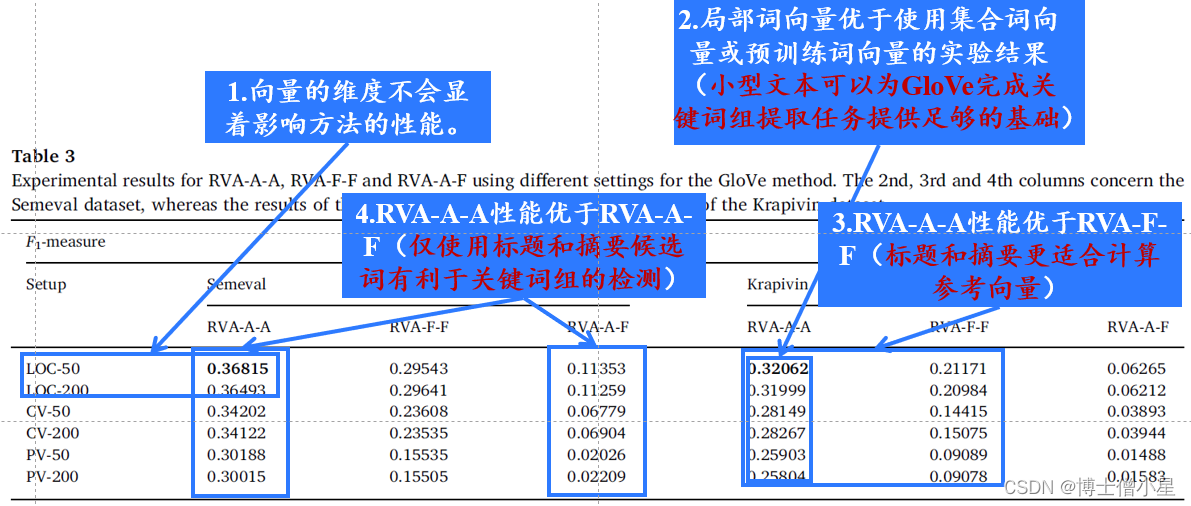
4.4 Glove训练中基于文本大小的RVA变量评估
在本节中,我们通过改变词向量的维度和在不同的语料库大小上训练 GloVe 模型,包括使用在海量网络数据集上训练的词向量(预训练词向量)来大致了解 RVA 算法的性能.
由于这是第一次以这种方式使用此类本地词向量,我们准备了一项实验研究,旨在为我们提供关于参考向量作为关键词组提取过程指南的参考。出于这个原因,我们设计了另外两个不同版本的提议的RVA方法:
• 全文参考向量算法 ( RVA-F-F ) :候选词和参考向量,是通过对出现在全文中的单个局部词向量进行平均来计算的,而不仅是在标题和摘要中。• 全文候选的参考向量算法 ( RVA-A-F ) :使用整篇文章中的候选一元、二元和三元,而不像 RVA 那样局限于文章的摘要。但是,参考向量仍然仅根据标题和摘要计算。• RVA-A-A
表2详细描述了用于GloVe训练的向量维度和文本大小方面的不同设置,并提供了结果表3中使用的相应缩写。

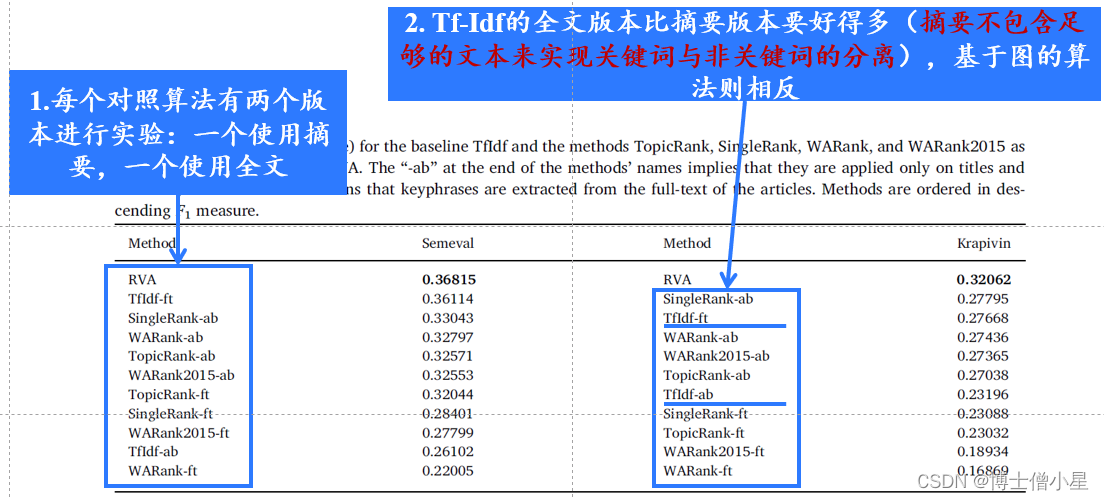
4.5 与其他算法比较
4.6 定性结果:实践中的RVA



5.结论与未来工作