前言
大家好,我是 JavaPub。日志是我们定位问题的得力助手,也是我们团队间协作沟通(甩锅)、明确责任归属(撕B)的利器。没有日志的程序运行起来就如同脱缰的野🐎。打印日志非常重要。今天我们来聊聊日志打印的 N 个好建议~
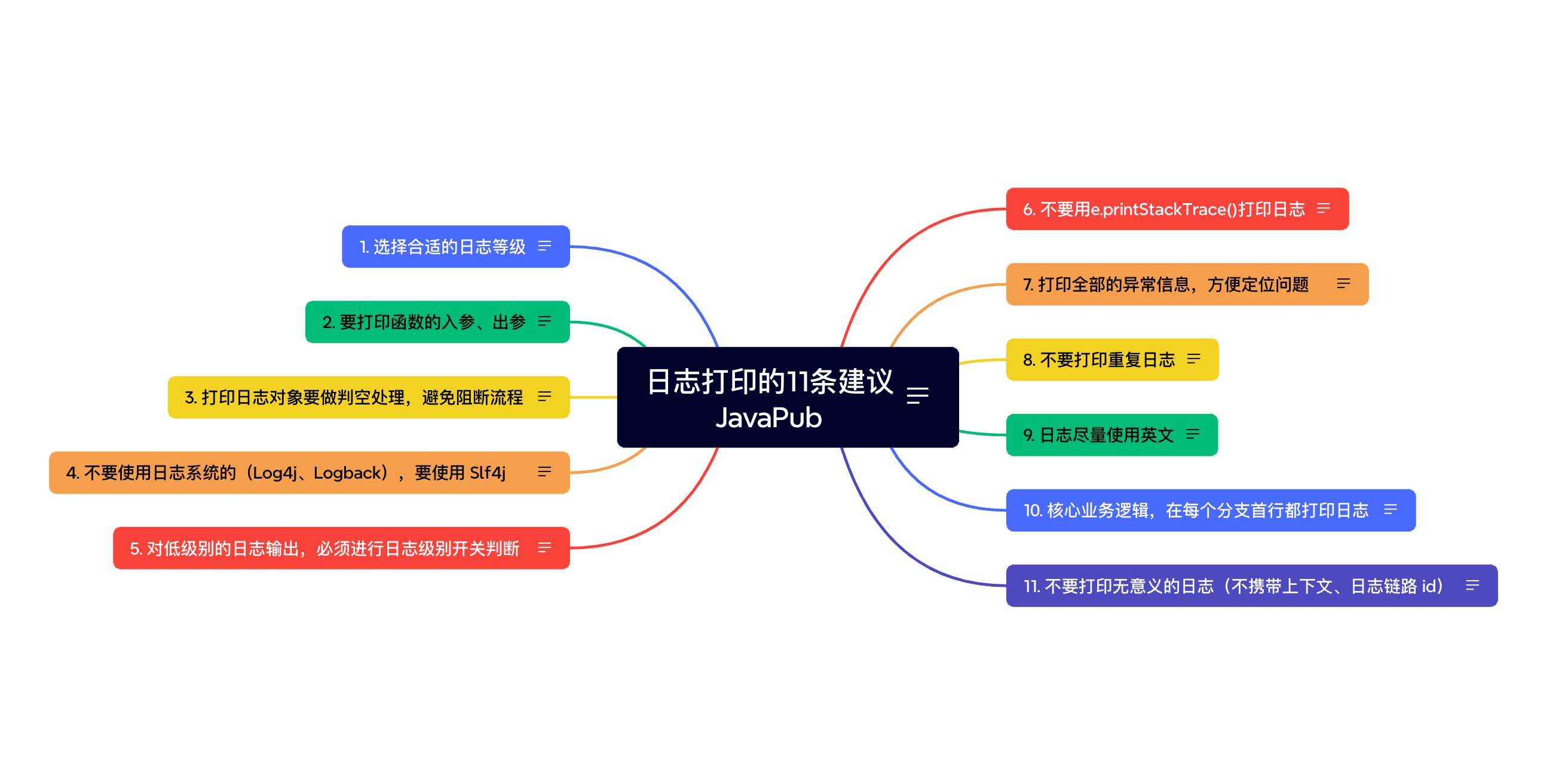
文章目录
- 前言
- 选择合适的日志等级
- 要打印函数的入参、出参
- 打印日志对象要做判空处理,避免阻断流程
- 不要使用日志系统的(Log4j、Logback),要使用 Slf4j
- 对低级别的日志输出,必须进行日志级别开关判断
- 不要用e.printStackTrace()打印日志
- 打印全部的异常信息,方便定位问题
- 不要打印重复日志
- 日志尽量使用英文
- 核心业务逻辑,在每个分支首行都打印日志
- 不要打印无意义的日志(不携带上下文、日志链路 id)
选择合适的日志等级
在开发中我们有常见的四种日志打印等级,debug、info、warn、error,要选择合适的等级打印,不要上来直接 info。

-
error: 错误日志,指比较严重的问题,会对系统和有业务造成伤害。运维监控重点关注。
-
warn: 警告日志,不会对系统运行造成大的影响,一般由开发人员关注。
-
info: 关键日志,为了保留系统运行关键指标,比如函数的入参、出参,时间等信息。
-
debug: 开发日志,在开发调试阶段,记录对象数据在关键处理步骤中的变化情况、快速定位。
要打印函数的入参、出参
记录日志并不是要把所有信息都记录下来,那日志存储就要大到上天。我们只记录关键有效的日志,有效日志才是 battle 🆚 时杀手锏。

哪些算是有效日志?比如函数的入口处,打印入参,还包括用户唯一标识 (uid)、链路标识 (traceId) 等。函数出口打印返回值及时间等。
public String GetName(Request req, Integer id){log.debug("method start param: {}", req.UserID);String name = "JavaPub";log.debug("method end result: {}", name);return name;}
打印日志对象要做判空处理,避免阻断流程

为了打印一行日志,程序写挂了。空指针异常在任何代码中都是最常见的异常之一。
反例:当 book 对象是 NULL 的话,这行日志就会抛空指针异常。
public void doSome(Book book){log.info("do do and print log: {}". book.getName());// do something......
}
不要使用日志系统的(Log4j、Logback),要使用 Slf4j

Slf4j 是使用门面模式的日志框架,可以解耦具体的日志实现。可以在不修改代码的情况下,更换底层的日志框架。
正例:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;private static final Logger logger = LoggerFactory.getLogger(JavaPub.class);
对低级别的日志输出,必须进行日志级别开关判断

对于 trace、debug、info 这些比较低的日志级别,必须进行日志级别开关。
正例:
开关判断逻辑通常放在日志工具类中。
public void doSomething(){User user = new User(1, "技术自媒体", "JavaPub");if (logger.isDebugEnabled()) {logger.debug("print debug log. 666 is {}", user.getName());}
}
反例:
public void doSth(){String name = "JavaPub";logger.trace("print debug log" + name);logger.debug("print debug log" + name);logger.info("print info log" + name);// 业务逻辑...
}
当日志级别是 warn 时,以上日志不会打印,但是会执行字符串拼接操作,如果打印值是对象的话,还会执行 toString() 方法,浪费了系统资源,因此建议加上日志开关判断。
不要用e.printStackTrace()打印日志
反例:
public void doSomething(){try{// 业务代码...} catch (Exception e){e.printStackTrace();}
}
-
e.printStackTrace()打印出的日志包含堆栈信息,导致我们的日志信息不规整、增加定位问题的难度。如果使用 ELK 分析日志也会非常困难。 -
e.printStackTrace()语句产生的字符串记录的是堆栈信息,如果信息太长太多,字符串常量池所在的内存块没有空间了,即内存满了,系统请求也将被阻塞。
正例:
public void doSomething(){try{// 业务逻辑...} catch (Exception e){log.error("程序异常 failed", e);}
}
打印全部的异常信息,方便定位问题

反例:
没有打印系统异常 e,无法定位出现了什么类型的异常。
public void doSth(){try{// 业务逻辑...} catch (Exception e){log.error("发生了一个异常");}
}
不要打印重复日志

在嵌套逻辑代码中打印重复日志,增加系统资源消耗占用。
反例:
public void doSomething(String s){log.info("do something and print log: {}", s);doSubSomething(s);
}
private void doSubSomething(String s){log.info("do sub something and print log: {}", s);// 写点业务逻辑...
}
正例:
应该直接删掉或者将为 debug 日志级别。
日志尽量使用英文
反例:

建议:尽量在打印时日志时输出英文,防止中文编码与终端不一致导致打印出现乱码,对排查故障造成感染。
核心业务逻辑,在每个分支首行都打印日志
在编写核心业务逻辑代码时,遇到 if…else 或者 switch 这样的分支条件,在行首打印日志,通过日志可以快速排查定位异常。
public void doSomething(){if(user.isVip()){log.info("该用户是 JavaPub 会员,Id:{},开始处理会员逻辑",user,getUserId());// TODO 会员逻辑}else{log.info("该用户是非会员,Id:{},开始处理非会员逻辑",user,getUserId())// TODO 非会员逻辑}
}
不要打印无意义的日志(不携带上下文、日志链路 id)

反例:
不携带任何业务信息的日志,对故障排查意义不大。
public void doSomething(){log.info("do something and print log. i am NB");// TODO 业务逻辑...
}
正例:
- 日志一定要携带业务信息相关内容,有利于快速定位问题原因
public void doSomething(Request req, User user){log.info("do something and print log, id={}, trace_id={}", user.GetId, req.GetTraceId);// TODO 业务逻辑...
}
如何打印日志呢?总的来说不要让你的程序在黑盒总运行,打印关键信息、保证在出现异常时通过日志快速定位到那里就可以啦。

![中间件 | RPC - [Dubbo]](https://img-blog.csdnimg.cn/direct/f2296201d2604c08aea759d34b456e9a.png)