文章目录
- Vision Mamba Encoder
- 初始化
- 输入映射
- 序列变换
- 参数映射
- BC参数映射
- delta参数映射
- SSM参数初始化
- A , D矩阵初始化
- delta参数初始化
- 双向SSM初始化
- 参数初始化
- 前向
- 输入映射
- fast_path
- use_fast_path
- no use_fast_path
- 双向SSM
- v1
- 前向
- 后向
- v2
- 前向
- 后向
Vision Mamba Encoder
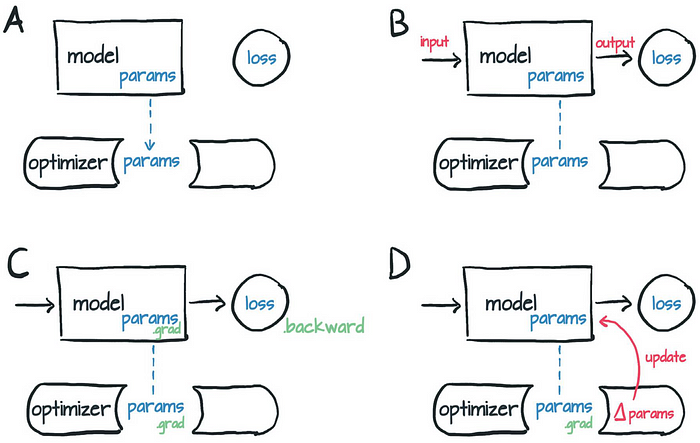
Vision Mamba的编码器部分,也位于Vim模型的中间和主要部分。由多个Mamba块堆叠而成,VisionMamba的Mamba块是在原始论文MambaBlock上修改,特别的地方在于其双向SSM机制。双向与数据流动方向无关,并不是指网络中存在反馈回路,而是等价的扫描方向有两种。

初始化
输入映射
首先,还是一个标准的输入映射,这一点没有更改,输入映射用来得到门控变量z和主干变量x,其中x的维度d_model扩充到2 * d_inner。
self.in_proj = nn.Linear(self.d_model, self.d_inner * 2, bias=bias, **factory_kwargs)
序列变换
通过一个1D卷积进行序列变换。
self.conv1d = nn.Conv1d(in_channels=self.d_inner,out_channels=self.d_inner,bias=conv_bias,kernel_size=d_conv,groups=self.d_inner,padding=d_conv - 1,**factory_kwargs,)self.activation = "silu"self.act = nn.SiLU()
参数映射
参数映射是一个简单的线性映射,为了得到输入依赖的矩阵参数B,C还有 Δ \Delta Δ参数
BC参数映射
d_state*2属于B,C参数,dt_rank属于delta参数的原始维度
self.x_proj = nn.Linear(self.d_inner, self.dt_rank + self.d_state * 2, bias=False, **factory_kwargs)
delta参数映射
delta参数的给出:x->x_proj ->split -> dt_proj ->delta
输入x经过x_proj映射得到数据依赖的三个参数 B , C , Δ B, C,\Delta B,C,Δ,其中 Δ \Delta Δ 得到的维度是dt_rank,还需要进行一个(dt_rank, d_inner)的线性映射
self.dt_proj = nn.Linear(self.dt_rank, self.d_inner, bias=True, **factory_kwargs)
SSM参数初始化
在这里初始化非输入依赖的SSM参数包括A矩阵和D矩阵,还包括步长delta参数dt的初始化
A , D矩阵初始化
| 参数 | 维度 |
|---|---|
| A | [d_state] -> [d_inner, d_state] |
| D | [d_inner] |
A = repeat(torch.arange(1, self.d_state + 1, dtype=torch.float32, device=device),"n -> d n",d=self.d_inner,).contiguous()A_log = torch.log(A) # Keep A_log in fp32self.A_log = nn.Parameter(A_log)self.A_log._no_weight_decay = True# D "skip" parameterself.D = nn.Parameter(torch.ones(self.d_inner, device=device)) # Keep in fp32self.D._no_weight_decay = True
delta参数初始化
d t = e α ( ⋅ l o g ( d t _ m a x ) − l o g ( d t _ m i n ) ) + l o g ( d t _ m i n ) dt = e^{\alpha (\cdot log(dt\_max) - log(dt\_min)) + log(dt\_min)} dt=eα(⋅log(dt_max)−log(dt_min))+log(dt_min)
其中 α \alpha α属于0到1的均匀分布,因此 d t dt dt的取值为 e l o g d t _ m i n e^{log{dt\_min}} elogdt_min到 e l o g d t _ m a x e^{log{dt\_max}} elogdt_max。即 d t _ m i n dt\_min dt_min到 d t _ m a x dt\_max dt_max
softplus函数为 S o f t p l u s ( x ) = 1 β ∗ l o g ( 1 + e x p ( β ∗ x ) ) Softplus(x) = \frac{1}{\beta} \ast log(1+exp(\beta \ast x)) Softplus(x)=β1∗log(1+exp(β∗x))
# Initialize special dt projection to preserve variance at initializationdt_init_std = self.dt_rank**-0.5 * dt_scaleif dt_init == "constant":nn.init.constant_(self.dt_proj.weight, dt_init_std)elif dt_init == "random":nn.init.uniform_(self.dt_proj.weight, -dt_init_std, dt_init_std)else:raise NotImplementedError# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_maxdt = torch.exp(torch.rand(self.d_inner, **factory_kwargs) * (math.log(dt_max) - math.log(dt_min))+ math.log(dt_min)).clamp(min=dt_init_floor)# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759inv_dt = dt + torch.log(-torch.expm1(-dt))with torch.no_grad():self.dt_proj.bias.copy_(inv_dt)# Our initialization would set all Linear.bias to zero, need to mark this one as _no_reinitself.dt_proj.bias._no_reinit = True
双向SSM初始化
参数初始化
对于标准Mamba块来说,仅限于前向分支,而后向分支是不存在的,可以看到后向分支是前向分支的复制。在初始化阶段,双向SSM只是额外定义并初始化了一个A矩阵名为A_b。对于v1版本仅仅是多初始化一个矩阵A,而v2版本除此之外,还初始化了标准Mamba所需的全部参数,如D矩阵,参数映射。简单来说,v1版本的双向SSM除A矩阵以外,其他参数是公用的。
| 参数 | 维度 |
|---|---|
| A_b | [d_state] -> [d_inner, d_state] |
# bidirectionalif bimamba_type == "v1":A_b = repeat(torch.arange(1, self.d_state + 1, dtype=torch.float32, device=device),"n -> d n",d=self.d_inner,).contiguous()A_b_log = torch.log(A_b) # Keep A_b_log in fp32self.A_b_log = nn.Parameter(A_b_log)self.A_b_log._no_weight_decay = Trueelif bimamba_type == "v2":A_b = repeat(torch.arange(1, self.d_state + 1, dtype=torch.float32, device=device),"n -> d n",d=self.d_inner,).contiguous()A_b_log = torch.log(A_b) # Keep A_b_log in fp32self.A_b_log = nn.Parameter(A_b_log)self.A_b_log._no_weight_decay = True self.conv1d_b = nn.Conv1d(in_channels=self.d_inner,out_channels=self.d_inner,bias=conv_bias,kernel_size=d_conv,groups=self.d_inner,padding=d_conv - 1,**factory_kwargs,)self.x_proj_b = nn.Linear(self.d_inner, self.dt_rank + self.d_state * 2, bias=False, **factory_kwargs)self.dt_proj_b = nn.Linear(self.dt_rank, self.d_inner, bias=True, **factory_kwargs)self.D_b = nn.Parameter(torch.ones(self.d_inner, device=device)) # Keep in fp32self.D_b._no_weight_decay = True
前向
| 参数 | 维度 |
|---|---|
| 输入x | [b, l, d] |
| xz | [b, 2 * d, l] |
| x_dbl | [b,dt_rank + d_state * 2 ] |
| SSM参数 | shape | 来源 |
|---|---|---|
| 状态矩阵A | (d_in, n) | 在初始化中定义,非数据依赖 |
| 输入矩阵B | (b, l, n) | 由x_db1切分而来,因此数据依赖 |
| 输出矩阵C | (b, l, n) | 由x_db1切分而来,因此数据依赖 |
| 直接传递矩阵D | (d_in) | 在初始化中定义,非数据依赖 |
| 数据依赖步长 Δ \Delta Δ | (b, l, d_in) | 由x_db1切分而来,因此数据依赖 |
| 维度约定 | 说明 |
|---|---|
| B / b | batch size |
| L / l | length |
| D / d | d_inner |
输入映射
输入映射把输入x映射为两个分支xz,主分支x和门控分支z。
def forward(self, hidden_states, inference_params=None):"""hidden_states: (B, L, D)Returns: same shape as hidden_states"""batch, seqlen, dim = hidden_states.shapeconv_state, ssm_state = None, Noneif inference_params is not None:conv_state, ssm_state = self._get_states_from_cache(inference_params, batch)if inference_params.seqlen_offset > 0:# The states are updated inplaceout, _, _ = self.step(hidden_states, conv_state, ssm_state)return out# We do matmul and transpose BLH -> HBL at the same timexz = rearrange(self.in_proj.weight @ rearrange(hidden_states, "b l d -> d (b l)"),"d (b l) -> b d l",l=seqlen,)if self.in_proj.bias is not None:xz = xz + rearrange(self.in_proj.bias.to(dtype=xz.dtype), "d -> d 1")
fast_path
在之后通过use_fast_path分为两种
use_fast_path
在这里通过bimamba类别又可分为三类,v1,v2和其它
bimamba_type == v1
在v1版本中,调用的函数是bimamba_inner_fn 在后面专门介绍。
if self.use_fast_path and inference_params is None: # Doesn't support outputting the statesif self.bimamba_type == "v1":A_b = -torch.exp(self.A_b_log.float())out = bimamba_inner_fn(xz,self.conv1d.weight,self.conv1d.bias,self.x_proj.weight,self.dt_proj.weight,self.out_proj.weight,self.out_proj.bias,A,A_b,None, # input-dependent BNone, # input-dependent Cself.D.float(),delta_bias=self.dt_proj.bias.float(),delta_softplus=True,) bimamba_type == v2
在v2版本中,调用的函数是mamba_inner_fn_no_out_proj在后面专门介绍。可以看到,在这里不同于v1,v2版本因为新增了一套SSM参数,因此也得到了额外的输出out_b,最后的输出也有两种模式,一是两者的简单平均,注意到因为反向SSM方向与正向方向相反,因此反向的输出要先翻转后再相加。而是直接翻转后相加。
elif self.bimamba_type == "v2":A_b = -torch.exp(self.A_b_log.float())out = mamba_inner_fn_no_out_proj(xz,self.conv1d.weight,self.conv1d.bias,self.x_proj.weight,self.dt_proj.weight,A,None, # input-dependent BNone, # input-dependent Cself.D.float(),delta_bias=self.dt_proj.bias.float(),delta_softplus=True,)out_b = mamba_inner_fn_no_out_proj(xz.flip([-1]),self.conv1d_b.weight,self.conv1d_b.bias,self.x_proj_b.weight,self.dt_proj_b.weight,A_b,None,None,self.D_b.float(),delta_bias=self.dt_proj_b.bias.float(),delta_softplus=True,)if not self.if_devide_out:out = F.linear(rearrange(out + out_b.flip([-1]), "b d l -> b l d"), self.out_proj.weight,self.out_proj.bias)else:out = F.linear(rearrange(out + out_b.flip([-1]), "b d l -> b l d") / 2, self.out_proj.weight, self.out_proj.bias)其他
如果选择了双向模式,却没有定义模式,则使用Mamba默认的mamba_inner_fn
else:out = mamba_inner_fn(xz,self.conv1d.weight,self.conv1d.bias,self.x_proj.weight,self.dt_proj.weight,self.out_proj.weight,self.out_proj.bias,A,None, # input-dependent BNone, # input-dependent Cself.D.float(),delta_bias=self.dt_proj.bias.float(),delta_softplus=True,)
no use_fast_path
和原始论文一致,如果不选择use_fast_path,则会在这里计算完整个流程,而不是定位到selective_scan_interface中定义的函数,而是计算出SSM参数后再调用selective_scan_interface中定义的selective_scan_fn(),SSM数据依赖的参数有参数映射x_proj得到x_db1,然后切分得到B, C,delta参数。
else:x, z = xz.chunk(2, dim=1)if conv_state is not None:conv_state.copy_(F.pad(x, (self.d_conv - x.shape[-1], 0))) # Update state (B D W)if causal_conv1d_fn is None:x = self.act(self.conv1d(x)[..., :seqlen])else:assert self.activation in ["silu", "swish"]x = causal_conv1d_fn(x=x,weight=rearrange(self.conv1d.weight, "d 1 w -> d w"),bias=self.conv1d.bias,activation=self.activation,)x_dbl = self.x_proj(rearrange(x, "b d l -> (b l) d")) # (bl d)dt, B, C = torch.split(x_dbl, [self.dt_rank, self.d_state, self.d_state], dim=-1)dt = self.dt_proj.weight @ dt.t()dt = rearrange(dt, "d (b l) -> b d l", l=seqlen)B = rearrange(B, "(b l) dstate -> b dstate l", l=seqlen).contiguous()C = rearrange(C, "(b l) dstate -> b dstate l", l=seqlen).contiguous()assert self.activation in ["silu", "swish"]y = selective_scan_fn(x,dt,A,B,C,self.D.float(),z=z,delta_bias=self.dt_proj.bias.float(),delta_softplus=True,return_last_state=ssm_state is not None,)if ssm_state is not None:y, last_state = yssm_state.copy_(last_state)y = rearrange(y, "b d l -> b l d")out = self.out_proj(y)if self.init_layer_scale is not None:out = out * self.gamma return out双向SSM
v1
对于v1版本双向SSM在前向时首先定义到bimamba_inner_fn,然后调用BiMambaInnerFn
def bimamba_inner_fn(xz, conv1d_weight, conv1d_bias, x_proj_weight, delta_proj_weight,out_proj_weight, out_proj_bias,A, A_b, B=None, C=None, D=None, delta_bias=None, B_proj_bias=None,C_proj_bias=None, delta_softplus=True
):return BiMambaInnerFn.apply(xz, conv1d_weight, conv1d_bias, x_proj_weight, delta_proj_weight,out_proj_weight, out_proj_bias,A, A_b, B, C, D, delta_bias, B_proj_bias, C_proj_bias, delta_softplus)
前向
去掉和原始论文中的MambaInnerFn相同的部分,在forward前向过程中,不同在于定义了两个输出,分别为out_zf和out_zb,out_zf对应于原来的前向输出,out_zb则是新增的反向输出,最终的out_z是两者翻转相加。
out_f, scan_intermediates_f, out_z_f = selective_scan_cuda.fwd(conv1d_out, delta, A, B, C, D, z, delta_bias, delta_softplus)assert not A_b.is_complex(), "A should not be complex!!"out_b, scan_intermediates_b, out_z_b = selective_scan_cuda.fwd(conv1d_out.flip([-1]), delta.flip([-1]), A_b, B.flip([-1]), C.flip([-1]), D, z.flip([-1]), delta_bias, delta_softplus,)out_z = out_z_f + out_z_b.flip([-1])后向
去掉和原始论文中的MambaInnerFn相同的部分,在backward后向过程中。对应的,定义复制了一套新参数,参数对应如下
| 原参数 | 新增后向参数 |
|---|---|
| dz | dz_b |
| dconv1d_out | dconv1d_out_f_b |
| ddelta | ddelta_f_b |
| dA | dA_b |
| dB | dB_f_b |
| dC | dC_f_b |
| dD | dD_b |
dz_b = torch.empty_like(dz)dconv1d_out_f_b, ddelta_f_b, dA_b, dB_f_b, dC_f_b, dD_b, ddelta_bias_b, dz_b, out_z_b = selective_scan_cuda.bwd(conv1d_out.flip([-1]), delta.flip([-1]), A_b, B.flip([-1]), C.flip([-1]), D, z.flip([-1]), delta_bias, dout_y.flip([-1]), scan_intermediates_b, out_b, dz_b,ctx.delta_softplus,True # option to recompute out_z)根据这些新定义的参数,我们和前向参数相加来重定义原始的参数。我们得到新的dconv1d_out,ddelta等参数,最终保持与原始SSM一致
dconv1d_out = dconv1d_out + dconv1d_out_f_b.flip([-1])ddelta = ddelta + ddelta_f_b.flip([-1])dB = dB + dB_f_b.flip([-1])dC = dC + dC_f_b.flip([-1])dD = dD + dD_bddelta_bias = ddelta_bias + ddelta_bias_bdz = dz + dz_b.flip([-1])out_z = out_z_f + out_z_b.flip([-1])
v2
对于v2版本双向Mamba在前向时首先定义到mamba_inner_fn_no_out_proj,然后调用MambaInnerFnNoOutProj。在v2版本,因为定义了两套SSM参数,因此双向的修改相比于v1要简单。
def mamba_inner_fn_no_out_proj(xz, conv1d_weight, conv1d_bias, x_proj_weight, delta_proj_weight,A, B=None, C=None, D=None, delta_bias=None, B_proj_bias=None,C_proj_bias=None, delta_softplus=True
):return MambaInnerFnNoOutProj.apply(xz, conv1d_weight, conv1d_bias, x_proj_weight, delta_proj_weight,A, B, C, D, delta_bias, B_proj_bias, C_proj_bias, delta_softplus)
前向
mamba_inner_fn_no_out_proj 即相比于原始的mamba_inner_fn缺少了输出映射。
return F.linear(rearrange(out_z, "b d l -> b l d"), out_proj_weight, out_proj_bias)
后向
相应的,在其中修改掉和out_proj_weight相关的部分。