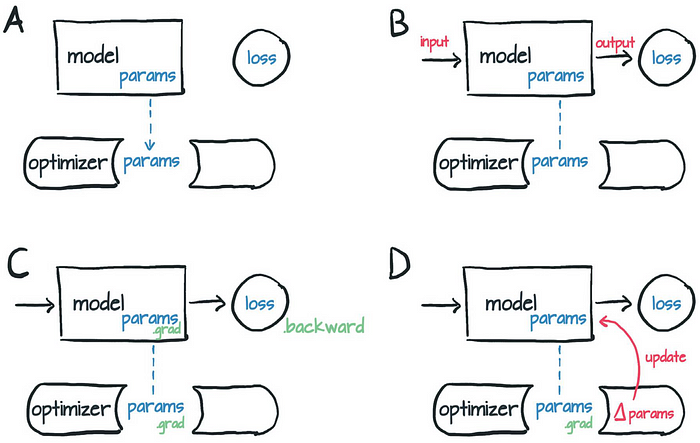
深度强化学习(七)策略梯度
策略学习的目的是通过求解一个优化问题,学出最优策略函数或它的近似函数(比如策略网络)
一.策略网络
假设动作空间是离散的,,比如 A = { 左 , 右 , 上 } \cal A=\{左,右,上\} A={左,右,上},策略函数 π \pi π是个条件概率函数:
π ( a ∣ s ) = P ( A = a ∣ S = s ) \pi(a\mid s)=\Bbb P(A=a\mid S=s) π(a∣s)=P(A=a∣S=s)
与 D Q N DQN DQN类似,我们可以用神经网络 π ( a ∣ s ; θ ) \pi(a \mid s ; \boldsymbol{\theta}) π(a∣s;θ)去近似策略函数 π ( a ∣ s ) \pi(a\mid s) π(a∣s), θ \boldsymbol \theta θ是我们需要训练的神经网络的参数。
回忆动作价值函数的定义是
Q π ( a t , s t ) = E A t + 1 , S t + 1 … [ U t ∣ A t = a t , S t = s t ] Q_{\pi}(a_t,s_t)=\Bbb E_{A_{t+1},S_{t+1}\ldots}[U_t\mid A_t=a_t,S_t=s_t] Qπ(at,st)=EAt+1,St+1…[Ut∣At=at,St=st]
状态价值函数的定义是
V π ( s t ) = E A t ∼ π ( a ∣ s ) [ Q π ( A t , s t ) ] V_{\pi}(s_t)=\Bbb E_{A_t\sim \pi(a\mid s)}[Q_{\pi}(A_t,s_t)] Vπ(st)=EAt∼π(a∣s)[Qπ(At,st)]
状态价值既依赖于当前状态 s t , 也依赖于策略网络 π 的参数 θ 。 \text { 状态价值既依赖于当前状态 } s_t \text {, 也依赖于策略网络 } \pi \text { 的参数 } \boldsymbol{\theta} \text { 。 } 状态价值既依赖于当前状态 st, 也依赖于策略网络 π 的参数 θ 。
为排除状态对策略的影响,我们对状态 S t S_t St求期望,得出
J ( θ ) = E S t [ V π ( S t ) ] J(\boldsymbol \theta)=\Bbb E_{S_t}[V_{\pi}(S_t)] J(θ)=ESt[Vπ(St)]
这个目标函数排除掉了状态 S S S 的因素,只依赖于策略网络 π \pi π的参数 θ \boldsymbol \theta θ;策略越好,则 J J J越大。所以策略学习可以描述为这样一个优化问题
Max θ J ( θ ) \text{Max}_{\boldsymbol \theta} \quad J(\boldsymbol \theta) MaxθJ(θ)
由于是求最大化问题,我们可利用梯度上升对 J ( θ ) J(\boldsymbol \theta) J(θ)进行更新,问题的关键是计算 ∇ θ J ( θ ) \nabla_{\boldsymbol \theta}J(\boldsymbol \theta) ∇θJ(θ)
二.策略梯度定理推导
Theorem:递归公式,其中 S ′ S' S′是 下一时刻的状态。
∂ V π ( s ) ∂ θ = E A ∼ π ( ⋅ ∣ s ; θ ) [ ∂ ln π ( A ∣ s ; θ ) ∂ θ ⋅ Q π ( s , A ) + γ ⋅ E S ′ ∼ p ( ⋅ ∣ s , A ) [ ∂ V π ( S ′ ) ∂ θ ] ] (2.1) \frac{\partial V_\pi(s)}{\partial \boldsymbol{\theta}}=\mathbb{E}_{A \sim \pi(\cdot \mid s ; \boldsymbol{\theta})}\left[\frac{\partial \ln \pi(A \mid s ; \boldsymbol{\theta})}{\partial \boldsymbol{\theta}} \cdot Q_\pi(s, A)+\gamma \cdot \mathbb{E}_{S^{\prime} \sim p(\cdot \mid s, A)}\left[\frac{\partial V_\pi\left(S^{\prime}\right)}{\partial \boldsymbol{\theta}}\right]\right]\tag{2.1} ∂θ∂Vπ(s)=EA∼π(⋅∣s;θ)[∂θ∂lnπ(A∣s;θ)⋅Qπ(s,A)+γ⋅ES′∼p(⋅∣s,A)[∂θ∂Vπ(S′)]](2.1)
Proof:
∂ V π ( s ) ∂ θ = ∂ ∂ θ [ E A ∼ π ( ⋅ ∣ s ; θ ) [ Q π ( s , A ) ] ] = ∂ ∂ θ [ ∑ A π ( a ∣ s ; θ ) Q π ( s , a ) ] = ∑ A [ ∂ π ( a ∣ s ; θ ) ∂ θ Q π ( s , a ) + π ( a ∣ s ; θ ) ∂ Q π ( s , a ) ∂ θ ] = ∑ A [ π ( a ∣ s ; θ ) ⋅ ∂ ln π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) + π ( a ∣ s ; θ ) ∂ Q π ( s , a ) ∂ θ ] = E A ∼ π ( ⋅ ∣ s ; θ ) [ ∂ ln π ( A ∣ s ; θ ) ∂ θ ⋅ Q π ( s , A ) ] + E A ∼ π ( ⋅ ∣ s ; θ ) [ ∂ Q π ( s , a ) ∂ θ ] . = E A ∼ π ( ⋅ ∣ s ; θ ) [ ∂ ln π ( A ∣ s ; θ ) ∂ θ ⋅ Q π ( s , A ) + ∂ Q π ( s , a ) ∂ θ ] \begin{aligned} \frac{\partial V_\pi(s)}{\partial \boldsymbol{\theta}} &=\frac{\partial}{\partial \boldsymbol \theta}[\Bbb E_{A\sim \pi(\cdot \mid s;\boldsymbol \theta)}[Q_{\pi}(s,A)]]\\ &= \frac{\partial}{\partial \boldsymbol \theta}[\sum_{A}\pi(a\mid s;\boldsymbol \theta)Q_{\pi}(s,a)]\\ &=\sum_{A}[\frac{\partial \pi(a\mid s;\boldsymbol \theta)}{\partial \boldsymbol \theta}Q_{\pi}(s,a)+\pi(a\mid s;\boldsymbol \theta)\frac{\partial Q_{\pi}(s,a)}{\partial \boldsymbol \theta}]\\ &=\sum_{A}[\pi(a\mid s;\boldsymbol \theta)\cdot\frac{\partial \ln \pi(a\mid s;\boldsymbol \theta)}{\partial \boldsymbol \theta}\cdot Q_{\pi}(s,a)+\pi(a\mid s;\boldsymbol \theta)\frac{\partial Q_{\pi}(s,a)}{\partial \boldsymbol \theta}] \\ & =\mathbb{E}_{A \sim \pi(\cdot \mid s ; \boldsymbol{\theta})}\left[\frac{\partial \ln \pi(A \mid s ; \boldsymbol{\theta})}{\partial \boldsymbol{\theta}} \cdot Q_\pi(s, A)\right]+\mathbb{E}_{A \sim \pi(\cdot \mid s ; \boldsymbol{\theta})}\left[\frac{\partial Q_\pi(s, a)}{\partial \boldsymbol{\theta}}\right] . \\ &= \mathbb{E}_{A \sim \pi(\cdot \mid s ; \boldsymbol{\theta})}[\frac{\partial \ln \pi(A \mid s ; \boldsymbol{\theta})}{\partial \boldsymbol{\theta}} \cdot Q_\pi(s, A)+\frac{\partial Q_\pi(s, a)}{\partial \boldsymbol{\theta}}] \end{aligned} ∂θ∂Vπ(s)=∂θ∂[EA∼π(⋅∣s;θ)[Qπ(s,A)]]=∂θ∂[A∑π(a∣s;θ)Qπ(s,a)]=A∑[∂θ∂π(a∣s;θ)Qπ(s,a)+π(a∣s;θ)∂θ∂Qπ(s,a)]=A∑[π(a∣s;θ)⋅∂θ∂lnπ(a∣s;θ)⋅Qπ(s,a)+π(a∣s;θ)∂θ∂Qπ(s,a)]=EA∼π(⋅∣s;θ)[∂θ∂lnπ(A∣s;θ)⋅Qπ(s,A)]+EA∼π(⋅∣s;θ)[∂θ∂Qπ(s,a)].=EA∼π(⋅∣s;θ)[∂θ∂lnπ(A∣s;θ)⋅Qπ(s,A)+∂θ∂Qπ(s,a)]
接下来仅需证明 ∂ Q π ( s , a ) ∂ θ = γ E S ′ ∼ p ( ⋅ ∣ s , A ) [ ∂ V π ( S ′ ) ∂ θ ] \frac{\partial Q_\pi(s, a)}{\partial \boldsymbol{\theta}}=\gamma \mathbb{E}_{S^{\prime} \sim p(\cdot \mid s, A)}[\frac{\partial V_\pi\left(S^{\prime}\right)}{\partial \boldsymbol{\theta}}] ∂θ∂Qπ(s,a)=γES′∼p(⋅∣s,A)[∂θ∂Vπ(S′)],贝尔曼方程为
Q π ( s , a ) = E S ′ ∼ p ( ⋅ ∣ s , a ) [ R ( s , a , S ′ ) + γ ⋅ V π ( s ′ ) ] = ∑ s ′ ∈ S p ( s ′ ∣ s , a ) ⋅ [ R ( s , a , s ′ ) + γ ⋅ V π ( s ′ ) ] = ∑ s ′ ∈ S p ( s ′ ∣ s , a ) ⋅ R ( s , a , s ′ ) + γ ⋅ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) ⋅ V π ( s ′ ) . \begin{aligned} Q_\pi(s, a) & =\mathbb{E}_{S^{\prime} \sim p(\cdot \mid s, a)}\left[R\left(s, a, S^{\prime}\right)+\gamma \cdot V_\pi\left(s^{\prime}\right)\right] \\ & =\sum_{s^{\prime} \in \mathcal{S}} p\left(s^{\prime} \mid s, a\right) \cdot\left[R\left(s, a, s^{\prime}\right)+\gamma \cdot V_\pi\left(s^{\prime}\right)\right] \\ & =\sum_{s^{\prime} \in \mathcal{S}} p\left(s^{\prime} \mid s, a\right) \cdot R\left(s, a, s^{\prime}\right)+\gamma \cdot \sum_{s^{\prime} \in \mathcal{S}} p\left(s^{\prime} \mid s, a\right) \cdot V_\pi\left(s^{\prime}\right) . \end{aligned} Qπ(s,a)=ES′∼p(⋅∣s,a)[R(s,a,S′)+γ⋅Vπ(s′)]=s′∈S∑p(s′∣s,a)⋅[R(s,a,s′)+γ⋅Vπ(s′)]=s′∈S∑p(s′∣s,a)⋅R(s,a,s′)+γ⋅s′∈S∑p(s′∣s,a)⋅Vπ(s′).
在观测到 s 、 a 、 s ′ s 、 a 、 s^{\prime} s、a、s′ 之后, p ( s ′ ∣ s , a ) p\left(s^{\prime} \mid s, a\right) p(s′∣s,a) 和 R ( s , a , s ′ ) R\left(s, a, s^{\prime}\right) R(s,a,s′) 都与策略网络 π \pi π 无关, 因此
∂ ∂ θ [ p ( s ′ ∣ s , a ) ⋅ R ( s , a , s ′ ) ] = 0. \frac{\partial}{\partial \boldsymbol{\theta}}\left[p\left(s^{\prime} \mid s, a\right) \cdot R\left(s, a, s^{\prime}\right)\right]=0 . ∂θ∂[p(s′∣s,a)⋅R(s,a,s′)]=0.
可得:
∂ Q π ( s , a ) ∂ θ = ∑ s ′ ∈ S ∂ ∂ θ [ p ( s ′ ∣ s , a ) ⋅ R ( s , a , s ′ ) ] ⏟ 等于零 + γ ⋅ ∑ s ′ ∈ S ∂ ∂ θ [ p ( s ′ ∣ s , a ) ⋅ V π ( s ′ ) ] = γ ⋅ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) ⋅ ∂ V π ( s ′ ) ∂ θ = γ ⋅ E S ′ ∼ p ( ⋅ ∣ s , a ) [ ∂ V π ( S ′ ) ∂ θ ] . \begin{aligned} \frac{\partial Q_\pi(s, a)}{\partial \boldsymbol{\theta}} & =\sum_{s^{\prime} \in \mathcal{S}} \underbrace{\frac{\partial}{\partial \boldsymbol{\theta}}\left[p\left(s^{\prime} \mid s, a\right) \cdot R\left(s, a, s^{\prime}\right)\right]}_{\text {等于零 }}+\gamma \cdot \sum_{s^{\prime} \in \mathcal{S}} \frac{\partial}{\partial \boldsymbol{\theta}}\left[p\left(s^{\prime} \mid s, a\right) \cdot V_\pi\left(s^{\prime}\right)\right] \\ & =\gamma \cdot \sum_{s^{\prime} \in \mathcal{S}} p\left(s^{\prime} \mid s, a\right) \cdot \frac{\partial V_\pi\left(s^{\prime}\right)}{\partial \boldsymbol{\theta}} \\ & =\gamma \cdot \mathbb{E}_{S^{\prime} \sim p(\cdot \mid s, a)}\left[\frac{\partial V_\pi\left(S^{\prime}\right)}{\partial \boldsymbol{\theta}}\right] . \end{aligned} ∂θ∂Qπ(s,a)=s′∈S∑等于零 ∂θ∂[p(s′∣s,a)⋅R(s,a,s′)]+γ⋅s′∈S∑∂θ∂[p(s′∣s,a)⋅Vπ(s′)]=γ⋅s′∈S∑p(s′∣s,a)⋅∂θ∂Vπ(s′)=γ⋅ES′∼p(⋅∣s,a)[∂θ∂Vπ(S′)].
证毕
设 g ( s , a ; θ ) ≜ Q π ( s , a ) ⋅ ∂ ln π ( a ∣ s ; θ ) ∂ θ \boldsymbol{g}(s, a ; \boldsymbol{\theta}) \triangleq Q_\pi(s, a) \cdot \frac{\partial \ln \pi(a \mid s ; \theta)}{\partial \boldsymbol{\theta}} g(s,a;θ)≜Qπ(s,a)⋅∂θ∂lnπ(a∣s;θ) 。设一局游戏在第 n n n 步之后结束。那么
∂ J ( θ ) ∂ θ = E S 1 , A 1 [ g ( S 1 , A 1 ; θ ) ] + γ ⋅ E S 1 , A 1 , S 2 , A 2 [ g ( S 2 , A 2 ; θ ) ] + γ 2 ⋅ E S 1 , A 1 , S 2 , A 2 , S 3 , A 3 [ g ( S 3 , A 3 ; θ ) ] + ⋯ + γ n − 1 ⋅ E S 1 , A 1 , S 2 , A 2 , S 3 , A 3 , ⋯ S n , A n [ g ( S n , A n ; θ ) ] (2.2) \begin{aligned} \frac{\partial J(\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}= & \mathbb{E}_{S_1, A_1}\left[\boldsymbol{g}\left(S_1, A_1 ; \boldsymbol{\theta}\right)\right] \\ & +\gamma \cdot \mathbb{E}_{S_1, A_1, S_2, A_2}\left[\boldsymbol{g}\left(S_2, A_2 ; \boldsymbol{\theta}\right)\right] \\ & +\gamma^2 \cdot \mathbb{E}_{S_1, A_1, S_2, A_2, S_3, A_3}\left[\boldsymbol{g}\left(S_3, A_3 ; \boldsymbol{\theta}\right)\right] \\ & +\cdots \\ & \left.+\gamma^{n-1} \cdot \mathbb{E}_{S_1, A_1, S_2, A_2, S_3, A_3, \cdots S_n, A_n}[\boldsymbol{g}\left(S_n, A_n ; \boldsymbol{\theta}\right)\right] \end{aligned} \tag{2.2} ∂θ∂J(θ)=ES1,A1[g(S1,A1;θ)]+γ⋅ES1,A1,S2,A2[g(S2,A2;θ)]+γ2⋅ES1,A1,S2,A2,S3,A3[g(S3,A3;θ)]+⋯+γn−1⋅ES1,A1,S2,A2,S3,A3,⋯Sn,An[g(Sn,An;θ)](2.2)
Proof:由式 2.1 2.1 2.1可知
∇ θ V π ( s t ) = E A t ∼ π ( ⋅ ∣ s t ; θ ) [ ∂ ln π ( A t ∣ s t ; θ ) ∂ θ ⋅ Q π ( s t , A t ) + γ ⋅ E S t + 1 ∼ p ( ⋅ ∣ s t , A t ) [ ∇ θ V π ( S t + 1 ) ] ] = E A t ∼ π ( ⋅ ∣ s t ; θ ) [ g ( s t , A t ; θ ) + γ ⋅ E S t + 1 [ ∇ θ V π ( S t + 1 ) ∣ A t , S t = s t ] ] = E A t [ g ( s t , A t ; θ ) ∣ S t = s t ] + γ E A t [ E S t + 1 [ ∇ θ V π ( S t + 1 ) ∣ A t , S t = s t ] ∣ S t = s t ] = E A t [ g ( s t , A t ; θ ) ∣ S t = s t ] + γ E A t , S t + 1 [ ∇ θ V π ( S t + 1 ) ∣ S t = s t ] \begin{aligned} \nabla_{\boldsymbol \theta }V_{\pi}(s_t)&=\mathbb{E}_{A_t \sim \pi(\cdot \mid s_t ; \boldsymbol{\theta})}\left[\frac{\partial \ln \pi(A_t \mid s_t ; \boldsymbol{\theta})}{\partial \boldsymbol{\theta}} \cdot Q_\pi(s_t, A_t)+\gamma \cdot \mathbb{E}_{S_{t+1} \sim p(\cdot \mid s_t, A_t)}[\nabla _{\boldsymbol \theta}V_\pi\left(S_{t+1}\right)]\right]\\ &=\mathbb{E}_{A_t \sim \pi(\cdot \mid s_t ; \boldsymbol{\theta})}\left[\boldsymbol g(s_t,A_t;\boldsymbol \theta)+\gamma \cdot \mathbb{E}_{S_{t+1} }[\nabla _{\boldsymbol \theta}V_\pi\left(S_{t+1}\right)\mid A_t,S_t=s_t]\right]\\ &=\Bbb E_{A_t}[\boldsymbol g(s_t,A_t;\boldsymbol \theta)\mid S_t=s_t]+\gamma \Bbb E_{A_t}[\Bbb E_{S_{t+1}}[\nabla_{\boldsymbol \theta}V_{\pi}(S_{t+1})\mid A_t,S_t=s_t]\mid S_t=s_t]\\ &=\Bbb E_{A_t}[\boldsymbol g(s_t,A_t;\boldsymbol \theta)\mid S_t=s_t]+\gamma \Bbb E_{A_t,S_{t+1}}[\nabla_{\boldsymbol \theta}V_{\pi}(S_{t+1})\mid S_t=s_t] \end{aligned} ∇θVπ(st)=EAt∼π(⋅∣st;θ)[∂θ∂lnπ(At∣st;θ)⋅Qπ(st,At)+γ⋅ESt+1∼p(⋅∣st,At)[∇θVπ(St+1)]]=EAt∼π(⋅∣st;θ)[g(st,At;θ)+γ⋅ESt+1[∇θVπ(St+1)∣At,St=st]]=EAt[g(st,At;θ)∣St=st]+γEAt[ESt+1[∇θVπ(St+1)∣At,St=st]∣St=st]=EAt[g(st,At;θ)∣St=st]+γEAt,St+1[∇θVπ(St+1)∣St=st]
则 ∇ θ V π ( S t + 1 ) = E A t + 1 [ g ( S t + 1 , A t + 1 ; θ ) ∣ S t + 1 ] + γ E A t + 1 , S t + 2 [ ∇ θ V π ( S t + 2 ) ∣ S t + 1 ] \nabla_{\boldsymbol \theta }V_{\pi}(S_{t+1})=\Bbb E_{A_{t+1}}[\boldsymbol g(S_{t+1},A_{t+1};\boldsymbol \theta)\mid S_{t+1}]+\gamma \Bbb E_{A_{t+1},S_{t+2}}[\nabla_{\boldsymbol \theta}V_{\pi}(S_{t+2})\mid S_{t+1}] ∇θVπ(St+1)=EAt+1[g(St+1,At+1;θ)∣St+1]+γEAt+1,St+2[∇θVπ(St+2)∣St+1],带入上式中可得
∇ θ V π ( s t ) = E A t [ g ( s t , A t ; θ ) ∣ S t = s t ] + γ E A t , S t + 1 [ ∇ θ V π ( S t + 1 ) ∣ S t = s t ] = E A t [ g ( s t , A t ; θ ) ∣ S t = s t ] + γ E A t , S t + 1 [ E A t + 1 [ g ( S t + 1 , A t + 1 ; θ ) ∣ S t + 1 ] + γ E A t + 1 , S t + 2 [ ∇ θ V π ( S t + 2 ) ∣ S t + 1 ] ∣ S t = s t ] = E A t [ g ( s t , A t ; θ ) ∣ S t = s t ] + γ E A t , S t + 1 [ E A t + 1 [ g ( S t + 1 , A t + 1 ; θ ) ∣ S t + 1 , S t = s t , A t ] + γ E A t + 1 , S t + 2 [ [ ∇ θ V π ( S t + 2 ) ∣ S t + 1 ] ∣ S t = s t ] 马尔可可夫性 = E A t [ g ( s t , A t ; θ ) ∣ S t = s t ] + γ E A t , S t + 1 , A t + 1 [ g ( S t + 1 , A t + 1 ; θ ) ∣ S t = s t ] + γ E A t + 1 , S t + 2 [ [ ∇ θ V π ( S t + 2 ) ∣ S t + 1 ] ∣ S t = s t ] \begin{aligned} \nabla_{\boldsymbol \theta }V_{\pi}(s_t)&=\Bbb E_{A_t}[\boldsymbol g(s_t,A_t;\boldsymbol \theta)\mid S_t=s_t]+\gamma \Bbb E_{A_t,S_{t+1}}[\nabla_{\boldsymbol \theta}V_{\pi}(S_{t+1})\mid S_t=s_t]\\ &=\Bbb E_{A_t}[\boldsymbol g(s_t,A_t;\boldsymbol \theta)\mid S_t=s_t]+\gamma \Bbb E_{A_t,S_{t+1}}[\Bbb E_{A_{t+1}}[\boldsymbol g(S_{t+1},A_{t+1};\boldsymbol \theta)\mid S_{t+1}]+\gamma \Bbb E_{A_{t+1},S_{t+2}}[\nabla_{\boldsymbol \theta}V_{\pi}(S_{t+2})\mid S_{t+1}]\mid S_t=s_t]\\ &=\Bbb E_{A_t}[\boldsymbol g(s_t,A_t;\boldsymbol \theta)\mid S_t=s_t]+\gamma \Bbb E_{A_t,S_{t+1}}[\Bbb E_{A_{t+1}}[\boldsymbol g(S_{t+1},A_{t+1};\boldsymbol \theta)\mid S_{t+1},S_t=s_t,A_t]+\gamma \Bbb E_{A_{t+1},S_{t+2}}[[\nabla_{\boldsymbol \theta}V_{\pi}(S_{t+2})\mid S_{t+1}]\mid S_t=s_t]\text{马尔可可夫性}\\ &= \Bbb E_{A_t}[\boldsymbol g(s_t,A_t;\boldsymbol \theta)\mid S_t=s_t]+\gamma\Bbb E_{A_t,S_{t+1},A_{t+1}}[\boldsymbol g(S_{t+1},A_{t+1};\boldsymbol \theta)\mid S_t=s_t]+\gamma \Bbb E_{A_{t+1},S_{t+2}}[[\nabla_{\boldsymbol \theta}V_{\pi}(S_{t+2})\mid S_{t+1}]\mid S_t=s_t] \end{aligned} ∇θVπ(st)=EAt[g(st,At;θ)∣St=st]+γEAt,St+1[∇θVπ(St+1)∣St=st]=EAt[g(st,At;θ)∣St=st]+γEAt,St+1[EAt+1[g(St+1,At+1;θ)∣St+1]+γEAt+1,St+2[∇θVπ(St+2)∣St+1]∣St=st]=EAt[g(st,At;θ)∣St=st]+γEAt,St+1[EAt+1[g(St+1,At+1;θ)∣St+1,St=st,At]+γEAt+1,St+2[[∇θVπ(St+2)∣St+1]∣St=st]马尔可可夫性=EAt[g(st,At;θ)∣St=st]+γEAt,St+1,At+1[g(St+1,At+1;θ)∣St=st]+γEAt+1,St+2[[∇θVπ(St+2)∣St+1]∣St=st]
继续利用上式反复带入,最后可得
∂ V π ( S 1 ) ∂ θ = E A 1 [ g ( S 1 , A 1 ; θ ) ∣ S 1 ] + γ ⋅ E A 1 , S 2 , A 2 [ g ( S 2 , A 2 ; θ ) ∣ S 1 ] + γ 2 ⋅ E A 1 , S 2 , A 2 , S 3 , A 3 [ g ( S 3 , A 3 ; θ ) ∣ S 1 ] + ⋯ + γ n − 1 ⋅ E A 1 , S 2 , A 2 , S 3 , A 3 , ⋯ S n , A n [ g ( S n , A n ; θ ) ∣ S 1 ] + γ n ⋅ E A 1 , S 2 , A 2 , S 3 , A 3 , ⋯ S n , A n , S n + 1 [ ∂ V π ( S n + 1 ) ∂ θ ⏟ 等于零 ∣ S 1 ] \begin{aligned} \frac{\partial V_\pi\left(S_1\right)}{\partial \boldsymbol{\theta}}= & \mathbb{E}_{A_1}\left[\boldsymbol{g}\left(S_1, A_1 ; \boldsymbol{\theta}\right)\mid S_1\right] \\ & +\gamma \cdot \mathbb{E}_{A_1, S_2, A_2}\left[\boldsymbol{g}\left(S_2, A_2 ; \boldsymbol{\theta}\right)\mid S_1\right] \\ & +\gamma^2 \cdot \mathbb{E}_{A_1, S_2, A_2, S_3, A_3}\left[\boldsymbol{g}\left(S_3, A_3 ; \boldsymbol{\theta}\right)\mid S_1\right] \\ & +\cdots \\ & +\gamma^{n-1} \cdot \mathbb{E}_{A_1, S_2, A_2, S_3, A_3, \cdots S_n, A_n}\left[\boldsymbol{g}\left(S_n, A_n ; \boldsymbol{\theta}\right)\mid S_1\right] \\ &+\gamma^n \cdot \mathbb{E}_{A_1, S_2, A_2, S_3, A_3, \cdots S_n, A_n, S_{n+1}}[\underbrace{\frac{\partial V_\pi\left(S_{n+1}\right)}{\partial \boldsymbol{\theta}}}_{\text {等于零 }}\mid S_1] \end{aligned} ∂θ∂Vπ(S1)=EA1[g(S1,A1;θ)∣S1]+γ⋅EA1,S2,A2[g(S2,A2;θ)∣S1]+γ2⋅EA1,S2,A2,S3,A3[g(S3,A3;θ)∣S1]+⋯+γn−1⋅EA1,S2,A2,S3,A3,⋯Sn,An[g(Sn,An;θ)∣S1]+γn⋅EA1,S2,A2,S3,A3,⋯Sn,An,Sn+1[等于零 ∂θ∂Vπ(Sn+1)∣S1]
上式中最后一项等于零,原因是游戏在n时刻后结束,而 n + 1 n+1 n+1时刻之后没有奖励,所以 n + 1 n+1 n+1时刻的回报和价值都是零。最后,由上面的公式和,最后,由 J ( θ ) J(\boldsymbol \theta) J(θ)定义知
∂ J ( θ ) ∂ θ = E S 1 [ ∂ V π ( S 1 ) ∂ θ ] \frac{\partial J(\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}=\mathbb{E}_{S_1}\left[\frac{\partial V_\pi\left(S_1\right)}{\partial \boldsymbol{\theta}}\right] ∂θ∂J(θ)=ES1[∂θ∂Vπ(S1)]
证毕
稳态分布:想要严格证明策略梯度定理, 需要用到马尔科夫链 (Markov chain) 的稳态分布 (stationary distribution)。设状态 S ′ S^{\prime} S′ 是这样得到的: S → A → S ′ S \rightarrow A \rightarrow S^{\prime} S→A→S′ 。回忆一下, 状态转移函数 p ( S ′ ∣ S , A ) p\left(S^{\prime} \mid S, A\right) p(S′∣S,A), 是一个概率质量函数。设 f ( S ) f(S) f(S) 是状态 S S S 的概率质量函数那么状态 S ′ S^{\prime} S′的边缘分布 f ( S ′ ) f(S') f(S′)是
f ( S ′ ) = E S , A [ p ( S ′ ∣ A , S ) ] = E S [ E A [ p ( S ′ ∣ A , S ) ∣ S ] ] = E S [ ∑ A p ( S ′ ∣ a , S ) ⋅ π ( a ∣ S ) ] = ∑ S ∑ A p ( S ′ ∣ a , s ) ⋅ π ( a ∣ s ) ⋅ f ( s ) \begin{aligned} f(S')&=\Bbb E_{S,A}[p(S'\mid A,S)]\\ &=\Bbb E_{S}[\Bbb E_{A}[p(S'\mid A,S)\mid S]]\\ &=\Bbb E_{S}[\sum_{A}p(S'\mid a,S)\cdot \pi(a\mid S)]\\ &=\sum_{S}\sum_{A}p(S'\mid a,s)\cdot \pi(a\mid s)\cdot f(s) \end{aligned} f(S′)=ES,A[p(S′∣A,S)]=ES[EA[p(S′∣A,S)∣S]]=ES[A∑p(S′∣a,S)⋅π(a∣S)]=S∑A∑p(S′∣a,s)⋅π(a∣s)⋅f(s)
如果 f ( S ′ ) f(S') f(S′) 与 f ( S ) f(S) f(S) 是相同的概率质量函数, 即 $f(S)=f(S’) $, 则意味着马尔科夫链达到稳态, 而 f ( S ) f(S) f(S) 就是稳态时的概率质量函数。
Theorem:
设 f ( S ) f(S) f(S) 是马尔科夫链稳态时的概率质量 (密度) 函数。那么对于任意函数 G ( S ′ ) G\left(S^{\prime}\right) G(S′),
E S ∼ f ( ⋅ ) [ E A ∼ π ( ⋅ ∣ S ; θ ) [ E S ′ ∼ p ( ⋅ ∣ s , A ) [ G ( S ′ ) ] ] ] = E S ′ ∼ f ( ⋅ ) [ G ( S ′ ) ] (2.3) \mathbb{E}_{S \sim f(\cdot)}\left[\mathbb{E}_{A \sim \pi(\cdot \mid S ; \boldsymbol{\theta})}\left[\mathbb{E}_{S^{\prime} \sim p(\cdot \mid s, A)}\left[G\left(S^{\prime}\right)\right]\right]\right]=\mathbb{E}_{S^{\prime} \sim f(\cdot)}\left[G\left(S^{\prime}\right)\right]\tag{2.3} ES∼f(⋅)[EA∼π(⋅∣S;θ)[ES′∼p(⋅∣s,A)[G(S′)]]]=ES′∼f(⋅)[G(S′)](2.3)
Proof:
E S ∼ f ( ⋅ ) [ E A ∼ π ( ⋅ ∣ S ; θ ) [ E S ′ ∼ p ( ⋅ ∣ S , A ) [ G ( S ′ ) ] ] ] = E S ∼ f ( ⋅ ) [ E A [ E S ′ [ G ( S ′ ) ∣ S , A ] ∣ S ] ] = E S ∼ f ( ⋅ ) [ E A , S ′ [ G ( S ′ ) ∣ S ] ] = E S , A , S ′ [ G ( S ′ ) ] = E S ′ [ G ( S ′ ) ] \begin{aligned} \mathbb{E}_{S \sim f(\cdot)}\left[\mathbb{E}_{A \sim \pi(\cdot \mid S ; \boldsymbol{\theta})}\left[\mathbb{E}_{S^{\prime} \sim p(\cdot \mid S, A)}\left[G\left(S^{\prime}\right)\right]\right]\right]&= \Bbb E_{S\sim f(\cdot)}[\Bbb E_{A}[\Bbb E_{S'}[G(S')\mid S,A]\mid S]]\\ &=\Bbb E_{S\sim f(\cdot)}[\Bbb E_{A,S'}[G(S')\mid S]]\\ &=\Bbb E_{S,A,S'}[G(S')]\\ &=\Bbb E_{S'}[G(S')] \end{aligned} ES∼f(⋅)[EA∼π(⋅∣S;θ)[ES′∼p(⋅∣S,A)[G(S′)]]]=ES∼f(⋅)[EA[ES′[G(S′)∣S,A]∣S]]=ES∼f(⋅)[EA,S′[G(S′)∣S]]=ES,A,S′[G(S′)]=ES′[G(S′)]
又因 S , S ′ S,S' S,S′有相同的分布 f ( ⋅ ) f(\cdot) f(⋅),所以 E S ′ [ G ( S ′ ) ] = E S ′ ∼ f ( ⋅ ) [ G ( S ′ ) ] \Bbb E_{S'}[G(S')]=\mathbb{E}_{S^{\prime} \sim f(\cdot)}\left[G\left(S^{\prime}\right)\right] ES′[G(S′)]=ES′∼f(⋅)[G(S′)]
Theorem:策略梯度定理
设目标函数为 J ( θ ) = E S ∼ f ( ⋅ ) [ V π ( S ) ] J(\boldsymbol{\theta})=\mathbb{E}_{S \sim f(\cdot)}\left[V_\pi(S)\right] J(θ)=ES∼f(⋅)[Vπ(S)], 设 f ( S ) f(S) f(S) 为马尔科夫链稳态分布的概率质量 (密度) 函数。那么
∂ J ( θ ) ∂ θ = ( 1 + γ + γ 2 + ⋯ + γ n − 1 ) ⋅ E S ∼ f ( ⋅ ) [ E A ∼ π ( ⋅ ∣ S ; θ ) [ ∂ ln π ( A ∣ S ; θ ) ∂ θ ⋅ Q π ( S , A ) ] ] \frac{\partial J(\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}=\left(1+\gamma+\gamma^2+\cdots+\gamma^{n-1}\right) \cdot \mathbb{E}_{S \sim f(\cdot)}\left[\mathbb{E}_{A \sim \pi(\cdot \mid S ; \boldsymbol{\theta})}\left[\frac{\partial \ln \pi(A \mid S ; \boldsymbol{\theta})}{\partial \boldsymbol{\theta}} \cdot Q_\pi(S, A)\right]\right] ∂θ∂J(θ)=(1+γ+γ2+⋯+γn−1)⋅ES∼f(⋅)[EA∼π(⋅∣S;θ)[∂θ∂lnπ(A∣S;θ)⋅Qπ(S,A)]]
Proof:设初始状态 S 1 S_1 S1 服从马尔科夫链的稳态分布,它的概率质量函数是 f ( S 1 ) f\left(S_1\right) f(S1) 。对于所有的 t = 1 , ⋯ , n t=1, \cdots, n t=1,⋯,n, 动作 A t A_t At 根据策略网络抽样得到:
A t ∼ π ( ⋅ ∣ S t ; θ ) A_t \sim \pi\left(\cdot \mid S_t ; \boldsymbol{\theta}\right) At∼π(⋅∣St;θ)
对于任意函数 G G G, 反复应用式 2.3 可得:
E A 1 , … , A t − 1 , S 1 , … , S t [ G ( S t ) ] = E S 1 ∼ f { E A 1 ∼ π , S 2 ∼ p { E A 2 , S 3 , A 3 , S 4 , ⋯ , A t − 1 , S t [ G ( S t ) ] } } = E S 2 ∼ f { E A 2 , S 3 , A 3 , S 4 , ⋯ , A t − 1 , S t [ G ( S t ) ] } = E S 2 ∼ f { E A 2 ∼ π , S 3 ∼ p { E A 3 , S 4 , A 4 , S 5 , ⋯ , A t − 1 , S t [ G ( S t ) ] } } = E S 3 ∼ f { E A 3 , S 4 , A 4 , S 5 , ⋯ , A t − 1 , S t [ G ( S t ) ] } ⋮ = E S t − 1 ∼ f { E A t − 1 ∼ π , S t ∼ p { G ( S t ) } } = E S t ∼ f { G ( S t ) } . \begin{aligned} \Bbb E_{A_1,\ldots,A_{t-1},S_1,\ldots,S_{t}}[G(S_t)] & =\mathbb{E}_{S_1 \sim f}\left\{\mathbb{E}_{A_1 \sim \pi, S_2 \sim p}\left\{\mathbb{E}_{A_2, S_3, A_3, S_4, \cdots, A_{t-1}, S_t}\left[G\left(S_t\right)\right]\right\}\right\} \\ & =\mathbb{E}_{S_2 \sim f}\left\{\mathbb{E}_{A_2, S_3, A_3, S_4, \cdots, A_{t-1}, S_t}\left[G\left(S_t\right)\right]\right\} \quad \\ & =\mathbb{E}_{S_2 \sim f}\left\{\mathbb{E}_{A_2 \sim \pi, S_3 \sim p}\left\{\mathbb{E}_{A_3, S_4, A_4, S_5, \cdots, A_{t-1}, S_t}\left[G\left(S_t\right)\right]\right\}\right\} \\ & =\mathbb{E}_{S_3 \sim f}\left\{\mathbb{E}_{A_3, S_4, A_4, S_5, \cdots, A_{t-1}, S_t}\left[G\left(S_t\right)\right]\right\} \quad \\ & \vdots \\ & =\mathbb{E}_{S_{t-1} \sim f}\left\{\mathbb{E}_{A_{t-1} \sim \pi, S_t \sim p}\left\{G\left(S_t\right)\right\}\right\} \\ & =\mathbb{E}_{S_t \sim f}\left\{G\left(S_t\right)\right\} . \end{aligned} EA1,…,At−1,S1,…,St[G(St)]=ES1∼f{EA1∼π,S2∼p{EA2,S3,A3,S4,⋯,At−1,St[G(St)]}}=ES2∼f{EA2,S3,A3,S4,⋯,At−1,St[G(St)]}=ES2∼f{EA2∼π,S3∼p{EA3,S4,A4,S5,⋯,At−1,St[G(St)]}}=ES3∼f{EA3,S4,A4,S5,⋯,At−1,St[G(St)]}⋮=ESt−1∼f{EAt−1∼π,St∼p{G(St)}}=ESt∼f{G(St)}.
设 g ( s , a ; θ ) ≜ Q π ( s , a ) ⋅ ∂ ln π ( a ∣ s ; θ ) ∂ θ \boldsymbol{g}(s, a ; \boldsymbol{\theta}) \triangleq Q_\pi(s, a) \cdot \frac{\partial \ln \pi(a \mid s ; \boldsymbol{\theta})}{\partial \boldsymbol{\theta}} g(s,a;θ)≜Qπ(s,a)⋅∂θ∂lnπ(a∣s;θ) 。设一局游戏在第 n n n 步之后结束。由式2.2与上面的公式可得:
∂ J ( θ ) ∂ θ = E S 1 , A 1 [ g ( S 1 , A 1 ; θ ) ] + γ ⋅ E S 1 , A 1 , S 2 , A 2 [ g ( S 2 , A 2 ; θ ) ] + γ 2 ⋅ E S 1 , A 1 , S 2 , A 2 , S 3 , A 3 [ g ( S 3 , A 3 ; θ ) ] + ⋯ + γ n − 1 ⋅ E S 1 , A 1 , S 2 , A 2 , S 3 , A 3 , ⋯ S n , A n [ g ( S n , A n ; θ ) ] ] = E S 1 ∼ f ( ⋅ ) { E A 1 ∼ π ( ⋅ ∣ S 1 ; θ ) [ g ( S 1 , A 1 ; θ ) ] } + γ ⋅ E S 2 ∼ f ( ⋅ ) { E A 2 ∼ π ( ⋅ ∣ S 2 ; θ ) [ g ( S 2 , A 2 ; θ ) ] } + γ 2 ⋅ E S 3 ∼ f ( ⋅ ) { E A 3 ∼ π ( ⋅ ∣ S 3 ; θ ) [ g ( S 3 , A 3 ; θ ) ] } + ⋯ + γ n − 1 ⋅ E S n ∼ f ( ⋅ ) { E A n ∼ π ( ⋅ ∣ S n ; θ ) [ g ( S n , A n ; θ ) ] } = ( 1 + γ + γ 2 + ⋯ + γ n − 1 ) ⋅ E S ∼ f ( ⋅ ) { E A ∼ π ( ⋅ ∣ S ; θ ) [ g ( S , A ; θ ) ] } . \begin{aligned} \frac{\partial J(\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}= & \mathbb{E}_{S_1, A_1}\left[\boldsymbol{g}\left(S_1, A_1 ; \boldsymbol{\theta}\right)\right] \\ & +\gamma \cdot \mathbb{E}_{S_1, A_1, S_2, A_2}\left[\boldsymbol{g}\left(S_2, A_2 ; \boldsymbol{\theta}\right)\right] \\ & +\gamma^2 \cdot \mathbb{E}_{S_1, A_1, S_2, A_2, S_3, A_3}\left[\boldsymbol{g}\left(S_3, A_3 ; \boldsymbol{\theta}\right)\right] \\ & +\cdots \\ & \left.+\gamma^{n-1} \cdot \mathbb{E}_{S_1, A_1, S_2, A_2, S_3, A_3, \cdots S_n, A_n}\left[\boldsymbol{g}\left(S_n, A_n ; \boldsymbol{\theta}\right)\right]\right] \\ = & \mathbb{E}_{S_1 \sim f(\cdot)}\left\{\mathbb{E}_{A_1 \sim \pi\left(\cdot \mid S_1 ; \boldsymbol{\theta}\right)}\left[\boldsymbol{g}\left(S_1, A_1 ; \boldsymbol{\theta}\right)\right]\right\} \\ & +\gamma \cdot \mathbb{E}_{S_2 \sim f(\cdot)}\left\{\mathbb{E}_{A_2 \sim \pi\left(\cdot \mid S_2 ; \boldsymbol{\theta}\right)}\left[\boldsymbol{g}\left(S_2, A_2 ; \boldsymbol{\theta}\right)\right]\right\} \\ & +\gamma^2 \cdot \mathbb{E}_{S_3 \sim f(\cdot)}\left\{\mathbb{E}_{A_3 \sim \pi\left(\cdot \mid S_3 ; \boldsymbol{\theta}\right)}\left[\boldsymbol{g}\left(S_3, A_3 ; \boldsymbol{\theta}\right)\right]\right\} \\ & +\cdots \\ & +\gamma^{n-1} \cdot \mathbb{E}_{S_n \sim f(\cdot)}\left\{\mathbb{E}_{A_n \sim \pi\left(\cdot \mid S_n ; \boldsymbol{\theta}\right)}\left[\boldsymbol{g}\left(S_n, A_n ; \boldsymbol{\theta}\right)\right]\right\} \\ = & \left(1+\gamma+\gamma^2+\cdots+\gamma^{n-1}\right) \cdot \mathbb{E}_{S \sim f(\cdot)}\left\{\mathbb{E}_{A \sim \pi(\cdot \mid S ; \boldsymbol{\theta})}[\boldsymbol{g}(S, A ; \boldsymbol{\theta})]\right\} . \end{aligned} ∂θ∂J(θ)===ES1,A1[g(S1,A1;θ)]+γ⋅ES1,A1,S2,A2[g(S2,A2;θ)]+γ2⋅ES1,A1,S2,A2,S3,A3[g(S3,A3;θ)]+⋯+γn−1⋅ES1,A1,S2,A2,S3,A3,⋯Sn,An[g(Sn,An;θ)]]ES1∼f(⋅){EA1∼π(⋅∣S1;θ)[g(S1,A1;θ)]}+γ⋅ES2∼f(⋅){EA2∼π(⋅∣S2;θ)[g(S2,A2;θ)]}+γ2⋅ES3∼f(⋅){EA3∼π(⋅∣S3;θ)[g(S3,A3;θ)]}+⋯+γn−1⋅ESn∼f(⋅){EAn∼π(⋅∣Sn;θ)[g(Sn,An;θ)]}(1+γ+γ2+⋯+γn−1)⋅ES∼f(⋅){EA∼π(⋅∣S;θ)[g(S,A;θ)]}.
证毕