前言
在做性能测试时,如果有一个性能测试结果实时展示的页面,可以极大的提高我们对系统性能表现的掌握程度,进而提高我们的测试效率。但是我们每次打开Jmeter都会有几个硕大的字提示别用GUI模式进行负载测试,而且它自带的监视器效果实在一般:在Windows下渲染效果不好,在linux环境(非GUI环境)下更是无法使用,这一点我在之前的文章中有过简单的描述。
所以,在做性能测试时,为Jmeter构建一个可视化的监控环境平台是非常有价值的。这也是这篇博客的目的。
首先我们来看一下最后的成品,监控了TPS、并发、请求成功率、失败率、请求&接收数据大小、平均响应时长、95%的请求平均响应时长等等。(这里面的各个板块都是可自定义配置的,无论多花里花哨都可以[奸笑脸])

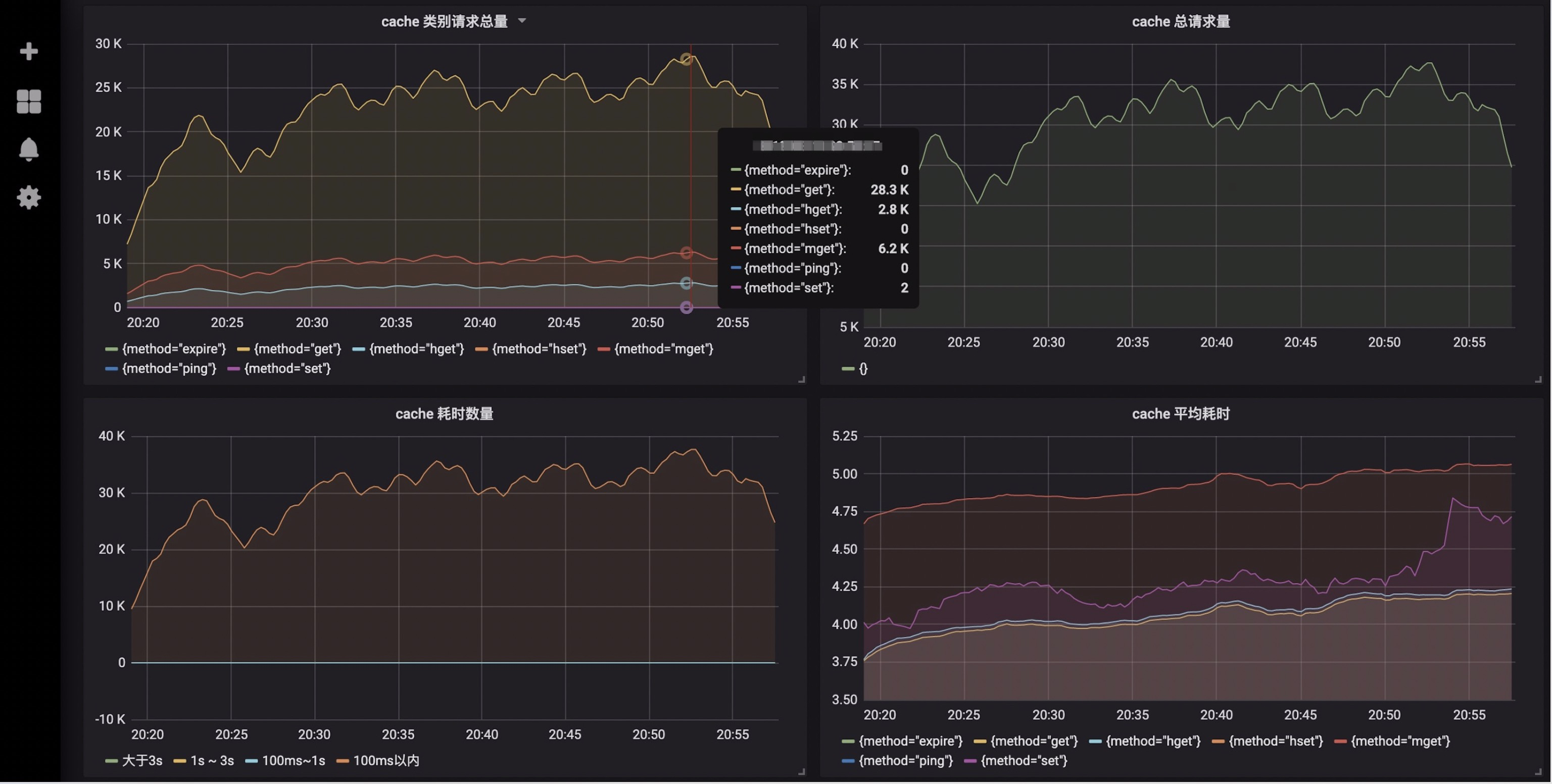
业务服务监控:精确到具体的接口
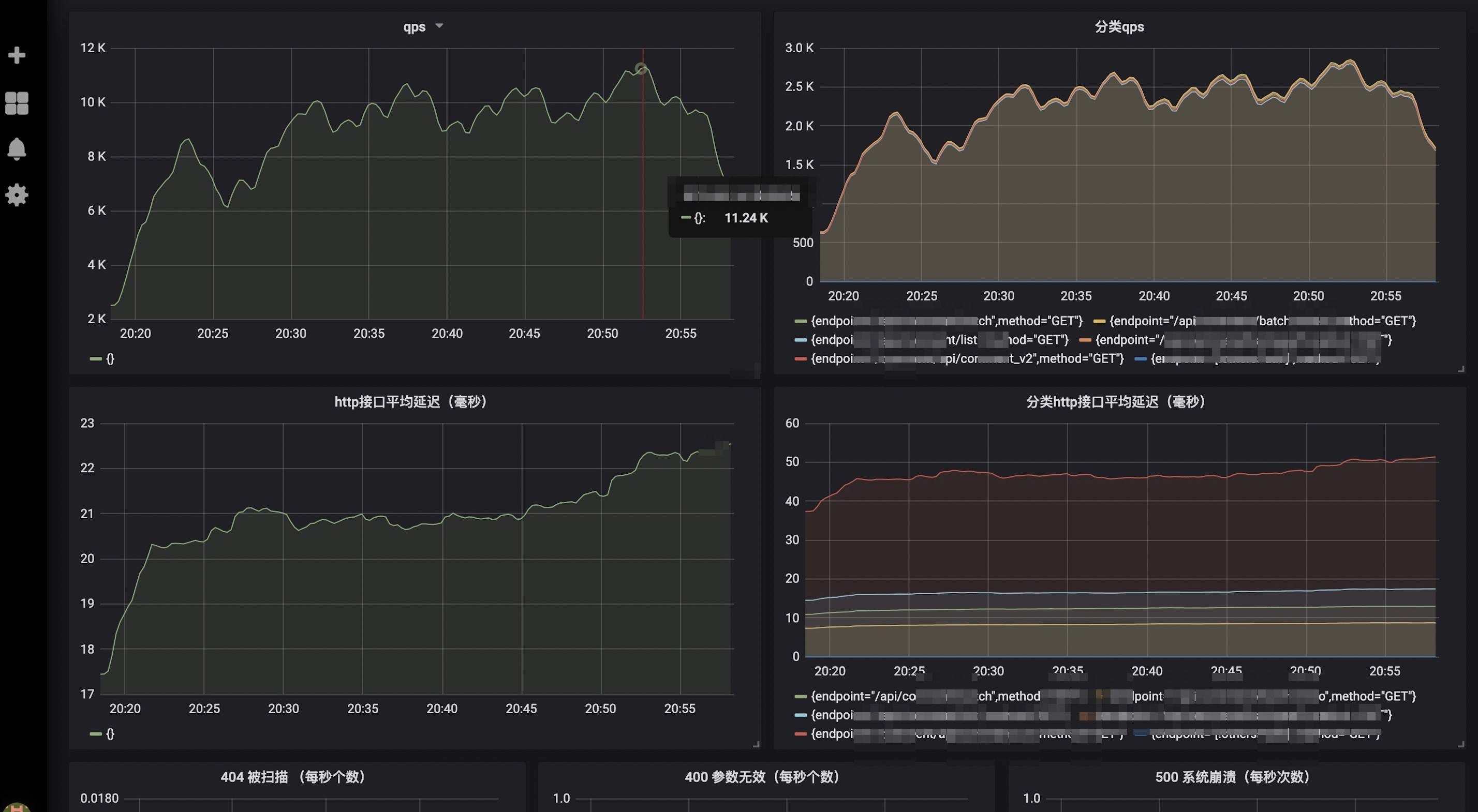
Mysql监控:精确到具体的查询函数
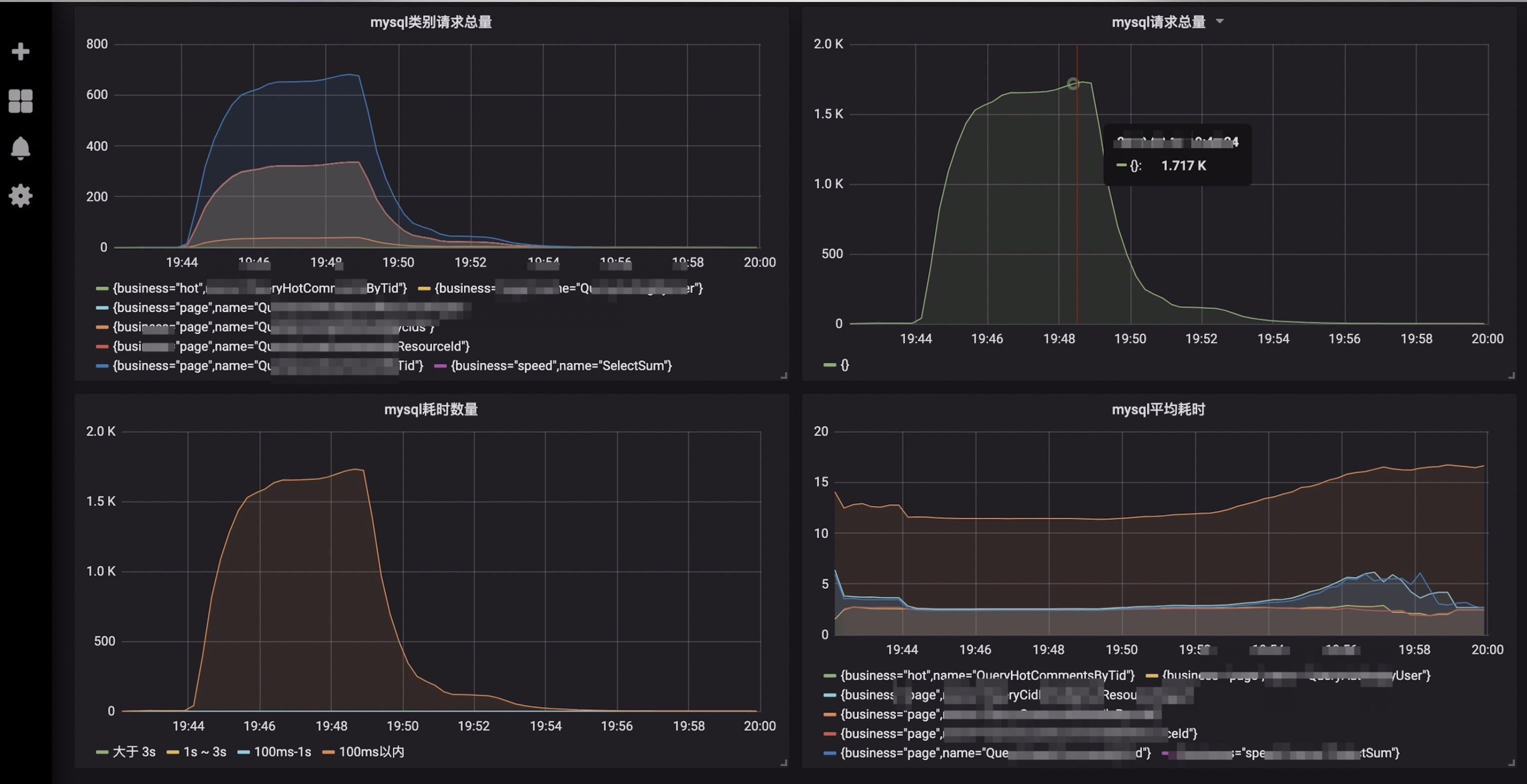
Redis监控:精确到具体的cache操作
组件简介
首先我们一起来简单了解下今天需要用到的这几个工具。
InfluxDB
一个开源的时序数据库,使用GO语言开发,特别适合用于处理和分析资源监控数据这种时序相关数据。
cAdvisor
Google用来监测单节点的资源信息的监控工具。Kubernetes中也缺省地将其作为单节点的资源监控工具,各个节点缺省会被安装上Cadvisor。
Grafana
一款可视化度量分析和可视化套件,常用于可视化基础设施和应用程序分析,与Kibana类似,UI更加灵活,且插件丰富。
Jmeter
Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。
镜像安装+启动
虽然直接部署、配置grafana、InfluxDB并不复杂,但是使用docker部署会有更好的环境可移植性,也更简单,所以选择使用docker进行部署。
如果我们确定自己想要的镜像版本,可以直接指定版本执行docker run来运行,从而忽略掉拉取镜像的过程,本文就是使用的这种方法。
但是有一点需要注意,如果没有指定镜像版本直接运行docker run,docker主进程首先会在本地查找,如未发现合适的镜像,会直接到远程镜像仓库(可以指定私有仓库)拉取最新版本(tag:latest)。
安装influxDB
docker run -d \-p 8083:8083 \-p 8086:8086 \--expose 8090 \--expose 8099 \--name influxsrv \tutum/influxdb
安装cadvisor
docker run \--volume=/:/rootfs:ro \--volume=/var/run:/var/run:rw \--volume=/sys:/sys:ro \--volume=/var/lib/docker/:/var/lib/docker:ro \-p 8080:8080 \--detach=true --link influxsrv:influxsrv \--name=cadvisor \google/cadvisor:latest \-storage_driver=influxdb \-storage_driver_db=cadvisor \-storage_driver_host=influxsrv:8086
安装granfana
docker run -d \-p 3000:3000 \-e INFLUXDB_HOST=localhost \-e INFLUXDB_PORT=8086 \-e INFLUXDB_NAME=cadvisor \-e INFLUXDB_USER=root -e INFLUXDB_PASS=root \--link influxsrv:influxsrv \--name grafana \
grafana/grafana
各个参数含义
| 参数 | 含义 |
|---|---|
| -d | 容器在后台运行 |
| -p | 将容器内端口映射到宿主机端口,格式为 宿主机端口:容器内端口;8083是influxdb的web管理工具端口,8086是influxdb的HTTP API端口 |
| --expose | 可以让容器接受外部传入的数据 |
| --name | 指定容器名称 |
| --link | --link [name/id]:alias, name和id是源容器的name和id,alias是源容器在link下的别名;在--link标签下,接收容器就是通过设置环境变量和更新/etc/hosts文件来获取源容器的信息,并与之建立通信和传递数据的。 |
| --volume | 把一个本地主机的目录当做数据卷挂载在容器上,[host-dir]:[container-dir]:[rw/ro],挂载点可以让多个容器共享。 |
- storage| storage_driver/指定数据库类型、storage_driver_db/指定数据库实例、storage_driver_host/指定数据库host
镜像名称后面加冒号接tag,能指定docker版本,安装完成之后执行docker ps会看到下面的信息
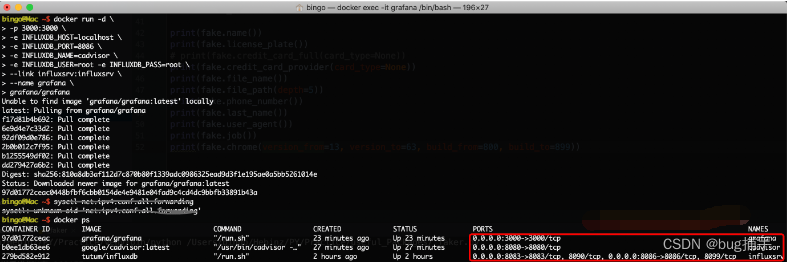
也可以执行docker exec -it container-id /bin/bash进入容器内部查看信息,比如我们拉取的grafana镜像的grafana版本是5.3.4。

influxdb配置
登录influxdb
我们在上面执行了docker run之后,其实服务就已经起来了,所以现在可以直接使用8083这个已经映射好的influxdb的web管理端口进行influxd的配置管理。
直接访问http://host-ip:8083/进入配置管理界面。点击配置管理界面右上角的 配置按钮图标 进入配置配置管理后台,使用root/root登录。

创建cAdvisor应用数据库
在上图中我们可以看到influxdb提供了一些查询/操作数据的语句模版,这对我们这些不太熟悉它的人写SQL非常有帮助。
比如我们选择模板CREATE DATABASE,在输入框会出现CREATE DATABASE "db_name",把db_name 替换成我们的数据源cadvisor,回车,我们的数据库就创建完成了。接下来我们继续执行下面的SQL来完成用户的创建和授权:
CREATE USER "cadvisor" WITH PASSWORD 'cadvisor'
grant all privileges on "cadvisor" to "cadvisor"
执行成功会有 Success! (no results to display) 的提示。
执行docker run 的命令的时候会生成的一串数字
查看cAdvisor信息
其实在上面我们执行docker run安装cAdvisor的时候,cAdvisor就已经完成了,我们访问http://host-ip:8080/containers/能看到下面的信息

granfana配置
我们在前面已经完成了grafana的部署启动,访问http://host-ip:3000使用admin/admin即可登录配置管理后台,如果不想修改密码可以选择跳过。

配置Granfana数据源
选择数据库类型为influxdb,host为http://influxsrv:8086,填写cadvisor的账户密码:

保存之后,点击保存并测试:

添加Dashboard
点击左侧的 + 号,选择Dashboard,选择graph
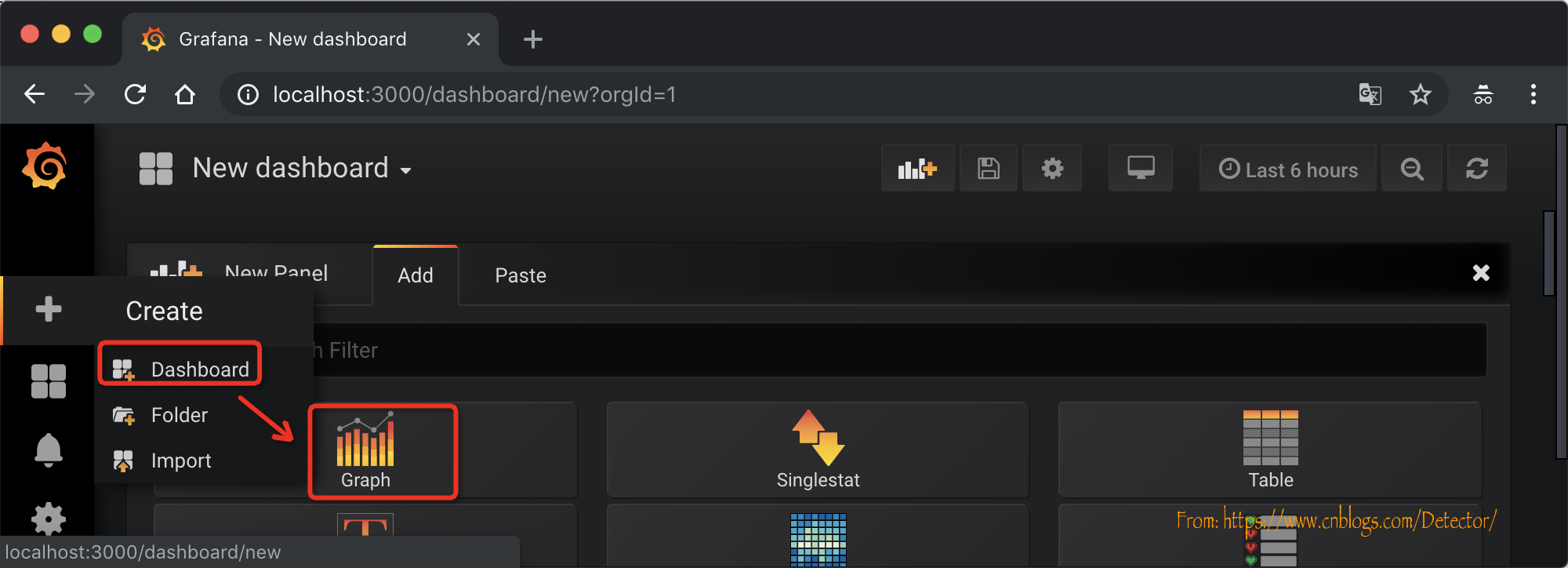
进入心界面后,选择title,选择编辑
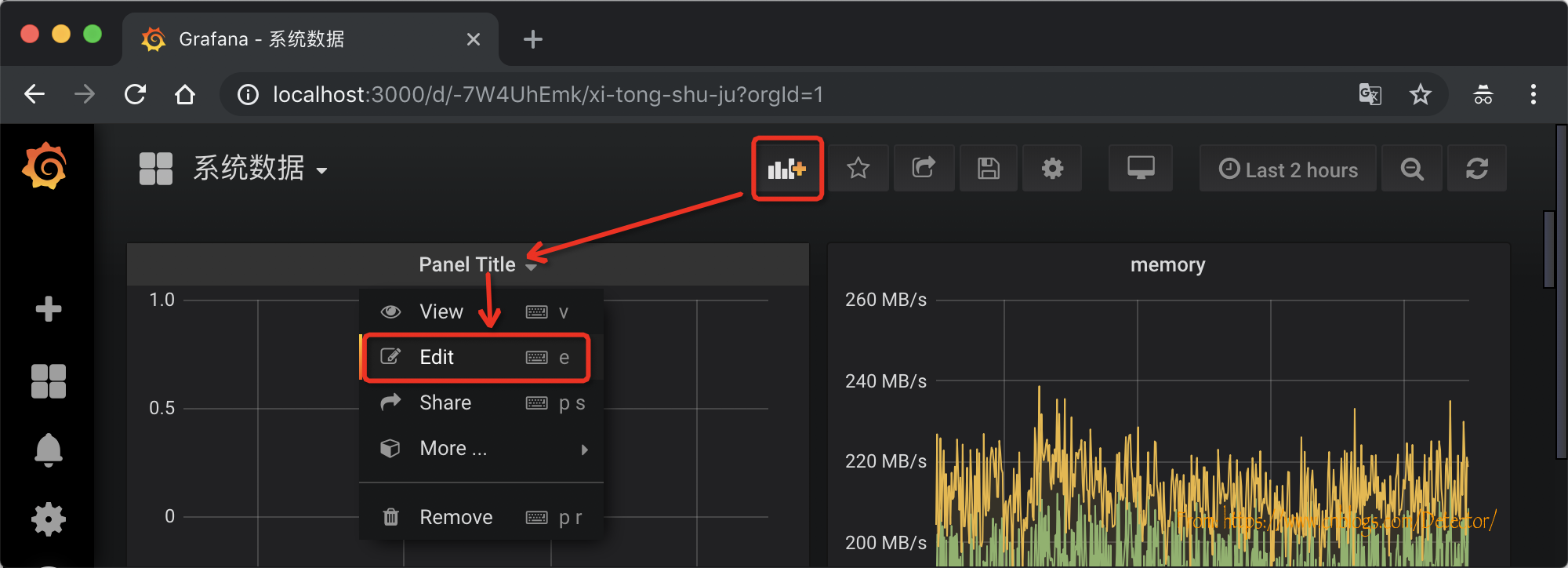
在展示数据配置界面选择一个数据源,比如内存,点击保存,即可完成该数据的动态展示:

在配置界面Axes选项卡中配置相关的显示单位。可以根据实际的情况选择监控的单位。,因为我们监控的内存,所以选择的是相关的单位。
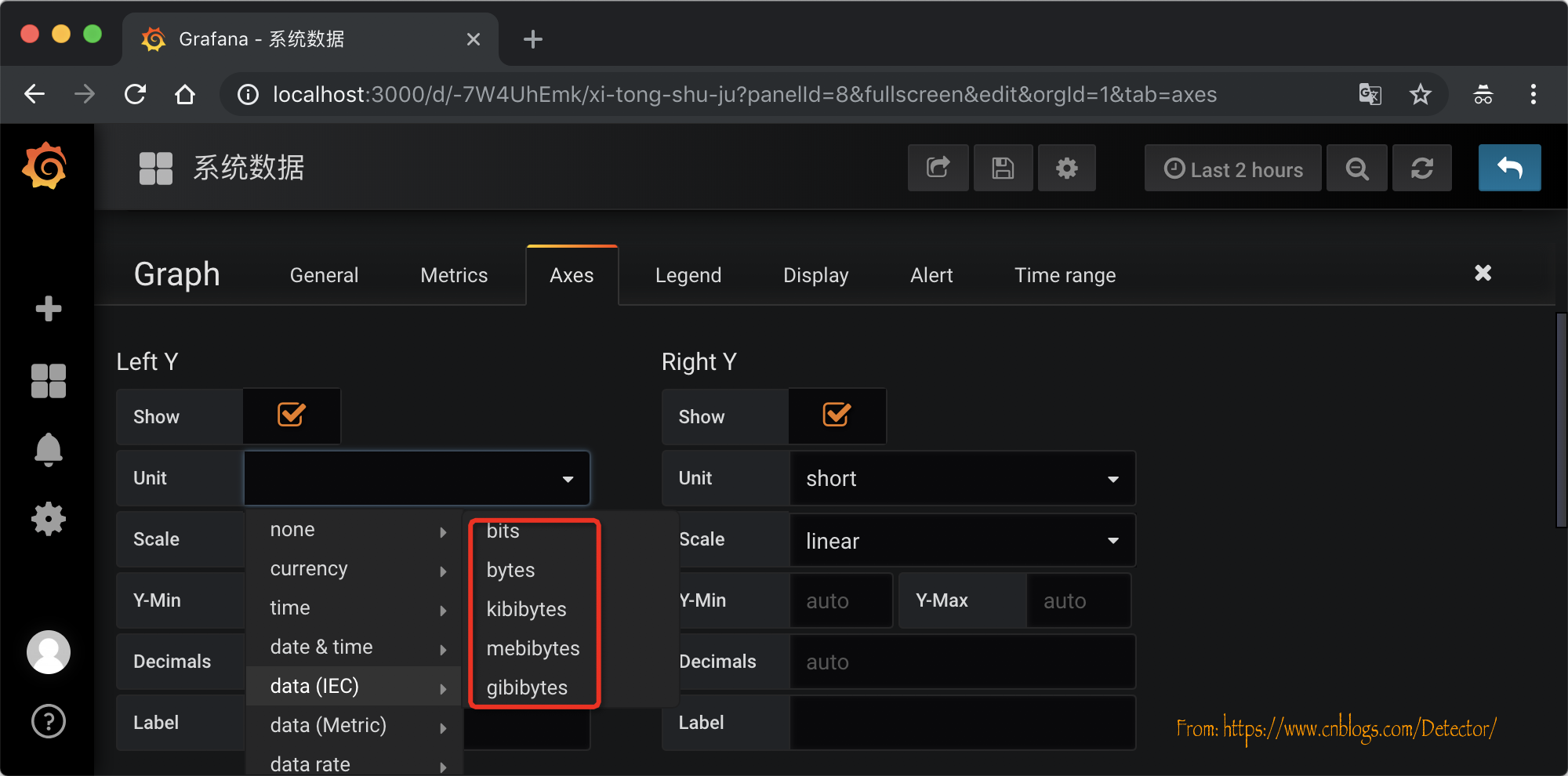
至此, 所有配置步骤完成,简单配置了两个图像:

配置Jmeter监控
是不是很奇怪怎么说了那么久还是没有说到怎么配置Jmeter的监控?其实做完前面的事情,我们的测试环境就已经搭建完了,在接入数据库之前我们可以使用前面的方法在influxdb建一张叫Jmeter的表,然后在启动测试之前选择添加一个后端监听器,并选择为 influxdb ,数据库连接配置修改为我们搭建的真实host就可以运行测试了,数据都会写入Jmeter这张表,剩下的就是如何配置第一张图那样的花里胡哨的东西把它展示出来:

下图是我简单选择的几个维度生成的监控图像,红框标出的是可以选择的各种指标,还有一部分没有罗列出来,可以根据实际情况进行选择:

总结
前面介绍的都是压力机的配置,实际上性能测试还需要搭建性能测试环境、进行代码埋点等。
代码埋点我们是通过写一些公共的类库,比如在操作redis、DB的方法的封装中添加;
压测环境部署我们使用的是helm(基于k8s)封装chart文件夹的方式完成的,可以快速的集成,再结合Jenkins快速的完成性能自动化的持续集成。
资料获取方法
【留言777】


各位想获取源码等教程资料的朋友请点赞 + 评论 + 收藏,三连!
三连之后我会在评论区挨个私信发给你们~