文章目录
- 前言
- RetinaNet 算法原理
- 1.RetinaNet 简介
- 2.backbone 部分
- 3.FPN特征金字塔
- 4.分类和预测
- 5.Focal Loss
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
提示:这里可以添加本文要记录的大概内容:
在RetinaNet之前,目标检测领域普遍认为one-stage算法,如YOLO系列和SSD,在准确性上不及two-stage算法,如Faster R-CNN。这种差异主要源于以下两个原因:
- two-stage算法的流程包括使用
RPN(Region Proposal Network)生成一系列的建议框,随后在这些建议框的基础上利用Fast R-CNN进行精细化调整,这一双阶段的设计使得结果更为精确。样本不平衡问题在one-stage算法中尤为突出。在Faster R-CNN中,正负样本的比例被明确设定为1:3,而one-stage算法中的正负样本比可能极端失衡,有时甚至达到1:1000。这种不平衡导致在训练过程中,梯度主要被简单样本所驱动,而复杂样本因为占比小,在损失函数的计算中被大量简单样本的影响所淹没。
RetinaNet的提出,在一定程度上解决了这一问题,它使得one-stage算法也能达到与two-stage算法相媲美的准确性。RetinaNet 原始论文为发表于 2017 ICCV 的 Focal Loss for Dense Object Detection。one-stage 网络首次超越 two-stage 网络,拿下了 best student paper,仅管其在网络结构部分并没有颠覆性贡献。
论文地址:https://arxiv.org/pdf/1708.02002.pdf
RetinaNet 算法原理
1.RetinaNet 简介
单阶段目标检测经过不断发展,虽然在检测速度上能够满足实时性的要求,但在精度上与 R-CNN 系列为代表的两阶段目标检测仍有着一定的差距。一个主要原因是正负样本数量的不均衡,对训练过程产生负面影响, He 等人提出基于Focal Loss的RetinaNet 模型,来改善样本间的不均衡性,以达到两阶段检测方法同等的精度。
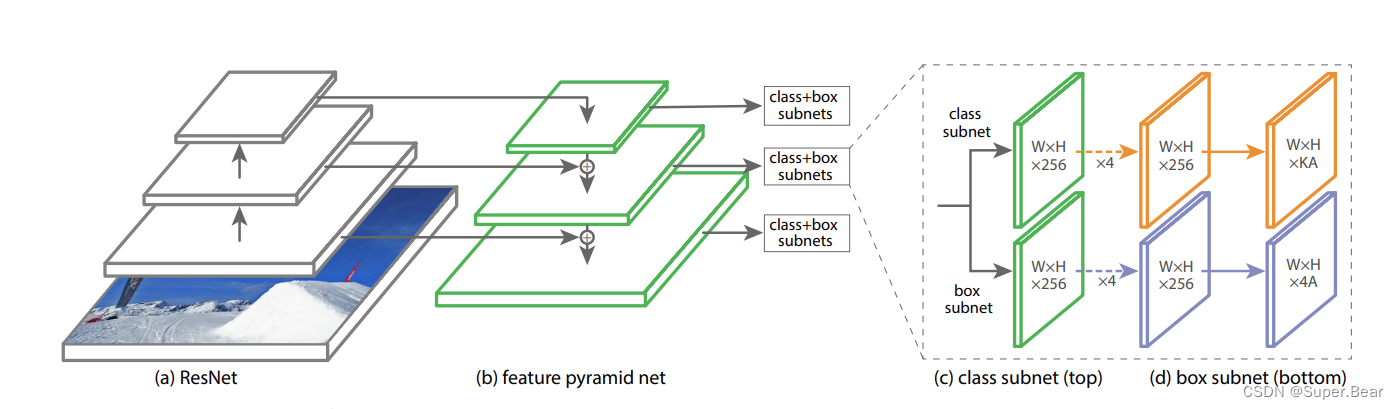
如上图所示,RetinaNet 网络主要由ResNet主干网络、FPN特征金字塔、分类子网络和边框回归子网络组成。其中,主干网络由 ResNet 与 FPN 共同构成,以实现对目标的特征提取。分类子网络与边框回归子网络分别负责对== FPN 输出的特征图进行目标分类与位置回归==。在锚点的设计上,为了使锚框与目标边框的重合度更高, RetinaNet 设置了三种长宽比为 1:2、 1:1、 2:1,尺寸为 2 0 、 2 1 / 3 、 2 2 / 3 2^0、2^{1/3}、2^{2/3} 20、21/3、22/3 的锚框,并使锚框的大小跟随特征层的增加而增加,使之能够匹配不同特征层上大小尺度不同的目标。
2.backbone 部分
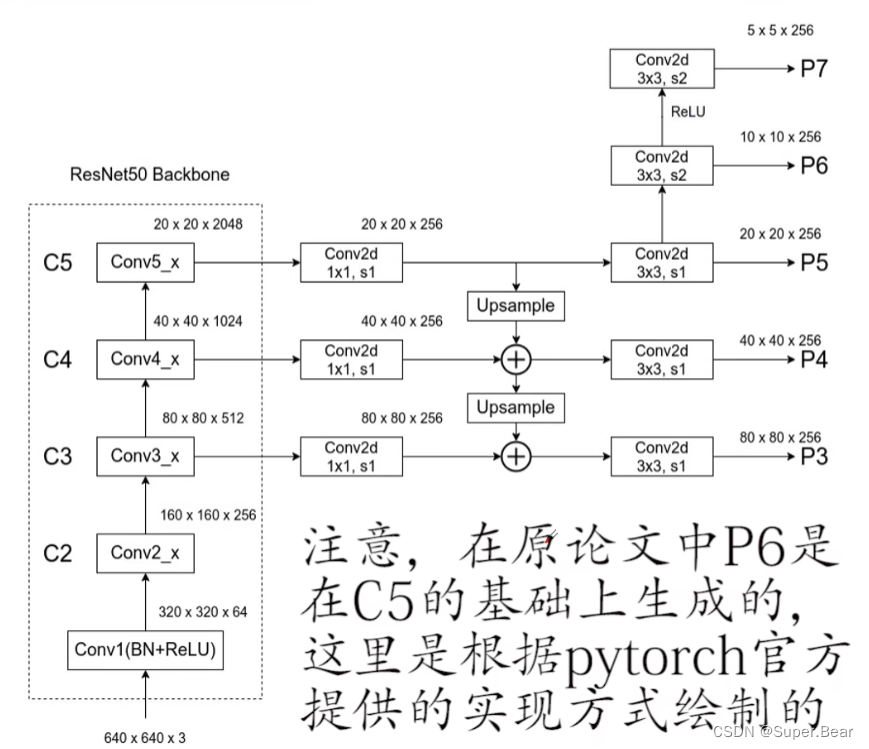
RetinaNet的网络结构如图所示,与FPN网络相比,FPN在构建过程中融合了C2层的特征,而RetinaNet则跳过了C2层。这一省略是出于对计算资源的有效利用考虑,因为C2层产生的P2特征图会显著增加计算的复杂度。因此,RetinaNet的设计者选择了从C3层直接开始生成P3特征图。
RetinaNet的backbone部分与FPN在结构上相似,在P6特征图的生成上,RetinaNet的实现与原始论文描述的不同。原论文建议通过最大池化操作来下采样C5层的特征图以获得P6,而在实际的pytorch实现中,采用了一种更为高效的方法——通过一个3×3的卷积层来进行下采样。RetinaNet与FPN在特征图的尺度上也有所不同。FPN构建了一个从P2到P6的特征金字塔,而RetinaNet则构建了一个从P3到P7的特征金字塔。
3.FPN特征金字塔
深度神经网络学习到的特征中,浅层特征学到的是物理信息,如物体的角点、边缘的细节信息,而深层特征学到的是语义信息,更加high-level和抽象化。对于分类任务来说,深层网络学到的特征可能更为重要,而对于定位任务来说,深层次和浅层次的特征同样重要,因为要想精准的定位,浅层的物理细节信息是必不可少的。
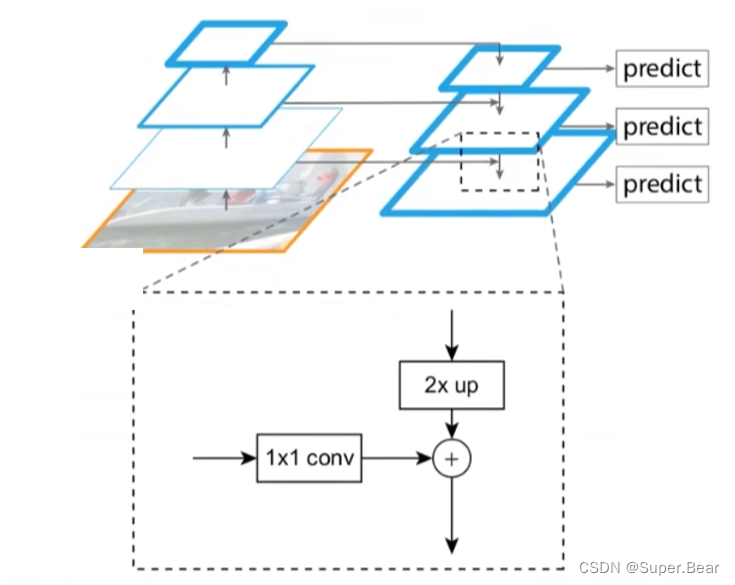
FPN之前的目标检测算法,多数只采用顶层特征来做预测,所含的细节信息比较粗略,即使采用了特征融合的方法,也一般是采用融合后的特征进行预测的。FPN提出了特征金字塔网络,可以在不同的特征层上独立进行预测。FPN 通过自下向上、自上向下以及横向连接,可以融合不同层的特征图,得到更加丰富的信息,如上图所示。
-
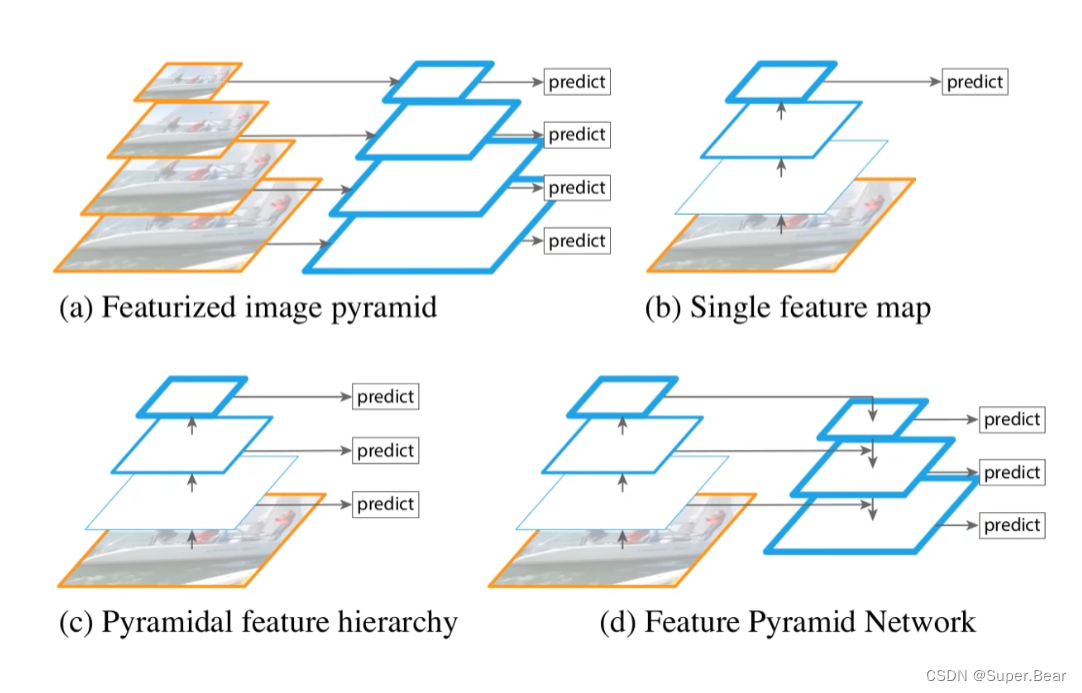
图(a)
先对原始图像构造图像金字塔,然后对图像金字塔的每一层提取不同的特征并进行相应的预测。优点:精度不错;缺点:计算量大,占用内存大。 -
图(b)
通过对原始图像进行卷积和池化操作来获得不同尺寸的特征图,在图像的特征空间中构造出金字塔。因为浅层的网络更关注于细节信息,高层的网络更关注于语义信息,更有利于准确检测出目标,因此利用最后一个卷积层上的feature map来进行预测分类。优点:速度快、内存少。缺点:仅关注深层网络中最后一层的特征,却忽略了其它层的特征。 -
图(c )
在图(b)的基础之上,同时利用低层特征和高层特征,首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。优点:在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不用进行多余的前向操作),速度更快,又提高了算法的检测性能。缺点:获得的特征不鲁棒,都是一些弱特征(因为很多的特征都是从较浅的层获得的)。 -
图(d)
FPN(Feature Pyramid Network)即特征金字塔:自下而上,自上而下,横向连接和卷积融合。
(1)自下而上:即神经网络的前向传播过程,特征图经过卷积核计算,通常会越变越小。对于ResNet,使用每个阶段的最后一个residual block输出的特征激活输出。对于conv2,conv3,conv4和conv5输出,将这些最后residual block的输出表示为{C2,C3,C4,C5},如下图所示,并且它们相对于输入图像具有{4, 8, 16, 32} 的步长。由于其庞大的内存占用,不会将conv1纳入金字塔中。
(2)自上而下:把更抽象、语义更强的高层特征图进行上采样(upsampling),而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。横向连接的两层特征在空间尺寸相同,这样做可以利用底层定位细节信息。将低分辨率的特征图做2倍上采样(为了简单起见,使用最近邻上采样)。然后通过按元素相加,将上采样映射与相应的自底而上映射合并。这个过程是迭代的,直到生成最终的分辨率图。 为了开始迭代,只需在C5上附加一个1×1卷积层来生成低分辨率图P5。最后,在每个合并的图上附加一个3×3卷积来生成最终的特征映射,这是为了减少上采样的混叠效应。这个最终的特征映射集称为{P2,P3,P4,P5},分别对应于{C2,C3,C4,C5},它们具有相同的尺寸。 由于金字塔的所有层次都像传统的特征化图像金字塔一样使用共享分类器/回归器,因此在所有特征图中固定特征维度(通道数,记为d),文中设置d = 256,因此所有额外的卷积层都有256个通道的输出。
(3)横向连接:采用1×1的卷积核进行连接(减少特征图数量)。
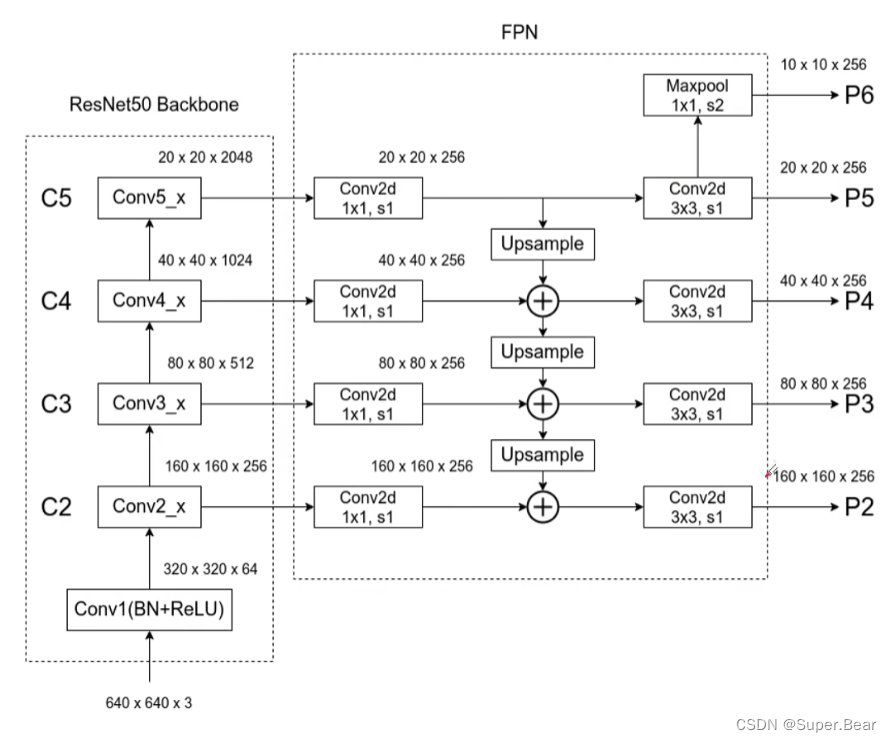
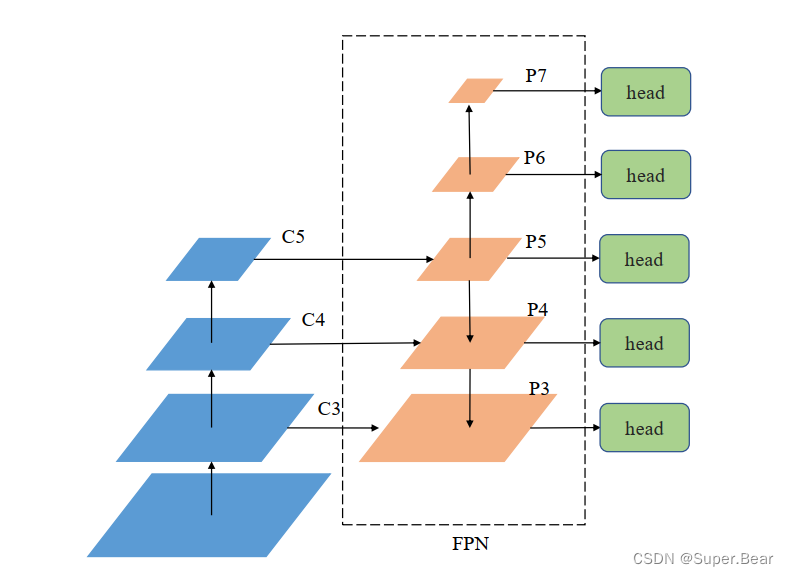
在RetinaNet网络中,输入特征经ResNet50骨干网络特征提取后,送入FPN特征金字塔中进行特征融合,以得到目标的多尺度信信息,丰富特征语义。 RetinaNet 中的特征金字塔对 FPN 部分改进,FPN 接收 C3、 C4、 C5 特征图,输出 P3-P7 五个特征图,其中 P5 上采样和 P4 进行融合, P4 上采样与 P3 进行融合, P6 和 P7 为 P5 下采样得到,目的是增大感受野,获得图片的全局信息,具体结构如下图所示。
4.分类和预测
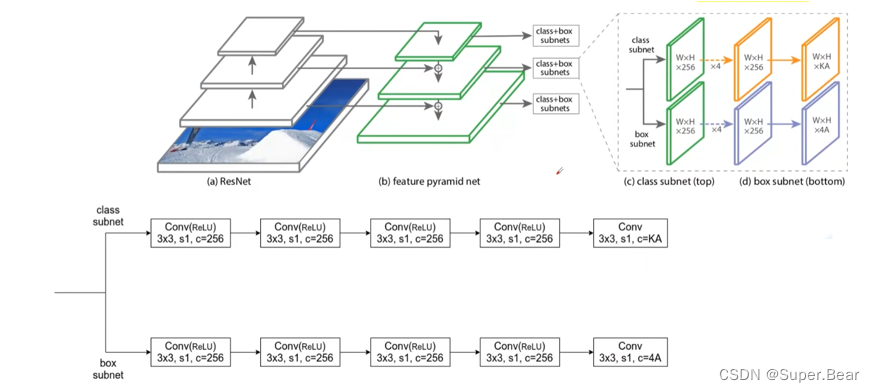
融合后的特征层送入分类子网络(Class Subnet)和边界框子网络(Box Subnet)中,分类子网络中先进行 4 次卷积核为 256 的 3×3 的卷积操作,并且在每次卷积后都使用一次 Relu 激活函数,再进行一次卷积核为K×A的3×3 卷积操作,其中== K 为目标的类别数==,== A 为锚框的数量==,最后使用 Softmax 函数得到每个锚框的置信度,训练时候选择达到置信度阈值的锚框使用Focal Loss计算分类损失,并对网络进行学习优化,分类子网络和边界框框子网络之间不共享参数,但对特征层之间实现参数共享。
5.Focal Loss
基于回归的目标检测算法由于没有候选区域生成这一步骤,因此在使用锚点对目标进行预测时,会出现正负样本不平衡和难易样本不平衡问题,这将使简单负样本占据网络模型训练中的大部分损失值,导致网络模型的优化效果不佳,影响网络模型对难样本的训练,进而使得网络模型对目标的检测效果不好。
重点标记性文字设置
具体的标记性正文
具体的标记性正文
具体的标记性正文
具体的标记性正文
具体的标记性正文
具体的标记性正文
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。