文章目录
- 一、聚合函数
- 1.1 count 返回查询到的数据的数量
- 1.2 sum 返回查询到的数据的总和
- 1.3 avg 返回查询到的数据的平均值
- 1.4 max 返回查询到的数据的最大值
- 1.5 min 返回查询到的数据的最小值
- 二、分组查询group by
- 2.1 导入雇员信息表
- 2.2 找到最高薪资和员工平均薪资
- 2.3 显示每个部门的平均工资和最高工资
- 2.4 显示每个部门不同岗位的平均工资和最低工资
- 2.5 显示平均工资低于2000的部门和它的平均工资
一、聚合函数
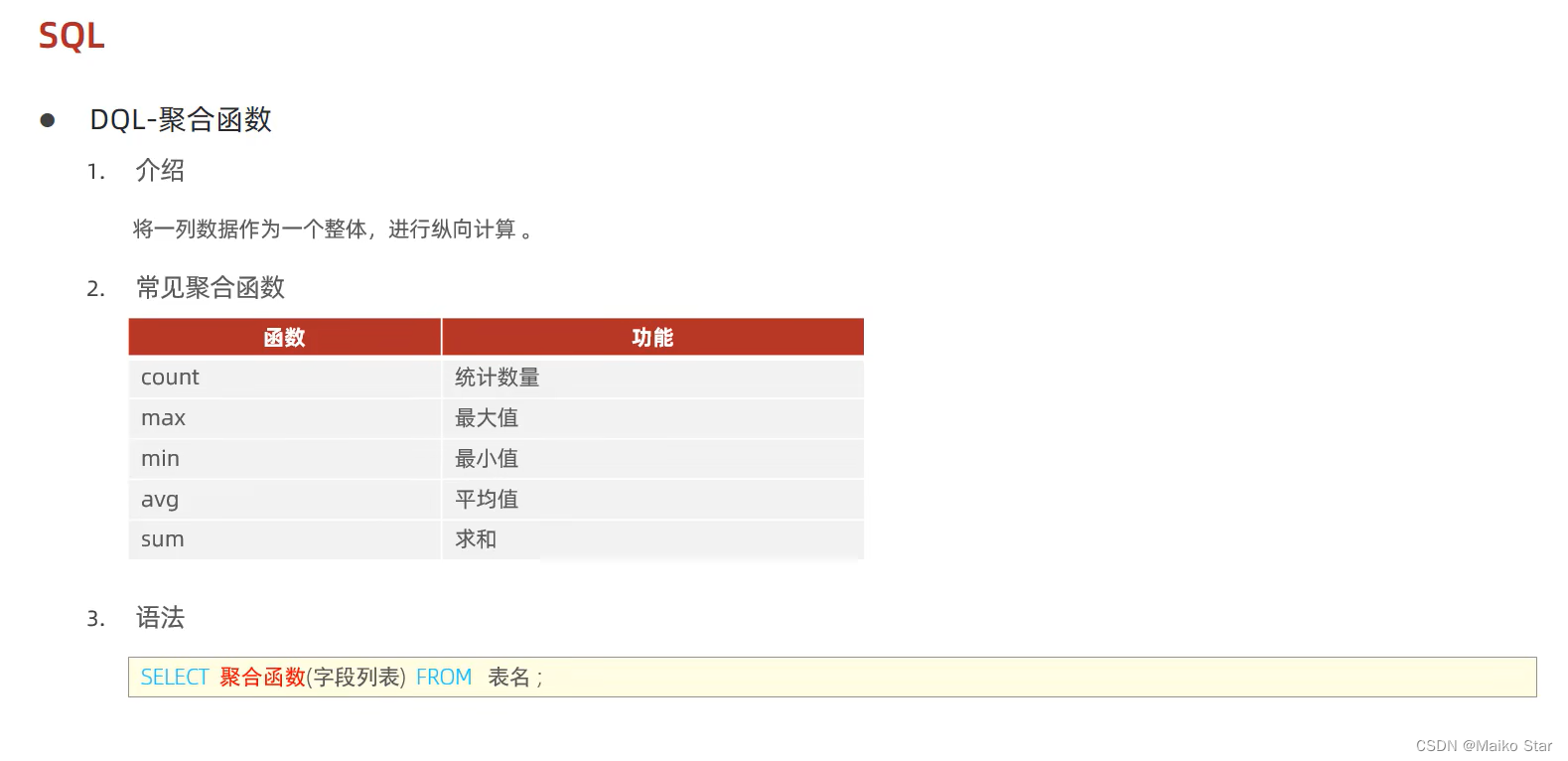
MySQL中的聚合函数用于对数据进行计算和统计,常见的聚合函数包括下面列举出来的聚合函数:
函数 说明
COUNT([DISTINCT] expr) 返回查询到的数据的数量
SUM([DISTINCT] expr) 返回查询到的数据的总和,不是数字没有意义
AVG([DISTINCT] expr) 返回查询到的数据的平均值,不是数字没有意义
MAX([DISTINCT] expr) 返回查询到的数据的最大值,不是数字没有意义
MIN([DISTINCT] expr) 返回查询到的数据的最小值,不是数字没有意义
1.1 count 返回查询到的数据的数量
- 查看班级有多少同学
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 张三 | 134 | 98 | 56 |
| 2 | 李四 | 120 | 80 | 77 |
| 4 | 赵六 | 164 | 84 | 67 |
| 5 | 田七 | 110 | 115 | 45 |
| 6 | 孙八 | 140 | 84 | 78 |
| 8 | 张翼德 | 90 | 128 | 66 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)mysql> select count(*) 总数 from exam_result;
+--------+
| 总数 |
+--------+
| 6 |
+--------+
1 row in set (0.00 sec)mysql> select count(1) 总数 from exam_result;
+--------+
| 总数 |
+--------+
| 6 |
+--------+
1 row in set (0.00 sec)
- 统计数学成绩有多少个
# 统计全部
mysql> select count(math) from exam_result;
+-------------+
| count(math) |
+-------------+
| 6 |
+-------------+
1 row in set (0.00 sec)# 统计有效的(去重)
mysql> select count(distinct math) as res from exam_result;
+-----+
| res |
+-----+
| 5 |
+-----+
1 row in set (0.00 sec)
- 统计英语不及格的人数
mysql> select count(*) from exam_result where english<60;
+----------+
| count(*) |
+----------+
| 2 |
+----------+
1 row in set (0.00 sec)
1.2 sum 返回查询到的数据的总和
- 查看数学成绩的总和
mysql> select sum(math) from exam_result;
+-----------+
| sum(math) |
+-----------+
| 589 |
+-----------+
1 row in set (0.00 sec)
- 统计英语不及格的分数总和
mysql> select sum(english) from exam_result where english<60;
+--------------+
| sum(english) |
+--------------+
| 101 |
+--------------+
1 row in set (0.00 sec)# 也可以统计不及格的平均分
mysql> select sum(english)/count(english) from exam_result where english<60;
+-----------------------------+
| sum(english)/count(english) |
+-----------------------------+
| 50.5 |
+-----------------------------+
1 row in set (0.00 sec)
1.3 avg 返回查询到的数据的平均值
统计不及格的英语的平均分不需要上面那么麻烦自己手动除:
mysql> select avg(english) from exam_result where english<60;
+--------------+
| avg(english) |
+--------------+
| 50.5 |
+--------------+
1 row in set (0.01 sec)
- 统计总分的平均分
mysql> select avg(chinese+math+english) from exam_result;
+---------------------------+
| avg(chinese+math+english) |
+---------------------------+
| 289.3333333333333 |
+---------------------------+
1 row in set (0.00 sec)
1.4 max 返回查询到的数据的最大值
- 查询数学成绩的最大值
mysql> select max(math) from exam_result;
+-----------+
| max(math) |
+-----------+
| 128 |
+-----------+
1 row in set (0.00 sec)
这里要注意聚合必须分组,不能这么使用:
mysql> select name, max(math) from exam_result;
1.5 min 返回查询到的数据的最小值
# 查看数学成绩的最小值
mysql> select min(math) from exam_result;
+-----------+
| min(math) |
+-----------+
| 80 |
+-----------+
1 row in set (0.00 sec)# 查看数学成绩大于100的最小值
mysql> select min(math) from exam_result where math>100;
+-----------+
| min(math) |
+-----------+
| 115 |
+-----------+
1 row in set (0.00 sec)
二、分组查询group by
分组的目的是为了进行分组之后,方便进行聚合统计
在select中使用group by 子句可以对指定列进行分组查询
语法:
select column1, column2, .. from table group by column;
2.1 导入雇员信息表
# 将linux目录下的sql表导入MySQL
mysql> source /home/yyh/scott_data.sql
Query OK, 0 rows affected, 1 warning (0.00 sec)mysql> use scott;
Database changedmysql> show tables;
+-----------------+
| Tables_in_scott |
+-----------------+
| dept |
| emp |
| salgrade |
+-----------------+
3 rows in set (0.00 sec)
emp员工表
dept部门表
salgrade工资等级表
2.2 找到最高薪资和员工平均薪资
# 查看员工表
mysql> select * from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.00 sec)# 聚合函数
mysql> select max(sal) 最高, avg(sal) 平均 from emp;
+---------+-------------+
| 最高 | 平均 |
+---------+-------------+
| 5000.00 | 2073.214286 |
+---------+-------------+
1 row in set (0.00 sec)
2.3 显示每个部门的平均工资和最高工资
这里就需要进行分组。
# 通过列分组
group by 列名
# 用该列的不同数据进行分组
mysql> select deptno,max(sal) 最高, avg(sal) 平均 from emp group by deptno;
+--------+---------+-------------+
| deptno | 最高 | 平均 |
+--------+---------+-------------+
| 10 | 5000.00 | 2916.666667 |
| 20 | 3000.00 | 2175.000000 |
| 30 | 2850.00 | 1566.666667 |
+--------+---------+-------------+
3 rows in set (0.00 sec)
这里分组条件用的是deptno,所以每个组内的deptno一定是相同的。
分组就是把一张表按照条件在逻辑上拆成了多个子表,然后分别对每个子表进行聚合统计。
2.4 显示每个部门不同岗位的平均工资和最低工资
这里既然要每个部门和不同岗位,那么就注定要分组。
先分组再聚合
group by deptno, job;
mysql> select deptno,job,max(sal) 最高,avg(sal) 平均 from emp group by deptno,job;
+--------+-----------+---------+-------------+
| deptno | job | 最高 | 平均 |
+--------+-----------+---------+-------------+
| 10 | CLERK | 1300.00 | 1300.000000 |
| 10 | MANAGER | 2450.00 | 2450.000000 |
| 10 | PRESIDENT | 5000.00 | 5000.000000 |
| 20 | ANALYST | 3000.00 | 3000.000000 |
| 20 | CLERK | 1100.00 | 950.000000 |
| 20 | MANAGER | 2975.00 | 2975.000000 |
| 30 | CLERK | 950.00 | 950.000000 |
| 30 | MANAGER | 2850.00 | 2850.000000 |
| 30 | SALESMAN | 1600.00 | 1400.000000 |
+--------+-----------+---------+-------------+
9 rows in set (0.00 sec)
这里要注意一般select后边的字段必须在group by中出现
比如说select 后边加个ename就会报错,因为同一个分组可能会有不同的ename。
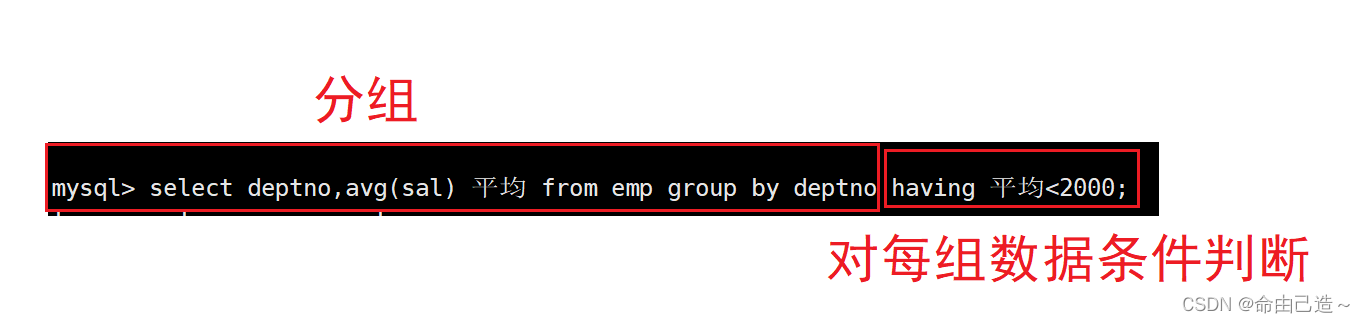
2.5 显示平均工资低于2000的部门和它的平均工资
分成两步:
先统计每一个部门的平均工资(先按部门对平均工资进行分组聚合)
再对聚合的结果进行条件判断
- 如何对聚合的结果条件判断?
通过having搭配group by
having就是对聚合后的数据统计进行条件筛选
mysql> select deptno,avg(sal) 平均 from emp group by deptno having 平均<2000;
+--------+-------------+
| deptno | 平均 |
+--------+-------------+
| 30 | 1566.666667 |
+--------+-------------+
1 row in set (0.00 sec)
- having和where区别理解,执行顺序
先来看个样例:
SMITH不参与统计,显示每个部门、每种岗位的平均工资低于2000的工种。
mysql> select deptno,job,avg(sal) 平均 from emp where ename!='SMITH' group by deptno,job having 平均<2000;
+--------+----------+-------------+
| deptno | job | 平均 |
+--------+----------+-------------+
| 10 | CLERK | 1300.000000 |
| 20 | CLERK | 1100.000000 |
| 30 | CLERK | 950.000000 |
| 30 | SALESMAN | 1400.000000 |
+--------+----------+-------------+
4 rows in set (0.00 sec)
where 是对任意列进行条件筛选(筛选之后才会进行分组)
having 是对分组聚合之后的结果进行条件筛选
执行顺序:
先要知道从哪个表中取数据(from),再看拿数据过程中的筛选条件(where),然后对拿到的数据分组(group by),在按照分组之后的结果进行聚合统计并且重命名(select),最后再对结果做条件筛选(having)