目录
一、集合框架介绍
1、集合与集合框架说明
2、使用集合框架原因
3、集合框架接口体系
二、Collection接口
1、Collection常用方法
2、AbstractCollection
三、迭代器
1、迭代器说明
2、自定义Collection集合
四、泛型
1、泛型说明
2、使用泛型方法
3、泛型通配符
4、泛型上限
5、泛型下限
五、List接口
1、特征描述
2、ArrayList学习
3、LinkedList学习
4、栈学习
六、Queue接口
1、特性描述
2、LinkedBlockingQueue
3、PriorityQueue
七、比较器接口
1、比较器作用
2、Comparable接口
3、Comparator接口
4、总结
八、Map接口
1、特性描述
2、HashMap学习
3、TreeMap学习
4、LinkedHashMap学习
九、Set接口
1、特性描述
2、HashSet学习
3、TreeSet学习
4、LinkedHashSet学习
一、集合框架介绍
1、集合与集合框架说明
集合(有时称为容器)只是一个将多个元素分组为一个单元的对象,集合用于存储、检索、操作和传达聚合数据。
集合框架是用于表示和操作集合的统一体系结构。
2、使用集合框架原因
使用数组对元素进行增删改查时,需要我们自己编码实现。而集合是Java平台提供的,也能进行增删改查,已经有了具体的实现。我们不需要再去实现,直接使用Java平台提供的集合即可, 这无疑减少了编程的工作量。同时java平台提供的集合无论是在数据结构还是算法设计上都具有更优的性能。
3、集合框架接口体系
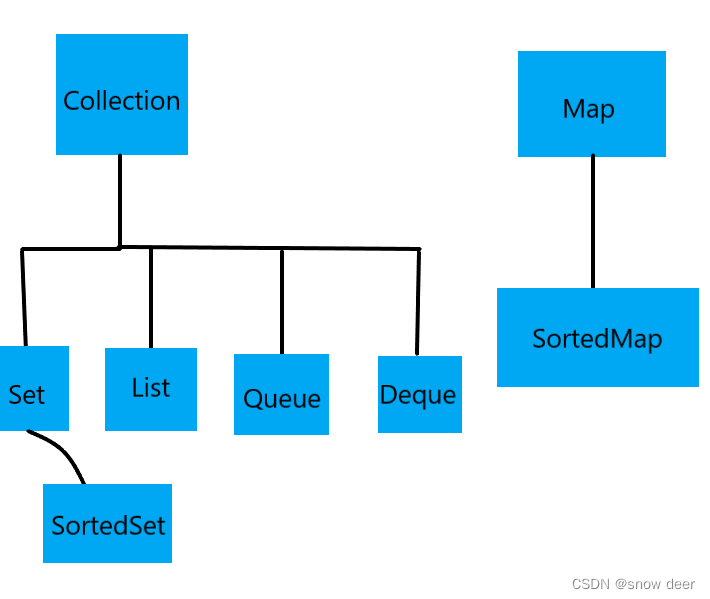
集合接口体系中有两个顶层接口Collection和Map,Collection接口属于单列接口(可以理解为一次存储一个元素),Map接口属于双列接口(可以理解为一次存入两个相关联的元素)。
二、Collection接口
1、Collection常用方法
int size(); //获取集合的大小
boolean isEmpty();//判断集合是否存有元素
boolean contains(object o);//判断集合中是否包含给定的元素
Iterator<E> iterator();//获取集合的迭代器
object[ ] toArray();//将集合转换为数组
<T> T[ ] toArray(T[ ] a);//将集合转换为给定类型的数组并将该数组返回
boolean add(E e);//向集合中添加元素
boolean remove(object o);//从集合中移除给定的元素
void clear();//清除集合中的元素
boolean containsAll(Collection<?> c);//判断集合中是否包含给定的集合
boolean addAll(Collection<? extends E> c) ;//将给定的集合添加到集合中
2、AbstractCollection
AbstractCollection实现了Collection接口,属于单列集合的顶层抽象类。
源码解读
AbstractCocllection抽象类中没有实现的方法:
Iterator <E> iterator(); //获取集合的迭代器
int size; //获取集合的大小
boolean add(E e); //向集合中添加元素
由此可以看出AbstractCocllection并没有存储元素的容器,因此所有核心方法都没有实现。
三、迭代器
1、迭代器说明
集合是用来存储元素的,存储元素的目的是为了对元素进行操作,最常用的操作就是检索元素。为了满足这种需要,JDK提供了一个Iterable接口(表示可迭代的),供所有单列集合来实现。
public interface collection<E> extends Iterable<E>
可以看出,collection接口是 Iterable接口的子接口,表示所有的单列集合都是可迭代的。Iterable接口中有一 个约定:
Iterator<T> iterator();//获取集合的迭代器
因此所有单列集合必须提供一个迭代元素的迭代器。而迭代器Iterator也是一个接口。其中约定如下:
boolean hasNext();//判断迭代器中是否有下一个元素
E next();//获取迭代器中的下一个元素
default void remove();//将元素从选代器中移除,默认是空实现
场景举例认识迭代器:一位顾客在超市买了许多商品, 当他提着购物篮去结算时, 收银员并没有数商品有多少件,只需要看购物篮中还有没有下一个商品,有就取出来结算,直到购物篮中没有商品为止。收银员的操作就是一个迭代过程,购物篮就相当于一个选代器。
2、自定义Collection集合
例子
package testdo;import java.util.AbstractCollection;
import java.util.Arrays;
import java.util.Iterator;public class MyCollection extends AbstractCollection {private Object[] elemates;private int size;public MyCollection(){this(16);}public MyCollection(int capacity){elemates=new Object[capacity];}@Overridepublic boolean add(Object o) {//数组中存储满了,数组需要扩容才能存储新的元素if(size==elemates.length){//4 >> 1 0100 >> 1 => 010 =2int length=elemates.length+elemates.length>>1;elemates= Arrays.copyOf(elemates, length);}elemates[size++]=o;return true;}@Overridepublic Iterator iterator() {return new CollectionIterator();}@Overridepublic int size() {return size;}class CollectionIterator implements Iterator{//内部类使用private int cursor;// 光标,实际指下标@Overridepublic boolean hasNext() {return cursor<size;}@Overridepublic Object next() {if(cursor>=size||cursor<0){throw new ArrayIndexOutOfBoundsException("下标越界了");}return elemates[cursor++];}@Overridepublic void remove() {//在定义的代码中,先调用next(),再调用remove()if(cursor>=size||cursor<0){throw new ArrayIndexOutOfBoundsException("下标越界了");}System.arraycopy(elemates,cursor,elemates,cursor-1,size-cursor);if(cursor==size) cursor--; //表示移除的是最后一个元素,光标就会向前移动一位size--;//存储个数减去1}}
}package testdo;import java.util.Iterator;public class MyCollectionTest {public static void main(String[] args) {MyCollection collection=new MyCollection();collection.add("a");collection.add("b");collection.add("c");collection.add("d");collection.add("e");collection.add("f");System.out.println("集合大小:"+collection.size());//遍历方式1Iterator iterator=collection.iterator();while (iterator.hasNext()){String s=(String) iterator.next();System.out.println(s);}System.out.println("==============================");collection.remove("c");System.out.println("集合大小:"+collection.size());//遍历方式2for(Object o:collection){System.out.println(o);}boolean exists=collection.contains("c");System.out.println(exists);MyCollection c=new MyCollection();c.add(5);c.add(4);c.add(3);c.add(2);c.add(1);//遍历方式3for (Iterator iter=c.iterator();iter.hasNext();){Integer i= (Integer) iter.next();System.out.println(i);}}
}
注:上面的集合中,存储的都是字符串,在使用迭代器遍历元素时,将元素强制转换为字符串,这时程序能够正常运行,当集合中存储多种数据类型时,强制类型转换将出现异常。
四、泛型
1、泛型说明
简言之,泛型在定义类、接口和方法时使类型(类和接口)成为参数。与方法声明中使用的更熟悉的形式参数非常相似,类型参数为你提供了一种使用不同输入重复使用相同代码的方法。区别在于形式参数的输入是值,而类型参数的输入是类型。
从上面的描述中可以看出:泛型就是一个变量,只是该变量只能使用引用数据类型来赋值,这样能够使同样的代码被不同数据类型的数据重用。
2、使用泛型方法
包含泛型的类定义语法:
通常使用的泛型变量:E T K V
访问修饰符 class 类名 <泛型变量> {
}
包含泛型的接口定义语法:
访问修饰符 interface 接口名 <泛型变量> {
}
方法中使用新的泛型语法:
访问修饰符 泛型变量 返回值类型 方法名(泛型变量 变量名,数据类型1,变量名1,……,数据类型n,变量名n) {
}
使用泛型改造自定义集合Collection:
package FX;import java.util.AbstractCollection;
import java.util.Arrays;
import java.util.Iterator;//定义了泛型变量T,在使用MyCollection创建对象的时候,就需要使用具体的数据类型来替换泛型变量
public class MyCollection<T> extends AbstractCollection<T> {private Object[] elemates;private int size;public MyCollection(){this(16);}public MyCollection(int capacity){elemates=new Object[capacity];}@Overridepublic boolean add(T o) {//数组中存储满了,数组需要扩容才能存储新的元素if(size==elemates.length){//4 >> 1 0100 >> 1 => 010 =2int length=elemates.length+elemates.length>>1;elemates= Arrays.copyOf(elemates, length);}elemates[size++]=o;return true;}@Overridepublic Iterator<T> iterator() {return new CollectionIterator();}@Overridepublic int size() {return size;}class CollectionIterator implements Iterator<T>{//内部类使用private int cursor;// 光标,实际指下标@Overridepublic boolean hasNext() {return cursor<size;}@Overridepublic T next() {if(cursor>=size||cursor<0){throw new ArrayIndexOutOfBoundsException("下标越界了");}return (T)elemates[cursor++];}@Overridepublic void remove() {//在定义的代码中,先调用next(),再调用remove()if(cursor>=size||cursor<0){throw new ArrayIndexOutOfBoundsException("下标越界了");}System.arraycopy(elemates,cursor,elemates,cursor-1,size-cursor);if(cursor==size) cursor--; //表示移除的是最后一个元素,光标就会向前移动一位size--;//存储个数减去1}}
}package FX;import java.util.Iterator;public class MyCollectionTest {public static void main(String[] args) {//在JDK7及以上版本,new 对象时如果类型带有泛型,可以不写具体的泛型//在JDK7以下版本,在new 对象时如果类型带有泛型,必须写具体的泛型MyCollection<String> c2=new MyCollection<>();c2.add("admin");c2.add("uesr");for(Iterator<String> iterator1=c2.iterator();iterator1.hasNext();){String s=iterator1.next();System.out.println(s);}//当创建MyCollection对象没有使用泛型时,默认是Object类型MyCollection c=new MyCollection();c.add(5);c.add(4.0);c.add("3");c.add(2.0F);c.add(1);//遍历方式3for (Iterator iter=c.iterator();iter.hasNext();){Object i= (Object) iter.next();System.out.println(i);}}
}
3、泛型通配符
当使用泛型类或接口时,如果泛型类型不能确定,可以通过通配符?表示。例如Collection接口中的约定:
boolean containsAll ( Collection<?> c ); //判断集合是否包含给定集合中的所有元素
示例
package FX;import java.util.AbstractCollection;
import java.util.Arrays;
import java.util.Iterator;//定义了泛型变量T,在使用MyCollection创建对象的时候,就需要使用具体的数据类型来替换泛型变量
public class MyCollection<T> extends AbstractCollection<T> {private Object[] elemates;private int size;public MyCollection(){this(16);}public MyCollection(int capacity){elemates=new Object[capacity];}@Overridepublic boolean add(T o) {//数组中存储满了,数组需要扩容才能存储新的元素if(size==elemates.length){//4 >> 1 0100 >> 1 => 010 =2int length=elemates.length+elemates.length>>1;elemates= Arrays.copyOf(elemates, length);}elemates[size++]=o;return true;}@Overridepublic Iterator<T> iterator() {return new CollectionIterator();}@Overridepublic int size() {return size;}class CollectionIterator implements Iterator<T>{//内部类使用private int cursor;// 光标,实际指下标@Overridepublic boolean hasNext() {return cursor<size;}@Overridepublic T next() {if(cursor>=size||cursor<0){throw new ArrayIndexOutOfBoundsException("下标越界了");}return (T)elemates[cursor++];}@Overridepublic void remove() {//在定义的代码中,先调用next(),再调用remove()if(cursor>=size||cursor<0){throw new ArrayIndexOutOfBoundsException("下标越界了");}System.arraycopy(elemates,cursor,elemates,cursor-1,size-cursor);if(cursor==size) cursor--; //表示移除的是最后一个元素,光标就会向前移动一位size--;//存储个数减去1}}
}package FX;import java.util.Iterator;public class MyCollectionTest {public static void main(String[] args) {MyCollection<String> c=new MyCollection<>();c.add("a");c.add("b");c.add("c");c.add("d");c.add("e");MyCollection<String> c1=new MyCollection<>();c1.add("b");c1.add("c");c1.add("d");boolean contains1=c.containsAll(c1);System.out.println(contains1);//输出trueMyCollection<Integer> c2=new MyCollection<>();c2.add(1);c2.add(2);c2.add(3);boolean contains2=c.containsAll(c2);System.out.println(contains2);//输出false//泛型使用通配符的集合不能存储数据,只能读取数据MyCollection<?> c3=new MyCollection<>();
// c3.add(1);//报错
// c3.add("");//报错}
}
4、泛型上限
语法
<? extend 数据类型>
在使用泛型时,可以设置泛型的上限,表示只能接受该类型或其子类。当集合使用泛型上限时,因为编译器只知道存储类型的上限,但不知道具体存的是什么类型,因此,该集合不能存储元素,只能读取元素。
示例
package FX;public class GenericUpperLimit {public static void main(String[] args) {//定义了一个泛型上限为Number的集合 其子类有Integer Double Short Float LongMyCollection<? extends Number> c=new MyCollection<>();//添加元素时使用的是占位符? extends Number来对泛型变量进行替换,当//传入参数时,无法确定该参数应该怎么来匹配? extends Number,因此不能//存入数据,只能拿来读}
}5、泛型下限
语法
<? super 数据类型>
在使用泛型时,可以设置泛型的下限,表示只能接受该类型及其子类或该类型的父类。当集合使用泛型下限时,因为编译器知道存储类型的下限,至少可以将该类型对象存入,但不知道有存储的数据有多少种父类,因此,该集合只能存储元素,不能读取元素。
示例
package FX;public class GenericLowerLimit {public static void main(String[] args) {//集合中存储元素的类型可以是Number的子类、Number类、Number的父类MyCollection<? super Number> c=new MyCollection<>();//虽然存储元素的类型可以是Number的父类,但由于父类类型无法//确定具体有多少种,因此在使用添加功能时,编译器会报错}
}
五、List接口
1、特征描述
列表是有序的集合(有时称为序列)。列表可能包含重复的元素。
Java平台包含两个常用的List实现。ArrayList通常是性能较好的实现,而LinkedList在某些情况下可以提供更好的性能。
List接口常用方法
E get(int index); //获取给定位置的元素
E set(int index, E element);//修改给定位置的元素
void add(int index, E element);//在给定位置插入一个元素
E remove(int index);//移除给定位置的元素
int indexof(object o);//获取给定素未第一次出现的下标
int lastIndexof(object o);//获取给定元素最后一次出现的下标
ListIterator<E> listIterator();//获取List集合专有的迭代器
ListIterator<E> listIterator (int index);//获取List集合专有的迭代器,从给定的下标位置开始的迭代器
List<E> subList(int fromIndex, int toIndex);//获取List集合的一个子集合
2、ArrayList学习
示例
package List;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;public class ArrayListTest {public static void main(String[] args) {//集合有序是指存储顺序与遍历时取出的顺序一致ArrayList<String> list=new ArrayList<>();list.add("a");//第一次调用size=0;list.add("b");list.add("c");list.add("d");// a b c dlist.add(2,"r");//a b r c dString old=list.set(1,"g");//a g r c d//old为bSystem.out.println(old);System.out.println("==========================");for(String str:list){System.out.println(str);}System.out.println("===========================");Iterator<String> iter=list.iterator();//获得从前到后的迭代器while (iter.hasNext()){String s=iter.next();System.out.println(s);}System.out.println("============================");//获得从后往前输出的迭代器ListIterator<String> prevIterator=list.listIterator(list.size());while(prevIterator.hasPrevious()){String s=prevIterator.previous();System.out.println(s);}System.out.println("=============================");List<String> sublist=list.subList(2,4);for(String s:sublist){System.out.println(s);//输出r c}System.out.println("=============================");for(int i=0;i<list.size();i++){String s=list.get(i);System.out.println(s);}System.out.println("============================");ArrayList<Integer> numbers=new ArrayList<>();numbers.add(1);numbers.add(2);numbers.add(3);numbers.add(4);//移除下标为3这个位置的元素numbers.remove(3);//是移除下标为3这个位置的元素还是移除3这个元素?//移除3这个元素numbers.remove((Integer)3);for(Integer integer:numbers){System.out.println(integer);}numbers.add(2);numbers.add(2);int index1=numbers.indexOf(2);int index2=numbers.lastIndexOf(2);System.out.println(index1);//输出1System.out.println(index2);//输出3}
}
代码解读
ArrayList继承于AbstractList, AbstractList继承于AbstractColletion
ensurecapacityInternal(int mincapacity) 确保数组有足够的容量来存储新添加的数据
void grow(int mincapacity) 实现数组扩容,扩容至原来的1.5倍
ListItr可以从前到后对集合进行遍历,可以从后往前对集合进行遍历,还可以向集合中添加元素,修改元素。而Itr只能从前到后对集合进行遍历。
ArrayList底层采用的是数组来存储元素,根据数组的特性,ArrayList在随机访问时效率极高,在添加和删除元时效率偏低,因为在添加和删除元素时会涉及到数组中元素位置的移动。
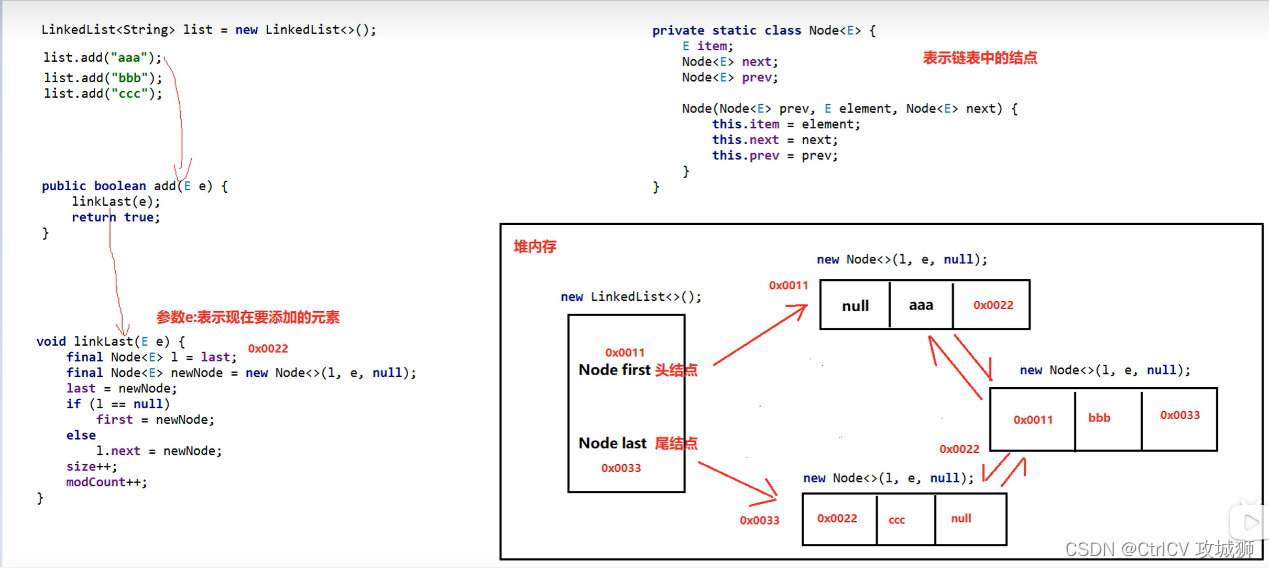
3、LinkedList学习
示例
单向链表
package List;/*** 自定义单向链表* @param <T> 泛型变量*/
public class MyNode<T> {private T data;//链中存储的数据private MyNode<T> next;//下一个链public MyNode(T data,MyNode<T> next){this.data=data;this.next=next;}public T getData() {return data;}public void setData(T data) {this.data = data;}public MyNode<T> getNext() {return next;}public void setNext(MyNode<T> next) {this.next = next;}
}package List;public class MyNodeTest {public static void main(String[] args) {MyNode<String> first=new MyNode<>("第一个链",null);MyNode<String> second=new MyNode<>("第二个链",null);first.setNext(second);MyNode<String> third=new MyNode<>("第三个链",null);second.setNext(third);MyNode<String> fourth=new MyNode<>("第四个链",null);third.setNext(fourth);MyNode<String> nextNode=first;while (nextNode!=null){System.out.println(nextNode.getData());nextNode=nextNode.getNext();}System.out.println("==========================");MyNode<Integer> number4=new MyNode<>(4,null);MyNode<Integer> number3=new MyNode<>(3,number4);MyNode<Integer> number2=new MyNode<>(2,number3);MyNode<Integer> number1=new MyNode<>(1,number2);MyNode<Integer> next=number1;while (next!=null){System.out.println(next.getData());next=next.getNext();}}
}双向链表
package List;/*** 自定义双向链表* @param <T>*/
public class DeNode<T> {private T data;//链中存储的数据private DeNode<T> prev;//前一个链private DeNode<T> next;//后一个链public DeNode(T data, DeNode<T> prev, DeNode<T> next) {this.data = data;this.prev = prev;this.next = next;}public T getData() {return data;}public void setData(T data) {this.data = data;}public DeNode<T> getPrev() {return prev;}public void setPrev(DeNode<T> prev) {this.prev = prev;}public DeNode<T> getNext() {return next;}public void setNext(DeNode<T> next) {this.next = next;}
}package List;public class DeNodeTest {public static void main(String[] args) {DeNode<Integer> number1=new DeNode<>(1,null,null);DeNode<Integer> number2=new DeNode<>(2,number1,null);number1.setNext(number2);DeNode<Integer> number3=new DeNode<>(3,number2,null);number2.setNext(number3);DeNode<Integer> number4=new DeNode<>(4,number3,null);number3.setNext(number4);DeNode<Integer> nextNode=number1;while (nextNode!=null){System.out.println(nextNode.getData());nextNode=nextNode.getNext();}System.out.println("===========================");DeNode<Integer> prevNode=number4;while (prevNode!=null){System.out.println(prevNode.getData());prevNode=prevNode.getPrev();}}
}
LinkedList继承于AbstractSequentialList, AbstractSequentialList 继承于AbstractList, AbstractList继承于AbstractColletion
void addFirst(E e); //将数据存储在链表的头部
void addLast(E e); //将数据存储在链表的尾部
E removeFirst(); //移除链表头部数据
E removeLast(); //移除链表尾部数据
package List;import java.util.LinkedList;public class LinkedListTest {public static void main(String[] args) {LinkedList<String> list=new LinkedList();list.add("第一个字符串");list.add("第二个字符串");list.addLast("第三个字符串");list.addFirst("第四个字符串");//将第一个链移除String first=list.removeFirst();//将最后一个链移除String last=list.removeLast();System.out.println(first);//输出”第四个字符串“System.out.println(last);//输出”第三个字符串“first=list.getFirst();last=list.getLast();System.out.println(first);//输出”第一个字符串“System.out.println(last);//输出”第二个字符串“}
}
注:LinkedList底层采用的是双向链表来存储数据,根据链表的特性可知,LinkedList在增加和删除元素时效率极高,只需要链之间进行链接即可。在随机访问时效率较低,因为需要从链的一端遍历到链的另一端。
4、栈学习
package List;import java.util.ArrayList;/*** 自定义栈:后进先出* @param <T>*/
public class MyStack<T> extends ArrayList<T> {public void push(T t){add(t);}public T pop(){if(size()==0) throw new IllegalArgumentException("栈里没数据了");T t= get(size() - 1);remove(t);return t;}
}package List;public class MyStackTest {public static void main(String[] args) {MyStack<Integer> stack=new MyStack<>();stack.push(1);stack.push(2);stack.push(3);stack.push(4);stack.push(5);while (!stack.isEmpty()){System.out.println(stack.pop());}}
}
六、Queue接口
1、特性描述
队列是用于在处理之前保存元素的集合。除了基本的收集操作外,队列还提供其他插入、移除和检查操作。
队列通常但不是必须以FIFO (先进先出)的方式对元素进行排序。优先队列除外, 它们根据元素的值对元素进行排序。无论使用哪种排序, 队列的开头都是将通过调用remove或poll删除的元素。在FIFO队列中, 所有新元素都插入到队列的尾部。其他种类的队列可能使用不同的放置规则。每个Queue实现必须指定其排序属性。
队列实现有可能限制其持有的元素数量:这样的队列称为有界队列。 java.util.concurrent中的某些Queue实现是有界的,但java.util中的某些实现不受限制。
Queue常用接口方法
boolean add(E e);//向队列中添加一个元素,如果出现异常,则直接抛出异常
boolean offer(E e);//向队列中添加一个元素,如果出现异常,则返回false
E remove();//移除队列中第一个元素, 如果队列中没有元素,则将抛出异常
E poll();//移除队列中第一个元素,如果队列中没有元素,则返回null
E element();//获取队列中的第一个元素,但不会移除。如果队列为空,则将抛出异常
E peek();//获取队列中的第一个元素, 但不会移除。如果队列为空,则返回null
2、LinkedBlockingQueue
LinkedBlockingQueue是一个FIFO队列, 队列有长度,超出长度范围的元素将无法存储进队列。
示例
package queue;import java.util.concurrent.LinkedBlockingQueue;public class LinkedBlockingQueueTest {public static void main(String[] args) {//构建队列时,通常会对队列设置一个容量,因为默认容量太大了LinkedBlockingQueue<String> queue=new LinkedBlockingQueue<>(5);
// String first=queue.element();//获取队列中第一个元素,如果为空,则抛出异常String first=queue.peek();//获取队列第一个元素,如果队列为空,则返回nullSystem.out.println(first);//输出nullqueue.add("a");queue.add("b");queue.add("c");queue.add("d");queue.add("e");// queue.add("f");//放入第6个元素将抛出异常queue.offer("f");//放入第六个元素不会抛出异常,只会返回falseboolean success=queue.offer("f");System.out.println(success);//输出false// while (!queue.isEmpty()){
// String s=queue.poll();
// System.out.println(s);
// }queue.remove();queue.remove();queue.remove();queue.remove();queue.remove();System.out.println("=======================");// queue.remove();//移除第6个元素将抛出异常String s=queue.poll();//移除第6个元素,不会抛出异常,但返回null}
}
3、PriorityQueue
PriorityQueue是一个有排序规则的队列, 存入进去的元素是无序的,队列有长度,超出长度范围的元素将无法存储进队列。需要注意的是,如果存储的元素如果不能进行比较排序,也未提供任何对元素进行排序的方式,运行时会抛出异常。
示例
package queue;public class User {private String name;//o-普通用户 1-vip用户1 2-vip2private int level;public User(String name, int level) {this.name = name;this.level = level;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", level=" + level +'}';}
}package queue;import java.util.PriorityQueue;public class PriorityQueueTest {public static void main(String[] args) {PriorityQueue<Integer> queue=new PriorityQueue<>();queue.offer(5);queue.offer(4);queue.offer(3);queue.offer(2);queue.offer(1);for(Integer number:queue){System.out.println(number);}System.out.println("============================");while (!queue.isEmpty()){Integer number=queue.poll();System.out.println(number);}PriorityQueue<User> users=new PriorityQueue<>();//对象不能进行比较排序users.offer(new User("fire",0));users.offer(new User("fall",1));users.offer(new User("from",3));users.offer(new User("fox",2));}
}
注:如果对象不能进行比较,则不能排序,运行时会报异常。要解决这个问题,需要使用Java平台提供的比较器接口。
七、比较器接口
1、比较器作用
在使用数组或者集合时,我们经常都会遇到排序问题,比如将学生信息按照学生的成绩从高到低依次排列。数字能够直接比较大小,对象不能够直接比较大小,为了解决这个问题,Java 平台提供了Comparable和Comparator两个接口来解决。
2、Comparable接口
接口对实现该接口的每个类的对象强加了总体排序。此排序称为类的自然排序,而该类的compareTo方法被称为其自然比较方法。
package queue;public class User implements Comparable<User>{private String name;//o-普通用户 1-vip用户1 2-vip2private int level;public User(String name, int level) {this.name = name;this.level = level;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", level=" + level +'}';}@Overridepublic int compareTo(User o) {if(level==o.level) return 0;else if(level<o.level) return 1;else return -1;}
}package queue;import java.util.PriorityQueue;public class PriorityQueueTest {public static void main(String[] args) {PriorityQueue<User> users=new PriorityQueue<>();users.offer(new User("fire",0));users.offer(new User("fall",1));users.offer(new User("from",3));users.offer(new User("fox",2));while (!users.isEmpty()){User user=users.poll();System.out.println(user);}}
}
package compare;public class Student implements Comparable<Student>{private String name;private int age;public Student(String name, int age) {this.name = name;this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic int compareTo(Student o) {if(age==o.age){return name.compareTo(o.name);} else if(age<o.age) return 1;else return -1;}
}package compare;import java.util.*;public class ComparableTest {public static void main(String[] args) {Student[] students={new Student("as",24),new Student("lp",23),new Student("ws",24),new Student("lh",23)};Arrays.sort(students);for(Student s:students){System.out.println(s);}System.out.println("=======================");//对集合排序List<Student> studentList=new ArrayList<>();studentList.add(new Student("as",24));studentList.add(new Student("lp",23));studentList.add(new Student("ws",24));studentList.add(new Student("lh",23));Collections.sort(studentList);for(Student s:studentList){System.out.println(s);}}
}
3、Comparator接口
比较功能,对某些对象集合施加总排序。可以将比较 器传递给排序方法(例如Collections . sort或Arrays.sort),以实现对排序顺序的精确控制。
示例
package compare;public class Course {private String name;private double score;public Course(String name, double score) {this.name = name;this.score = score;}@Overridepublic String toString() {return "Course{" +"name='" + name + '\'' +", score=" + score +'}';}public String getName() {return name;}public void setName(String name) {this.name = name;}public double getScore() {return score;}public void setScore(double score) {this.score = score;}
}package compare;import java.util.*;public class ComparatorTest {public static void main(String[] args) {Course[] courses={new Course("Java",5),new Course("Html",3),new Course("JavaScript",2),new Course("JDBC",6)};// Comparator<Course> c=new Comparator<Course>(){
//
// @Override
// public int compare(Course o1, Course o2) {
// return 0;
// }
// };// Comparator<Course> c=(Course o1,Course o2) -> {
// return 0;
// };Comparator<Course> c=(o1,o2) -> {double score1=o1.getScore();double score2=o2.getScore();if(score1==score2)return o1.getName().compareTo(o2.getName());else if(score1<score2) return -1;else return 1;};Arrays.sort(courses,c);for(Course course:courses){System.out.println(course);}System.out.println("===========================");List<Course> courseList=new ArrayList<>();courseList.add( new Course("Java",5));courseList.add(new Course("Html",3));courseList.add(new Course("JavaScript",2));courseList.add(new Course("JDBC",6));Collections.sort(courseList,c);for(Course course:courseList){System.out.println(course);}}
}
4、总结
Comparable接口是有数组或者集合中的对象的类所实现,实现后对象就拥有比较的方法,因此称为内排序或者自然排序。Comparator接口是外部提供的对两个对象的比较方式的实现,对象本身并没有比较的方式,因此被称为外排序器。
八、Map接口
1、特性描述
Map集合是将键映射到值的对象。映射不能包含重复的键:每个键最多可以映射到一个值。
Java平台包含三个常用Map的实现: HashMap, TreeMap和LinkedHashMap。
Map接口常用方式
int size(); //获取集合的大小
boolean isEmpty();//判断集合是否为空
boolean containsKey(object key)://判断集合中是否包含给定的键
boolean containsValue(object value);//判断集合中是否包含给定的值
V get(object key);//获取集合中给定键对应的值
V put(K key, V value);//将一个键值对放入集合中
V remove(object key) ;//将给定的键从集合中移除
void putAll(Map<? extends K,? extends V> m);//将给定的集合添加到集合中
void clear();//清除集合中所有元素
Set<K> keySet();//获取集合中键的集合
Collection<V> values();//获取集合中值的集合
set(Map Entry<K, V>> entrySet()://获取集合中键值对的集合
Entry常用方法
K getKey(); //获取键
V getValue();//获取值
V setValue(V value);//设置值
boolean equals (object o);//比较是否是同一个对象
int hashCode() ;//获取哈希码
注:Map接口中的内部接口Entry就是Map存储的数据项,一个Entry就是一个键值对。
示例
package Map;public class MyEntry<K,V> {private K key;private V value;private MyEntry<K,V> next;//链条实现public MyEntry(K key, V value,MyEntry<K,V> next) {this.key = key;this.value = value;this.next=next;}public K getKey() {return key;}public void setKey(K key) {this.key = key;}public V getValue() {return value;}public void setValue(V value) {this.value = value;}public MyEntry<K, V> getNext() {return next;}public void setNext(MyEntry<K, V> next) {this.next = next;}
}package Map;public class MyMap<K,V> {private MyEntry<K,V>[] elements;private int size;private float loadFactor=0.75f;//负载因子public MyMap(){this(16);}public MyMap(int capacity){this.elements=new MyEntry[capacity];}public V put(K key,V value){int currentSize=size+1;//进行扩容if(currentSize>=elements.length*loadFactor){MyEntry<K,V>[] entries=new MyEntry[currentSize<<1];for (MyEntry<K,V> entry:entries){int hash=entry.getKey().hashCode();int index=hash&(entries.length-1);entries[index]=entry;}elements=entries;}int hash=key.hashCode();int index=hash&(elements.length-1);MyEntry<K,V> addEntry=new MyEntry<>(key,value,null);if(elements[index]==null){elements[index]=addEntry;} else {MyEntry<K,V> existEntry=elements[index];while (existEntry.getNext()!=null){existEntry=existEntry.getNext();}existEntry.setNext(addEntry);}size++;return elements[index].getValue();}public V get(K key){for(MyEntry<K,V> entry:elements){if(entry==null) continue;K k=entry.getKey();if(k.equals(key)) return entry.getValue();MyEntry<K,V> temp=entry;while (temp!=null){if(temp.getKey().equals(key)) return temp.getValue();temp=temp.getNext();}}return null;}public int size(){return size;}public boolean isEmpty(){return size==0;}
}package Map;public class Test {public static void main(String[] args) {MyMap<Integer,String> map=new MyMap<>();map.put(1,"a");map.put(2,"b");map.put(3,"c");map.put(17,"d");map.put(33,"e");}
}
2、HashMap学习
基于哈希表的Map接口的实现。此实现提供所有可选的映射操作,并允许空值和空键。(HashMap类与Hashtable大致等效,不同之处在于它是不同步的,并且允许为null。)该类不保证映射的顺序。特别是, 它不能保证顺序会随着时间的推移保持恒定。
HashMap存储的是一组无序的键值对。存储时是根据键的哈希码来计算存储的位置,因为对象的哈希码是不确定的,因此HashMap存储的元素是无序的。
示例
package Map;import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;public class HashMapTest {public static void main(String[] args) {//HashMap采用的是数组、链表以及红黑树来存储数据//链表的设计主要是针对Hash碰撞而引发存储位置冲突//红黑树的设计主要是针对于链表过长,遍历太慢HashMap<Integer,String> map=new HashMap<>();//映射实现map.put(1,"a");map.put(2,"b");map.put(3,"c");map.put(4,"d");map.put(17,"e");String value=map.get(1);System.out.println(value);//输出aSystem.out.println(map.size());//输出5System.out.println(map.isEmpty());//输出falseSystem.out.println(map.containsKey(3));//输出trueSystem.out.println(map.containsValue("e"));//输出trueSystem.out.println(map.remove(17));HashMap<Integer,String> map1=new HashMap<>();map1.put(5,"CN");map1.put(6,"US");map1.put(7,"EN");map.putAll(map1);System.out.println(map.size());//输出7System.out.println("=======================");Set<Integer> keySet=map.keySet();for(Integer i:keySet){System.out.println(i);}System.out.println("==========================");Collection<String> valus=map.values();for(String str:valus){System.out.println(str);}Set<Map.Entry<Integer,String>> entries=map.entrySet();for (Map.Entry<Integer,String> entry:entries){Integer key=entry.getKey();String val=entry.getValue();System.out.println(key+"=>"+val);}map.clear();System.out.println(map.size());//输出0}
}
HashMap采用的是数组加单向链表加红黑树的组合来储存数据。
3、TreeMap学习
基于红黑树的NavigableMap实现。根据集合存储的键的自然排序或在映射创建时提供的Comparator来对键进行排序,具体取决于所使用的构造方法。
示例
package Map;public class Computer implements Comparable<Computer>{private String brand;private double price;public Computer(String brand, double price) {this.brand = brand;this.price = price;}public String getBrand() {return brand;}public void setBrand(String brand) {this.brand = brand;}public double getPrice() {return price;}public void setPrice(double price) {this.price = price;}@Overridepublic String toString() {return "Computer{" +"brand='" + brand + '\'' +", price=" + price +'}';}@Overridepublic int compareTo(Computer o) {return Double.compare(price,o.price);}
}package Map;import java.util.Comparator;
import java.util.Set;
import java.util.TreeMap;public class TreeMapTest {public static void main(String[] args) {TreeMap<Computer, Integer> map=new TreeMap<>();map.put(new Computer("联想",4000),1);map.put(new Computer("外星人",30000),2);Set<Computer> set=map.keySet();for(Computer comp:set){System.out.println(comp);}System.out.println("====================================");
// Comparator<Computer> c=new Comparable<Computer>(Computer o1,Computer o2) {
// @Override
// public int compareTo(Computer o) {
// return 0;
// }
// };// Comparator<Computer> c=( o1, o2) -> {
// return Double.compare(o1.getPrice(),o2.getPrice());
// };Comparator<Computer> c=( o1, o2) -> Double.compare(o1.getPrice(),o2.getPrice());TreeMap<Computer, Integer> map1=new TreeMap<>();map1.put(new Computer("联想",4000),1);map1.put(new Computer("外星人",30000),2);for(Computer comp:map1.keySet()){System.out.println(comp);}}
}
4、LinkedHashMap学习
Map接口的哈希表和链表实现,具有可预测的迭代顺序。此实现与HashMap的不同之处在于,它维护一个贯穿其所有条目的双向链表。此链表定义了迭代顺序,通常是将键插入映射的顺序(插入顺序) 。请注意, 如果将键重新插入到映射中,则插入顺序不会受到影响。
示例
package Map;import java.util.LinkedHashMap;
import java.util.Map;public class LinkedHashMapTest {public static void main(String[] args) {LinkedHashMap<String,String> map=new LinkedHashMap<>();map.put("CN","中华人民共和国");//第一次是放入map.put("EN","英国");map.put("US","美国");map.put("AU","澳大利亚");map.put("CN","中国");//第二次是修改for(String key:map.keySet()){System.out.println(key);}System.out.println("================================");for(Map.Entry<String,String> entry:map.entrySet()){System.out.println(entry.getKey()+"=>"+entry.getValue());}}
}
九、Set接口
1、特性描述
集合是一个集合,不能包含重复的元素。它为数学集合抽象建模。 Set接口仅包含从Collection继承的方法,并增加了禁止重复元素的限制。Set还为equals和hashCode操作的行为增加了更紧密的约定,即使它们的实现类型不同,也可以有意义地比较Set实例。如果两个Set实例包含相同的元素,则它们相等。
Java平台包含三个通用的Set实现: HashSet, TreeSet 和LinkedHashSet。 HashsSet将其元素存储在哈希表中, 是性能最好的实现。但是,它不能保证迭代的顺序。
2、HashSet学习
示例
package set;import java.util.HashSet;
import java.util.Iterator;public class HashSetTest {public static void main(String[] args) {HashSet<String> set=new HashSet<>();set.add("a");set.add("a");System.out.println(set.size());//输出1set.add("b");for(String str:set){System.out.println(str);}HashSet<String> hashSet=new HashSet<>();hashSet.add("C");hashSet.add("D");hashSet.add("E");set.addAll(hashSet);System.out.println("=========================");for(String str:set){System.out.println(str);}System.out.println(set.contains("C"));System.out.println(set.remove("E"));Iterator<String> iterator=set.iterator();System.out.println("========================");while (iterator.hasNext()){System.out.println(iterator.next());}}
}
3、TreeSet学习
基于TreeMap的Navigableset实现。元素使用其自然顺序或在集合创建时提供的Comparator进行排序,具体取决于所使用的构造方法。
示例
package set;public class Car implements Comparable<Car>{private String brand;private double price;public Car(String brand, double price) {this.brand = brand;this.price = price;}public String getBrand() {return brand;}public void setBrand(String brand) {this.brand = brand;}public double getPrice() {return price;}public void setPrice(double price) {this.price = price;}@Overridepublic String toString() {return "Car{" +"brand='" + brand + '\'' +", price=" + price +'}';}@Overridepublic int compareTo(Car o) {return Double.compare(price,o.price);}
}package set;import java.util.TreeSet;public class TreeMapTest {public static void main(String[] args) {TreeSet<Car> cars=new TreeSet<>();cars.add(new Car("奥迪",100000));cars.add(new Car("大众",50000));for(Car c:cars){System.out.println(c);}}
}
package set;public class Car{private String brand;private double price;public Car(String brand, double price) {this.brand = brand;this.price = price;}public String getBrand() {return brand;}public void setBrand(String brand) {this.brand = brand;}public double getPrice() {return price;}public void setPrice(double price) {this.price = price;}@Overridepublic String toString() {return "Car{" +"brand='" + brand + '\'' +", price=" + price +'}';}}package set;import java.util.Comparator;
import java.util.TreeSet;public class TreeMapTest {public static void main(String[] args) {Comparator<Car> c=(c1,c2)->Double.compare(c1.getPrice(),c2.getPrice());TreeSet<Car> cars=new TreeSet<>();cars.add(new Car("奥迪",100000));cars.add(new Car("大众",50000));for(Car car:cars){System.out.println(car);}}
}
4、LinkedHashSet学习
Set接口的哈希表和链表实现,具有可预测的迭代顺序。此实现与HashSet的不同之处在于,它维护在其所有条目中运行的双向链接列表。此链表定义了迭代顺序,即将元素插入到集合中的顺序(插入顺序)。请注意, 如果将元素重新插入到集合中,则插入顺序不会受到影响。
示例
package set;import java.util.LinkedHashSet;public class LinkedHashSetTest {public static void main(String[] args) {LinkedHashSet<String> strings=new LinkedHashSet<>();strings.add("D");strings.add("C");strings.add("B");strings.add("A");for(String str:strings){System.out.println(str);}}
}