- 论文:https://arxiv.org/abs/2403.10516
- 代码:https://github.com/mhamilton723/FeatUp
- 语雀文档:https://www.yuque.com/lart/papers/behz5m63gp96bv75
背景动机
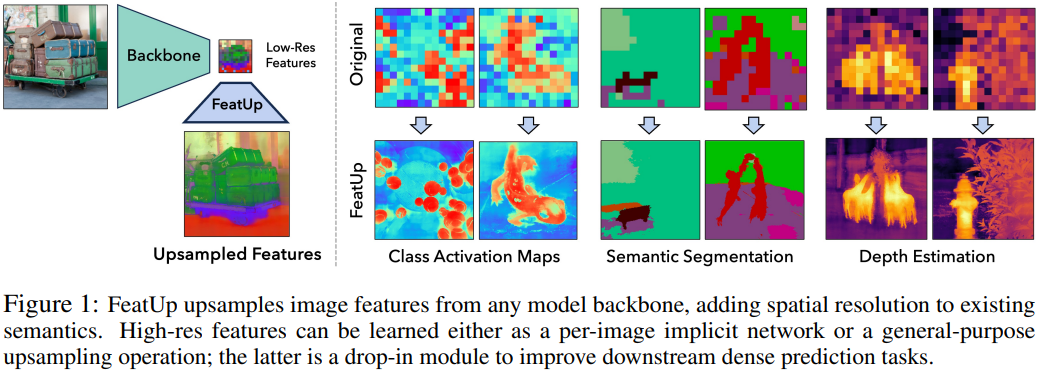
深层特征是计算机视觉研究的基石,捕获图像语义并使社区即使在零或少样本情况下也能解决下游任务。然而,这些特征通常缺乏空间分辨率来直接执行分割和深度预测等密集预测任务,因为模型会积极地池化大区域的信息。在这项工作中引入了 FeatUp,这是一个与任务和模型无关的框架,用于恢复深层特征中丢失的空间信息。
相关工作
Image-adaptive Filtering
自适应滤镜通常用于增强图像,同时保留其底层结构和内容。
例如,双边滤波器(bilateral filters)【Bilateral filtering for gray and color images,The Guided Bilateral Filter: When the Joint/Cross Bilateral Filter Becomes Robust,Fast image dehazing using guided joint bilateral filter】 将空间滤波器应用于低分辨率信号,将图像亮度滤波器应用于高分辨率引导,以混合来自二者的信息。而其重要的扩展形式,联合双边上采样(Joint Bilateral Upsampling,JBU)【Joint bilateral upsampling】,可以在高分辨率引导下对低分辨率信号进行上采样。已成功用于高效图像增强和其他应用。
最近一些工作嵌入了双边滤波方法【Guided Upsampling Network for Real-Time Semantic Segmentation】和非局部均值(Nonlocal Means)【A Non-Local Algorithm for Image Denoising】方法到卷积网络【Superpixel Convolutional Networks using Bilateral Inceptions,Non-local neural networks】和视觉 transformer【Blending Anti-Aliasing into Vision Transformer,Transformer for Single Image Super-Resolution】中。
- Shape Recipes【Shape recipes: scene representations that refer to the image】学习信号之间的局部关系以创建上采样目标信号。
- Pixel-adaptive convolutional (PAC) 【Pixel-Adaptive Convolutional Neural Networks】使卷积运算适应输入数据,并已用于提高分割【Single-Stage Semantic Segmentation from Image Labels】和单目深度估计【Semantically-Guided Representation Learning for Self-Supervised Monocular Depth,SelfDeco: Self-Supervised Monocular Depth Completion in Challenging Indoor Environments】。
- Spatially-Adaptive Convolution (SAC)【SqueezeSegV3: Spatially-Adaptive Convolution for Efficient Point-Cloud Segmentation】中的空间自适应卷积将自适应滤波器分解为注意力图和卷积核。
- Bilateral Inception Module【Superpixel Convolutional Networks using Bilateral Inceptions】将双边过滤扩展到超像素,并将此操作嵌入到深层网络中以改进语义分割。
这类方法在各种应用中都有效,直接将空间信息合并到任务中,同时仍然允许学习网络的灵活性。
Image Super-resolution
- 最早的深度无监督超分辨率方法之一是零样本超分辨率 ZSSR【Zero-Shot Super-Resolution Using Deep Internal Learning】,它在测试时学习单图像网络。
- 局部隐式模型 LIIF【Learning Continuous Image Representation with Local Implicit Image Function】使用局部自适应模型来插值信息,并已被证明可以提高超分辨率网络的性能。
- 深度图像先验 DIP【Deep Image Prior】表明,CNN 可以为零样本图像去噪和超分辨率等逆问题提供归纳偏置。
尽管有大量关于图像超分辨率的文献,但这些方法并不适合处理超低分辨率但高维的深层特征。
General-purpose feature upsampling
- 双线性插值是一种广泛使用的对深度特征图进行上采样的方法。虽然有效,但这种方法模糊了信息,并且对原始图像中的内容或高分辨率结构不敏感。最近邻插值法和双三次插值法也有类似的缺点。
- 在更大的输入上评估网络可以实现更高的分辨率,但计算成本很高。此外,由于相对感受野大小的减小,这通常会降低模型性能和语义。
- 对于深度卷积网络,一种流行的技术是将最终卷积步长设置为 1【Fully Convolutional Networks for Semantic Segmentation】。然而,这种方法会产生模糊的特征,因为模型的感受野仍然很小(原文是仍然很大,似乎意思不太对)。
- 最近使用 visual transformer 的工作【Deep vit features as dense visual descriptors】对输入 patch 步幅进行了类似的修改并插入位置编码。虽然简单有效,但分辨率每增加 2 倍,这种方法就会导致计算占用量急剧增加,因此无法在实践中用于更大的上采样因子。由于前面 patch 的感受野是固定的,这种方法也会扭曲特征。
Image-adaptive feature upsampling
- 反卷积/转置卷积【Learning Deconvolution Network for Semantic Segmentation】使用学到的卷积核将特征转换到具有更大分辨率的新空间。
- Resize+Convolution【Deconvolution and Checkerboard Artifacts】将学习的卷积附加到确定性上采样过程中,并减少困扰反卷积的棋盘伪影。这一设定是现在图像解码器的常见组件,并已应用于语义分割和超分辨率。
- 其他方法,如 IndexNet【Index Networks】和 Affinity-Aware Upsampling (A2U) 【Learning Affinity-Aware Upsampling for Deep Image Matting】在图像抠图方面很有效,但在其他密集预测任务上效果不佳【FADE: Fusing the Assets of Decoder and Encoder for Task-Agnostic Upsampling】。
- Pixel-adaptive convolutional (PAC) 【Pixel-Adaptive Convolutional Neural Networks】、CARAFE【Carafe: Content-aware reassembly of features】、SAPA【Sapa: Similarity-aware point affiliation for feature upsampling】和 DGF【Fast end-to-end trainable guided filter】等方法使用可学习的输入自适应算子来转换特征。
- PAC 很灵活,但它并没有忠实地对现有特征图进行上采样,而是用于转换下游任务的特征。
- DGF 通过逐点卷积和线性映射来近似 JBU 操作,但没有完全实现 JBU,因为局部的 query/model 在计算上很难处理。这正是本文通过新的高效 CUDA 核解决的问题。
- FADE 中引入了一种新的半移位算子,并使用解码器特征来生成联合特征上采样模块。
- Implicit Feature Alignment function (IFA)【Learning implicit feature alignment function for semantic segmentation】从不同的角度(in a different light)看待特征上采样,重点关注最近邻方法,以将编码器 - 解码器架构中的特征图与 IFA 对齐。虽然 IFA 在特定语义分割基准上表现良好,但它没有利用图像引导,也无法在编码 - 解码器框架之外学习高质量表示。
具体方法
FeatUp 背后的核心直觉是,人们可以通过观察低分辨率特征的多个不同“视角”来计算高分辨率特征。
与 NeRF 通过在场景的许多 2D 照片之间强制一致性来构建 3D 场景的隐式表示一样,FeatUp 通过在许多低分辨率特征图之间强制一致性来构建上采样器,即认为低分辨率信号的多视图一致性可以监督高分辨率信号的构建。更具体地说,通过聚合多个“抖动”(例如翻转、填充、裁剪)图像的模型输出的低分辨率视图来学习高分辨率信息。通过学习具有多视图一致性损失的上采样网络来聚合这些信息。这一基本思想可以产生多种方法。
- 基于联合双边上采样的轻量级前向上采样器:该前馈上采样器是联合双边上采样 (JBU) 滤波器的参数化概括,通过自定义 CUDA 核函数从而比现有实现速度快了几个数量级且占用内存更少。该上采样器可以与几个卷积相当的计算成本产生与对象边缘对齐的高质量特征。
- 基于隐式网络的上采样器:将隐式模型拟合到单个图像以在任何分辨率下重建特征。通过用深度隐式网络过拟合信号,针对目标图像独立学习,允许任意分辨率特征生成,同时具有较低的存储成本。
在这两种上采样架构的特征可以在下游应用中直接替换使用,因为所提方法不会转换底层特征的语义,即使无需重新训练也能获得分辨率和性能提升。
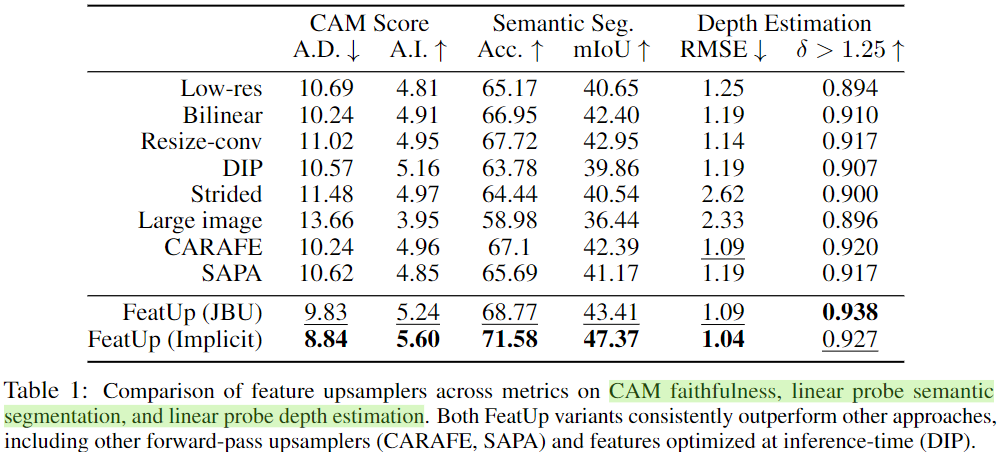
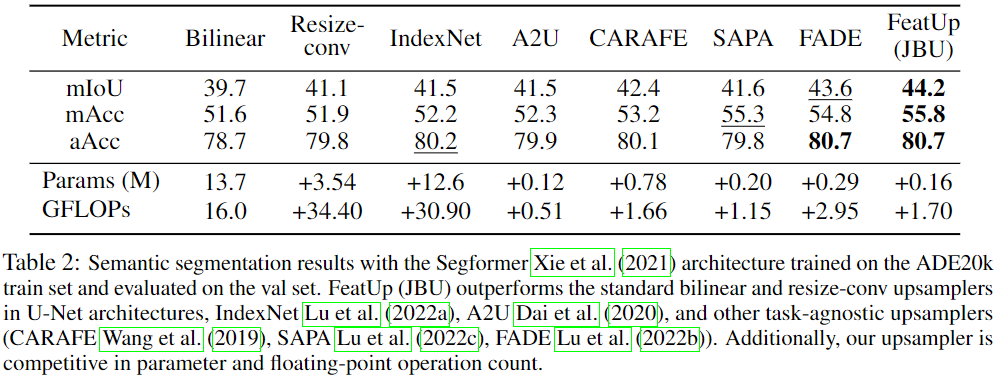
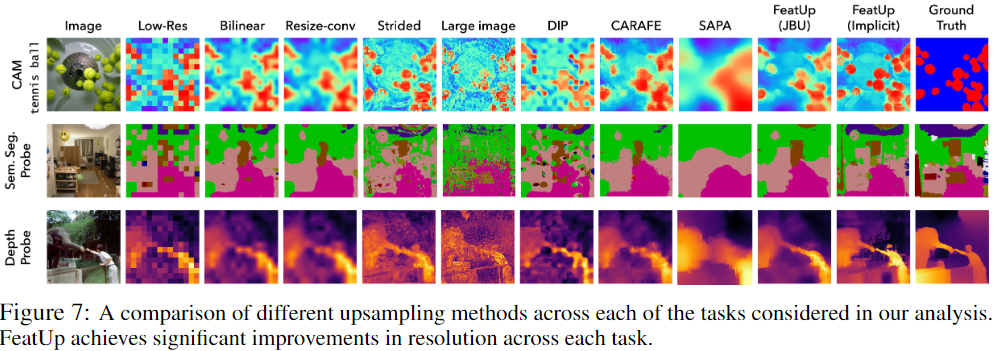
文中的实验表明,FeatUp 在类激活图生成、分割和深度预测的迁移学习以及语义分割的端到端训练方面显着优于其他特征上采样和图像超分辨率方法。
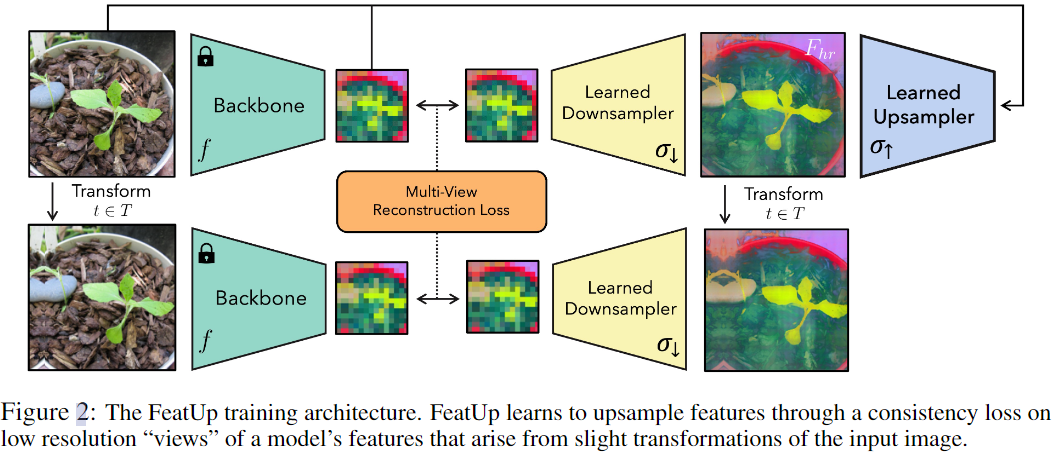
- 第一步是生成低分辨率特征视图,以细化为单个高分辨率输出。为此用小的 padding、尺寸和水平翻转扰乱输入图像,并将模型应用于每个变换后的图像,以提取低分辨率特征图的集合。这些小的图像抖动可以帮助观察输出特征的微小差异,并提供子特征信息来训练上采样器。
- 接下来从这些视图构建一致的高分辨率特征图。假设可以学习一个潜在的高分辨率特征图。当下采样时,它可以再现低分辨率的抖动特征。FeatUp 的下采样是光线行进(ray-marching)的直接模拟;正如在此 NeRF 中将 3D 数据渲染为 2D 一样,这里的下采样器将高分辨率特征转换为低分辨率特征。与 NeRF 不同,这里不需要估计生成每个视图的参数。相反,用于 " 抖动 " 每个图像的参数被跟踪,并在下采样之前对学到的高分辨率特征应用相同的转换。然后使用高斯似然损失将下采样特征与真实模型输出进行比较【It Is Likely That Your Loss Should be a Likelihood】。一个好的高分辨率特征图应该重建所有不同视图中观察到的特征。
整体的多视角重建损失可以表示如下:(低分辨率特征层面上的一致性)
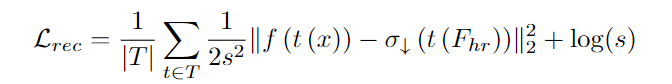
- t ∈ T t \in T t∈T 代表这些小变换的集合, x x x 为输入图像, f f f 为模型主干。
- σ ↓ \sigma_{\downarrow} σ↓ 为学到的下采样器, σ ↑ \sigma_{\uparrow} σ↑ 为学到的上采样器。
- F h r = σ ↑ ( f ( x ) , x ) F_{hr} = \sigma_{\uparrow}(f(x), x) Fhr=σ↑(f(x),x) 形成预测的高分辨率特征 F h r F_{hr} Fhr。这种参数化允许 σ ↑ \sigma_{\uparrow} σ↑ 可以有四种形式:
- 引导上采样器(取决于 x x x 和 f ( x ) f (x) f(x));
- 非引导上采样器(仅取决于 f ( x ) f (x) f(x));
- 隐式网络(取决于仅 x x x);
- 特征的可学习缓存参数(不依赖任何东西,即一套可学习的参数)。
- ∥ ⋅ ∥ \|\cdot\| ∥⋅∥ 是标准的 l 2 l_2 l2 范数。
- s = N ( f ( t ( x ) ) ) s = \mathcal{N}(f(t(x))) s=N(f(t(x))) 是空间变化的自适应不确定性【It Is Likely That Your Loss Should be a Likelihood】。这将 MSE 损失转化为能够处理不确定性的更合适的似然。这种额外的灵活性允许网络在某些异常特征从根本上无法进行上采样时进行学习。
下采样器设计
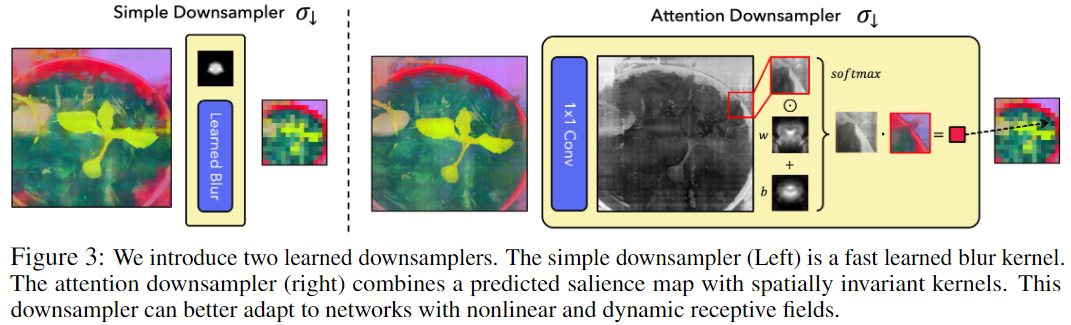
这里引入两个选项,即快速且简单的学到的模糊核,更灵活的基于注意力的下采样器。两个提出的模块都不会通过特殊变换来改变特征的 " 空间 " 或 " 语义 ",而只是在一个小邻域内插入特征。图 3 中绘制了这两种选择。
两个下采样器的主要超参数是核大小,对于具有较大感受野的模型(例如卷积网络),内核大小应该更大。
简单的下采样器
通过学到的模糊核来模糊特征,可以实现为独立应用于每个通道的卷积。学习到的核被归一化为非负且总和为 1,以确保特征保持在同一空间中。尽管这种基于模糊的下采样器非常高效,但它无法捕获动态感受野、对象显着性或其他非线性效应。
更灵活的注意力下采样器
可以在空间上调整下采样核。该组件使用 1x1 卷积根据高分辨率特征预测显着性图。它将显着性图与学到的空间不变权重和偏置核相结合,并对归一化结果以创建插入特征的空间变化模糊核:
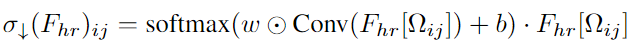
- σ ↓ ( F ) i j \sigma_\downarrow(F)_{ij} σ↓(F)ij 是结果特征图的第 i, j 个分量。
- F h r [ Ω i j ] F_{hr}[\Omega_{ij}] Fhr[Ωij] 是指与下采样特征中的 i, j 位置相对应的高分辨率特征块。
- ⊙ \odot ⊙ 和 ⋅ \cdot ⋅ 分别指元素级乘积和向量内积。
- w w w 和 b b b 是所有补丁共享的学习权重和偏置核。
上采样器设计
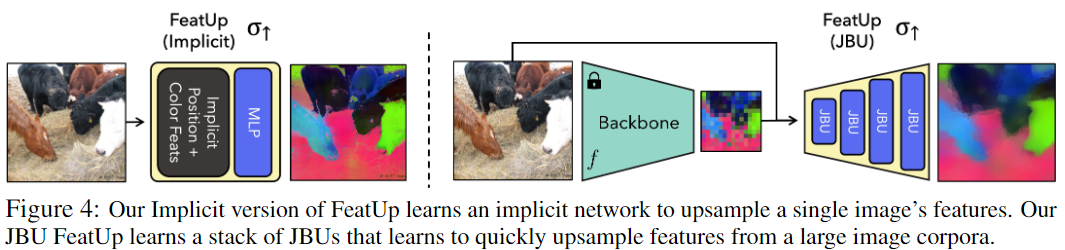
图中展示了本文设计的两种方法,二者都使用相同的更广泛的架构和损失进行训练。
基于堆叠的联合双边上采样器的引导上采样器
该架构学习了一种跨图像语料泛化的上采样策略。
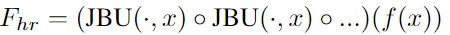
∘ \circ ∘ 是函数组合。 f ( x ) f(x) f(x) 是低分辨率特征图。 x x x 是原始图像。
该架构速度快,直接将输入图像中的高频细节合并到上采样过程中,并且独立于 f f f 的架构。
公式将原始 JBU 的实现推广到高维信号,并使该操作可学习。在联合双边上采样中,使用高分辨率信号 G G G 作为低分辨率特征 F l r F_{lr} Flr 的引导。 Ω \Omega Ω 是每个像素在引导图像中的邻域。
在实践中,我们使用以每个像素为中心的 3×3 正方形。令 k ( ⋅ , ⋅ ) k(\cdot,\cdot) k(⋅,⋅) 为相似核,用于衡量两个向量的 " 接近 " 程度。然后我们可以形成联合双边过滤器:
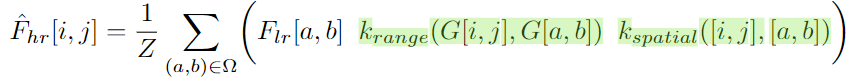
原始的 JBU 形式:
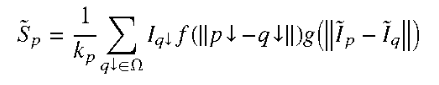
其中的 Z Z Z 是归一化因子,确保核参数加和为 1。spatial 核是向量坐标之间欧氏距离上宽度为 σ s p a t i a l \sigma_{spatial} σspatial 的可学习的高斯核:
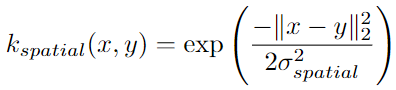
此外,range 核是对引导信号 G G G 进行操作的多层感知器 (MLP) 输出内积施加温度 σ r a n g e 2 \sigma_{range}^2 σrange2 的 softmax 的形式:
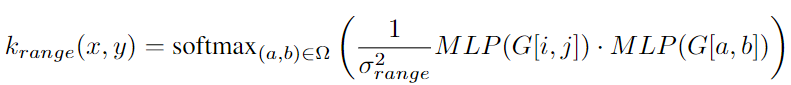
原始 JBU 在引导信号 G 上使用固定的高斯核。而这里设计的泛化性能要好得多,因为可以从数据中学习 MLP 以创建更好的上采样器。在实验中使用具有 30 维隐藏向量和输出向量的两层 GeLU MLP。为了评估 F l r [ a , b ] F_{lr}[a, b] Flr[a,b],如果引导像素不直接与低分辨率特征对齐,则遵循原始 JBU 公式使用双线性插值特征。为了与分辨率无关,这里在空间核中使用归一化到 [−1, 1] 的坐标距离。
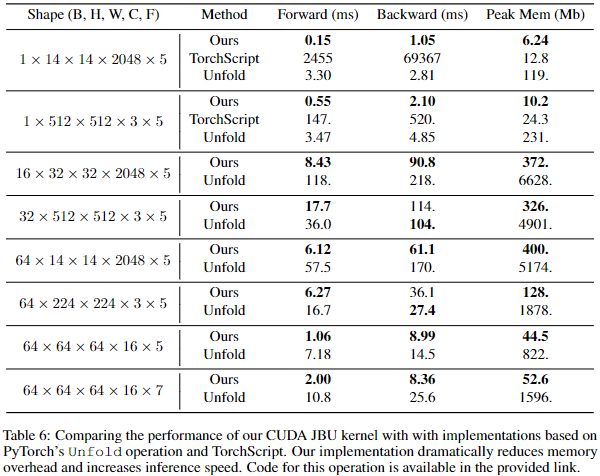
这一形式的挑战之一是现有 JBU 实现的速度和内存性能较差。这可以解释为什么这种简单的方法没有得到更广泛的使用。为此,本文为 JBU 中使用的空间自适应内核提供了高效的 CUDA 实现。与使用 torch.nn.Unfold 运算符的简单实现相比,改进操作使用的内存减少了两个数量级,并且推理速度提高了 10 倍。
基于隐式神经网络的图像特定的上采样器
这在过度拟合单个图像时可以产生非常清晰的特征。通过使用隐式函数 F h r = M L P ( z ) F_{hr}=MLP(z) Fhr=MLP(z) 参数化单个图像的高分辨率特征。一些现有的上采样解决方案也采用这种推理时训练方法,包括 DIP 和 LIIF。这里使用小型 MLP 将图像坐标和强度映射到给定位置的高维特征。遵循先前工作【Implicit Neural Representations with Periodic Activation Functions】的指导,并使用傅里叶特征来提高隐式表示的空间分辨率。除了标准傅里叶位置特征之外,本文也表明添加傅里叶颜色特征允许网络使用原始图像中的高频颜色信息。这显着加快了收敛速度,并能够优雅地使用高分辨率图像信息,而无需使用条件随机场 (CRF) 等技术。
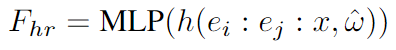
h ( z , ω ^ ) h(z,\hat{\omega}) h(z,ω^) 表示输入信号 z z z 的各个成分的离散傅立叶变换,其中频率向量为 ω ^ \hat{\omega} ω^。 e i e_i ei 和 e j e_j ej 表示范围在区间 [−1, 1] 内的二维像素坐标场。 : : : 表示沿通道维度的拼接。
这里的 MLP 是一个小型 3 层 ReLU 网络,具有 dropout( p = 0.1 p = 0.1 p=0.1)和层归一化。
这一设定可以使得测试时可以查询像素坐标场以产生任何分辨率下的特征。而隐式表示中的参数数量比一个 224×224 的显式表征小两个数量级以上,同时更具表现力,显着减少收敛时间和存储大小。
其他细节
使用特征压缩加速训练
- 为了减少内存占用并进一步加速 FeatUp 隐式网络的训练,本文首先将空间变化的特征压缩到其最大的 k = 128 k=128 k=128 个主成分。此操作几乎是无损的,因为前 128 个分量解释了单个图像特征中 96% 的方差。这将 ResNet-50 的训练时间缩短了 60 倍,减少了内存占用,支持更大的批次,并且对学习的特征质量没有任何明显的影响。
- 在训练 JBU 上采样器时,在每个批次中对随机投影矩阵进行采样来降维,以避免在内循环中计算 PCA。得益于 Johnson–Lindenstrauss 引理 (让人惊叹的Johnson-Lindenstrauss引理:理论篇 - 科学空间|Scientific Spaces),这可以达到相同的效果。
总变分先验
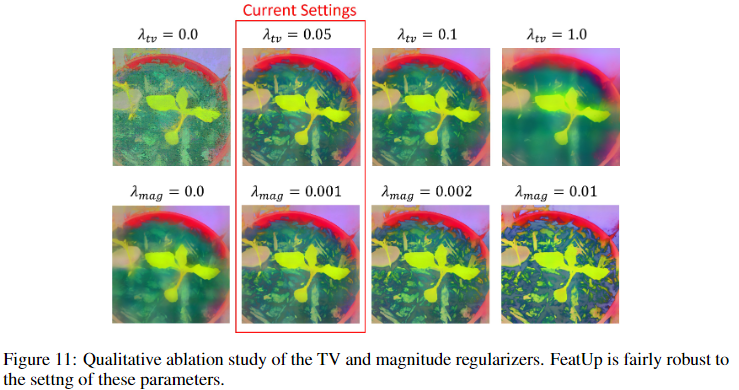
为了避免高分辨率特征中的杂散噪声,在隐式特征量值上添加一个小的 ( λ t v = 0.05 \lambda_{tv}=0.05 λtv=0.05) 总变分平滑先验:

这比正则化完整特征更快,并且避免过度规定各个组件的组织方式。注意不在 JBU 上采样器中使用它,因为此时不会受到过度拟合的影响。
实验结果

![Github profile Readme实现小游戏[github自述游戏]](https://img-blog.csdnimg.cn/direct/ad06cdac18964627b576b485190dbc3a.png)