案例 6:图像自然语言描述生成(让计算机“看图说话”)
相关知识点:RNN、Attention 机制、图像和文本数据的处理
1 任务目标
1.1 任务和数据简介
本次案例将使用深度学习技术来完成图像自然语言描述生成任务,输入一张图片,模型会给出关于图片内容的语言描述。本案例使用 coco2014 数据集[1],包含 82,783 张训练图片,40,504 张验证图片,40,775 张测试图片。案例使用 Andrej Karpathy[2]提供的数据集划分方式和图片标注信息,案例已提供数据处理的脚本,只需下载数据集和划分方式即可。
图像自然语言描述生成任务一般采用 Encoder-Decoder 的网络结构,Encoder 采用 CNN 结构,对输入图片进行编码,Decoder 采用 RNN 结构,利用 Encoder 编码信息,逐个单词的解码文字描述输出。模型评估指标采用 BLEU 分数[3],用来衡量预测和标签两句话的一致程度,具体计算方法可自行学习,案例已提供计算代码。
1.2 方法描述
-
模型输入
图像统一到 256×256 大小,并且归一化到[−1,1]后还要对图像进行 RGB 三通道均值和标准差的标准化。语言描述标签信息既要作为目标标签,也要作为 Decoder 的输入,以
<start>开始,<end>结束并且需要拓展到统一长度,例如:< 𝑠𝑡𝑎𝑟𝑡 > 𝑎 𝑡𝑎𝑏𝑙𝑒 𝑡𝑜𝑝𝑝𝑒𝑑 𝑤𝑖𝑡ℎ 𝑝𝑙𝑎𝑡𝑒𝑠 𝑜𝑓 𝑓𝑜𝑜𝑑 𝑎𝑛𝑑 𝑑𝑟𝑖𝑛𝑘𝑠 < 𝑒𝑛𝑑 > < 𝑝𝑎𝑑 > < 𝑝𝑎𝑑 >< 𝑝𝑎𝑑 > ⋯ 每个 token 按照词汇表转为相应的整数。同时还需要输入描述语言的长度, 具体为单词数加
2(<start>,<end>),目的是为了节省在<pad>上的计算时间。 -
Encoder
案例使用
ResNet101网络作为编码器,去除最后Pooling和Fc两层,并添加 了AdaptiveAvgPool2d()层来得到固定大小的编码结果。编码器已在 ImageNet 上预训练好,在本案例中可以选择对其进行微调以得到更好的结果。 -
Decoder
Decoder 是本案例中着重要求的内容。案例要求实现两种 Decoder 方式,分别对应这两篇文章[4][5]。在此简要阐述两种 Decoder 方法,进一步学习可参考原文章。
第一种 Decoder 是用 RNN 结构来进行解码,解码单元可选择 RNN、LSTM、GRU 中的一种,初始的隐藏状态和单元状态可以由编码结果经过一层全连接层并做批归一化 (Batch Normalization) 后作为解码单元输入得到,后续的每个解码单元的输入为单词经过
word embedding后的编码结果、上一层的隐藏状态和单元状态,解码输出经过全连接层和 Softmax 后得到一个在所有词汇上的概率分布,并由此得到下一个单词。Decoder 解码使用到了teacher forcing机制,每一时间步解码时的输入单词为标签单词,而非上一步解码出来的预测单词。训练时,经过与输入相同步长的解码之后,计算预测和标签之间的交叉熵损失,进行 BP 反传更新参数即可。测试时由于不提供标签信息,解码单元每一时间步输入单词为上一步解码预测的单词,直到解码出信息。测试时可以采用beam search解码方法来得到更准确的语言描述,具体方法可自行学习。 第二种 Decoder 是用 RNN 加上 Attention 机制来进行解码,Attention 机制做的是生成一组权重,对需要关注的部分给予较高的权重,对不需要关注的部分给 予较低的权重。当生成某个特定的单词时,Attention 给出的权重较高的部分会在图像中该单词对应的特定区域,即该单词主要是由这片区域对应的特征生成的。 Attention 权重的计算方法为:
α = softmax ( f c ( relu ( f c ( encoder_ouput ) + f c ( h ) ) ) ) \alpha = \text{softmax} (fc(\text{relu}(fc(\text{encoder\_ouput})+fc(h)))) α=softmax(fc(relu(fc(encoder_ouput)+fc(h))))
其中 softmax \text{softmax} softmax 表示 Softmax 函数, f c ( ) fc() fc() 表示全连接层, r e l u ( ) relu() relu() 表示 ReLU 激活函数, encoder_ouput \text{encoder\_ouput} encoder_ouput 是编码器的编码结果, h h h 是上一步的隐藏状态。初始的隐藏状态和单元状态由编码结果分别经过两个全连接层得到。每一时间步解码单元的 输入除了上一步的隐藏状态和单元状态外,还有一个向量,该向量由单词经过word embedding后的结果和编码器编码结果乘上注意力权重再经过一层全连接层后的结果拼接而成。解码器同样使用teacher forcing机制,训练和测试时的流程与第一种 Decoder 描述的一致。 -
样例输出
第一种 Decoder 得到的结果仅包含图像的文字描述,如下图:

第二种 Decoder 由于有 Attention 机制的存在,可以得到每个单词对应的图片区域,如下图:

1.3 参考程序及使用说明
本次案例提供了完整、可供运行的参考程序,各程序简介如下:
create_input_files.py: 下载好数据集和划分方式后需要运行该脚本文件,会生成案例需要的json和hdf5文件,注意指定输入和输出数据存放的位置。datasets.py: 定义符合 pytorch 标准的 Dataset 类,供数据按 Batch 读入。models.py: 定义 Encoder 和 Decoder 网络结构,其中 Encoder 已提前定义好,无需自己实现。两种 Decoder 方法需要自行实现,已提供部分代码,只需将#ToDo部分补充完全即可。solver.py: 定义了训练和验证函数,供模型训练使用。train.ipynb: 用于训练的 jupyter 文件,其中超参数需要自行调节,训练过程中可以看到模型准确率和损失的变化,并可以得到每个 epoch 后模型在验证集上的 BLEU 分数,保存最优的验证结果对应的模型用于测试。test.ipynb: 用于测试的 jupyter 文件,加载指定的模型,解码时不使用teacher forcing,并使用beam search的解码方法,最终会得到模型在测试集上的 BLEU 分数。caption.ipynb: 加载指定模型,对单张输入图片进行语言描述,第一种 Decoder 方法只能得到用于描述的语句,第二种 Decoder 方法同时可以获取每个 单词对应的注意力权重,最后对结果进行可视化。utils.py: 定义一些可能需要用到的函数,如计算准确率、图像可视化等。
环境要求:python 包 pytorch, torchvision, numpy, nltk, tqdm, h5py, json, PIL, matplotlib, scikit-image, scipy=1.1.0 等。
1.4 要求与建议
- 完成
models.py文件中的#ToDo部分,可参考第 2 部分中的介绍或原论文; - 调节超参数,运行
train.ipynb,其中 attention 参数指示使用哪种Decoder,分别训练使用两种不同 Decoder 的模型,可以分两个 jupyter 文件保存最佳参数和训练记录,如train1.ipynb,train2.ipynb; - 运行
test.ipynb得到两个模型在测试集上的 BLEU 分数,分别保留结果; - 选择一张图片,可以是测试集中的,也可以是自行挑选的,对图片进行语言描述自动生成,分别保留可视化结果;
- 在参考程序的基础上,综合使用深度学习各项技术,尝试提升该模型在图像自然语言描述生成任务上的效果,如使用更好的预训练模型作为 Encoder, 或者提出更好的 Decoder 结构,如 Adaptive Attention 等;
- 完成一个实验报告,内容包括基础两个模型的实现原理说明、两个模型的最佳参数和对应测试集 BLEU 分数、两个模型在单个图片上的表现效果、自己所做的改进、对比分析两个基础模型结果的不同优劣。
- 禁止任何形式的抄袭,借鉴开源程序务必加以说明。
1.5 参考资料
[1] MS-COCO 数据集: https://cocodataset.org/
[2] 划分方式与 caption 信息: http://cs.stanford.edu/people/karpathy/deepimagesent/caption_datasets.zip
[3] https://en.wikipedia.org/wiki/BLEU
[4] Vinyals O, Toshev A, Bengio S, et al. Show and tell: A neural image caption generator[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3156-3164.
[5] Xu K, Ba J, Kiros R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]//International conference on machine learning. 2015: 2048-2057
2 采用无 Attention 机制的 Decoder 训练
2.1 代码补全
实验提供的代码中,model.py 中的 DecoderWithRNN(nn.Moulde) 类需要补全,才能进行训练。以下补全的代码部分。
-
定义 Decoder 需要的层
- 嵌入层 (
self.embedding):用于将单词的索引转换为连续的向量表示。矩阵行数为词汇表的大小vocab_size,列数为每个单词嵌入的维度embed_dim。 - LSTMCell 层 (
self.decode_step):一种循环神经网络(RNN)的组件,用于处理序列数据。输入大小与隐藏大小都为decoder_dim。 - 线性层 (
self.init):用于学习输入和输出之间的线性关系。输入特征的数量为encoder_dim,输出特征的数量为decoder_dim。 - 批量归一化层 (
self.bn):用于提高训练过程的稳定性和性能。过规范化层的输入来减少内部协变量偏移。 - 全连接层 (
self.fc):用于将解码器的隐藏状态转换为对词汇表中每个单词的分数。输入是解码器的隐藏状态维度sdecoder_dim,输出是词汇表的大小vocab_size。 - Dropout 层 (
self.dropout):通过 Dropout 防止过拟合。
# 嵌入层 self.embedding = nn.Embedding(self.vocab_size, self.embed_dim) # LSTMCell 层 self.decode_step = nn.LSTMCell(self.decoder_dim, self.decoder_dim) # 线性层 self.init = nn.Linear(self.encoder_dim, self.decoder_dim) # 批量归一化层 self.bn = nn.BatchNorm1d(self.decoder_dim) # 全连接层 self.fc = nn.Linear(self.decoder_dim, self.vocab_size) # Dropout 层 self.dropout = nn.Dropout(self.dropout) - 嵌入层 (
-
解码器前向传播 (
forward)采用Teacher forcing,在每个时间步,使用前一个词嵌入在解码器中生成一个新单词。
- 计算
num来确定在当前时间步t还有哪些序列需要继续生成新的单词。 - 从
embeddings张量中选择当前时间步t的有效嵌入表示。 - 调用
self.one_step函数来生成预测preds并更新 LSTM 状态h和c。
for t in range(max(decode_lengths)):num = sum([1 if l > t else 0 for l in decode_lengths])preds, h, c = self.one_step(embeddings[:num,t,:], h[:num], c[:num])predictions[:num,t,:] = preds - 计算
-
单步解码 (
one_step)该代码是序列生成模型中用于执行单步解码操作的实现。
- 调用 LSTM 细胞层
self.decode_step,进行前向传播。 - 通过正则化技术,将 LSTM 细胞的输出
h传递给self.dropout层,用于减少过拟合。 - 通过
self.fc(全连接层)将 dropout 后的输出转换为对词汇表中每个单词的预测分数。
def one_step(self, embeddings, h, c):h, c = self.decode_step(embeddings, (h, c))preds = self.fc(self.dropout(h))return preds, h, c - 调用 LSTM 细胞层
2.2 项目训练
本次实验采用MS-COCO 数据集进行训练,由于数据量过于庞大,所以仍然选择通过云平台训练。
-
MS-COCO 数据集
MS-COCO(Microsoft Common Objects in Context Dataset)是一个大规模的图像识别、分割和描述的数据集,由微软研究院于2014年发布。

{"images": [{"filepath": "val2014", "sentids": [770337, 771687, 772707, 776154, 781998], "filename": "COCO_val2014_000000391895.jpg", "imgid": 0, "split": "test", "sentences": [{"tokens": ["a", "man", "with", "a", "red", "helmet", "on", "a", "small", "moped", "on", "a", "dirt", "road"], "raw": "A man with a red helmet on a small moped on a dirt road. ", "imgid": 0, "sentid": 770337}, {"tokens": ["man", "riding", "a", "motor", "bike", "on", "a", "dirt", "road", "on", "the", "countryside"], "raw": "Man riding a motor bike on a dirt road on the countryside.", "imgid": 0, "sentid": 771687}, {"tokens": ["a", "man", "riding", "on", "the", "back", "of", "a", "motorcycle"], "raw": "A man riding on the back of a motorcycle.", "imgid": 0, "sentid": 772707}, {"tokens": ["a", "dirt", "path", "with", "a", "young", "person", "on", "a", "motor", "bike", "rests", "to", "the", "foreground", "of", "a", "verdant", "area", "with", "a", "bridge", "and", "a", "background", "of", "cloud", "wreathed", "mountains"], "raw": "A dirt path with a young person on a motor bike rests to the foreground of a verdant area with a bridge and a background of cloud-wreathed mountains. ", "imgid": 0, "sentid": 776154}, {"tokens": ["a", "man", "in", "a", "red", "shirt", "and", "a", "red", "hat", "is", "on", "a", "motorcycle", "on", "a", "hill", "side"], "raw": "A man in a red shirt and a red hat is on a motorcycle on a hill side.", "imgid": 0, "sentid": 781998}], "cocoid": 391895}...以上为 COCO 数据集的 json 文件,可以看到每个图片包含以下内容:
"filepath": "val2014": 表示图像所在的文件夹路径。"sentids": [770337, 771687, 772707, 776154, 781998]: 这是一个句子 ID 列表,每个 ID 对应一个描述该图像的句子。"filename": "COCO_val2014_000000391895.jpg": 图像的文件名。"imgid": 0: 图像的唯一标识符(image ID),在这里被设置为 0。"split": "test": 表示这张图像属于数据集的测试集(test set)。"sentences": 这是一个句子列表,每个句子都是对图像的描述。- 每个句子都有一个
"tokens"属性,它是一个包含描述中单词的列表(已经分词)。 "raw"属性包含了原始的描述句子(未经分词的完整句子)。"imgid"和"sentid"分别是图像 ID 和句子 ID,用于关联特定的图像和描述。
- 每个句子都有一个
"cocoid": 391895: 这是图像在 COCO 数据集中的唯一标识符。
-
云平台环境创建
通过 Fork 作业,创建环境,镜像为
Cuda11.3.1 PyTorch 1.10.2 Tensorflow2.8.0 Python 3.7。注意本次训练需生成大量文件,所以需要挂载 work 文件夹,用于存储数据文件。通过
train.ipynb中以下代码,配置环境。!pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple !pip install -U nltk通过以下代码,组合数据集。
!mkdir /home/mw/project/coco2014 !ln -s /home/mw/input/020614521/test2014/test2014 /home/mw/project/coco2014 !ln -s /home/mw/input/02066579/val2014/* /home/mw/project/coco2014 !ln -s /home/mw/input/020628093/train2014-1/train2014-1 /home/mw/project/coco2014 !ln -s /home/mw/input/020631458/train2014-2/train2014-2 /home/mw/project/coco2014 -
配置数据集文件
修改
create_input_files.py文件内容,更改输入输出文件路径。if __name__ == '__main__':# Create input files (along with word map)create_input_files(dataset='coco',karpathy_json_path='/home/mw/project/coco2014/dataset_coco.json', # downloaded from http://cs.stanford.edu/people/karpathy/deepimagesent/caption_datasets.zipimage_folder='/home/mw/project/coco2014/',captions_per_image=5,min_word_freq=5,output_folder='/home/mw/work/work_dir/coco/',max_len=50)通过以下指令,运行
create_input_files.py脚本文件,生成需要的json和hdf5文件,注意指定输入和输出数据存放的位置。%cp /home/mw/project !python create_input_files.py运行成功后,得到以下文件。
TEST_CAPLENS_coco_5_cap_per_img_5_min_word_freq.json TEST_CAPTIONS_coco_5_cap_per_img_5_min_word_freq.json TEST_IMAGES_coco_5_cap_per_img_5_min_word_freq.hdf5 TRAIN_CAPLENS_coco_5_cap_per_img_5_min_word_freq.json TRAIN_CAPTIONS_coco_5_cap_per_img_5_min_word_freq.json TRAIN_IMAGES_coco_5_cap_per_img_5_min_word_freq.hdf5 VAL_CAPLENS_coco_5_cap_per_img_5_min_word_freq.json VAL_CAPTIONS_coco_5_cap_per_img_5_min_word_freq.json VAL_IMAGES_coco_5_cap_per_img_5_min_word_freq.hdf5 WORDMAP_coco_5_cap_per_img_5_min_word_freq.json -
修改配置信息
修改
cfg内容,配置训练路径。如果中间训练中断,可以通过修改checkpoint路径来继续之前的训练。cfg = {# Data parameters'data_folder' : '/home/mw/work/work_dir/coco/', 'data_name' : 'coco_5_cap_per_img_5_min_word_freq', # base name shared by data files# Model parameters'embed_dim' : 512, # dimension of word embeddings'attention_dim' : 512, # dimension of attention linear layers'decoder_dim' : 512, # dimension of decoder RNN'dropout' : 0.5,'device' : torch.device("cuda:0" if torch.cuda.is_available() else "cpu"), # sets device for model and PyTorch tensors# Training parameters'start_epoch' : 0,'epochs' : 10, # number of epochs to train for (if early stopping is not triggered)'epochs_since_improvement' : 0, # keeps track of number of epochs since there's been an improvement in validation BLEU'batch_size' : 32,'workers' : 1, # for data-loading; right now, only 1 works with h5py'encoder_lr' : 1e-4, # learning rate for encoder if fine-tuning'decoder_lr' : 4e-4, # learning rate for decoder'grad_clip' : 5., # clip gradients at an absolute value of'alpha_c' : 1., # regularization parameter for 'doubly stochastic attention', as in the paper'best_bleu4' : 0., # BLEU-4 score right now'print_freq' : 100, # print training/validation stats every __ batches'fine_tune_encoder' : False, # fine-tune encoder or not'checkpoint' : None, # path to checkpoint, None if none'attention' : False, # train decoder with attention or not } cudnn.benchmark = True # set to true only if inputs to model are fixed size; otherwise lot of computational overhead -
开始训练
运行
train.ipynb的全部代码,开始训练。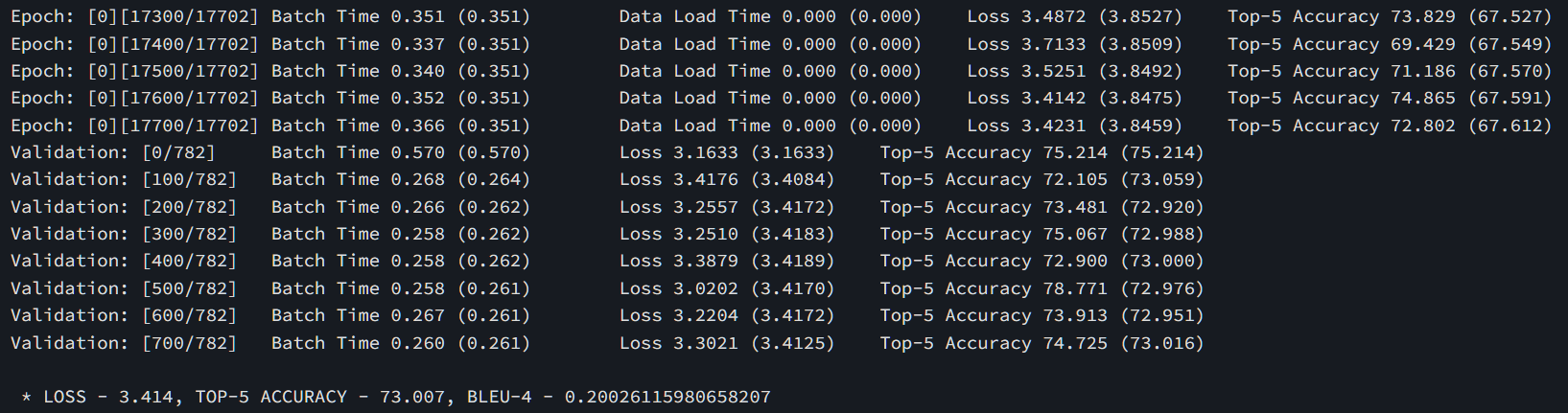
出现以上信息,说明成功开始训练,每轮训练结束会进行验证集验证,并生成两个 checkpoint 文件:
BEST_checkpoint_NoAttention.pth.tar checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar代表着训练最佳的模型,与训练记录。
每轮的训练结果如下:
* LOSS - 2.561, TOP-5 ACCURACY - 72.468, BLEU-4 - 0.19211562851102434 * LOSS - 2.444, TOP-5 ACCURACY - 74.052, BLEU-4 - 0.206167972668384 * LOSS - 2.397, TOP-5 ACCURACY - 74.702, BLEU-4 - 0.21208995512435172 * LOSS - 2.375, TOP-5 ACCURACY - 75.007, BLEU-4 - 0.2132522999078148 * LOSS - 2.361, TOP-5 ACCURACY - 75.335, BLEU-4 - 0.21634075906470107 * LOSS - 2.356, TOP-5 ACCURACY - 75.334, BLEU-4 - 0.21701614735505384 * LOSS - 2.350, TOP-5 ACCURACY - 75.414, BLEU-4 - 0.21586192777255203 * LOSS - 2.352, TOP-5 ACCURACY - 75.464, BLEU-4 - 0.21914566402602026 * LOSS - 2.353, TOP-5 ACCURACY - 75.423, BLEU-4 - 0.2185600676157566 * LOSS - 2.351, TOP-5 ACCURACY - 75.542, BLEU-4 - 0.21694456413193874
2.3 项目测试
-
模型评估
修改数据集地址后,运行
test.ipynb,进行测试。测试采用 BLUE-4 参数进行模型评估。BLUE-4 旨在提供对线性模型参数的最佳估计,以便它们是线性、无偏、具有最小方差。具体来说,BLUE-4 的估计量通过以下公式计算:
β ^ B L U E − 4 = ( X T W X ) − 1 X T W y \hat{\beta}_{BLUE-4} = (X^TWX)^{-1} X^TWy β^BLUE−4=(XTWX)−1XTWy
其中:- β ^ B L U E − 4 \hat{\beta}_{BLUE-4} β^BLUE−4 是参数向量的估计值。
- X X X 是设计矩阵(包含自变量的观察值)。
- Y Y Y 是响应向量(因变量的观察值)。
- W W W 是加权矩阵,用于处理异方差和/或自相关的问题。
在 BLUE-4 中, W W W 的选择对估计结果至关重要。通常情况下, W W W 被选择为方差-协方差矩阵的逆矩阵,其中方差-协方差矩阵包含了误差项的方差和协方差信息。通过适当地选择 W W W,可以消除异方差和自相关的影响,从而产生更稳健、更高效的估计结果。
总之,BLUE-4 提供了对线性模型参数的最佳估计,即它们是线性、无偏、具有最小方差的估计。通过适当地选择加权矩阵 W W W ,可以解决模型中可能存在的异方差和自相关问题。
不采用 Attention 机制训练结果,在 25000 张测试集结果为
BLUE-4 = 0.2671296429923623。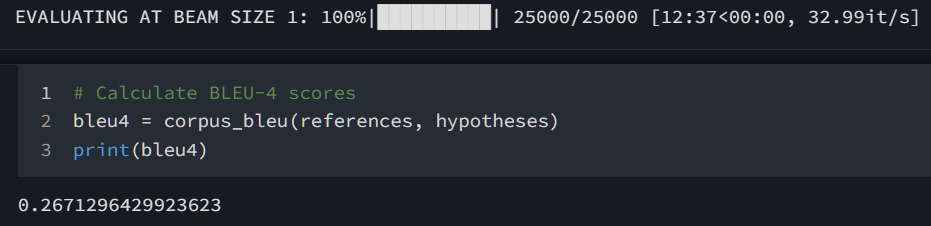
-
图像输出
通过
caption.ipynb加载指定模型,对单张输入图片进行语言描述。对测试集图片COCO_test2014_000000438031结果如下。
可以看到模型形容这张图片内容为 “a table that has some food on it”,较为准确的描述了图片内容。
上传一张图片,测试模型的性能,发现面对在训练集没有出现的东西,模型是不认识的。

模型错误的将月球上的宇航员,认成了 “a white dog laying on top of a surfboard”,一只白色的狗躺在冲浪板上。
3 采用带有 Attention 机制的 Decoder 训练
3.1 代码补全
本部分需要补全 Attention(nn.Module) 与 DecoderWithAttention(nn.Module) 的 TODO 部分代码。
-
定义
Attention需要的层注意力模块定义了三个线性层,它们负责转换编码器与解码器的维度,与将注意力维度转换成一个一位输出。
def __init__(self, encoder_dim, decoder_dim, attention_dim):super(Attention, self).__init__()self.encoder_att = nn.Linear(encoder_dim, attention_dim)self.decoder_att = nn.Linear(decoder_dim, attention_dim)self.att = nn.Linear(attention_dim, 1) -
注意力模块前向传播
这段代码过注意力机制,结合编码器和解码器的信息,动态地生成了一个加权的上下文表示
z,这个表示将被用于解码器生成序列的下一个词。注意力权重alpha显示了每个特征对当前生成词的贡献程度。def forward(self, encoder_out, decoder_hidden):att1 = self.encoder_att(encoder_out)att2 = self.decoder_att(decoder_hidden).unsqueeze(1)e = self.att(F.relu(att1 + att2))alpha = F.softmax(e, dim=1)z = (encoder_out * alpha).sum(dim=1)return z, alpha -
定义
DecoderWithAttention需要的层- 注意力机制模块:将编码器输出的特征维度(encoder_dim),解码器隐藏状态的维度(decoder_dim),以及注意力网络的内部维度(attention_dim)作为参数。
- 嵌入层:将词汇表中的单词索引映射到嵌入空间中的向量表示。
- 解码器 LSTM 细胞:将嵌入层的输出与编码器提供的上下文向量结合起来,并输出解码器的下一个隐藏状态。
- 线性层h:用于初始化解码器的隐藏状态。它的输入是编码器的输出,输出维度与解码器的隐藏状态维度相匹配。
- 线性层c:用于初始化解码器的单元状态。结构和目的与 init_h 类似。
- Sigmoid 激活函数层:用于生成权重 beta,这个权重通常用于控制注意力机制的输出,在解码器的隐藏状态中的影响。
- 全连接层:将解码器的隐藏状态映射到词汇表上的概率分布。
- Dropout 层:用于在训练过程中随机丢弃一些神经元的输出,以减少过拟合。
# 注意力模块 self.attention = Attention(encoder_dim, self.decoder_dim, self.attention_dim) # 嵌入层 self.embedding = nn.Embedding(self.vocab_size, self.embed_dim) # 解码器 LSTM 细胞 self.decode_step = nn.LSTMCell(self.embed_dim + self.encoder_dim, self.decoder_dim) # 线性层h,用于初始化解码器的隐藏状态 self.init_h = nn.Linear(self.encoder_dim, self.decoder_dim) # 线性层c,用于初始化解码器的单元状态 self.init_c = nn.Linear(self.encoder_dim, self.decoder_dim) # Sigmoid 激活函数层 self.beta = nn.Sigmoid() # 全连接层 self.fc = nn.Linear(self.decoder_dim, self.vocab_size) # Dropout 层 self.dropout = nn.Dropout(p=self.dropout) -
解码器前向传播(
forward)遍历解码过程的每个时间步,在每个时间步生成一个单词,并更新其内部状态。注意力权重
alpha显示了模型在生成每个单词时对输入序列的不同部分的关注程度。for t in range(max(decode_lengths)):num = sum([1 if l > t else 0 for l in decode_lengths])preds, alpha, h, c = self.one_step(embeddings[:num, t, :], encoder_out[:num], h[:num], c[:num])predictions[:num,t,:] = predsalphas[:num,t,:] = alpha -
单步解码 (
one_step)self.attention(encoder_out, h): 通过注意力机制计算得到上下文向量z和注意力权重alpha。F.sigmoid(self.f_beta(h)): 计算一个调整因子beta,它用于调整上下文向量z的影响。torch.cat([embeddings, z], dim=1): 将当前时间步的嵌入向量embeddings和调整后的上下文向量z拼接起来,作为 LSTM 细胞的输入。self.decode_step(...): 调用 LSTM 细胞来更新隐藏状态h和单元状态c。self.fc(h): 将更新后的隐藏状态h通过一个全连接层来生成预测分数preds,这些分数表示模型对下一个单词的预测。self.dropout(h): 应用 Dropout 正则化技术于隐藏状态h,以减少过拟合的风险。
def one_step(self, embeddings, encoder_out, h, c):z, alpha = self.attention(encoder_out, h)beta = F.sigmoid(self.f_beta(h))z = beta * zh, c = self.decode_step(torch.cat([embeddings,z], dim=1),(h,c))preds = self.fc(self.dropout(h))return preds, alpha, h, c
3.2 项目训练
修改 train.ipynb 的配置文件,将 attention 改为 True,开始训练,训练时长比不用注意力机制更长,进行了20多个小时的训练,完成10轮的训练,最后一轮的验证结果如下。
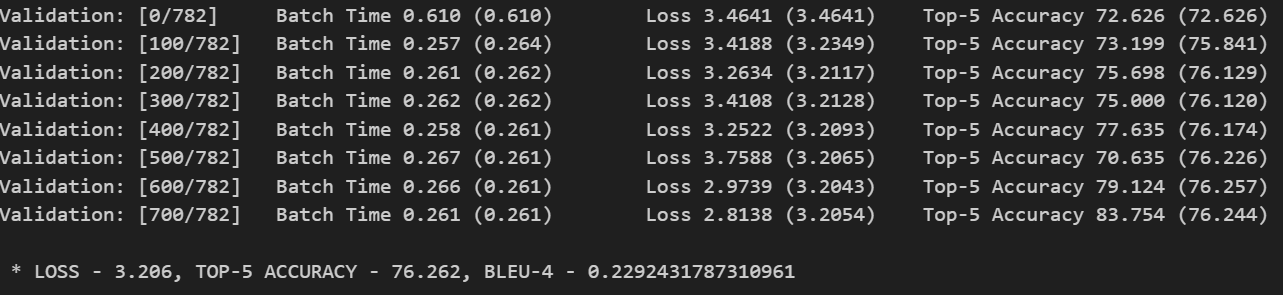
每轮的训练结果如下:
* LOSS - 3.414, TOP-5 ACCURACY - 73.007, BLEU-4 - 0.20026115980658207* LOSS - 3.305, TOP-5 ACCURACY - 74.551, BLEU-4 - 0.2129326655784661* LOSS - 3.258, TOP-5 ACCURACY - 75.256, BLEU-4 - 0.220877622883263* LOSS - 3.234, TOP-5 ACCURACY - 75.598, BLEU-4 - 0.2232005371638974* LOSS - 3.219, TOP-5 ACCURACY - 75.904, BLEU-4 - 0.22577627017891636* LOSS - 3.209, TOP-5 ACCURACY - 76.118, BLEU-4 - 0.22701703762313327* LOSS - 3.207, TOP-5 ACCURACY - 76.132, BLEU-4 - 0.22905155826158327* LOSS - 3.208, TOP-5 ACCURACY - 76.158, BLEU-4 - 0.23044049990411558* LOSS - 3.206, TOP-5 ACCURACY - 76.249, BLEU-4 - 0.23045871177259478* LOSS - 3.206, TOP-5 ACCURACY - 76.262, BLEU-4 - 0.2292431787310961
3.3 项目测试
-
模型评估
运行
test.ipynb,进行测试。测试采用 BLUE-4 参数进行模型评估。结果如下。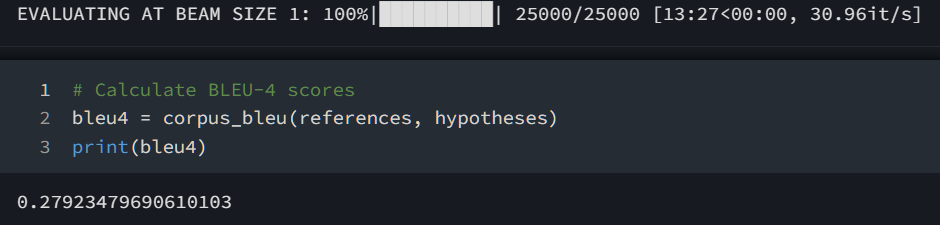
BLUE-4 值达到
0.27923479690610103,效果优于不用attention机制的结果。 -
图像输出
通过
caption.ipynb加载指定模型,并令attention为True,对单张输入图片进行语言描述。对测试集图片COCO_test2014_000000438031结果如下。

可以看到,结果显示出来了自然语言的单词的注意力在图像的哪里。
对
COCO_test2014_000000049721.jpg图片进行测试,结果如下。

可以看到模型精准的描述了图像信息,用一个长句子描述出了菜板上胡萝卜特写的图像信息。
4 模型调优
4.1 Adaptive Attention
Adaptive Attention,或称为自适应注意力,是一种在神经网络序列到序列(seq2seq)模型中使用的注意力机制。与传统的注意力机制相比,自适应注意力允许模型在不同的时间步动态调整其关注输入序列的哪些部分。这种机制特别适用于处理长序列数据,如自然语言处理中的长文本,或者图像描述任务中的多区域图像。
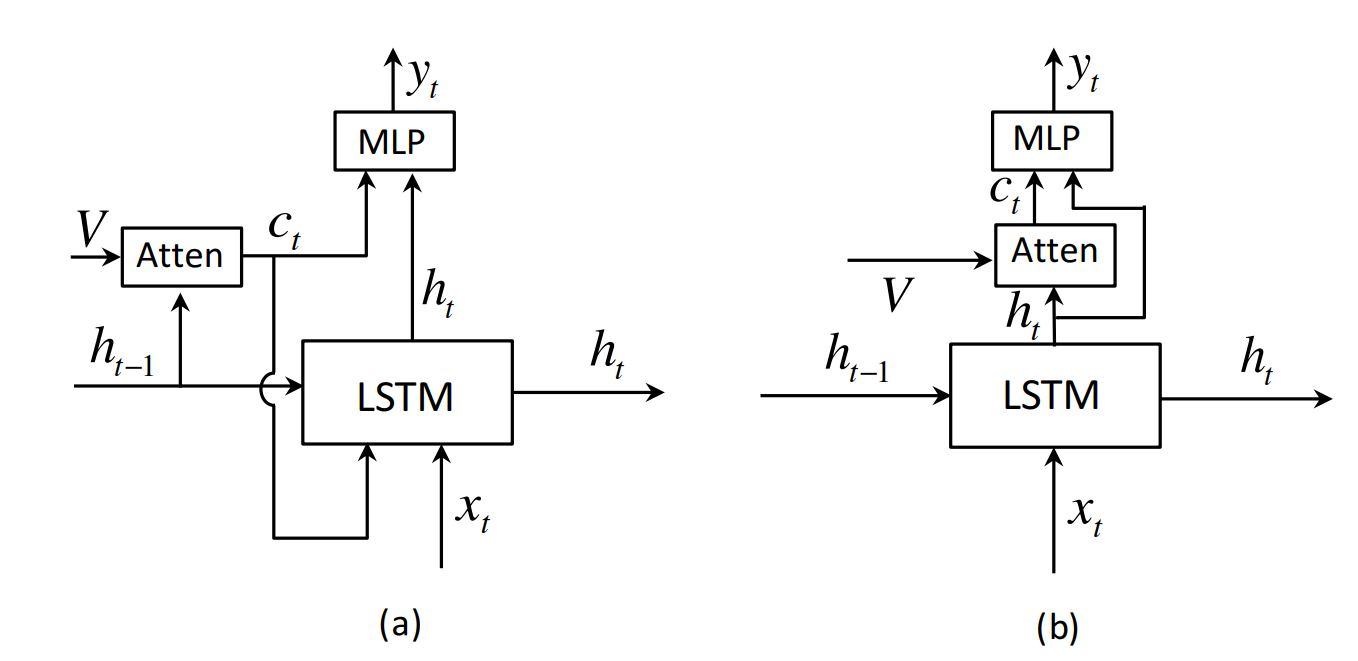
图(a)为普通注意力机制的架构,图(b)为作者改进后的架构。

详细信息查看论文 Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
以及github仓库:jiasenlu/AdaptiveAttention: Implementation of “Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning” (github.com)
-
工作原理
- 输入序列编码:首先,输入序列(例如,一句话或一张图像)被编码成一个固定长度的上下文向量或者一系列的隐藏状态。
- 动态权重分配:在解码过程中,自适应注意力机制会根据解码器当前的状态和已经生成的输出动态计算注意力权重。这意味着在每个解码步骤,模型都会重新评估并分配对输入序列不同部分的关注程度。
- 上下文向量调整:根据计算出的注意力权重,模型调整(加权平均)输入序列的隐藏状态,以生成一个新的上下文向量,这个向量更加关注当前步骤最相关的信息。
- 解码器更新:使用调整后的上下文向量,解码器生成下一个输出(例如,下一个单词或下一个字符)。
-
优势
- 灵活性:自适应注意力机制提供了更大的灵活性,因为它允许模型根据当前的解码状态来调整其关注点,而不是在整个序列中均匀地分配注意力。
- 减少信息冗余:通过关注与当前任务最相关的信息,自适应注意力有助于减少无关信息的干扰,从而提高模型的性能。
- 处理长序列:对于长序列,自适应注意力特别有效,因为它可以避免在解码过程中重复使用相同的信息。
-
实现
作者采用
lua进行代码的编写,我未能成功移植 Adaptive Attention 代码,最终没能实现
4.2 fine_tune_encoder
-
fine_tune
令配置中
fine_tune_encoder为True,Fine-tuning是一种训练策略,指的是在预训练模型的基础上进行额外的训练,以使模型更好地适应特定的任务或数据集。具体到fine_tune_encoder,这意味着我们将对编码器部分的权重进行微调,以便它能够更好地捕捉到新任务相关的特征。def fine_tune(self, fine_tune=True):"""Allow or prevent the computation of gradients for convolutional blocks 2 through 4 of the encoder.:param fine_tune: boolean"""for p in self.resnet.parameters():p.requires_grad = False# If fine-tuning, only fine-tune convolutional blocks 2 through 4for c in list(self.resnet.children())[5:]:for p in c.parameters():p.requires_grad = fine_tune- 如果
fine_tune是True,那么参数p将被设置为需要计算梯度。这意味着在训练过程中,当反向传播(backpropagation)通过这个参数时,PyTorch将会计算它的梯度,并且在优化步骤中更新它的值。这通常在你想要训练或微调模型参数时进行。 - 如果
fine_tune是False,那么参数p将被设置为不需要计算梯度。这意味着在反向传播过程中,即使这个参数被用于计算损失,它的梯度也不会被计算,因此在优化步骤中它的值也不会被更新。这通常用于冻结模型的某些层,即在训练过程中保持这些层的参数不变。
- 如果
-
项目训练
因为采用
fine tune机制,所以训练时长要更长,每轮训练几乎需要4h时间,但效果有明显提升。实现没有完整的进行10轮的训练,以下为训练4轮的结果。
* LOSS - 3.371, TOP-5 ACCURACY - 73.921, BLEU-4 - 0.21145163883000279 * LOSS - 3.245, TOP-5 ACCURACY - 75.622, BLEU-4 - 0.2242869197515953 * LOSS - 3.197, TOP-5 ACCURACY - 76.253, BLEU-4 - 0.2327172001811528 * LOSS - 3.166, TOP-5 ACCURACY - 76.723, BLEU-4 - 0.23495777605616544 -
项目测试
-
模型评估
运行
test.ipynb,进行测试。测试采用 BLUE-4 参数进行模型评估。经过长时间的测试,结果如下。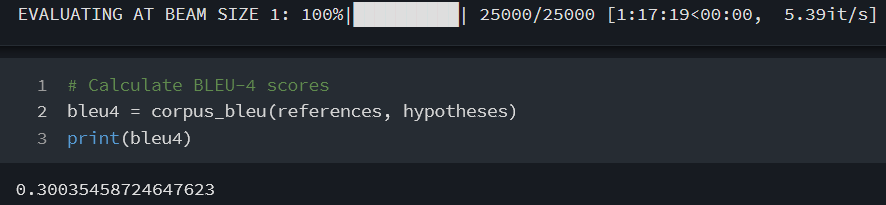
可以看到,
BLUE-4的值达到了0.30035458724647623,远远高于前面两组实验。 -
图像测试
通过
caption.ipynb加载指定模型,并令attention为True,对单张输入图片进行语言描述。对测试集图片COCO_test2014_000000438031结果如下。

可以看到,结果将图片中的内容描述的更加详细了,相比于未使用
fine-tune的描述,增加了对桌子上drinks的形容,说明模型对图像理解能力更强了。对
COCO_test2014_000000049721.jpg图片进行测试,结果如下。

可以看到,相比于未使用
fine tune的结果,该结果对图像的注意力明显更加集中,对图像的描述也更加准确。再次用宇航员登月的图片进行测试,结果如下。


发现虽然模型仍然不认识宇航员,但是能够分辨出来这是个 “小男孩站在沙滩上” 和图片的信息已经十分贴切了,比之前模型将其看成 “小狗站在冲浪板上” 准确了很多。
-
5 结论
本项目进行了3轮训练,分别在无注意力机制,有注意力机制,注意力机制加上fine tune的基础上进行三组训练。三组训练的每轮 loss 、Accuarcy、Blue-4 绘制到折线图上,结果如下。
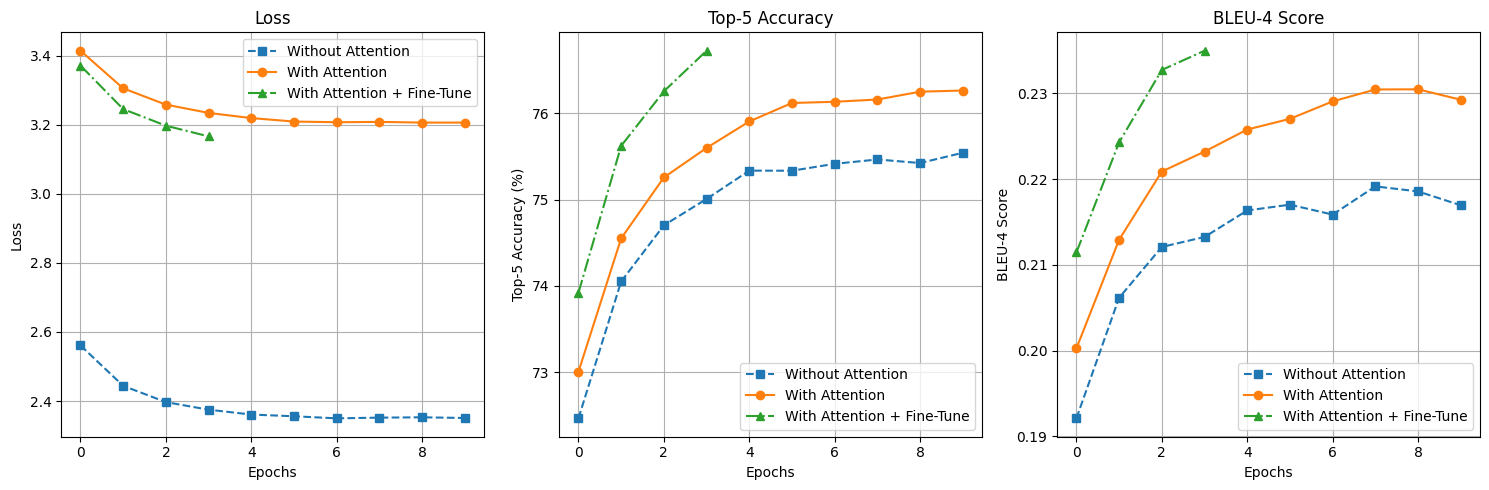
可以看到,添加 fine tune 机制的训练结果,虽然只训练了4轮,但是在 Accuarcy 与 Blue-4 的得分远超另外两组结果。
对比三组模型在测试集的BLUE-4的结果,如下表格。
| Without Attention | With Attention | Attention+fine tune |
|---|---|---|
| 0.2671296429923623 | 0.27923479690610103 | 0.30035458724647623 |
可以看到第三组的 BLUE-4 值远远高于前两组,说明带有fine tune 的编码器对训练有着明显提升。