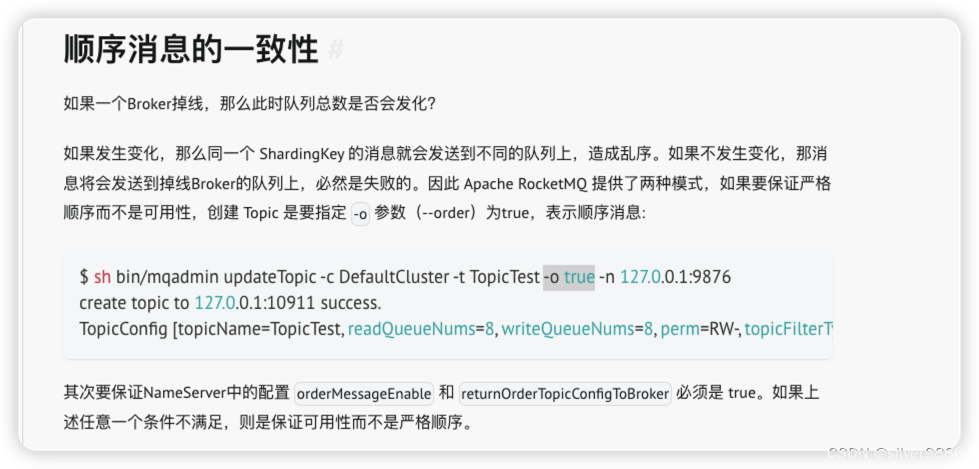
使用deepspeed可能需要注意精度问题

混合精度,LayerNorm
虽然deepspeed有混合精度训练的功能,但是对于网络上各种奇奇怪怪的代码的DIY转化中,他还是很弱小的。它的精度问题,使用deepspeed如果模型中有部分模型使用的是half精度,那么整个模型都会使用half精度,即使是nn.LayerNorm这样新创立的层。因为我们通常可能在计算权重的时候使用half,在LayerNorm的时候使用float32这样更好的归一化,防止 梯度 因为 精度 的问题消失或者爆炸。所以通常建议使用float32精度进行计算。但是这样的强制数据类型转化,在deepspeed中就会因为将模型的全部精度都降低而难以实现。
这个难题可以解决,但是需要特别设置,尤其是原来代码没有这样设置的时候。
class LayerNorm(nn.LayerNorm):def __init__(self, normalized_shape, eps=1e-5, elementwise_affine=True):super(LayerNorm, self).__init__(normalized_shape, eps=eps, elementwise_affine=elementwise_affine)# 确保权重和偏置初始化为float32,即使之后模型转换为fp16if self.elementwise_affine:self.weight.data = self.weight.data.float()self.bias.data = self.bias.data.float()def forward(self, x: torch.Tensor):# print(f"这是是layernorm")# embed()orig_type = x.dtype# ret = super().forward(x.type(torch.float32))ret = super().forward(x)return ret.type(orig_type)
一个很好的检查模型计算精度的方法是将模型的权重精度打印出来,单纯的显示出来模型并不能显示出来计算精度。
def print_model_parameters(model):for name, param in model.named_parameters():print(name, param.size(), id(param))## 我更喜欢使用 .dypte 来直接查看精度
print_model_parameters(your_model_instance)
共享张量(Shared Tensors)
safetensor可并没有那么好,它保存不了某些特别的自定义的共享张量。共享张量是PyTorch中一种用于减少内存使用并提高计算效率的特性。通过共享相同的数据缓冲区,多个张量可以引用相同的内存空间,而不需要复制数据。在transformers模型中,嵌入层(embeddings)和语言模型头(lm_head)经常共享权重,这样做既节省了参数数量,又使得梯度更有效地传播到模型的不同部分。共享向量是很多多模态领域训练的精髓。
共享张量说白了就是模型的参数传递,这种传递是直接赋值,而不是用另一个模型参数去计算。这种现象很常见就是一个张量数据是传递一致的,但是在模型的运算传递多次使用到。
layer1 = nn.Linear(10, 10)
layer2 = nn.Linear(10, 10)# 明确共享layer1的权重和偏置到layer2
layer2.weight = layer1.weight
layer2.bias = layer1.bias
这里报错误实际上和我实例化两个参数有关,实际上可以避免,但是模型原来的设计者可没有想到这一点。
报错的显示
RuntimeError: Some tensors share memory, this will lead to duplicate memory on disk and potential differences when loading them again: [{'encoder_decoder.cmn.linears.0.weight', 'encoder_decoder.model.cmn.linears.0.weight'},{'encoder_decoder.model.cmn.linears.0.bias', 'encoder_decoder.cmn.linears.0.bias'}, {'encoder_decoder.cmn.linears.1.weight', 'encoder_decoder.model.cmn.linears.1.weight'},{'encoder_decoder.cmn.linears.1.bias', 'encoder_decoder.model.cmn.linears.1.bias'}, {'encoder_decoder.model.cmn.linears.2.weight', 'encoder_decoder.cmn.linears.2.weight'}, {'encoder_decoder.cmn.linears.2.bias', 'encoder_decoder.model.cmn.linears.2.bias'}, {'encoder_decoder.cmn.linears.3.weight', 'encoder_decoder.model.cmn.linears.3.weight'},{'encoder_decoder.model.cmn.linears.3.bias', 'encoder_decoder.cmn.linears.3.bias'}].A potential way to correctly save your model is to use `save_model`.More information at https://huggingface.co/docs/safetensors/torch_shared_tensors0%| | 1/410000 [00:34<3883:03:26, 34.10s/it]
使用原始的pytorch存储格式就好使了,而transformers版本大一点的,如4.35,4.36它们在使用transformers.train函数调用自动保存时,保存的结果都是safetensor,但是safetensor应该是为了节约空间,做了一些现在还不完善的处理。导致出现了上面需要显示保存或者修改继承的方式。
安装库错误的问题
需要在集群上经常安装库,在报错的时候,尤其是下面这种,缺乏CUDA编译器的问题,直接使用module ava, load需要的CUDA库往往就能解决问题。
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting deepspeed==0.9.5Downloading https://pypi.tuna.tsinghua.edu.cn/packages/99/0f/a4ebd3b3f6a8fd9bca77ca5f570724f3902ca90b491f8146e45c9733e64f/deepspeed-0.9.5.tar.gz (809 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 809.9/809.9 kB 2.9 MB/s eta 0:00:00Preparing metadata (setup.py) ... errorerror: subprocess-exited-with-error× python setup.py egg_info did not run successfully.│ exit code: 1╰─> [8 lines of output]Traceback (most recent call last):File "<string>", line 2, in <module>File "<pip-setuptools-caller>", line 34, in <module>File "/tmp/pip-install-uc05hpfj/deepspeed_b69d07d91ac4496684f65ba796150c78/setup.py", line 82, in <module>cuda_major_ver, cuda_minor_ver = installed_cuda_version()File "/tmp/pip-install-uc05hpfj/deepspeed_b69d07d91ac4496684f65ba796150c78/op_builder/builder.py", line 41, in installed_cuda_versionassert cuda_home is not None, "CUDA_HOME does not exist, unable to compile CUDA op(s)"AssertionError: CUDA_HOME does not exist, unable to compile CUDA op(s)[end of output]note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed× Encountered error while generating package metadata.
╰─> See above for output.note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
module ava
module load cuda/7/11.8