概述
考虑到我上一篇文章中的材料,我赫兹量化软件可以说这只是我在算法中引入的所有函数的肤浅描述。它们不仅涉及EA创建的完全自动化,还涉及诸如结果优化和选择的完全自动化以及随后用于自动交易,或者我赫兹量化稍后将展示的更先进的EA的创建等重要函数。
由于交易终端、通用EA和算法本身的共生关系,您可以完全摆脱手动开发,或者在最坏的情况下,只要您具备必要的计算能力,就可以将可能改进的劳动强度降低一个数量级。在这篇文章中,我将开始描述这些创新最重要的方面。
常规过程
对我来说,随着时间的推移,创建和随后修改此类解决方案的最重要因素是了解确保常规操作最大限度自动化的可能性。在这种情况下,常规操作包括所有非必要的人工工作:
-
想法的产生。
-
创造一个理论。
-
根据理论编写代码。
-
代码修改。
-
持续的EA重新优化。
-
持续的EA选择。
-
EA维护。
-
使用终端。
-
实验和实践。
-
其它。
正如你所看到的,这个常规过程的范围相当广泛。我把这当成一种常规过程,因为我能够证明所有这些事情都是自动化的。我提供了一份总清单。你是谁并不重要——算法交易者、程序员,或者两者兼而有之。你是否了解如何编程并不重要。即使你不了解,那么在任何情况下,你都会遇到这个列表中的至少一半。我不是说当你在市场上购买EA,在图表上运行它,然后按下一个按钮就万事大吉了。当然,这种情况会发生,尽管极为罕见。
了解了这一切,首先我必须将最明显的事情自动化。我在上一篇文章中从概念上描述了所有这些优化。然而,当你做这样的事情时,你开始了解如何在已经实现的功能的基础上改进整个事情。对我来说,这方面的主要想法如下:
-
完善优化机制。
-
创建用于合并 EA(合并机器人)的机制。
-
所有组件的交互路径的正确体系结构。
当然,这只是一个非常简短的列举,我会更详细地描述每件事。我所说的优化是指同时包含几个因子的集合。所有这些都是在构建整个系统的选定范式中经过深思熟虑的:
-
通过消除分时加快优化速度。
-
通过消除交易决策点之间的利润曲线控制来加速优化。
-
通过引入自定义优化标准来提高优化质量。
-
最大限度地提高远期效率。
在这个论坛网站上,你仍然可以找到关于是否需要优化以及优化的好处的争论。此前,我对这一行为的态度相当明确,很大程度上是由于个人论坛和网站用户的影响。现在这种观点一点也不困扰我。至于优化,这完全取决于你是否知道如何正确使用它以及你的目标是什么。如果使用正确,此行动将产生所需的结果。总的来说,事实证明,这一行动非常有用。
许多人不喜欢优化,这有两个客观原因:
-
缺乏对基本知识的理解(为什么、做什么和如何做,如何选择结果以及与此相关的一切,包括缺乏经验)。
-
优化算法的缺陷。
事实上,这两个因素相辅相成。公平地说,MetaTrader 5优化器在结构上执行得无可挑剔,但在优化标准和可能的过滤器方面仍需要许多改进。到目前为止,所有这些功能都类似于儿童沙箱。很少有人考虑如何实现正向的前瞻时间段,最重要的是,如何控制这一过程。我想了很久了。事实上,当前文章中有相当一部分将专门讨论这个主题。
新的优化算法
除了任何回溯测试的基本已知评估标准外,我们还可以提出一些组合特征,这些特征可以帮助任何算法的值相乘,从而更有效地选择结果并随后应用设置。这些特性的优点是可以加快查找优化设置的过程。为此,我创建了一个类似于MetaTrader的策略测试报告:
图1

添加图片注释,不超过 140 字(可选)
有了这个工具,我只需点击一下就可以选择我喜欢的选项。通过点击,生成了一个设置,我可以立即将其移到终端中的适当文件夹中,以便通用EA可以读取并开始在其上进行交易。如果我愿意,我也可以点击按钮生成一个EA,在我需要一个单独的EA,里面有固定的设置时,它将被构建。还有一条利润曲线,当您从表中选择下一个选项时会重新绘制。
让我们计算一下表中的数字。计算这些特性的主要元素是以下数据:
-
Points:对应资产在整个回测中的利润点数(“_Points”)。
-
Orders:完全打开和关闭的订单的数量(它们按照严格的顺序相互遵循,根据规则“只能有一个打开的订单”)。
-
Drawdown:余额的回撤。
基于这些值,计算出以下交易特征:
-
Math Waiting: 数学期望点数。
-
P Factor:类似于利润因子,标准化为范围[-1…0…1](我的标准)。
-
Martingale:马丁格尔应用(我的标准)。
-
MPM Complex:上述三项的综合指标(我的标准)。
现在让我们看看这些标准是如何计算的:
等式1

添加图片注释,不超过 140 字(可选)
正如你所看到的,我创建的所有标准都非常简单,最重要的是易于理解。由于每个标准的增加表明回溯测试结果在概率论方面更好,因此可以将这些标准相乘,就像我在MPM综合标准中所做的那样。通用度量将更有效地根据结果的重要性对结果进行排序。在进行大规模优化的情况下,它将允许您分别保留更多高质量的选项和删除更多低质量的选项。
此外,请注意,在这些计算中都是使用点数。这对优化过程有积极影响。对于计算,使用严格正的主量,这些主量总是在开始时计算。其余的都是根据它们来计算的。我认为,值得列出表中未列出的主量:
-
Points Plus: 每个盈利订单或零盈利订单的利润总和(以点数为单位)
-
Points Minus: 每个不盈利订单的损失模之和(以点为单位)
-
Drawdown: 余额的回撤(我用自己的方式计算)
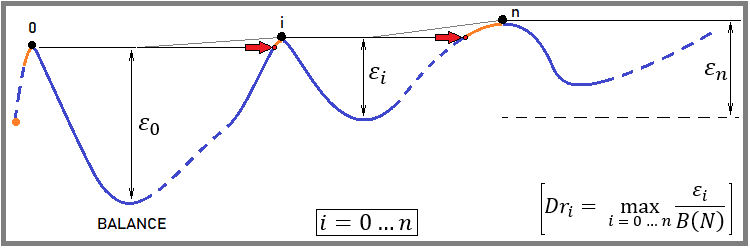
这里最有趣的是如何计算回撤。在我们的案例中,这是最大的相对余额回撤。考虑到我的测试算法拒绝监控资金曲线,其他类型的回撤无法计算。然而,我认为应该展示一下我是如何计算这一回撤的:
图2
添加图片注释,不超过 140 字(可选)
它的定义非常简单:
-
计算回测的起始点(第一次回撤计数的开始)。
-
如果交易以盈利开始,那么我们会随着余额的增长将这一点向上移动,直到出现第一个负值(这标志着回撤计算的开始)。
-
等待,直到余额达到参考点的水平。之后,将其设置为新的参考点。
-
我们返回到回撤搜索的最后一部分,并在上面寻找最低点(该部分的回撤量是从这一点计算得出的)。
-
对整个回溯测试或交易曲线重复整个过程。
最后一个周期将永远是未完成的状态,然而,它的回撤也被考虑在内,尽管如果测试继续下去,它有可能增加。但这在这里并不是一件特别重要的事情。
最重要的优化标准
现在让我们来谈谈最重要的过滤器。事实上,在选择优化结果时,这个标准是最重要的。这个标准没有包含在MetaTrader 5优化器的功能中,这是一个遗憾。所以让我提供一些理论材料,让每个人都能在自己的代码中重现这种算法。事实上,这一标准适用于任何类型的交易,适用于任何利润曲线,包括体育博彩、加密货币和你能想到的任何其他东西。标准如下:
等式2

添加图片注释,不超过 140 字(可选)
让我们看看这个等式里面有什么:
-
N - 在整个回溯测试或交易部分中完全开放和关闭的交易头寸的数量。
-
B(i) — 对应平仓“i”之后的余额线的值。
-
L(i) — 从零到余额最后一点的直线(最终余额)。
我们需要执行两次回溯测试来计算这个参数。第一次回溯测试将计算最终余额。之后,可以通过保存每个余额点的值来计算相应的指标,从而无需进行不必要的计算。然而,这种计算可以称为重复回溯测试。这个等式可以在自定义测试器中使用,这些测试器可以构建到您的EA中。
重要的是要注意,这一指标作为一个整体可以进行修改,以便更好地理解。例如,如下所示:
等式3

添加图片注释,不超过 140 字(可选)
这个等式在感知和理解方面更困难。但从实际角度来看,这样的标准很方便,因为它的值越高,我们的余额曲线就越像一条直线。我在以前的文章中谈到了类似的问题,但没有解释它们背后的含义。我们先来看下图:
图3
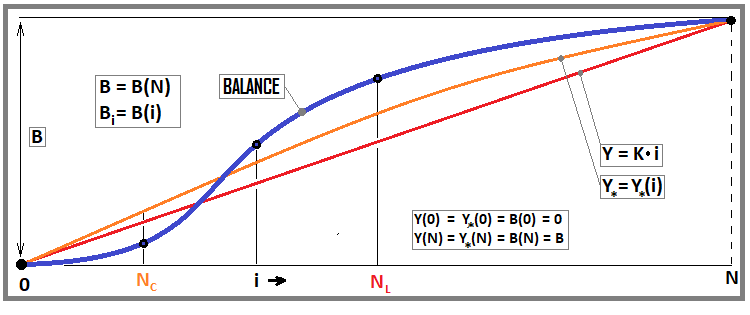
添加图片注释,不超过 140 字(可选)
该图显示了一条余额线和两条曲线:其中一条与我们的等式(红色)有关,第二条与以下修改标准有关(方程11)。我将进一步展示,但现在让我们专注于等式。
如果我们把我们的回溯测试想象成一个简单的有平衡的点阵列,那么我们可以把它表示为一个统计样本,并将概率论公式应用于它。我们将把直线视为我们正在努力的模型,而利润曲线本身就是为我们的模型而努力的真实数据流。
重要的是要理解,线性系数表示整个可用交易标准集的可靠性。反过来,更高的数据可靠性可能表明可能有更长更好的远期(未来可以获利的交易)。严格地说,一开始我应该考虑随机变量来考虑这些事情,但在我看来,这样的演示应该更容易理解。