常见设计模式/实践
RTL 设计(尤其是 ASIC)的最终目标是制作出最小、最快的电路。为此,我们需要了解综合工具如何分析和优化设计。此外,我们还关注仿真速度,因为等待测试运行实际上是在浪费工程精力。虽然综合和仿真工具有许多优化通道和转换,但最终结果的一个重要因素是设计模式,即代码是否遵循工具的设计指南。很多优化都是针对特定的设计模式进行的,这使得代码更容易被理解,从而被工具简化。此外,某些设计模式还可以简化代码结构,使代码更具可读性和可重用性。
在本章中,我们将介绍一些常见的设计实践,以及我们应该如何编写逻辑程序和结构化源代码。
4.1 Compiler Directives and Packages
与 C/C++ 类似,SystemVerilog 也定义了一个预处理阶段,在这个阶段,宏被扩展到原始源代码中。与 C/C++ 相比,SystemVerilog 的编译器指令不具备图灵完备性和通用性,这意味着即使是固定边界的递归计算也很难在 SystemVerilog 中指定。不过,它允许在 SystemVerilog 中进行一定程度的预处理。
4.1.1 Compiler Directives
该语言定义了多个编译器指令。我们将在此介绍一些最常用的宏:
`__FILE__`__LINE__`define`else`elseif`ifdef`ifndef`endif`undef`timescale`include
`__FILE__ 和 `__LINE__ 的使用方法与 C/C++ 中的 __FILE__ 和 __LINE__ 相同。用户可以使用它们进行测试台调试。在预处理过程中,这两个编译器指令将被替换为实际的文件名和行号。
`define 允许你定义宏,这些宏可以在以后的代码中使用。我们将展示两个示例,第一个示例定义了值,第二个示例定义了需要参数的函数式代码片段。请注意,与 C/C++ 不同,宏在代码中使用时必须以 ` 作为前缀。
`define VALUE 10
module top (input logic clk);
logic [31:0] a;
always_ff @(posedge clk)a <= `VALUE;
endmoduleIn the example above, we define `VALUE to be 10, and used it as register value. Even though we cover the usage here, please avoid defining constant values as macros in such way. It is because:
- It is difficult to find where the macro is defined, e.g. either from a file or command line options
- There is no namespace regarding macro values. If there are two macros shares the same name, whichever gets parsed later will be used. This may cause unexpected bugs that is difficult to debug, since the compiler may not issue warning for macro re-definition.
We highly recommend to use define constants in a package, which will be covered later in this chapter.
Another way to use `define is to define some code snippets which can be re-used later, as shown in the example below (also in code/04/macros_arguments.sv):
`define REGISTER(NAME, WIDTH, VALUE, CLK) \logic [WIDTH-1:0] NAME; \always_ff @(posedge CLK) begin \NAME <= VALUE; \end
module top;
logic clk;
logic [15:0] in;
// declare 3 registers that are pipelined to signal in, in sequence
`REGISTER(reg1, 16, in, clk)
`REGISTER(reg2, 16, reg1, clk)
`REGISTER(reg3, 16, reg2, clk)
// set the clock to 0 at time = 0, then tick the clock every 2 unit of time
initial clk = 0;
always clk = #2 ~clk;
initial beginfor (int i = 0; i < 3; i++) beginin = i;// wait for a cycle#4;// print out the register value$display("reg1: %d reg2: %d reg3: %d", reg1, reg2, reg3);end$finish;
end
endmoduleWe will see the expected output, where x denotes uninitialized register value:
reg1: 0 reg2: x reg3: x
reg1: 1 reg2: 0 reg3: x
reg1: 2 reg2: 1 reg3: 0在上面的代码示例中,我们首先定义了三个以流水线方式(链式)输入信号的寄存器。宏 REGISTER 首先定义了寄存器的名称(NAME)和宽度(WIDTH),然后实例化一个 always_ff 块,并在每个时钟周期为寄存器赋值。请注意,我们必须使用 ( )来进行多行定义。
虽然有时使用宏可以节省时间,使代码更容易重复使用,但在重复代码段和宏的使用之间找到平衡点是很重要的。请记住,宏是在预处理阶段替换的,这将给源代码级调试带来挑战。由于所有宏都在全局命名空间中,因此还需要注意宏的重新定义。
在宏定义过程中,有时需要为不同的用途取消定义某些宏名。与 C/C++ 类似,可以使用 `undef 来取消宏定义。
`ifdef 和 `ifndef 可用于测试某些宏是否已定义(或未定义)。您需要用 `endif 关闭编译器指令。您还可以添加 `else 和 `elseif 来应对不同的情况。请注意,对于头文件,它们可以与 `define 一起使用,以提供包含保护,从而允许在多个地方包含头文件。它们的用法与 C/C++ 相同,因此在此不再赘述。
`timescale是一个对模拟器有用的重要编译器指令。它指定了特定设计元素中的时间计量单位和时间精度。对于任何编译单元范围,最多只能定义一个时间刻度。换句话说,在一起编译的两个不同源文件中定义时标是非法的。时间刻度 "的语法如下所示:
// general syntax
`timescale time_unit / time_precision
// e.g.
`timescale 1ns / 1ps
`timescale 1ns / 1ns参数 time_unit 用于指定时间和延迟的测量单位,参数 time_precision 用于指定延迟值在用于仿真之前的四舍五入方式。time_unit 和 time_precision 的单位可以是 s、ms、us、ns、ps 和 fs。整数部分指定了数值大小的数量级,换句话说,有效数字只有 1、10 和 100。
时标对于模拟抖动和定时违规至关重要。任何与功率相关的分析也需要它。强烈建议在顶层测试台中包含时标,即使没有使用它。
`include 的作用与 C/C++ 中的 #include 相同,它包含另一个文件中的定义。强烈建议为包含文件提供一个包含保护。如果文件名用引号括起来,例如 `include "filename.svh",编译器将首先搜索当前工作目录,然后搜索用户指定的任何位置。如果文件名用角括弧括起来,例如`include <filename.svh>,则文件名必须是语言标准定义的文件。这一规则与 C/C++ 类似。
4.1.2 Packages
尽管 package为设计人员提供了一种共享定义的方法,但编译器指令本质上是要求编译器将包含文件的内容复制到源文件中,这是一种受 C 语言影响的传统功能。由于现代编程语言开始使用模块/包来结构源代码,例如 C++20 中的模块,SystemVerilog 引入了一种称为包的结构,允许设计人员重用定义、接口和函数。由于包是可综合的,因此强烈建议在 RTL 和测试平台中使用它。下面是一个包的示例:
package my_def_pkg;
// local parameters
localparam VALUE = 42;
// struct
typedef struct {logic a;logic b;
} my_struct_t;
// enum
typedef enum logic { RED, GREEN } color_t;
// function
function logic and_op(logic a, logic b);return a & b;
endfunction
endpackage: my_def_pkgHere is an incomplete list of constructs that are allowed inside a package:
- parameter declaration, e.g.
parameterandlocalparam - function declaration, e.g. automatic function
- data declaration, e.g., struct and enum
- DPI import and export
- class declaration
- package import declaration
Since parameter cannot be redefined in side a package, we highly recommend to use localparam in lieu of parameter since they are functionally identical in a package. In other words, localparam does not have the visibility restriction in a package.
4.1.2.1 Package Import
To use the package definition in other modules, we need to use import keyword to import definition. There are several ways to import contents of a package and we will cover two commonly used approaches here:
-
wildcard import. This is similar to Python’s
from pkg_name import *:import my_def_pkg::*; -
explicit import. This is similar to Python’s
from pkg_name import class_name:import my_def_pkg::my_struct_t;
导入后,标识符(即结构体名称或枚举值名称)可以直接在模块中使用。需要注意的是,我们可以在多个地方进行包导入。根据软件包内容的使用位置,有两种标准的方法:
-
If the identifier is used for module port definition, the import needs to placed before port list:
module topimport my_def_pkg::*;(input my_struct_t in);endmodule: top -
Otherwise, we shall put the import inside the module:
module top;import my_def_pkg::*;my_struct_t a; endmodule: top
4.1.2.2 Import Packages within a Package
Like software programming languages, you can import a package content inside another package, and the “chained” imports can be visible to the consumer. Here is an example (code/04/chained_packages.sv) illustrates the package imports:
package def1_pkg;typedef enum logic[1:0] {ADD, SUB, MULT, DIV} alu_opcode_t;
endpackage: def1_pkg
package def2_pkg;// import alu_opcode_t from def1_pkgimport def1_pkg::alu_opcode_t;// define a new struct that include alu_opcode_ttypedef struct {alu_opcode_t alu_opcode;logic[7:0] addr;} opcode_t;
endpackage: def2_pkg
module top;// alu_opcode_t is NOT accessible from def2_pkg// the next line is ILLEGAL// import def2_pkg::alu_opcode_t;import def2_pkg::*;
opcode_t opcode;
endmodule: topNotice unlike some software programming language such as Python, where the imported identifier is accessible as part of the new package, SystemVerilog prohibits such behavior. If you try to import alu_opcode_t from def2_pkg, you will get a recursive import error in the compiler.
4.1.2.3 Package Usage Caveats
由于软件包的内容是有作用域的,因此在使用通配符导入时,有可能会发生命名冲突。经验法则是,当命名冲突时,一定要使用显式导入。有些编码风格禁止使用通配符导入,这样会使代码稍显冗长,但可读性和可维护性更高。具体的范围规则不在本书讨论范围之内,感兴趣的用户可以参考 1800-2017 中的表 26-1。
另一个注意事项是,必须先编译软件包,然后再编译依赖于软件包的模块文件。一种系统化的方法是依靠 make 等构建工具来确保编译顺序。另一种简单的方法是将软件包放在其他源文件之前,同时向工具提供文件名。
4.2 Finite State Machines
有限状态机(FSM)是硬件控制逻辑的核心部分。如何设计好 FSM 会直接影响到综合和验证工作,因为这些工具对如何编写 FSM 有一定的限制。虽然 FSM 的理论超出了本书的范围,但我们将在介绍有关 FSM 的主要话题时尽可能多地涉及 FSM。
4.2.1 Moore and Mealy FSM
一般来说,硬件设计中常用的 FSM 有两种类型,即摩尔机和 Mealy 机。摩尔机以爱德华-摩尔(Edward F. Moore)命名,是一种输出值完全由当前状态决定的 FSM。另一方面,以 George H. Mealy 命名的 Mealy 机器是一种 FSM,其输出值由当前状态和当前输入决定。为了正式区分摩尔机和 Mealy 机,我们可以参考以下数学符号。
- A finite set of states S
- An initial state S0 such that S0∈S
- A finite input set Σ
- A finite output set Λ
- A state transition function T:Σ×S → S
- An output function G
For Moore machines, the output function is �:�→Λ, whereas for Mealy machines, the output function is �:Σ×�→Λ. Although Moore and Mealy machine are mathematically equivalent, there is a major difference when represented as a state transition diagram, as shown in Figure 4 and 5, where both diagram describes the logic that counts consecutive ones and output 1 once the count reaches 2. As a notation, the label on edges in Moore machine represents the input values and the label on the node represents the output value. In Mealy machine, the label on the edge follows input/output notation.

Figure 4: State transition diagram for Moore Machine.

Figure 5: State transition diagram for Mealy Machine.
由于存在这种差异,当我们在 SystemVerilog 中设计 Moore 和 Mealy 机器时,会看到时序和面积方面的不同: - 要描述相同的控制逻辑,Moore 机器的状态往往多于 Mealy 机器 - 与 Mealy 机器相比,Moore 机器的输出往往有一个额外的周期延迟。
选择使用哪种类型的机器通常取决于您要模拟的控制逻辑。如果在计算输出时忽略输入,那么 Mealy 机器也可用作 Moore 机器,因此 Mealy 机器更为通用。虽然没有什么可以阻止您将这两种机器混合使用,但我们强烈建议您坚持使用一种编码风格,以便工具可以轻松识别您的设计。
4.2.2 FSM State Encoding
There are several different ways to encode your states �, one-hot encoding, Gray encoding, and binary encoding. Given |�|=�:
- one-hot encoding implies that only one of its bits is set to
1for a particular state. That means the total number of bits required to represent the states is �. The Hamming distance of this encoding is 2, meaning we have to flip 2 bits for a state transition. - Gray encoding, named after Frank Gray, is a special encoding scheme that only requires ���2(�) bits to encode. In addition, its Hamming distance is designed to be 1, which means only one bit change is required to transit a state
- Binary encoding means the state value is assigned by its index in the states. As a result, it requires ���(�) to encode. Since each state transition may require flipping all bits, e.g., state 0 transits to state 3 for 2-bit state, its hamming distance is �(�).
每种编码都有各自的优势。例如,由于只需要一个比特来测试状态变量,单次热编码允许更小的多路复用逻辑,而加里编码允许更低的开关功耗,因此有利于低功耗设计。选择哪种编码更像是一个工程课题,取决于设计需求。因此,许多综合工具都提供了在综合过程中自动重新编码 FSM 状态的功能。因此,设计人员可以用一种编码方案对 FSM 进行编码,然后用另一种方案进行综合。然而,这也意味着 RTL 的综合版本与完成所有验证的原始 RTL 不同。因此,当工具对 FSM 进行重新编码时,可能会出现一些角落错误。一般来说,我们建议设计团队尽早根据一些工程实验结果决定编码方案。这样做可以确保综合与验证之间的一致性。
在 SystemVerilog 中,我们通常使用枚举来定义状态。与`define 和 localparam 等老式方法相比,使用枚举可以让编译器进行类型检查,从而使代码更安全、更易于调试。下面是几个使用一热编码、灰色编码和二进制编码的示例。
// on-hot encoding
typedef enum logic[3:0] {IDLE = 4'b0001,READY = 4'b0010,BUSY = 4'b0100,ERROR = 4'b1000
} hot_hot_state_t;
// Gray encoding
typedef enum logic[2:0] {RED = 4'b00,GREEN = 4'b01,BLUE = 4'b11,YELLOW = 4'b10
} gray_state_t;
// binary encoding
typedef enum logic[1:0] {STAGE_0 = 2'd0,STAGE_1 = 2'd1,STAGE_2 = 2'd2,STAGE_3 = 2'd3
} binary_state_t;4.2.3 General FSM Structure
As indicated by the formal definition of FSM, we need to design two components of the FSM: state transition logic � and output function �. However, since FSM needs to hold its state, we need another component that sequentially update the FSM state. As a result, a typical FSM always have three components, as shown in the Figure 6.

Figure 6: General FSM structure for Moore and Mealy machine.
4.2.4 One-, Two-, and Three-Block FSM Coding Style
虽然 FSM 有三个必要的组成部分,但有时我们可以将某些组成部分合并为一个流程。因此,我们有三种流行的 FSM 编码风格,通常称为单块、双块和三块 FSM 编码风格。
在下面的小节中,我们将以连续计数 1 为例,展示不同的编码风格。所有状态的定义以 SystemVerilog 包的形式显示如下。
`ifndef COUNT_ONE_FSM_PKG
`define COUNT_ONE_FSM_PKG
package count_one_fsm_pkg;
typedef enum logic[1:0] {moore_state0,moore_state1,moore_state2
} moore_state_t;
typedef enum logic {mealy_state0,mealy_state1
} mealy_state_t;
endpackage
`endif // COUNT_ONE_FSM_PKG4.2.4.1 Three-Block FSM Coding Style
Three-block FSM coding style is usually implemented as a Moore machine where:
- One block is used to update
statewithnext_state. - One block is used to determine
next_statebased onstateand current inputs. - One block is used to compute output based on
state.
The complete example of three-block FSM is shown below (code/04/three_block_fsm_moore.sv):
module three_block_fsm_moore (input logic clk,input logic rst_n,input logic in,output logic out
);
import count_one_fsm_pkg::*;
moore_state_t state, next_state;
// block 1: state <- next_state
always_ff @(posedge clk, negedge rst_n) beginif (!rst_n) beginstate <= moore_state0;endelse beginstate <= next_state;end
end
// block 2: determine next_state
always_comb begincase (next_state)moore_state0: beginif (in) next_state = moore_state1;else next_state = moore_state0;endmoore_state1: beginif (in) next_state = moore_state2;else next_state = moore_state0;endmoore_state2: beginif (in) next_state = moore_state2;else next_state = moore_state0;enddefault: beginnext_state = moore_state0;endendcase
end
// block 3: determine output based on state
always_comb begincase (state)moore_state0: out = 0;moore_state1: out = 0;moore_state2: out = 1;default: out = 0; endcase
end
endmodule: three_block_fsm_moore4.2.4.2 Two-Block FSM Coding Style
Two-block FSM is usually implemented in Mealy machine where: 1. One block is used to update state with next_state. 2. One block is used to determine next_state and the outputs, based on state and current inputs.
The complete example of two-block FSM is shown below (code/04/two_block_fsm_mealy.sv):
module two_block_fsm_mealy (input logic clk,input logic rst_n,input logic in,output logic out
);
import count_one_fsm_pkg::*;
mealy_state_t state, next_state;
// block 1: state <- next_state
always_ff @(posedge clk, negedge rst_n) beginif (!rst_n) beginstate <= mealy_state0;endelse beginstate <= next_state;end
end
// block 2: determine next_state and output
always_comb begincase (state)mealy_state0: beginif (in) beginnext_state = mealy_state1;out = 0;endelse beginnext_state = mealy_state0;out = 0;endendmealy_state1: beginif (in) beginnext_state = mealy_state1;out = 1;endelse beginnext_state = mealy_state0;out = 0;endendendcase
end
endmodule: two_block_fsm_mealy使用基于 Mealy 机器的双块 FSM 的好处是,只要输入发生变化,输出就会更新,而无需等待下一个周期。不过,这也给维护带来了困难。由于下一状态逻辑和输出是一起编码的,如果我们需要调整 FSM,可能需要对双块式进行重大重组。至于使用哪种方式,则由设计团队决定。
4.2.4.3 One-Block FSM Coding Style
One-block merges all the blocks together. As a result, maintaining and debugging such FSM is very challenging and we highly discourage people to adopt such FSM style unless absolute necessary. However, for completeness, we will show the code example people so that readers can recognize such programming style in practice.
module one_block_fsm_mealy (input logic clk,input logic rst_n,input logic in,output logic out
);
import count_one_fsm_pkg::*;
mealy_state_t state;
// one block: state update, next state, and output are in the same always_ff block
always_ff @(posedge clk, negedge rst_n) beginif (!rst_n) beginstate <= mealy_state0;endelse begincase (state)mealy_state0: beginif (in) beginstate <= mealy_state1;out <= 0;endelse beginstate <= mealy_state0;out <= 0;endendmealy_state1: beginif (in) beginstate <= mealy_state1;out <= 1;endelse beginstate <= mealy_state0;out <= 0;endenddefault: beginstate <= mealy_state0;out <= 0;endendcaseend
end
endmodule: one_block_fsm_mealy4.2.5 How to Write FSM Effectively
Designing an efficient FSM requires engineering work and experiments. A typical workflow is shown below:
- Identify states and state transition logic and turn it into a design specification.
- Implement FSM based on the specification
- (Optional) optimize the FSM based on feedbacks.
FSM 设计的第一步涉及设计探索,包括需要多少个状态、使用什么编码风格、使用什么状态编码以及输出逻辑是什么。可视化 FSM 的常用方法是用状态转换图来表示。另一种表示 FSM 的方法是使用表格,每一行代表一个状态转换。在确定所有状态后,我们可以通过状态还原等方法进一步优化 FSM,将具有完全相同逻辑(相同输出和相同转换)的状态合并为一个状态。
一旦确定了规范,将其转化为 FSM 就非常简单了。每个转换弧都可以用我们前面讨论过的情况项来表示,输出逻辑也是如此。一旦实现完成,我们就需要针对常见的错误(如死锁或无法达到的状态)进行彻底测试。有些问题可能与实现有关,有些可能与规范有关。在任何情况下,我们都需要修正设计/规范,以满足设计要求。在本书后面讨论形式验证时,我们将讨论发现死锁和不可达状态的策略。
4.3 Ready/Valid Handshake
Ready/valid handshake is one of the most used design pattern when transferring data in a latency-insensitive manner. It consists of two components, the source and the sink, where data flows from the former to the latter. The source uses valid signal to indicate whether the data is valid and the sink uses ready signal to indicate whether it is ready to receive data, as shown in the figure below.

Figure 7: Ready/Valid block diagram
Because ready/valid is latency-insensitive, each signal has precise semantics at the posedge of the clock (we assume we are dealing with synchronous circuit): - If the valid signal is high @(posedge clk), we know that data is valid as well - If the ready signal is high @posedge (clk) AND the valid signal is high as well, we complete the data transfer. The size of transfer is often referred as one word. - If the system wishes to transfer more data, then we need to complete a series of one-word transfer, until the entire packet is transferred.
The timing diagram below shows cases where a transfer should or should not occur.

Figure 8: No data transfer

Figure 9: No data transfer

Figure 10: One successful ready/valid data transfer
Ready/valid handshake has several design pitfalls that needs to avoid: 1. If the source waits for the sink’s ready before asserting valid and vice versa, there will be chance of deadlock since both parties are waiting for each other. To avoid this, the control signal should be computed independently. 2. If the ready/valid signals are computed purely on combinational logic, there will be a combinational loop between the source and sink. To resolve this, either source or sink needs to register the control signals, or compute the signals based on some flopped states.
4.4 Commonly Used Design Building Blocks
In this section we lists some code examples of commonly used design building blocks. These circuits are commonly used in various circuit designs and are optimized for high synthesis quality.
4.4.1 Registers
There are various types registers, such as synchronous and asynchronous registers. Each type has their own benefits. The design team should decide ahead of time what types of registers to use consistently throughout the design. All the code examples here use negative reset.
4.4.2 Asynchronous Reset Registers
Asynchronous reset register has reset on its sensitivity list.
logic r, value;
always_ff @(posedge clk, negedge rst_n) beginif (!rst_n) beginr <= 1'b0;endelse beginr <= value;end
end4.4.2.1 Synchronous Reset Registers
Unlike Asynchronous reset registers, synchronous reset register only resets the register on clock edge, hence the name “synchronous”.
logic r, value;
always_ff @(posedge clk) beginif (!rst) beginr <= 1'b0;endelse beginr <= value;end
end4.4.2.2 Chip-enable Registers
Chip-enable registers has additional single that enables or disables the value update (sometimes called clock-gating). On ASIC, there are usually specially design cells to handle such logic. As a result, if you follow the code example below you will get optimal synthesis result. We will use asynchronous reset register as an example.
logic r, value;
always_ff @(posedge clk, negedge rst_n) beginif (!rst_n) beginr <= 1'b0;endelse if (c_en) beginr <= value;end
endIn generally we do not recommend using your own logic control the register update, for instance, multiplexing the update value instead of using the syntax above, or creating your own clock based on the enable logic. These kinds of modification are unlikely to be picked up by the synthesis tools, hence reduce synthesis quality.
4.4.2.3 Power-up Values
Some FPGA tool chains allows initial values to be set along with declaration, as shown below. Since this approach does not work for ASIC, we do not recommend such approach if you want your code to be portable.
logic a = 1'b0;
logic value;
always_ff @(posedge clk) begina <= value;
end4.4.3 Multiplexer
Multiplexer is a type of hardware circuit that selects output signals from a list of input signals. There are many ways to implement a multiplexer and we will cover two common implementation of multiplexers.
4.4.3.1 case-based Multiplexer
The simplest way to implement a multiplexer is using case statement. It is straightforward to implement and also allows synthesis tools to recognize the multiplexer and optimize the netlist. Here is an example of multiplexer that takes 5 inputs. Notice that the number of inputs does not need to be 2’s power.
module Mux5#(parameter int WIDTH = 1) (input logic[WIDTH-1:0] I0,input logic[WIDTH-1:0] I1,input logic[WIDTH-1:0] I2,input logic[WIDTH-1:0] I3,input logic[WIDTH-1:0] I4,input logic[$clog2(5):0] S,output logic[WIDTH-1:0] O
);
always_comb beginunique case (S)0: O = I0;1: O = I1;2: O = I2;3: O = I3;4: O = I4;default:O = I0;endcase
end
endmoduleNotice that default is used to handle edges cases where the select signal S is out of range or containing x.
A slightly shorten version is to merge all the input signals into an array and use index operator as multiplexer, as shown below:
module Mux#(parameter int WIDTH=1,parameter int NUM_INPUT=2) (input logic[NUM_INPUT-1:0][WIDTH-1:0] I,input logic[$clog2(NUM_INPUT)-1:0] S,output logic[WIDTH-1:0] O
);
assign O = (S < NUM_INPUT)?I[S]:I[0];
endmoduleIn the code example above, we implicitly ask the synthesis tool to create a multiplexer for us. There are several advantage of this approach:
- We let synthesis tool to do its job to optimize the design
- The module works with any arbitrary number inputs (
NUM_INPUThas to be larger than 1), as well as outputs.
4.4.3.2 AOI Multiplexer
In situations where hand-optimization is required, we can implement an AOI max. AOI stands for AND-OR-Invert, which implies the the basic logic operation we are going to do with the inputs. AOI gates are efficient with CMOS technology since we can use NAND and NOR logic gate to construct AOI gate.
There are two components of AOI mux, namely a precoder and AOI logic. The precoder translate select signal into one-hot encoding, and AOI logic merge the inputs into output based on the one-hot-encoded select signal. Here is the complete implementation of the AOI mux with 5 inputs (code/04/aoi_mux.sv).
module aoi_mux#(parameter int WIDTH=1,parameter int NUM_INPUT=2) (input logic[NUM_INPUT-1:0][WIDTH-1:0] I,input logic[$clog2(NUM_INPUT)-1:0] S,output logic[WIDTH-1:0] O
);
// calculate the ceiling of num_input / 2
localparam NUM_OPS = (NUM_INPUT + 1) >> 1;
localparam MAX_RANGE = NUM_INPUT >> 1;
logic [NUM_INPUT-1:0] sel_one_hot;
// simplified one-hot precoder.
assign sel_one_hot = (S < NUM_INPUT)?1 << S:0;
// intermediate results
logic [NUM_OPS-1:0][WIDTH-1:0] inter_O;
// AOI logic part
always_comb begin// working on each bitfor (int w = 0; w < WIDTH; w++) begin// half the treefor (int i = 0; i < MAX_RANGE; i++) begininter_O[i][w] = (sel_one_hot[i * 2] & I[i * 2][w]) |(sel_one_hot[i * 2 + 1] & I[i * 2 + 1][w]);end// need to take care of odd number of inputsif (NUM_INPUT % 2) begininter_O[MAX_RANGE][w] = sel_one_hot[MAX_RANGE * 2] & I[MAX_RANGE * 2][w];endend
end
// compute the final result, i.e. OR the intermediate result together
// notice that |inter_O doesn't work here since it will reduce to 1-bit signal
always_comb beginO = 0;for (int i = 0; i < NUM_OPS; i++) beginO = O | inter_O[i];end
end
endmoduleThe example above can be explained with matrix operation. After one-hot encoding transformation, we create a matrix � where �[�]=���_���_ℎ�� for �∈{0,1,…,���_�����−1}. In other words, all entries in matrix S is zero except for the column indicated by the select signal, which are all one’s. The input signals can be expressed as � where each row of � is one input. We then compute the following result:������=�×�
Notice that since � only consists of one’s and zero’s, multiplication is effectively performing AND operation. Matrix ������ has similar characteristic as matrix � due to the property of one-hot encoding. To obtain the result, we can do a row-wise OR reduction to obtain the final result. Since CMOS technology is more area efficient when we fuse AND and OR operation together, instead of computing one row at a time, we can compute two rows together, hence the variable NUM_OPS is computed based on ⌈���_�����2⌉. Readers are encouraged to work out the process with some simple examples.
AOI mux is an example of how we can express the same logic in a clever way that is optimized for CMOS technology. This kind of optimization requires keen insight on the logic as well as deep understanding of logic synthesis. Unless required, we do not recommend to hand-optimize common logic such as adder or multiplexer since it may not achieve better result than synthesis tools and error prone. Use the syntax sugar offered by the SystemVerilog language and let synthesis tools do the heavy lifting. If the code follows the coding style, synthesis tools can pick up easily and perform automatic optimization.
4.5 Wishbone Protocol: A Case Study
A common place for bugs to occur is the interface between components, where each component may have different design assumptions. One approach to limit such bugs is to adhere to a well-specified protocol such that each component will follow and thus reduce the interface error. In this chapter we will take a look at a simple yet complete protocol, namely WIshbone, and how we can write RTL code based on the spec.
Unlike protocols such as AXI4, Wishbone is an open-source hardware bus interface, which allows engineers and hobbyists to share public domain designs.
4.5.1 Wishbone Introduction
Wishbone bus consists of two channels: a request channel which can either be read or write, and an acknowledge (ACK) channel. These two channels connect the bus master and slave together, as shown in the figure below.

Figure 11: Wishbone channel diagram
The master has a list of signals specified by the specification. Notice that it is explicitly stated that IPs can change the interface name (PERMISSION 2.0.0), we will use the names used in the specification to make it easier to compare with the document. Notice that the specification follows the naming convention that suffix _O indicates output port and _I indicates input port.
There are a list of signals that’s shared between master and slave interfaces:
| Signal Name | Function |
|---|---|
CLK_I | All Wishbone output signals are registered at the rising edge of CLK_I. All Wishbone input signals are stable before the rising edge of CLK_I |
DAT_I | The data input array to pass binary data. Maximum 64-bit |
DAT_O | The data output array to pass binary data. Maximum 64-bit |
RST_I | Reset signal. This signal only resets the Wishbone interface, not required to reset the other part of the IP. |
TGD_I | Data tag type, which contains additional information about the data. Must be specified in the IP datasheet. |
TGD_O | Data tag type, same as TGD_I |
We’ll ignore TGD_I and TGD_O in this section, but keep in mind that they can transfer very useful metadata information such as error checking code to protect data.
Below shows the complete interface ports for the master (excluding the shared ports).
| Signal Name | Function |
|---|---|
ACK_I | The acknowledge indicates the normal termination of a bus cycle |
ADR_O | The address used for read/write request |
CYC_O | The cycle output. When asserted, indicates a valid bus cycle in progress |
STALL_I | When asserted, indicates that the current slave is not able to accept the transfer |
ERR_I | When asserted, indicates an abnormal cycle termination |
LOCK_O | When asserted, indicates the current bus cycle is uninterruptible |
RTY_I | When asserted, indicates that the interface is not ready to accept/send data and the cycle should be retried |
SEL_O | Indicates where valid data is expected on the DAT_I signal array during read cycles, and where it is placed on the DAT_O signal array during write cycles |
STB_O | The strobe output indicates a valid data transfer cycle. It is used to qualify other signals on the interface. |
TGA_O | Address tag type, which contains information associated with address lines, which can be qualified by STR_O. |
TGC_O | Cycle tag type, which contains information associated with bus cycles, which can be qualified by signal CYC_O. |
WE_O | Write enable output, which indicates whether the current local bus cycle is a read or write cycle. |
Again, we will ignore tag information. Interested readers should check out the specification.
The slave interface is symmetric with the master slave: XX_I from master will have a correspondence port XX_O in the slave and vice versa. In general, Wishbone interface is simpler than other bus interface such as Advanced Microcontroller Bus Architecture (AMBA), which is the reason why we can explain the protocol without lengthy details here.
4.5.2 Wishbone Master Example
We present here a simplified version of master module, where the read write behavior is controlled via a simple interface. For any real-world practice, we need to connect the master to an IP that directly controls the master’s behavior. We also drop the tag, lock, and byte select interface for simplicity, but keep in mind that in a real IP interface we need to implement this as well! We will focus on register read write instead of block transfer; we will also drop corner case handling such as error and retry. Interested readers should try to implement block transfer and other missing features.
First, we need to define the IO ports, where the width or the data is parametrized by WIDTH. We also need to add other parameterization for control and data signals.
module wb_master #(parameter WIDTH=32,parameter ADDR_WIDTH=16) (input logic CLK_I,input logic[WIDTH-1:0] DAT_I,output logic[WIDTH-1:0] DAT_O,input logic RST_I,
input logic ACK_I,output logic[ADDR_WIDTH-1:0] ADR_O,output logic CYC_O,input logic STALL_I,output logic STB_O,output logic WE_O
// external controlsinput logic write,input logic enable,input logic[ADDR_WIDTH-1:0] addr,input logic[WIDTH-1:0] wdata,output logic[WIDTH-1:0] rdata,output logic ready,output logic ack
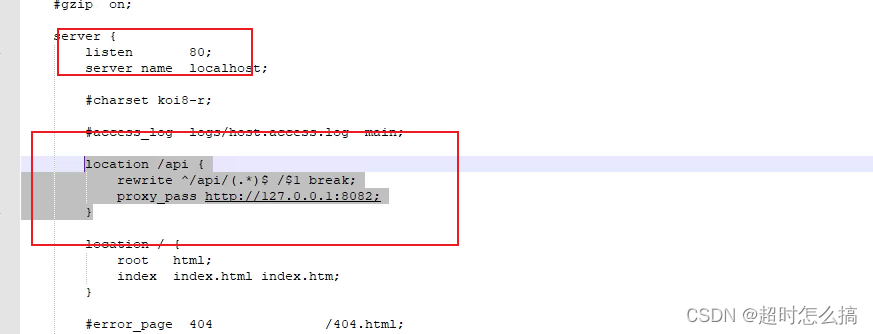
);请注意,根据命名规则,STALL_I 实质上是从属设备的就绪信号,而 STB_O 则是有效信号。考虑到这一点,我们可以快速勾勒出根据控制信号发送命令的逻辑。请注意,在 Wishbone 中,每个输出都将被注册。请注意,由于我们需要等待客户端确认转换,因此我们需要一个 FSM 来确定传输状态(我们将使用 2 块 FSM 来实现)。由于我们只对单个寄存器的传输感兴趣,因此无需记录传输的字数。
typedef enum logic {IDLE,BUSY
} State;
State state;Based on the state, we have three different outputs:
always_comb beginunique case (state)IDLE: beginCYC_O = 0;STB_O = 0;endBUSY: beginCYC_O = 1;STB_O = 1;endendcase
end然后,我们需要根据控制信号改变状态。由于我们只对一个字的传输感兴趣,因此当外部控制信号使能为高电平且从站准备就绪时,我们就开始交易。根据是读还是写请求,我们对 WB 控制数据进行不同的设置。启动事务后,主站进入忙状态,等待从站回执。之后,主站向外部客户端发出交易结束的信号,并返回空闲状态。
always_ff @(posedge CLK_I) begin// reset on highif (RST_I) beginstate <= IDLE;
// reset all registered outputsADDR_O <= 0;WE_O <= 0;DATA_O <= 0;
// external control signalack <= 0;ready <= 1;endelse beginunique case (state)IDLE: begin// only when the we're asked to send data// and slave is readyif (enable && !STALL_I) beginADDR_O <= addr;// write requestif (write) beginDATA_O <= wdata;WE_O <= 1;end else beginDATA_O <= 0;WE_O <= 0;end
SEL_O <= 1;state <= BUSY;// external control signalready <= 0;ack <= 0;endelse begin// external control signalready <= 1;ack <= 0;endendBUSY: begin// wait for slave ackif (ACK_I) begin// we goodstate <= IDLE;DATA_O <= 0;
// we assume control client will hold this signal until response gets backif (enable) beginack <= 1;if (!write) begin// if it's a readwdata <= DAT_I;endelse beginwdata <= 0;endendendendendcaseend
end