目录
- 使用pytorch库中CNN模型进行图像识别
- 收集数据集
- 定义CNN模型
- 卷积层
- 池化层
- 全连接层
- CNN模型代码
- 使用模型

使用pytorch库中CNN模型进行图像识别
收集数据集
可以去找开源的数据集或者自己手做一个
最终整合成 类别分类的图片文件
定义CNN模型
卷积层
功能:提取特征
概念:
- 卷积层输入层通道数
如果输入数据是彩色图像,那么通常情况下,输入数据具有三个通道(红、绿、蓝),因此第一个卷积层的输入通道数应该为3。
如果输入数据是灰度图像,那么输入通道数通常为 1。
- 卷积层输出层通道数
卷积层的输出通道数控制着该层提取的特征的数量和复杂度。更多的输出通道意味着网络可以学习更多种类的特征,但过多的输出通道数会导致复杂度和过拟合。
池化层
功能:使卷积层的特征更加明显,对图像进行降维压缩(舍弃无关特征,避免过拟合),提高神经网络的泛华能力。
问题:
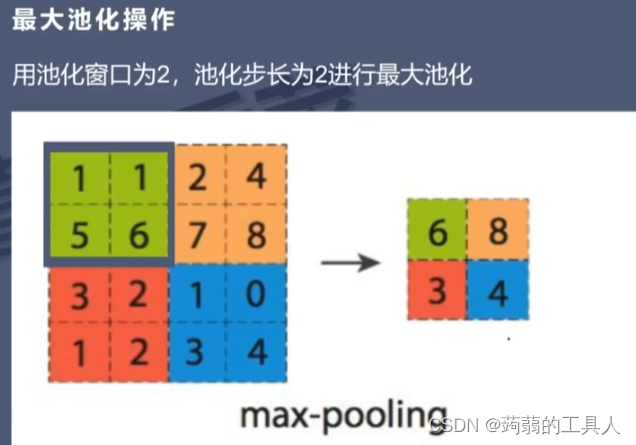
- 最大池化操作
最大池化操作是一种常用的池化操作,用于减少特征图的空间维度并保留最重要的特征信息
# 定义最大池化层,池化窗口大小为 2x2,步幅为 2
max_pool_layer = nn.MaxPool2d(kernel_size=2, stride=2)
全连接层
将特征进行整合,然后归一化,对各种分类情况都输入一个概率,根据概率进行分类
CNN模型代码
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from PIL import Image
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader, Dataset
# 进度条工具
from tqdm import tqdm# 数据集中的类别数
num_classes = len(os.listdir('./数据集'))
# 训练的轮数
num_epochs = 10
# 30次:['陕', '陕', 'U', 'U', '6', '6', '6', '6']
# 10次:['陕', 'A', 'D', '0', '6', '6', '6', '6']# 一、定义数据预处理和数据加载器
transform = transforms.Compose([# 固定图像大小transforms.Resize((64, 64)),# 将图像转换为灰度图像transforms.Grayscale(),# 将图像转换为张量transforms.ToTensor(),
])
# 使用ImageFolder定义数据集,标签为序号
train_dataset = ImageFolder(root='./数据集', transform=transform)
# 数据加载器,每个批次包含32张图像
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)# 二、定义 CNN 模型
class CNNModel(nn.Module):def __init__(self):super(CNNModel, self).__init__()# 卷积层1 1代表单通道,黑白;32代表输出通道;3代表3*3的卷积核, 1代表在最外围补一圈0self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1)# 池化层1 最大池化操作,2代表尺寸减半self.pool = nn.MaxPool2d(kernel_size=2, stride=2)# 卷积层2 ,32对于卷积层1的输出通道数self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)# 全连接层 64输出通道数,16*16代表压缩后的尺寸,生成长度128向量self.fc1 = nn.Linear(64 * 16 * 16, 128)self.fc2 = nn.Linear(128, num_classes)# 前向传播 返回输出结果def forward(self, x):# 卷积1x = self.conv1(x)# 激活函数/激化函数 引入非线性变化,增强神经网络复杂性x = torch.relu(x)# 池化x = self.pool(x)x = self.pool(torch.relu(self.conv2(x)))x = x.view(-1, 64 * 16 * 16)x = torch.relu(self.fc1(x))x = self.fc2(x)return x# 三、初始化模型、损失函数和优化器
model = CNNModel()
criterion = nn.CrossEntropyLoss()
# 学习率一般设0.01
optimizer = optim.SGD(model.parameters(), lr=0.01)# 四、只要当主文件运行时候,才训练模型
if __name__ == "__main__":for epoch in range(num_epochs):running_loss = 0.0print(f'Epoch : {epoch + 1}/{num_epochs}')# 显示每轮的进度条for images, labels in tqdm(train_loader):# 将优化器中存储的之前计算的梯度归零optimizer.zero_grad()# 将输入图像数据 images 输入到模型中进行前向传播,得到模型的输出outputs = model(images)# 损失函数 criterion 计算模型 输出 与 真实标签 之间的损失值。loss = criterion(outputs, labels)# 对损失值进行反向传播,计算模型参数的梯度loss.backward()# 据优化算法(梯度下降)更新模型参数,最小化损失函数optimizer.step()running_loss += loss.item()# 输出每个 epoch 的平均损失epoch_loss = running_loss / len(train_loader)print(f'Epoch {epoch + 1} loss: {epoch_loss:.4f}')# 保存模型torch.save(model.state_dict(), 'cnn_model.pt')使用模型
import torch
from PIL import Image
from torch.utils.data import dataset
from cnn_model import transform, train_dataset, CNNModel# 加载整个模型
model = CNNModel()
# 将模型设置为评估模式
model.eval()
checkpoint = torch.load('./cnn_model.pt')
model.load_state_dict(checkpoint)# 使用模型进行预测,识别单个文字图片
def predict_image(image_path):image = Image.open(image_path)# 转换图片格式image = transform(image)# 只进行前向传播with torch.no_grad():output = model(image)# ImageFolder输出的标签是文件序号,argmax找到张量output中的最大值predicted_idx = torch.argmax(output).item()print(predicted_idx)# 将输出转换成对应序号的文件名if predicted_idx < len(train_dataset.classes) :predicted_label = train_dataset.classes[predicted_idx]return predicted_labelelse:return "null"