本次课程链接在GitHub上:InternLM/Tutorial at camp2 (github.com)
第一次课程录播链接:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
InternLM2技术报告:arxiv.org/pdf/2403.17297.pdf
一、书生·浦语大模型全链路开源体系笔记
InternLM2是在2.6万亿token的高质量语料上训练得到的。沿袭第一代书生·浦语(InternLM)的设定,InternLM2包含7B及20B两种参数规格及基座、对话等版本,满足不同复杂应用场景需求。
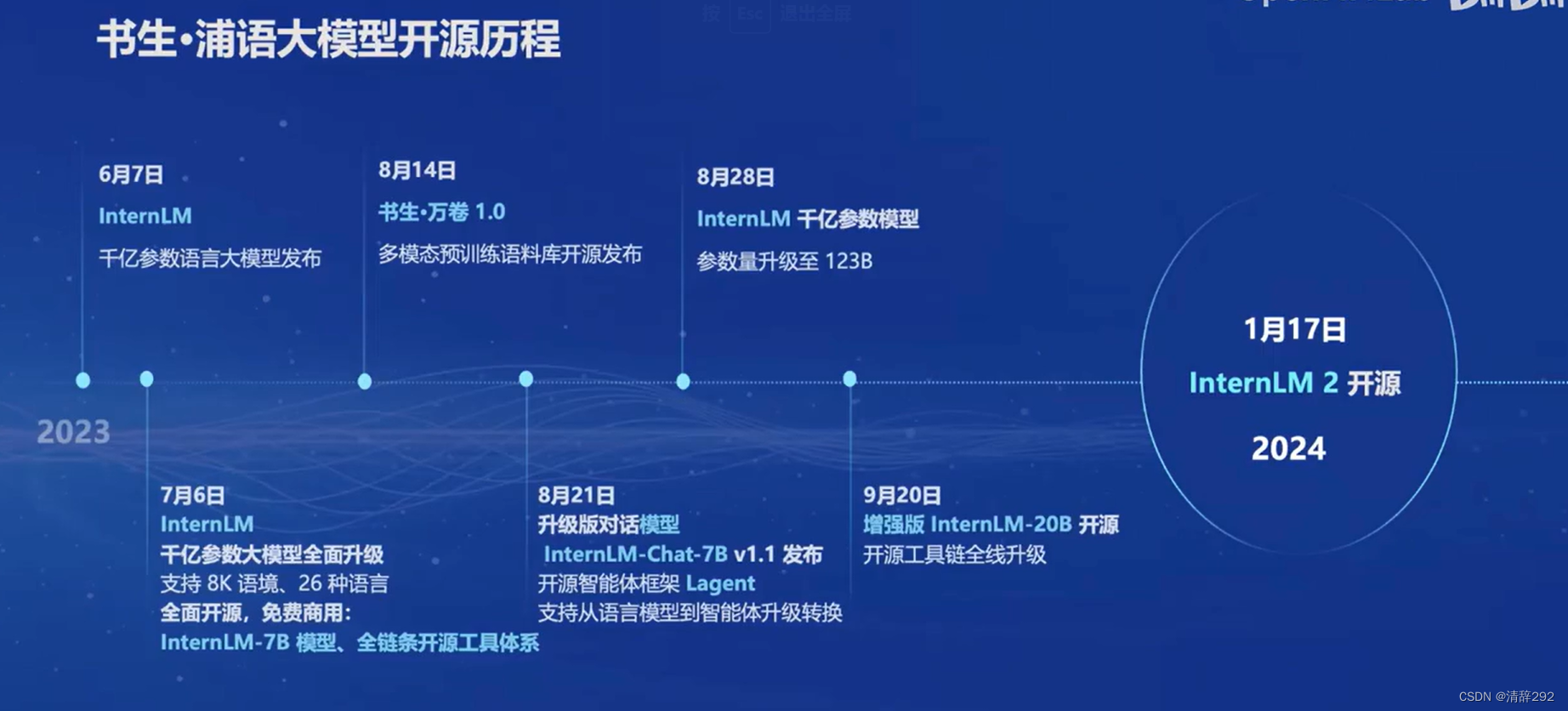
书生·浦语大模型开元历程
- 20230607 - InternLM千亿参数语言大模型发布
- 20230706 - InternLM千亿参数大模型全面升级,支持 8K 语境、26 种语言,全面开源,免费商用,InternLM-7B 模型、全链条开源工具体系
- 20230814 - 书生·万卷 1.0 多模态预训练语料库开源发布
- 20230821 - 升级版对话模型 InternLM-Chat-7B v1.1 发布,开源智能体框架 Lagent 支持从语言模型到智能体升级转换
- 20230828 - InternLM 干亿参数模型参数量升级至 123B
- 20230920 - 增强版 InternLM-20B 开源,开源工具链全线升级
- 20240117 - InternLM 2 开源
主要亮点
相比较于1代的InternLM,2代的InterLM2实现了全方位的性能提升(吊打)
- 1. 20w上下文,
- 2. 推理数学代码能力提升,
- 3. 结构化创作
- 4. 工具调用能力
- 5. 内生计算、代码解释

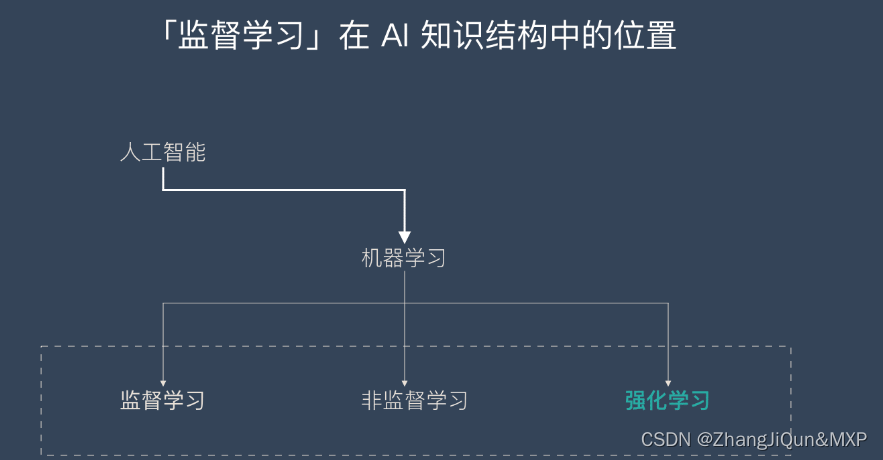
书生·浦语全链条开源开放体系
数据、预训练、微调、部署、评测、应用
模型的构建离不开数据作为基础,开放高质量语料数据集可以在OpenDataLab上获取:https://opendatalab.org.cn
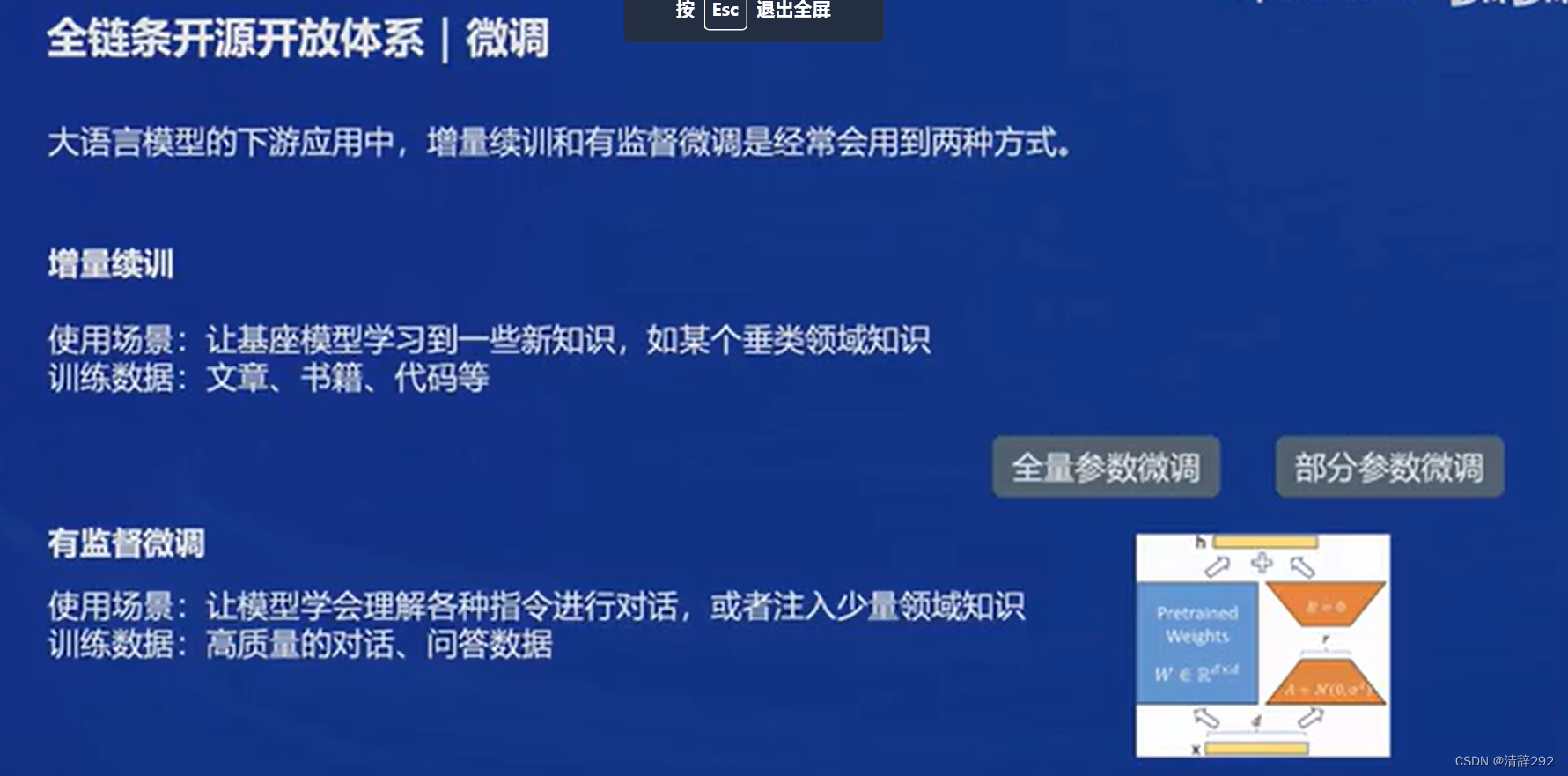
大模型的下游应用中,增量续训(如:以文章书籍代码等为训练数据,让基座模型学习到某个领域的一些新知识)和有监督微调(如:以高质量对话、问答数据等为训练数据,让模型学会理解各种指令进行对话,或者注入少量领域知识)是经常会用到的两种方式。
 微调
微调
- 增量续训
- 使用场景 - 新知识,垂类领域知识
- 训练数据 - 文章、书籍、代码
- 有监督微调(全量参数微调、部分参数微调)
- 使用场景 - 注入少量领域知识,对话
- 训练数据 - 高质量对话&问答数据
 部署
部署
LMDeploy是一个全面的开源平台,是一个高效部署、优化和管理机器学习模型及其在GPU加速系统上的推理工作流程。它的目标是为开发者提供一个全链条、开放且高性能的解决方案。

Agent智能体
基于开源轻量级的智能体框架Lagent和多模态的智能体工具箱AgentLego,其中Lagent可以支持多种类型的智能体能力,支持ReAct,ReWoo,AutoGPT不同的智能体Pipeline,灵活支持多种大模型,简单易拓展,支持丰富的工具。而AgentLego提供了一系列多功能的工具集合,支持多个主流智能体系统例如LangChain等,灵活的多模态工具调用接口,支持多模态扩展,包括视觉感知、图像生成与编辑、语音处理以及视觉-语言推理等功能,一键式远程工具部署,轻松使用和调试大模型智能体。

二、InternLM2技术报告笔记
概述
InternLM2是一个开源的大型语言模型(LLM),它在多个维度和基准测试中展现出了超越先前方法的能力。该模型通过创新的预训练和优化技术,在长序列建模和开放性主观评估方面表现突出。报告详细阐述了InternLM2的基础设施、模型结构、预训练数据、预训练设置、预训练阶段、对齐策略、评估和分析等内容。
主要贡献
- 模型开源与发布:
- InternLM2以不同规模(18亿、70亿和200亿参数)的模型形式公开发布,这些模型在主观和客观评估中都展现出了卓越的性能。
- 报告还发布了不同训练阶段的模型,以便社区能够分析监督微调(SFT)和基于人类反馈的条件在线强化学习(Conditional Online RLHF)训练后的模型变化。
- 长序列处理能力:
- InternLM2设计了具有200k上下文窗口的能力,使其在长序列任务中表现出色。特别是在“大海捞针”实验中,使用200k上下文几乎完美地识别出所有目标。
- 报告分享了在整个训练过程中(预训练、SFT和RLHF)训练长序列语言模型的经验和策略。
- 数据准备指南:
- 报告详细阐述了数据准备的各个环节,包括预训练数据、领域特定增强数据、SFT数据和RLHF数据的收集、处理和使用。
- 这些详细的数据准备指南将有助于社区更好地理解和训练LLMs,提高模型性能和泛化能力。
- 创新的RLHF训练技术:
- 报告引入了条件在线RLHF(COOL RLHF)方法,用于协调不同的偏好,从而显著提高了InternLM2在各种主观对话评估中的性能。
- 报告还进行了初步的主观和客观RLHF结果的分析和比较,为社区提供了对RLHF技术的深入理解。
基础设施
在人工智能领域,特别是在自然语言处理(NLP)方面,高效且强大的训练框架对于模型的开发和优化至关重要。InternEvo作为一个训练框架,在预训练、SFT(Supervised Fine-Tuning,有监督微调)以及RLHF(Reinforcement Learning from Human Feedback,从人类反馈中进行的强化学习)等关键阶段都发挥了关键作用。
InternEvo作为训练框架,在预训练、SFT和RLHF阶段展现了高效性和扩展性,通过数据并行等技术优化训练效率,支持灵活微调,并整合人类反馈优化模型表现,为大型语言模型的开发提供了坚实基础。
模型架构
该模型架构基于LLaMA的设计原则,不仅继承了RMSNorm和SwiGLU激活函数的优点,还在权重矩阵和注意力机制方面进行了创新。具体来说,模型对权重矩阵Wk、Wq、Wv进行了精心调整,以更好地支持不同的张量并行转换,从而显著提高了训练速度。这一改进使得模型在处理大规模数据时能够更加高效。
为了支持长上下文的处理,模型引入了分组查询注意力(GQA)结构。这种结构使得模型在处理非常长的上下文时能够保持高速运算和低GPU显存消耗,从而扩展了模型的应用范围。GQA结构通过分组处理查询向量,有效降低了计算复杂度和内存需求,使得模型在处理长文本时更加高效稳定。
预训练数据
预训练数据是构建大型语言模型(LLM)的基石,对于模型的性能至关重要。在本项目中,使用了海量的文本数据作为预训练数据,这些数据涵盖了多个领域,包括新闻、科技、文学、社交媒体等。通过收集这些多样化的数据,确保了模型能够从多个角度学习语言的规律和结构。
在数据预处理阶段,对原始数据进行了清洗和过滤,去除了重复、低质量和与任务不相关的内容。同时,还进行了分词、词频统计等处理,以便模型更好地理解和处理文本数据。
预训练设置
在预训练阶段,采用了多机多卡的方式进行分布式训练,以充分利用计算资源。具体来说,我们使用了数百个GPU进行并行训练,以加速模型的收敛速度。
在模型设置方面,采用了LLaMA的结构设计原则,并在此基础上进行了一些改进。使用了RMSNorm作为归一化方法,并采用了SwiGLU作为激活函数。这些选择有助于提高模型的稳定性和性能。
此外,还对模型的超参数进行了精心调整,包括学习率、批处理大小、训练轮数等。通过多次实验和调优,找到了一组适合本项目的超参数设置。
预训练阶段
预训练阶段是整个模型构建过程中最为耗时的部分。在这个阶段,模型通过无监督学习的方式从预训练数据中学习语言的规律和结构。采用了大规模并行化的训练策略,以加快训练速度。
在训练过程中,使用了梯度下降等优化算法来更新模型的参数。同时,还采用了学习率衰减、梯度裁剪等技术来防止模型过拟合和梯度爆炸等问题。
随着训练的进行,模型的性能逐渐提升,能够更好地理解和生成自然语言文本。
对齐策略
在对齐策略方面,采用了对齐损失函数来确保模型在生成文本时能够保持与原始文本的一致性。具体来说,计算了生成文本与原始文本之间的相似度或距离,并将其作为损失函数的一部分进行优化。
通过优化对齐损失函数,能够使模型在生成文本时更好地保留原始文本的信息和意图,提高生成文本的质量和相关性。
评估和分析
为了评估模型的性能,采用了多种评估指标,包括困惑度(Perplexity)、BLEU分数、ROUGE分数等。这些指标能够从不同角度评估模型在文本生成和理解方面的能力。
通过对模型在不同数据集和任务上的评估,发现模型在多个方面都取得了显著的性能提升。同时,还对模型的内部表示进行了可视化分析,以更好地理解其工作原理和性能瓶颈。
结论
InternLM2是一个功能强大且开源的大型语言模型,它在多个方面展现出了卓越的性能和创新能力。通过发布不同训练阶段和模型大小的版本,报告为社区提供了宝贵的洞察和参考。同时,训练框架InternEvo的高效性和可扩展性也为大型语言模型的训练提供了有力支持。这些贡献将有助于推动LLM领域的发展和应用。